 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Online Multi-Sensor Depth Fusion
Apr 07, 2022


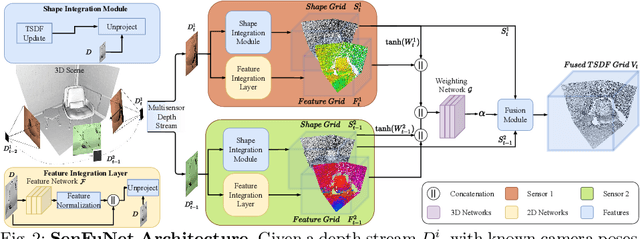
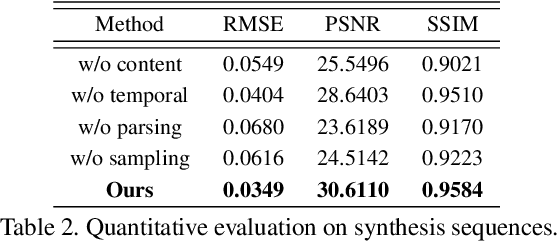
Many hand-held or mixed reality devices are used with a single sensor for 3D reconstruction, although they often comprise multiple sensors. Multi-sensor depth fusion is able to substantially improve the robustness and accuracy of 3D reconstruction methods, but existing techniques are not robust enough to handle sensors which operate with diverse value ranges as well as noise and outlier statistics. To this end, we introduce SenFuNet, a depth fusion approach that learns sensor-specific noise and outlier statistics and combines the data streams of depth frames from different sensors in an online fashion. Our method fuses multi-sensor depth streams regardless of time synchronization and calibration and generalizes well with little training data. We conduct experiments with various sensor combinations on the real-world CoRBS and Scene3D datasets, as well as the Replica dataset. Experiments demonstrate that our fusion strategy outperforms traditional and recent online depth fusion approaches. In addition, the combination of multiple sensors yields more robust outlier handling and precise surface reconstruction than the use of a single sensor.
Neural Video Portrait Relighting in Real-time via Consistency Modeling
Apr 01, 2021
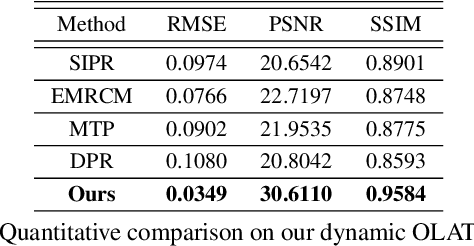
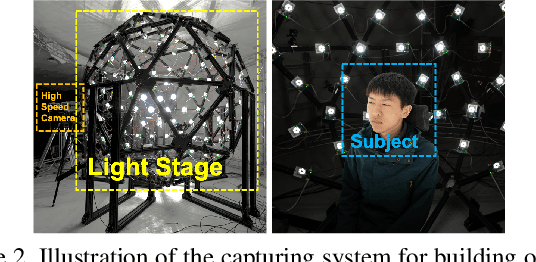
Video portraits relighting is critical in user-facing human photography, especially for immersive VR/AR experience. Recent advances still fail to recover consistent relit result under dynamic illuminations from monocular RGB stream, suffering from the lack of video consistency supervision. In this paper, we propose a neural approach for real-time, high-quality and coherent video portrait relighting, which jointly models the semantic, temporal and lighting consistency using a new dynamic OLAT dataset. We propose a hybrid structure and lighting disentanglement in an encoder-decoder architecture, which combines a multi-task and adversarial training strategy for semantic-aware consistency modeling. We adopt a temporal modeling scheme via flow-based supervision to encode the conjugated temporal consistency in a cross manner. We also propose a lighting sampling strategy to model the illumination consistency and mutation for natural portrait light manipulation in real-world. Extensive experiments demonstrate the effectiveness of our approach for consistent video portrait light-editing and relighting, even using mobile computing.
