 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 01, 2022
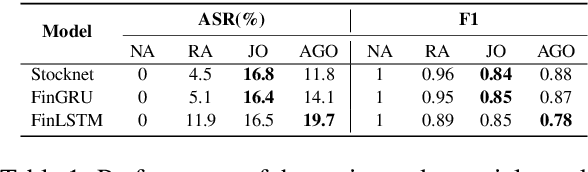
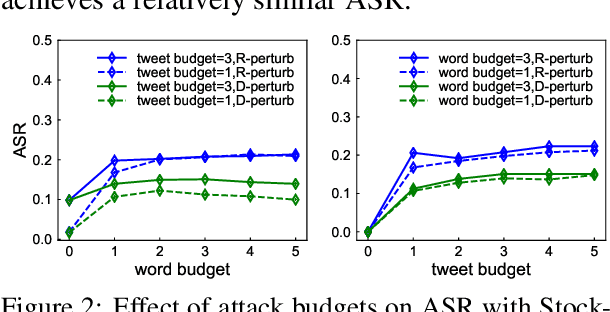
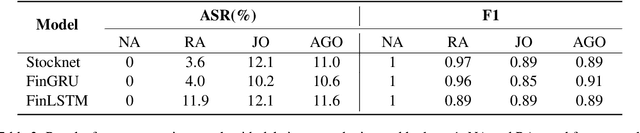
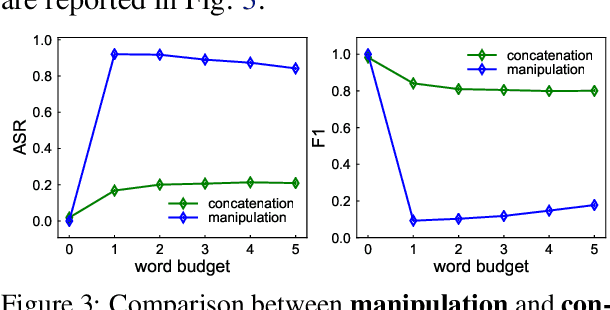
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.
Machine learning-based patient selection in an emergency department
Jun 08, 2022
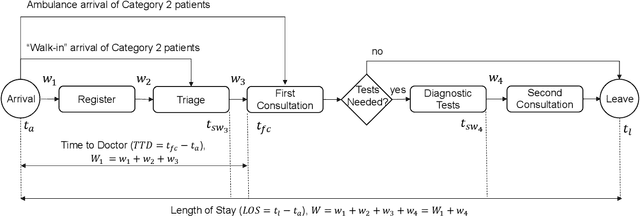
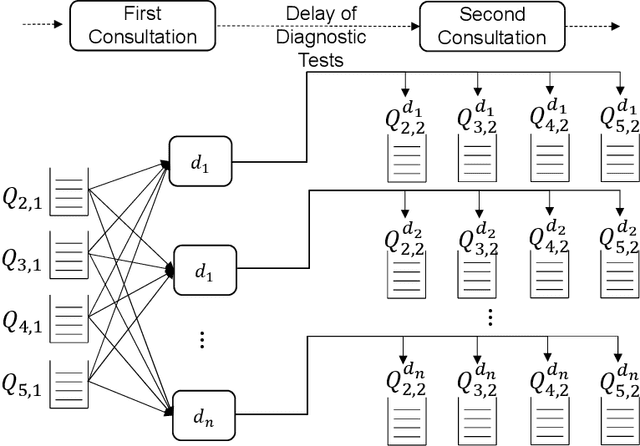
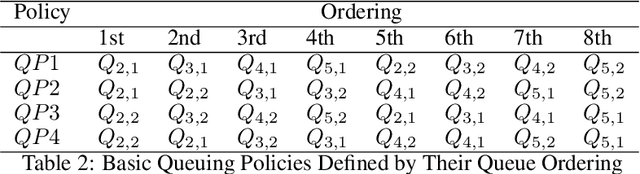
The performance of Emergency Departments (EDs) is of great importance for any health care system, as they serve as the entry point for many patients. However, among other factors, the variability of patient acuity levels and corresponding treatment requirements of patients visiting EDs imposes significant challenges on decision makers. Balancing waiting times of patients to be first seen by a physician with the overall length of stay over all acuity levels is crucial to maintain an acceptable level of operational performance for all patients. To address those requirements when assigning idle resources to patients, several methods have been proposed in the past, including the Accumulated Priority Queuing (APQ) method. The APQ method linearly assigns priority scores to patients with respect to their time in the system and acuity level. Hence, selection decisions are based on a simple system representation that is used as an input for a selection function. This paper investigates the potential of an Machine Learning (ML) based patient selection method. It assumes that for a large set of training data, including a multitude of different system states, (near) optimal assignments can be computed by a (heuristic) optimizer, with respect to a chosen performance metric, and aims to imitate such optimal behavior when applied to new situations. Thereby, it incorporates a comprehensive state representation of the system and a complex non-linear selection function. The motivation for the proposed approach is that high quality selection decisions may depend on a variety of factors describing the current state of the ED, not limited to waiting times, which can be captured and utilized by the ML model. Results show that the proposed method significantly outperforms the APQ method for a majority of evaluated settings
