 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Foundation Model for Multimodal Histopathology
Apr 04, 2026Accurate diagnosis and treatment of complex diseases require integrating histological, molecular, and clinical data, yet in practice these modalities are often incomplete owing to tissue scarcity, assay cost, and workflow constraints. Existing computational approaches attempt to impute missing modalities from available data but rely on task-specific models trained on narrow, single source-target pairs, limiting their generalizability. Here we introduce MuPD (Multimodal Pathology Diffusion), a generative foundation model that embeds hematoxylin and eosin (H&E)-stained histology, molecular RNA profiles, and clinical text into a shared latent space through a diffusion transformer with decoupled cross-modal attention. Pretrained on 100 million histology image patches, 1.6 million text-histology pairs, and 10.8 million RNA-histology pairs spanning 34 human organs, MuPD supports diverse cross-modal synthesis tasks with minimal or no task-specific fine-tuning. For text-conditioned and image-to-image generation, MuPD synthesizes histologically faithful tissue architectures, reducing Fréchet inception distance (FID) scores by 50% relative to domain-specific models and improving few-shot classification accuracy by up to 47% through synthetic data augmentation. For RNA-conditioned histology generation, MuPD reduces FID by 23% compared with the next-best method while preserving cell-type distributions across five cancer types. As a virtual stainer, MuPD translates H&E images to immunohistochemistry and multiplex immunofluorescence, improving average marker correlation by 37% over existing approaches. These results demonstrate that a single, unified generative model pretrained across heterogeneous pathology modalities can substantially outperform specialized alternatives, providing a scalable computational framework for multimodal histopathology.
A Reasoning-Enabled Vision-Language Foundation Model for Chest X-ray Interpretation
Apr 01, 2026Chest X-rays (CXRs) are among the most frequently performed imaging examinations worldwide, yet rising imaging volumes increase radiologist workload and the risk of diagnostic errors. Although artificial intelligence (AI) systems have shown promise for CXR interpretation, most generate only final predictions, without making explicit how visual evidence is translated into radiographic findings and diagnostic predictions. We present CheXOne, a reasoning-enabled vision-language model for CXR interpretation. CheXOne jointly generates diagnostic predictions and explicit, clinically grounded reasoning traces that connect visual evidence, radiographic findings, and these predictions. The model is trained on 14.7 million instruction and reasoning samples curated from 30 public datasets spanning 36 CXR interpretation tasks, using a two-stage framework that combines instruction tuning with reinforcement learning to improve reasoning quality. We evaluate CheXOne in zero-shot settings across visual question answering, report generation, visual grounding and reasoning assessment, covering 17 evaluation settings. CheXOne outperforms existing medical and general-domain foundation models and achieves strong performance on independent public benchmarks. A clinical reader study demonstrates that CheXOne-drafted reports are comparable to or better than resident-written reports in 55% of cases, while effectively addressing clinical indications and enhancing both report writing and CXR interpretation efficiency. Further analyses involving radiologists reveal that the generated reasoning traces show high clinical factuality and provide causal support for the final predictions, offering a plausible explanation for the performance gains. These results suggest that explicit reasoning can improve model performance, interpretability and clinical utility in AI-assisted CXR interpretation.
A data- and compute-efficient chest X-ray foundation model beyond aggressive scaling
Feb 26, 2026Foundation models for medical imaging are typically pretrained on increasingly large datasets, following a "scale-at-all-costs" paradigm. However, this strategy faces two critical challenges: large-scale medical datasets often contain substantial redundancy and severe class imbalance that bias representation learning toward over-represented patterns, and indiscriminate training regardless of heterogeneity in data quality incurs considerable computational inefficiency. Here we demonstrate that active, principled data curation during pretraining can serve as a viable, cost-effective alternative to brute-force dataset enlargement. We introduce CheXficient, a chest X-ray (CXR) foundation model that selectively prioritizes informative training samples. CheXficient is pretrained on only 22.7% of 1,235,004 paired CXR images and reports while consuming under 27.3% of the total compute budget, yet achieving comparable or superior performance to its full-data counterpart and other large-scale pretrained models. We assess CheXficient across 20 individual benchmarks spanning 5 task types, including non-adapted off-the-shelf evaluations (zero-shot findings classification and crossmodal retrieval) and adapted downstream tasks (disease prediction, semantic segmentation, and radiology report generation). Further analyses show that CheXficient systematically prioritizes under-represented training samples, improving generalizability on long-tailed or rare conditions. Overall, our work offers practical insights into the data and computation demands for efficient pretraining and downstream adaptation of medical vision-language foundation models.
Agentic Systems in Radiology: Design, Applications, Evaluation, and Challenges
Oct 10, 2025Building agents, systems that perceive and act upon their environment with a degree of autonomy, has long been a focus of AI research. This pursuit has recently become vastly more practical with the emergence of large language models (LLMs) capable of using natural language to integrate information, follow instructions, and perform forms of "reasoning" and planning across a wide range of tasks. With its multimodal data streams and orchestrated workflows spanning multiple systems, radiology is uniquely suited to benefit from agents that can adapt to context and automate repetitive yet complex tasks. In radiology, LLMs and their multimodal variants have already demonstrated promising performance for individual tasks such as information extraction and report summarization. However, using LLMs in isolation underutilizes their potential to support complex, multi-step workflows where decisions depend on evolving context from multiple information sources. Equipping LLMs with external tools and feedback mechanisms enables them to drive systems that exhibit a spectrum of autonomy, ranging from semi-automated workflows to more adaptive agents capable of managing complex processes. This review examines the design of such LLM-driven agentic systems, highlights key applications, discusses evaluation methods for planning and tool use, and outlines challenges such as error cascades, tool-use efficiency, and health IT integration.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats
Jun 03, 2024