Correcting Robot Plans with Natural Language Feedback
Apr 11, 2022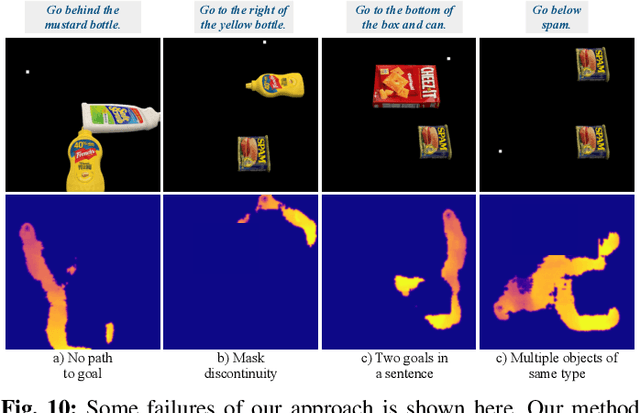
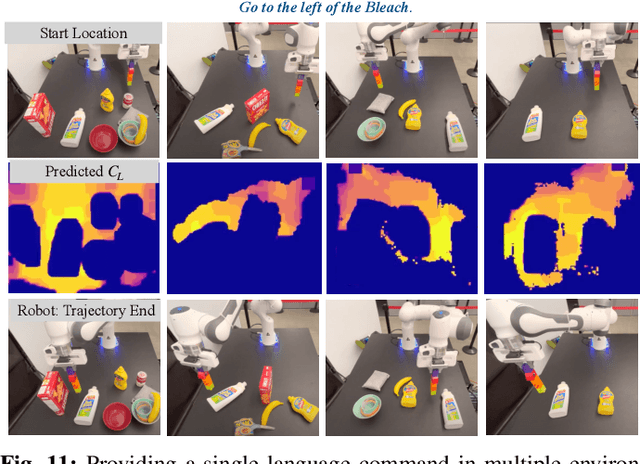

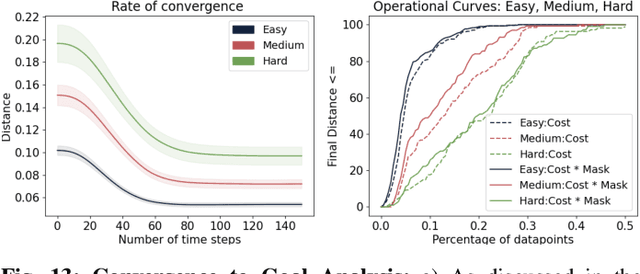
When humans design cost or goal specifications for robots, they often produce specifications that are ambiguous, underspecified, or beyond planners' ability to solve. In these cases, corrections provide a valuable tool for human-in-the-loop robot control. Corrections might take the form of new goal specifications, new constraints (e.g. to avoid specific objects), or hints for planning algorithms (e.g. to visit specific waypoints). Existing correction methods (e.g. using a joystick or direct manipulation of an end effector) require full teleoperation or real-time interaction. In this paper, we explore natural language as an expressive and flexible tool for robot correction. We describe how to map from natural language sentences to transformations of cost functions. We show that these transformations enable users to correct goals, update robot motions to accommodate additional user preferences, and recover from planning errors. These corrections can be leveraged to get 81% and 93% success rates on tasks where the original planner failed, with either one or two language corrections. Our method makes it possible to compose multiple constraints and generalizes to unseen scenes, objects, and sentences in simulated environments and real-world environments.