Simulating time to event prediction with spatiotemporal echocardiography deep learning
Mar 03, 2021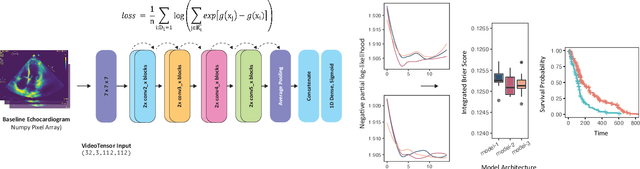
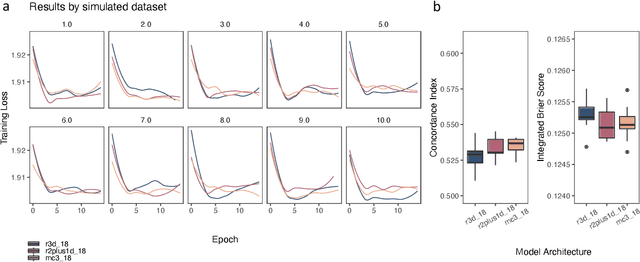
Integrating methods for time-to-event prediction with diagnostic imaging modalities is of considerable interest, as accurate estimates of survival requires accounting for censoring of individuals within the observation period. New methods for time-to-event prediction have been developed by extending the cox-proportional hazards model with neural networks. In this paper, to explore the feasibility of these methods when applied to deep learning with echocardiography videos, we utilize the Stanford EchoNet-Dynamic dataset with over 10,000 echocardiograms, and generate simulated survival datasets based on the expert annotated ejection fraction readings. By training on just the simulated survival outcomes, we show that spatiotemporal convolutional neural networks yield accurate survival estimates.
CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
May 17, 2022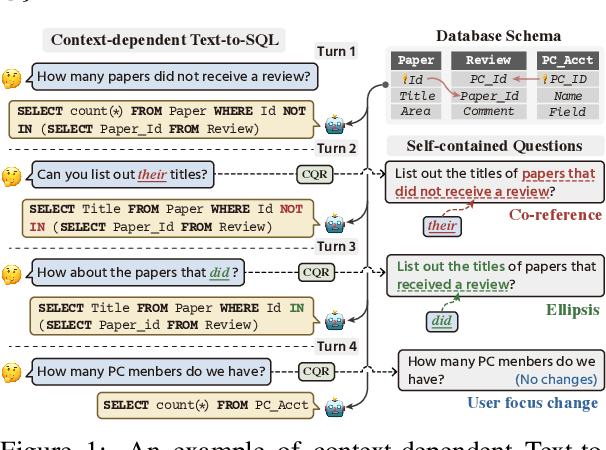

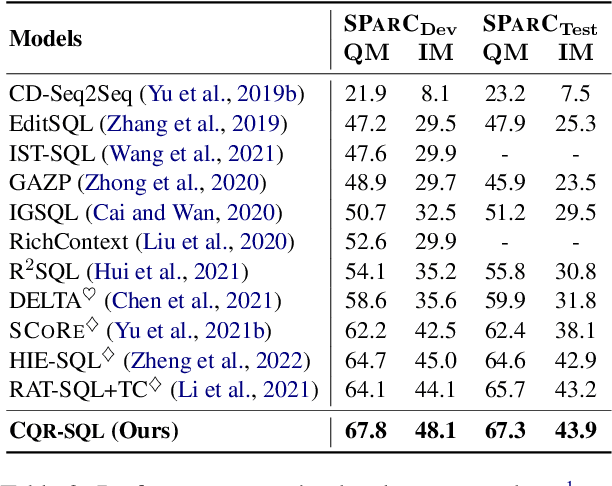
Context-dependent text-to-SQL is the task of translating multi-turn questions into database-related SQL queries. Existing methods typically focus on making full use of history context or previously predicted SQL for currently SQL parsing, while neglecting to explicitly comprehend the schema and conversational dependency, such as co-reference, ellipsis and user focus change. In this paper, we propose CQR-SQL, which uses auxiliary Conversational Question Reformulation (CQR) learning to explicitly exploit schema and decouple contextual dependency for SQL parsing. Specifically, we first present a schema enhanced recursive CQR method to produce domain-relevant self-contained questions. Secondly, we train CQR-SQL models to map the semantics of multi-turn questions and auxiliary self-contained questions into the same latent space through schema grounding consistency task and tree-structured SQL parsing consistency task, which enhances the abilities of SQL parsing by adequately contextual understanding. At the time of writing, our CQR-SQL achieves new state-of-the-art results on two context-dependent text-to-SQL benchmarks SParC and CoSQL.
