 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPPO: Contrastive Perception for Vision Language Policy Optimization
Jan 01, 2026We introduce CPPO, a Contrastive Perception Policy Optimization method for finetuning vision-language models (VLMs). While reinforcement learning (RL) has advanced reasoning in language models, extending it to multimodal reasoning requires improving both the perception and reasoning aspects. Prior works tackle this challenge mainly with explicit perception rewards, but disentangling perception tokens from reasoning tokens is difficult, requiring extra LLMs, ground-truth data, forced separation of perception from reasoning by policy model, or applying rewards indiscriminately to all output tokens. CPPO addresses this problem by detecting perception tokens via entropy shifts in the model outputs under perturbed input images. CPPO then extends the RL objective function with a Contrastive Perception Loss (CPL) that enforces consistency under information-preserving perturbations and sensitivity under information-removing ones. Experiments show that CPPO surpasses previous perception-rewarding methods, while avoiding extra models, making training more efficient and scalable.
DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models
Mar 04, 2025



Large Multimodal Models (LMMs) have emerged as powerful models capable of understanding various data modalities, including text, images, and videos. LMMs encode both text and visual data into tokens that are then combined and processed by an integrated Large Language Model (LLM). Including visual tokens substantially increases the total token count, often by thousands. The increased input length for LLM significantly raises the complexity of inference, resulting in high latency in LMMs. To address this issue, token pruning methods, which remove part of the visual tokens, are proposed. The existing token pruning methods either require extensive calibration and fine-tuning or rely on suboptimal importance metrics which results in increased redundancy among the retained tokens. In this paper, we first formulate token pruning as Max-Min Diversity Problem (MMDP) where the goal is to select a subset such that the diversity among the selected {tokens} is maximized. Then, we solve the MMDP to obtain the selected subset and prune the rest. The proposed method, DivPrune, reduces redundancy and achieves the highest diversity of the selected tokens. By ensuring high diversity, the selected tokens better represent the original tokens, enabling effective performance even at high pruning ratios without requiring fine-tuning. Extensive experiments with various LMMs show that DivPrune achieves state-of-the-art accuracy over 16 image- and video-language datasets. Additionally, DivPrune reduces both the end-to-end latency and GPU memory usage for the tested models. The code is available $\href{https://github.com/vbdi/divprune}{\text{here}}$.
LaWa: Using Latent Space for In-Generation Image Watermarking
Aug 11, 2024



With generative models producing high quality images that are indistinguishable from real ones, there is growing concern regarding the malicious usage of AI-generated images. Imperceptible image watermarking is one viable solution towards such concerns. Prior watermarking methods map the image to a latent space for adding the watermark. Moreover, Latent Diffusion Models (LDM) generate the image in the latent space of a pre-trained autoencoder. We argue that this latent space can be used to integrate watermarking into the generation process. To this end, we present LaWa, an in-generation image watermarking method designed for LDMs. By using coarse-to-fine watermark embedding modules, LaWa modifies the latent space of pre-trained autoencoders and achieves high robustness against a wide range of image transformations while preserving perceptual quality of the image. We show that LaWa can also be used as a general image watermarking method. Through extensive experiments, we demonstrate that LaWa outperforms previous works in perceptual quality, robustness against attacks, and computational complexity, while having very low false positive rate. Code is available here.
Compressive Feature Selection for Remote Visual Multi-Task Inference
May 15, 2024



Deep models produce a number of features in each internal layer. A key problem in applications such as feature compression for remote inference is determining how important each feature is for the task(s) performed by the model. The problem is especially challenging in the case of multi-task inference, where the same feature may carry different importance for different tasks. In this paper, we examine how effective is mutual information (MI) between a feature and a model's task output as a measure of the feature's importance for that task. Experiments involving hard selection and soft selection (unequal compression) based on MI are carried out to compare the MI-based method with alternative approaches. Multi-objective analysis is provided to offer further insight.
ArchBERT: Bi-Modal Understanding of Neural Architectures and Natural Languages
Oct 26, 2023