A Comprehensive Review of Sign Language Recognition: Different Types, Modalities, and Datasets
Apr 07, 2022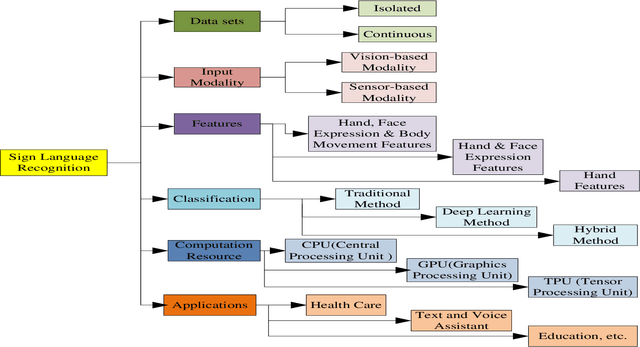
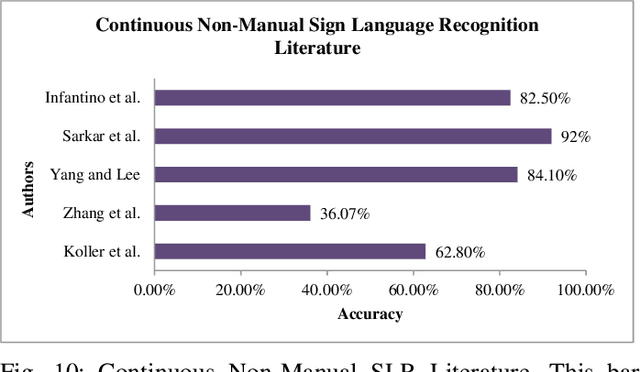
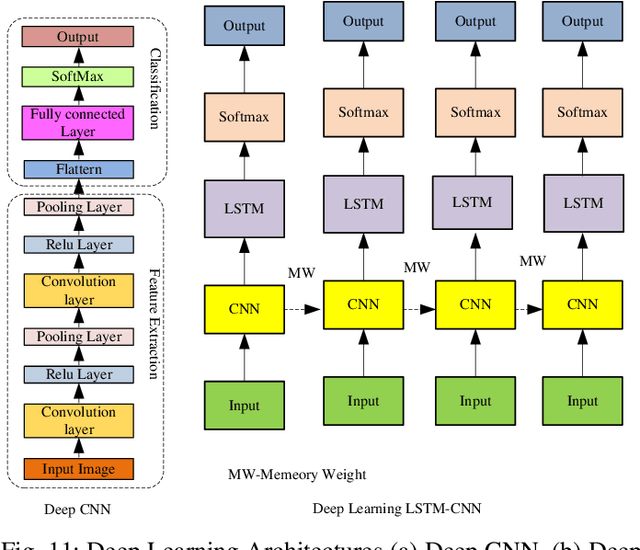
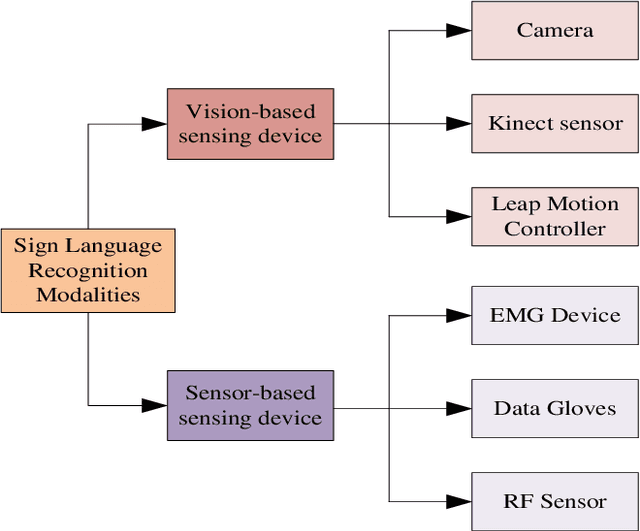
A machine can understand human activities, and the meaning of signs can help overcome the communication barriers between the inaudible and ordinary people. Sign Language Recognition (SLR) is a fascinating research area and a crucial task concerning computer vision and pattern recognition. Recently, SLR usage has increased in many applications, but the environment, background image resolution, modalities, and datasets affect the performance a lot. Many researchers have been striving to carry out generic real-time SLR models. This review paper facilitates a comprehensive overview of SLR and discusses the needs, challenges, and problems associated with SLR. We study related works about manual and non-manual, various modalities, and datasets. Research progress and existing state-of-the-art SLR models over the past decade have been reviewed. Finally, we find the research gap and limitations in this domain and suggest future directions. This review paper will be helpful for readers and researchers to get complete guidance about SLR and the progressive design of the state-of-the-art SLR model
Spatial-Temporal Hypergraph Self-Supervised Learning for Crime Prediction
Apr 18, 2022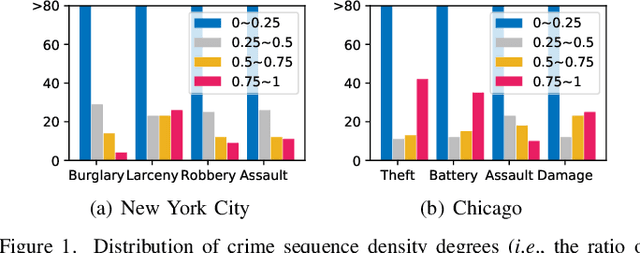
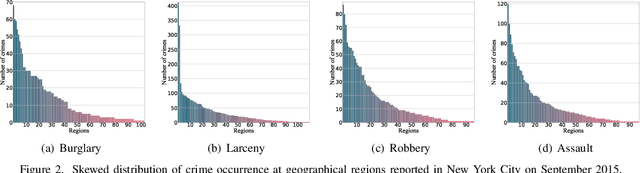
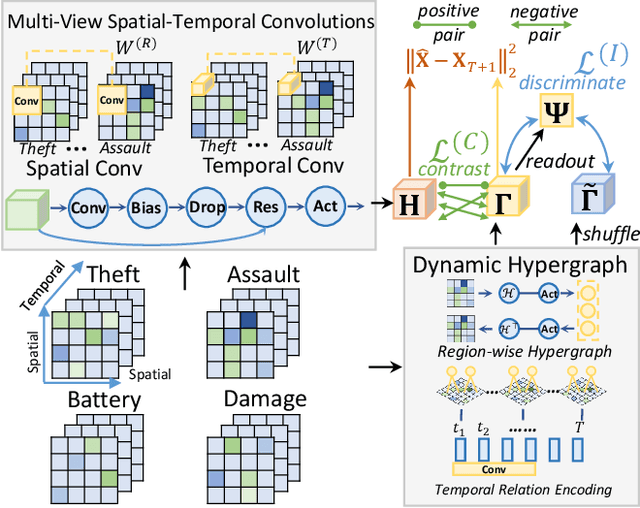