License Plate Privacy in Collaborative Visual Analysis of Traffic Scenes
May 03, 2022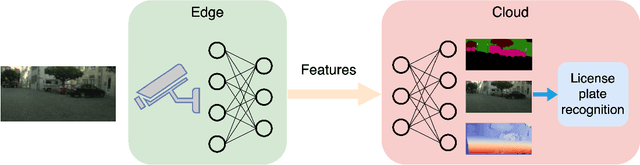
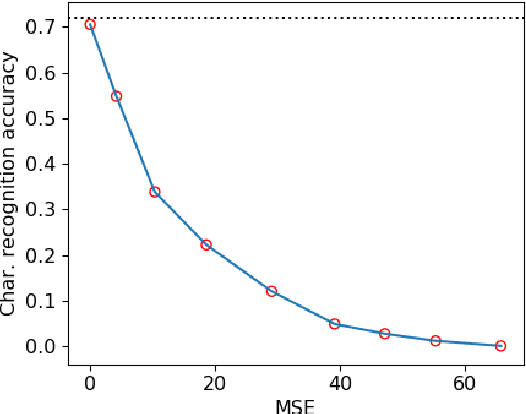
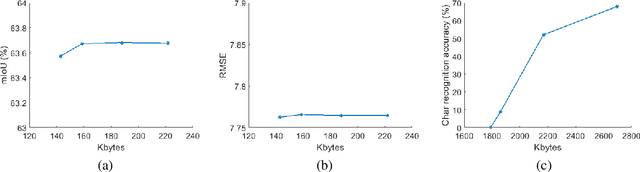

Traffic scene analysis is important for emerging technologies such as smart traffic management and autonomous vehicles. However, such analysis also poses potential privacy threats. For example, a system that can recognize license plates may construct patterns of behavior of the corresponding vehicles' owners and use that for various illegal purposes. In this paper we present a system that enables traffic scene analysis while at the same time preserving license plate privacy. The system is based on a multi-task model whose latent space is selectively compressed depending on the amount of information the specific features carry about analysis tasks and private information. Effectiveness of the proposed method is illustrated by experiments on the Cityscapes dataset, for which we also provide license plate annotations.
