 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Evidence is Sparse: Weakly Supervised Early Failure Alerting in Dialogs and LLM-Agent Trajectories
Jun 03, 2026Early failure alerting requires deciding, while a dialog or agent trajectory is still unfolding, whether to flag it as likely to fail. This is challenging because supervision is typically available only as a trajectory-level success/failure label while alerts must be raised from partial interactions. Prior early-classification methods often bridge this gap by assigning the terminal label to every prefix, treating every turn as failure evidence. We hypothesize that this prefix-label assumption is poorly matched to multi-turn language interactions, where evidence of eventual failure is sparse and often delayed. In this paper, we introduce a two-stage approach that learns from this sparse evidence structure and uses the resulting risk estimates for controllable early alerting. Specifically, our attention-based failure predictor learns sparse turn-level failure evidence from trajectory labels and uses it to estimate failure risk from partial histories. We then pair this predictor with $α$-STOP, a single preference-conditioned stopping policy that selects an accuracy-earliness operating point at inference time rather than training a separate trigger for each preference. Across five benchmarks spanning customer support, task-oriented dialog, persuasion, tool use, and planning, we first show that high-relevance failure evidence occupies only 4.7-11.3% of turns and first appears after 59.0-83.6\% of trajectories on average. We further show that the attention-based predictor improves Pareto-frontier quality (hypervolume) by 1-10\% over naive prefix supervision, and that the full system improves frontier quality by 3-42\% over state-of-the-art trigger policies while reducing training cost per operating point by 1-3 orders of magnitude.
Personalized Generative Models for Contextual Debiasing
May 25, 2026Different visual patterns appear with different frequencies in the world: e.g., beach balls appear on sand more often than they do on a road. These statistics are reflected in vision datasets, and as a result trained models more easily recognize objects in common scenarios. However, recognizing a beach ball on a road may arguably be even more important than recognizing it on sand. We study how to mitigate this discrepancy. Since collecting uncommon images in the real world may be difficult, we explore whether generating images with less frequent contexts can serve as effective training augmentation. A key challenge is guiding generations to remain close to the original dataset distribution while creating diverse images with uncommon contexts. We introduce Decoupling Contextual Patterns with Generations (DecoupleGen), a method that personalizes text-to-image diffusion models to facilitate coherent synthesis of images with rare contexts while preserving original visual details. The generated images contain semantically meaningful content and remain visually aligned with the original datasets. We further apply verification constraints to ensure relevance of the augmented data. We evaluate our approach on object classification and recognition tasks on complex scene datasets. Our experiments demonstrate consistent improvements over previous approaches, and our analyses identify factors underlying these improvements.
IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Dec 17, 2025



We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.
ALP: Action-Aware Embodied Learning for Perception
Jun 16, 2023



Current methods in training and benchmarking vision models exhibit an over-reliance on passive, curated datasets. Although models trained on these datasets have shown strong performance in a wide variety of tasks such as classification, detection, and segmentation, they fundamentally are unable to generalize to an ever-evolving world due to constant out-of-distribution shifts of input data. Therefore, instead of training on fixed datasets, can we approach learning in a more human-centric and adaptive manner? In this paper, we introduce \textbf{A}ction-aware Embodied \textbf{L}earning for \textbf{P}erception (ALP), an embodied learning framework that incorporates action information into representation learning through a combination of optimizing policy gradients through reinforcement learning and inverse dynamics prediction objectives. Our method actively explores complex 3D environments to both learn generalizable task-agnostic representations as well as collect downstream training data. We show that ALP outperforms existing baselines in object detection and semantic segmentation. In addition, we show that by training on actively collected data more relevant to the environment and task, our method generalizes more robustly to downstream tasks compared to models pre-trained on fixed datasets such as ImageNet.
Reward Uncertainty for Exploration in Preference-based Reinforcement Learning
May 24, 2022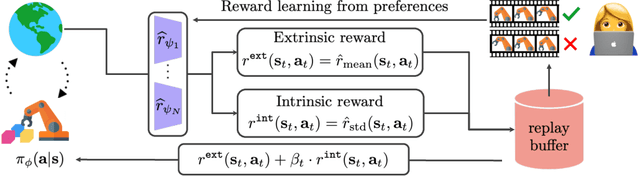



Conveying complex objectives to reinforcement learning (RL) agents often requires meticulous reward engineering. Preference-based RL methods are able to learn a more flexible reward model based on human preferences by actively incorporating human feedback, i.e. teacher's preferences between two clips of behaviors. However, poor feedback-efficiency still remains a problem in current preference-based RL algorithms, as tailored human feedback is very expensive. To handle this issue, previous methods have mainly focused on improving query selection and policy initialization. At the same time, recent exploration methods have proven to be a recipe for improving sample-efficiency in RL. We present an exploration method specifically for preference-based RL algorithms. Our main idea is to design an intrinsic reward by measuring the novelty based on learned reward. Specifically, we utilize disagreement across ensemble of learned reward models. Our intuition is that disagreement in learned reward model reflects uncertainty in tailored human feedback and could be useful for exploration. Our experiments show that exploration bonus from uncertainty in learned reward improves both feedback- and sample-efficiency of preference-based RL algorithms on complex robot manipulation tasks from MetaWorld benchmarks, compared with other existing exploration methods that measure the novelty of state visitation.