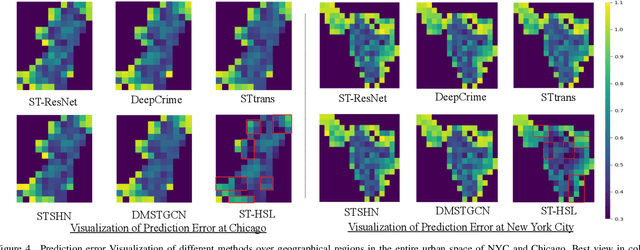
Crime has become a major concern in many cities, which calls for the rising demand for timely predicting citywide crime occurrence. Accurate crime prediction results are vital for the beforehand decision-making of government to alleviate the increasing concern about the public safety. While many efforts have been devoted to proposing various spatial-temporal forecasting techniques to explore dependence across locations and time periods, most of them follow a supervised learning manner, which limits their spatial-temporal representation ability on sparse crime data. Inspired by the recent success in self-supervised learning, this work proposes a Spatial-Temporal Hypergraph Self-Supervised Learning framework (ST-HSL) to tackle the label scarcity issue in crime prediction. Specifically, we propose the cross-region hypergraph structure learning to encode region-wise crime dependency under the entire urban space. Furthermore, we design the dual-stage self-supervised learning paradigm, to not only jointly capture local- and global-level spatial-temporal crime patterns, but also supplement the sparse crime representation by augmenting region self-discrimination. We perform extensive experiments on two real-life crime datasets. Evaluation results show that our ST-HSL significantly outperforms state-of-the-art baselines. Further analysis provides insights into the superiority of our ST-HSL method in the representation of spatial-temporal crime patterns. The implementation code is available at https://github.com/LZH-YS1998/STHSL.