Learning to Control Direct Current Motor for Steering in Real Time via Reinforcement Learning
Jul 31, 2021
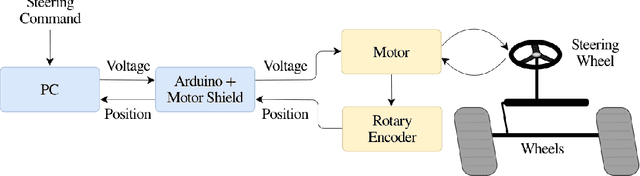
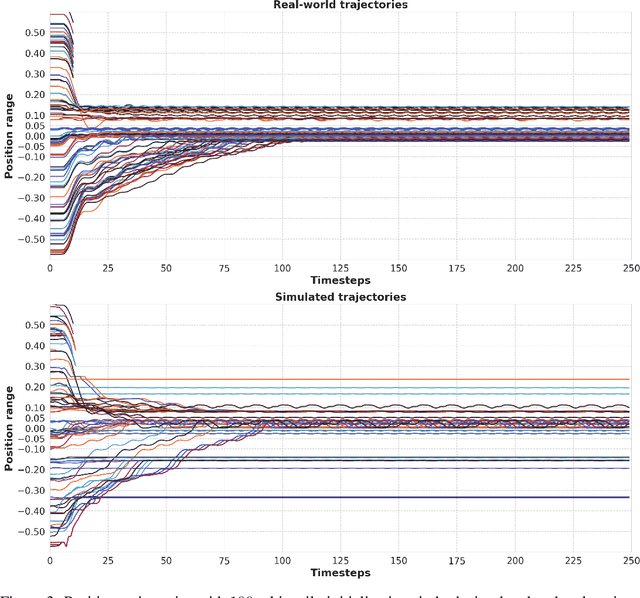
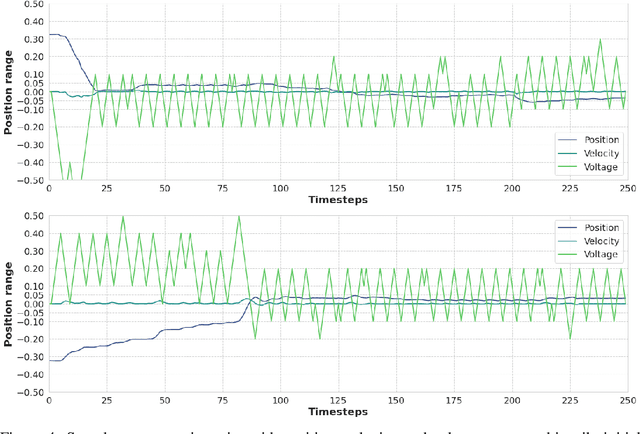
Model free techniques have been successful at optimal control of complex systems at an expense of copious amounts of data and computation. However, it is often desired to obtain a control policy in a short period of time with minimal data use and computational burden. To this end, we make use of the NFQ algorithm for steering position control of a golf cart in both a real hardware and a simulated environment that was built from real-world interaction. The controller learns to apply a sequence of voltage signals in the presence of environmental uncertainties and inherent non-linearities that challenge the the control task. We were able to increase the rate of successful control under four minutes in simulation and under 11 minutes in real hardware.
Accelerated Policy Learning with Parallel Differentiable Simulation
Apr 14, 2022
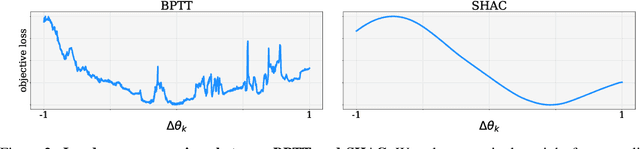
Deep reinforcement learning can generate complex control policies, but requires large amounts of training data to work effectively. Recent work has attempted to address this issue by leveraging differentiable simulators. However, inherent problems such as local minima and exploding/vanishing numerical gradients prevent these methods from being generally applied to control tasks with complex contact-rich dynamics, such as humanoid locomotion in classical RL benchmarks. In this work we present a high-performance differentiable simulator and a new policy learning algorithm (SHAC) that can effectively leverage simulation gradients, even in the presence of non-smoothness. Our learning algorithm alleviates problems with local minima through a smooth critic function, avoids vanishing/exploding gradients through a truncated learning window, and allows many physical environments to be run in parallel. We evaluate our method on classical RL control tasks, and show substantial improvements in sample efficiency and wall-clock time over state-of-the-art RL and differentiable simulation-based algorithms. In addition, we demonstrate the scalability of our method by applying it to the challenging high-dimensional problem of muscle-actuated locomotion with a large action space, achieving a greater than 17x reduction in training time over the best-performing established RL algorithm.