Building multi-modal language models has been a trend in the recent years, where additional modalities such as image, video, speech, etc. are jointly learned along with natural languages (i.e., textual information). Despite the success of these multi-modal language models with different modalities, there is no existing solution for neural network architectures and natural languages. Providing neural architectural information as a new modality allows us to provide fast architecture-2-text and text-2-architecture retrieval/generation services on the cloud with a single inference. Such solution is valuable in terms of helping beginner and intermediate ML users to come up with better neural architectures or AutoML approaches with a simple text query. In this paper, we propose ArchBERT, a bi-modal model for joint learning and understanding of neural architectures and natural languages, which opens up new avenues for research in this area. We also introduce a pre-training strategy named Masked Architecture Modeling (MAM) for a more generalized joint learning. Moreover, we introduce and publicly release two new bi-modal datasets for training and validating our methods. The ArchBERT's performance is verified through a set of numerical experiments on different downstream tasks such as architecture-oriented reasoning, question answering, and captioning (summarization). Datasets, codes, and demos are available supplementary materials.
Joint Image Compression and Denoising via Latent-Space Scalability
May 04, 2022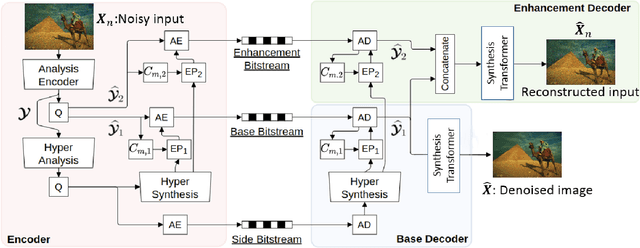
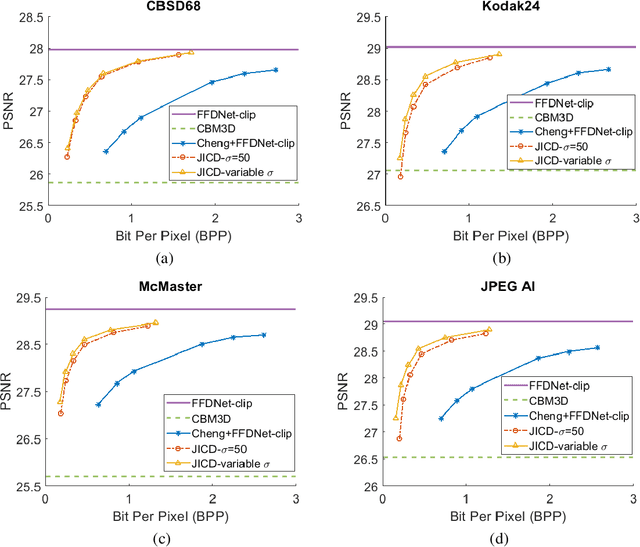
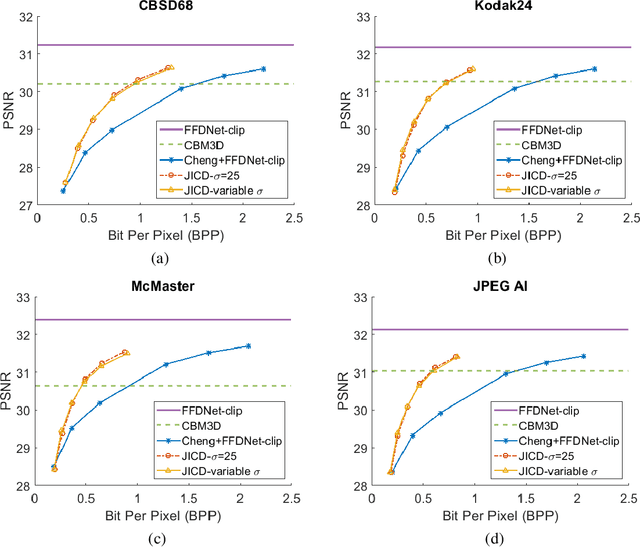
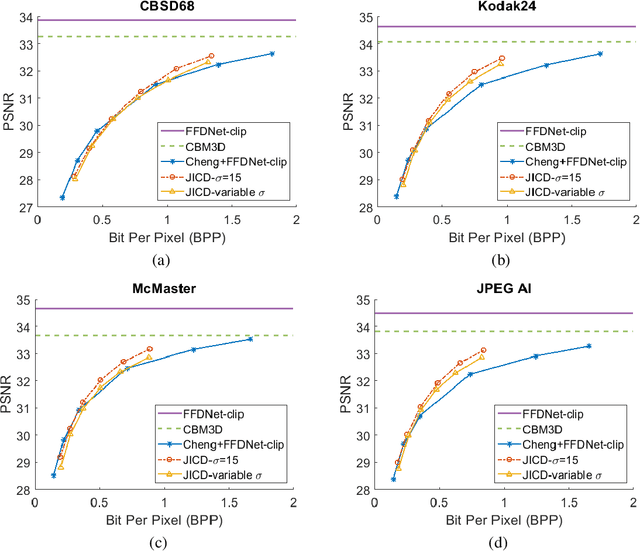