Model-Architecture Co-Design for High Performance Temporal GNN Inference on FPGA
Mar 10, 2022
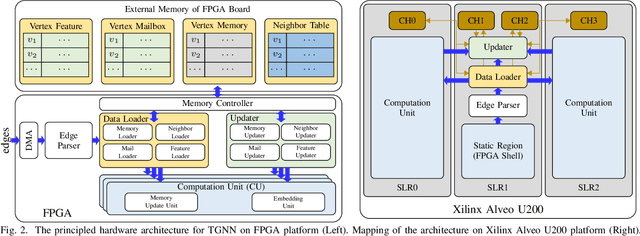
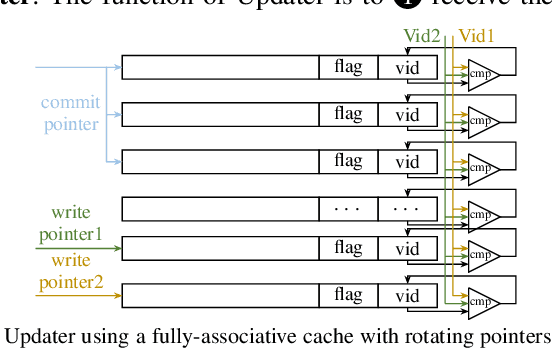
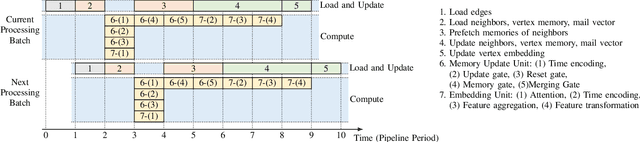
Temporal Graph Neural Networks (TGNNs) are powerful models to capture temporal, structural, and contextual information on temporal graphs. The generated temporal node embeddings outperform other methods in many downstream tasks. Real-world applications require high performance inference on real-time streaming dynamic graphs. However, these models usually rely on complex attention mechanisms to capture relationships between temporal neighbors. In addition, maintaining vertex memory suffers from intrinsic temporal data dependency that hinders task-level parallelism, making it inefficient on general-purpose processors. In this work, we present a novel model-architecture co-design for inference in memory-based TGNNs on FPGAs. The key modeling optimizations we propose include a light-weight method to compute attention scores and a related temporal neighbor pruning strategy to further reduce computation and memory accesses. These are holistically coupled with key hardware optimizations that leverage FPGA hardware. We replace the temporal sampler with an on-chip FIFO based hardware sampler and the time encoder with a look-up-table. We train our simplified models using knowledge distillation to ensure similar accuracy vis-\'a-vis the original model. Taking advantage of the model optimizations, we propose a principled hardware architecture using batching, pipelining, and prefetching techniques to further improve the performance. We also propose a hardware mechanism to ensure the chronological vertex updating without sacrificing the computation parallelism. We evaluate the performance of the proposed hardware accelerator on three real-world datasets.