Emulating Quantum Dynamics with Neural Networks via Knowledge Distillation
Mar 19, 2022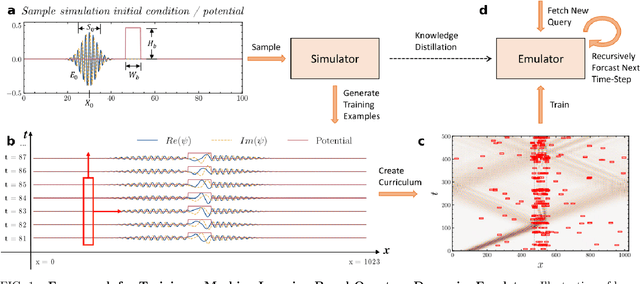
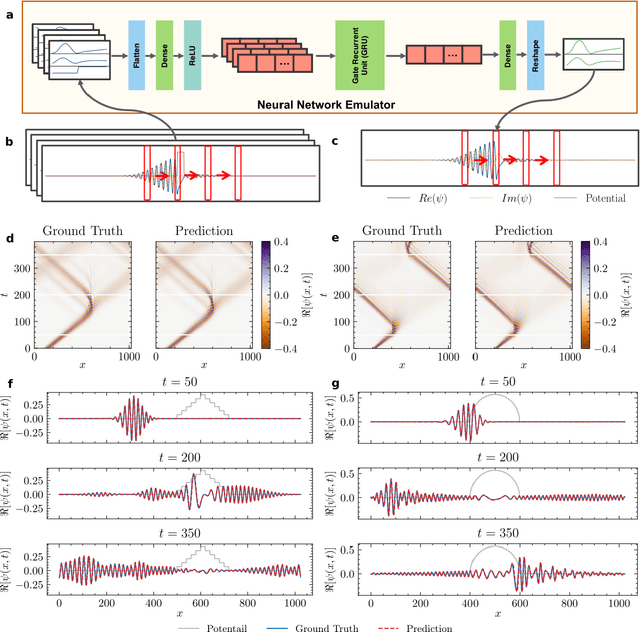
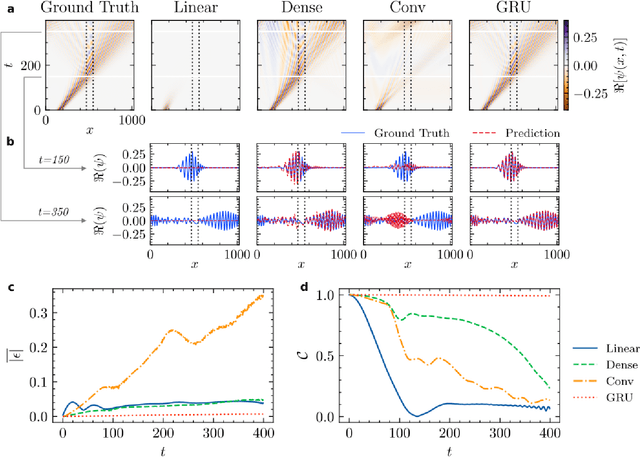
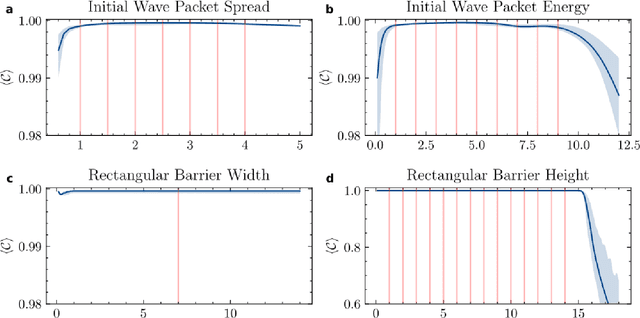
High-fidelity quantum dynamics emulators can be used to predict the time evolution of complex physical systems. Here, we introduce an efficient training framework for constructing machine learning-based emulators. Our approach is based on the idea of knowledge distillation and uses elements of curriculum learning. It works by constructing a set of simple, but rich-in-physics training examples (a curriculum). These examples are used by the emulator to learn the general rules describing the time evolution of a quantum system (knowledge distillation). The goal is not only to obtain high-quality predictions, but also to examine the process of how the emulator learns the physics of the underlying problem. This allows us to discover new facts about the physical system, detect symmetries, and measure relative importance of the contributing physical processes. We illustrate this approach by training an artificial neural network to predict the time evolution of quantum wave packages propagating through a potential landscape. We focus on the question of how the emulator learns the rules of quantum dynamics from the curriculum of simple training examples and to which extent it can generalize the acquired knowledge to solve more challenging cases.