Since the release of the original CheXpert paper five years ago, CheXpert has become one of the most widely used and cited clinical AI datasets. The emergence of vision language models has sparked an increase in demands for sharing reports linked to CheXpert images, along with a growing interest among AI fairness researchers in obtaining demographic data. To address this, CheXpert Plus serves as a new collection of radiology data sources, made publicly available to enhance the scaling, performance, robustness, and fairness of models for all subsequent machine learning tasks in the field of radiology. CheXpert Plus is the largest text dataset publicly released in radiology, with a total of 36 million text tokens, including 13 million impression tokens. To the best of our knowledge, it represents the largest text de-identification effort in radiology, with almost 1 million PHI spans anonymized. It is only the second time that a large-scale English paired dataset has been released in radiology, thereby enabling, for the first time, cross-institution training at scale. All reports are paired with high-quality images in DICOM format, along with numerous image and patient metadata covering various clinical and socio-economic groups, as well as many pathology labels and RadGraph annotations. We hope this dataset will boost research for AI models that can further assist radiologists and help improve medical care. Data is available at the following URL: https://stanfordaimi.azurewebsites.net/datasets/5158c524-d3ab-4e02-96e9-6ee9efc110a1 Models are available at the following URL: https://github.com/Stanford-AIMI/chexpert-plus
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024



The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis
Nov 17, 2023



Synthesizing information from multiple data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of patients at risk for pulmonary embolism (PE), along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, radiology report impression sections, and structured electronic health record (EHR) data (i.e. demographics, diagnoses, procedures, vitals, and medications). Using INSPECT, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and multimodal fusion models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best of our knowledge, INSPECT is the largest multimodal dataset integrating 3D medical imaging and EHR for reproducible methods evaluation and research.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.
RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
May 02, 2023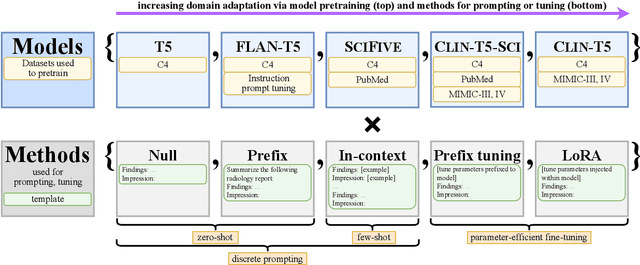
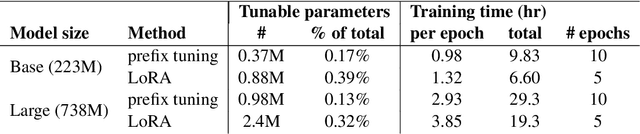
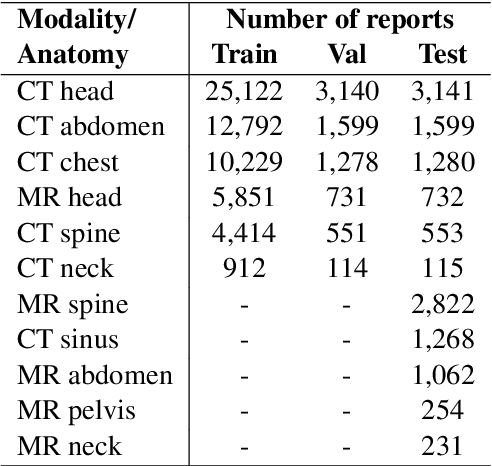

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.