On the throughput of the common target area for robotic swarm strategies -- extended version
Jan 25, 2022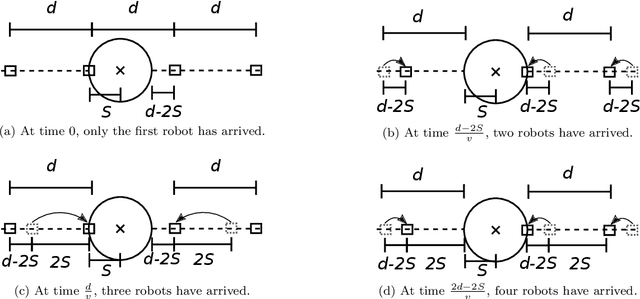
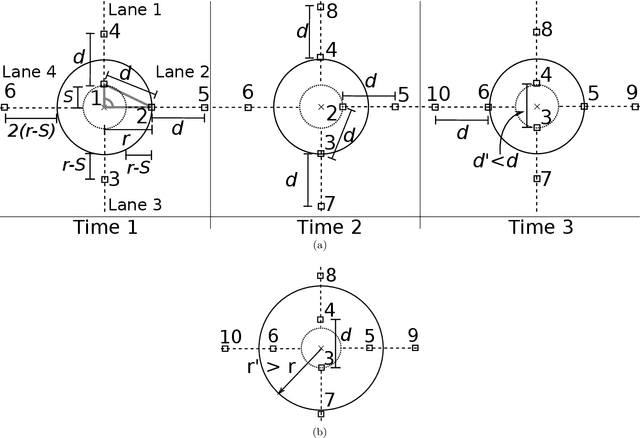
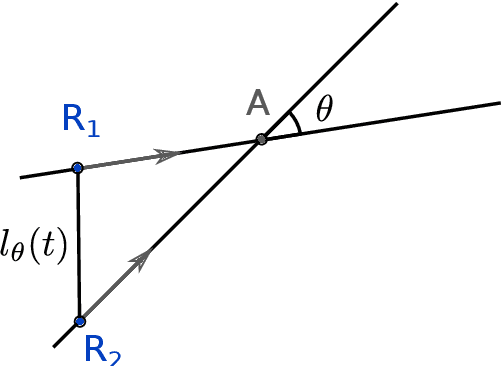
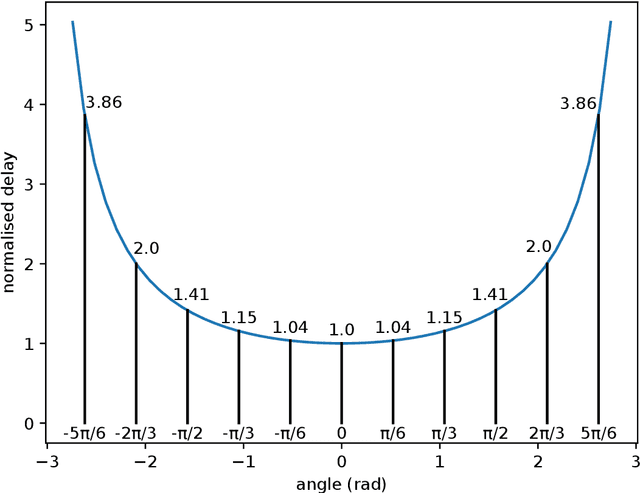
A robotic swarm may encounter traffic congestion when many robots simultaneously attempt to reach the same area. For solving that efficiently, robots must execute decentralised traffic control algorithms. In this work, we propose a measure for evaluating the access efficiency of a common target area as the number of robots in the swarm rises: the common target area throughput. We demonstrate that the throughput of a target region with a limited area as the time tends to infinity -- the asymptotic throughput -- is finite, opposed to the relation arrival time at target per number of robots that tends to infinity. Using this measure, we can analytically compare the effectiveness of different algorithms. In particular, we propose and formally evaluate three different theoretical strategies for getting to a circular target area: (i) forming parallel queues towards the target area, (ii) forming a hexagonal packing through a corridor going to the target, and (iii) making multiple curved trajectories towards the boundary of the target area. We calculate the throughput for a fixed time and the asymptotic throughput for these strategies. Additionally, we corroborate these results by simulations, showing that when an algorithm has higher throughput, its arrival time per number of robots is lower. Thus, we conclude that using throughput is well suited for comparing congestion algorithms for a common target area in robotic swarms even if we do not have their closed asymptotic equation.