Reward Uncertainty for Exploration in Preference-based Reinforcement Learning
May 24, 2022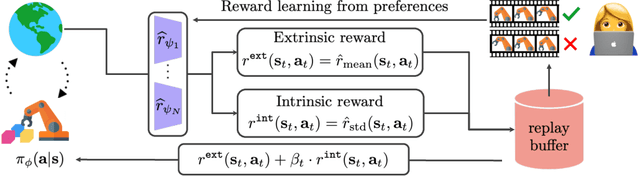



Conveying complex objectives to reinforcement learning (RL) agents often requires meticulous reward engineering. Preference-based RL methods are able to learn a more flexible reward model based on human preferences by actively incorporating human feedback, i.e. teacher's preferences between two clips of behaviors. However, poor feedback-efficiency still remains a problem in current preference-based RL algorithms, as tailored human feedback is very expensive. To handle this issue, previous methods have mainly focused on improving query selection and policy initialization. At the same time, recent exploration methods have proven to be a recipe for improving sample-efficiency in RL. We present an exploration method specifically for preference-based RL algorithms. Our main idea is to design an intrinsic reward by measuring the novelty based on learned reward. Specifically, we utilize disagreement across ensemble of learned reward models. Our intuition is that disagreement in learned reward model reflects uncertainty in tailored human feedback and could be useful for exploration. Our experiments show that exploration bonus from uncertainty in learned reward improves both feedback- and sample-efficiency of preference-based RL algorithms on complex robot manipulation tasks from MetaWorld benchmarks, compared with other existing exploration methods that measure the novelty of state visitation.
Towards a Real-time Measure of the Perception of Anthropomorphism in Human-robot Interaction
Jan 24, 2022
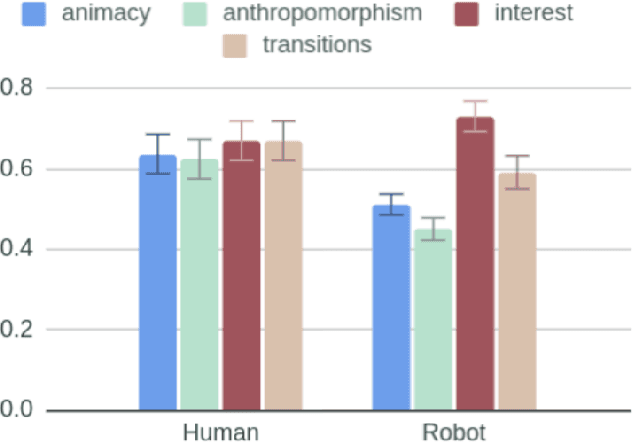
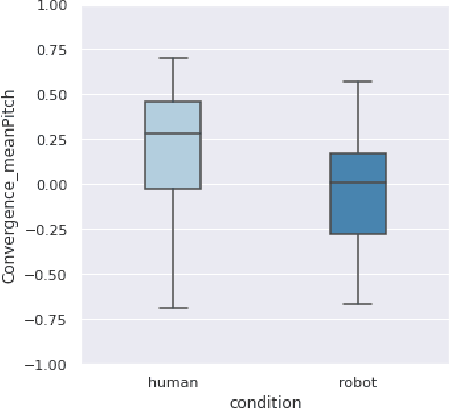
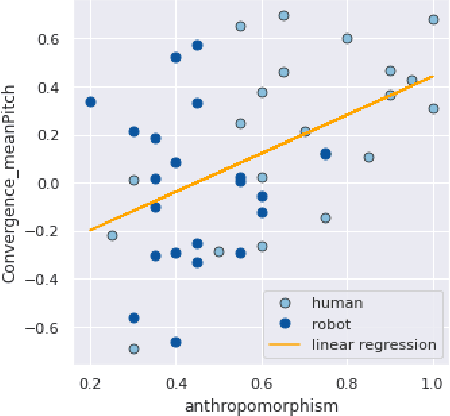
How human-like do conversational robots need to look to enable long-term human-robot conversation? One essential aspect of long-term interaction is a human's ability to adapt to the varying degrees of a conversational partner's engagement and emotions. Prosodically, this can be achieved through (dis)entrainment. While speech-synthesis has been a limiting factor for many years, restrictions in this regard are increasingly mitigated. These advancements now emphasise the importance of studying the effect of robot embodiment on human entrainment. In this study, we conducted a between-subjects online human-robot interaction experiment in an educational use-case scenario where a tutor was either embodied through a human or a robot face. 43 English-speaking participants took part in the study for whom we analysed the degree of acoustic-prosodic entrainment to the human or robot face, respectively. We found that the degree of subjective and objective perception of anthropomorphism positively correlates with acoustic-prosodic entrainment.