Event Camera Based Real-Time Detection and Tracking of Indoor Ground Robots
Feb 23, 2021
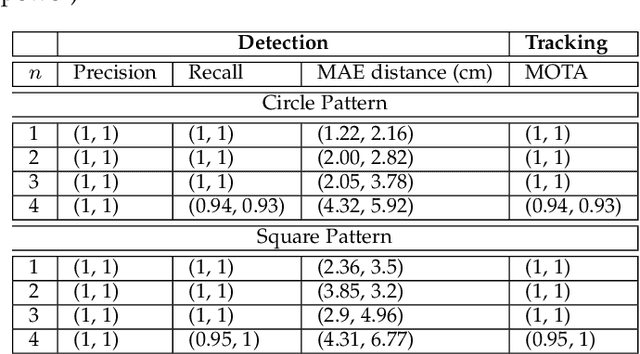

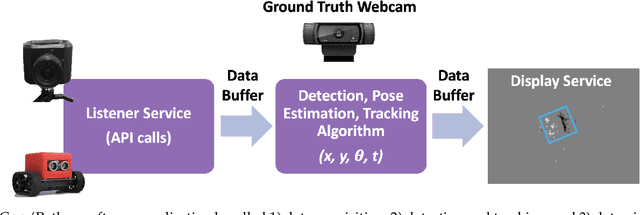
This paper presents a real-time method to detect and track multiple mobile ground robots using event cameras. The method uses density-based spatial clustering of applications with noise (DBSCAN) to detect the robots and a single k-dimensional (k-d) tree to accurately keep track of them as they move in an indoor arena. Robust detections and tracks are maintained in the face of event camera noise and lack of events (due to robots moving slowly or stopping). An off-the-shelf RGB camera-based tracking system was used to provide ground truth. Experiments including up to 4 robots are performed to study the effect of i) varying DBSCAN parameters, ii) the event accumulation time, iii) the number of robots in the arena, and iv) the speed of the robots on the detection and tracking performance. The experimental results showed 100% detection and tracking fidelity in the face of event camera noise and robots stopping for tests involving up to 3 robots (and upwards of 93% for 4 robots).
Artificial Intelligence Solution for Effective Treatment Planning for Glioblastoma Patients
Mar 09, 2022Glioblastomas are the most common malignant brain tumors in adults. Approximately 200000 people die each year from Glioblastoma in the world. Glioblastoma patients have a median survival of 12 months with optimal therapy and about 4 months without treatment. Glioblastomas appear as heterogeneous necrotic masses with irregular peripheral enhancement, surrounded by vasogenic edema. The current standard of care includes surgical resection, radiotherapy and chemotherapy, which require accurate segmentation of brain tumor subregions. For effective treatment planning, it is vital to identify the methylation status of the promoter of Methylguanine Methyltransferase (MGMT), a positive prognostic factor for chemotherapy. However, current methods for brain tumor segmentation are tedious, subjective and not scalable, and current techniques to determine the methylation status of MGMT promoter involve surgically invasive procedures, which are expensive and time consuming. Hence there is a pressing need to develop automated tools to segment brain tumors and non-invasive methods to predict methylation status of MGMT promoter, to facilitate better treatment planning and improve survival rate. I created an integrated diagnostics solution powered by Artificial Intelligence to automatically segment brain tumor subregions and predict MGMT promoter methylation status, using brain MRI scans. My AI solution is proven on large datasets with performance exceeding current standards and field tested with data from teaching files of local neuroradiologists. With my solution, physicians can submit brain MRI images, and get segmentation and methylation predictions in minutes, and guide brain tumor patients with effective treatment planning and ultimately improve survival time.
ParaPose: Parameter and Domain Randomization Optimization for Pose Estimation using Synthetic Data
Mar 02, 2022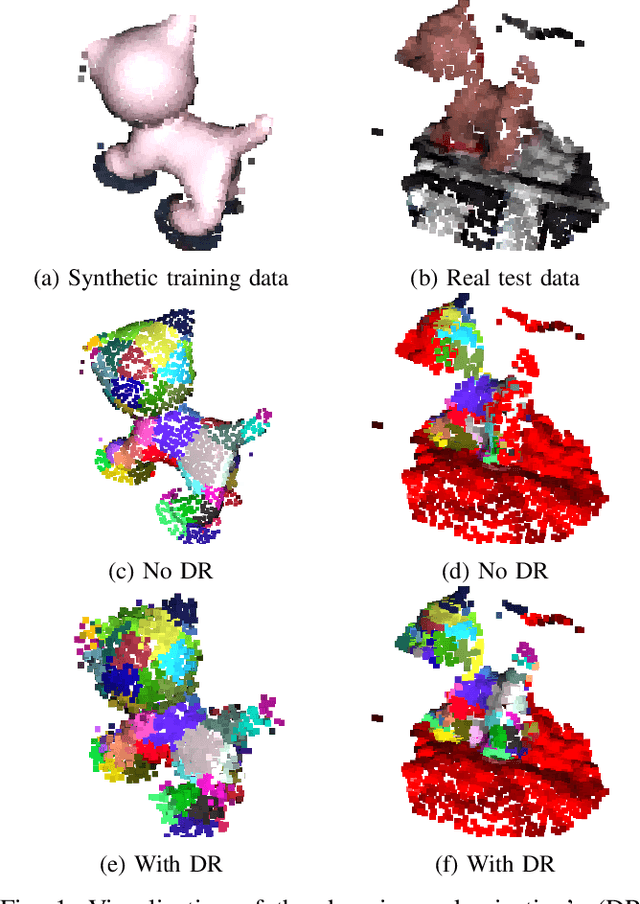
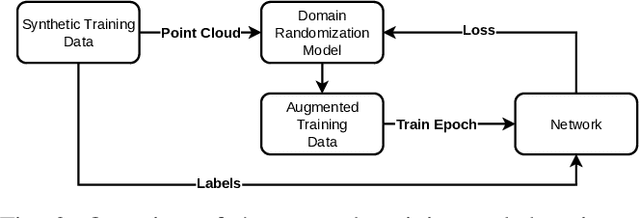
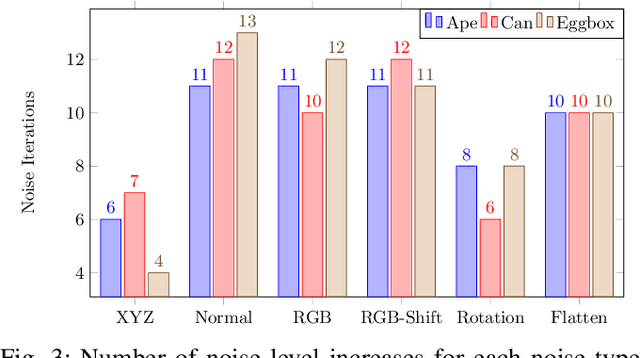
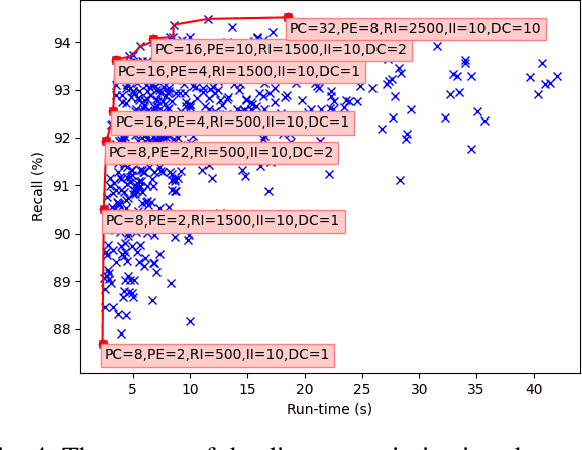
Pose estimation is the task of determining the 6D position of an object in a scene. Pose estimation aid the abilities and flexibility of robotic set-ups. However, the system must be configured towards the use case to perform adequately. This configuration is time-consuming and limits the usability of pose estimation and, thereby, robotic systems. Deep learning is a method to overcome this configuration procedure by learning parameters directly from the dataset. However, obtaining this training data can also be very time-consuming. The use of synthetic training data avoids this data collection problem, but a configuration of the training procedure is necessary to overcome the domain gap problem. Additionally, the pose estimation parameters also need to be configured. This configuration is jokingly known as grad student descent as parameters are manually adjusted until satisfactory results are obtained. This paper presents a method for automatic configuration using only synthetic data. This is accomplished by learning the domain randomization during network training, and then using the domain randomization to optimize the pose estimation parameters. The developed approach shows state-of-the-art performance of 82.0 % recall on the challenging OCCLUSION dataset, outperforming all previous methods with a large margin. These results prove the validity of automatic set-up of pose estimation using purely synthetic data.