When it comes to image compression in digital cameras, denoising is traditionally performed prior to compression. However, there are applications where image noise may be necessary to demonstrate the trustworthiness of the image, such as court evidence and image forensics. This means that noise itself needs to be coded, in addition to the clean image itself. In this paper, we present a learnt image compression framework where image denoising and compression are performed jointly. The latent space of the image codec is organized in a scalable manner such that the clean image can be decoded from a subset of the latent space at a lower rate, while the noisy image is decoded from the full latent space at a higher rate. The proposed codec is compared against established compression and denoising benchmarks, and the experiments reveal considerable bitrate savings of up to 80% compared to cascade compression and denoising.
License Plate Privacy in Collaborative Visual Analysis of Traffic Scenes
May 03, 2022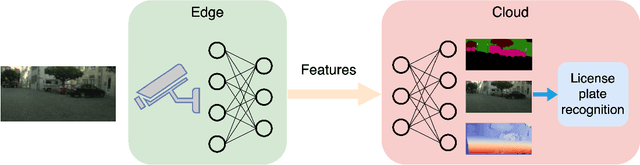
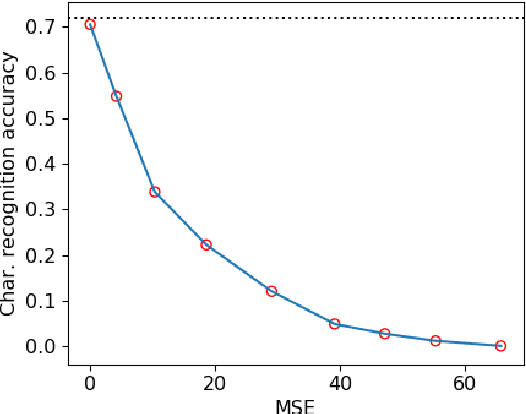
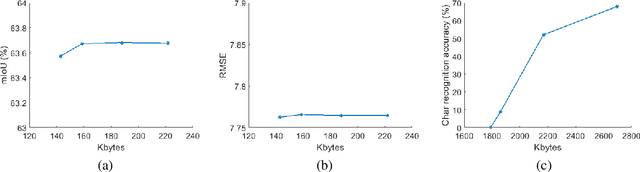

Traffic scene analysis is important for emerging technologies such as smart traffic management and autonomous vehicles. However, such analysis also poses potential privacy threats. For example, a system that can recognize license plates may construct patterns of behavior of the corresponding vehicles' owners and use that for various illegal purposes. In this paper we present a system that enables traffic scene analysis while at the same time preserving license plate privacy. The system is based on a multi-task model whose latent space is selectively compressed depending on the amount of information the specific features carry about analysis tasks and private information. Effectiveness of the proposed method is illustrated by experiments on the Cityscapes dataset, for which we also provide license plate annotations.
Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Mar 10, 2022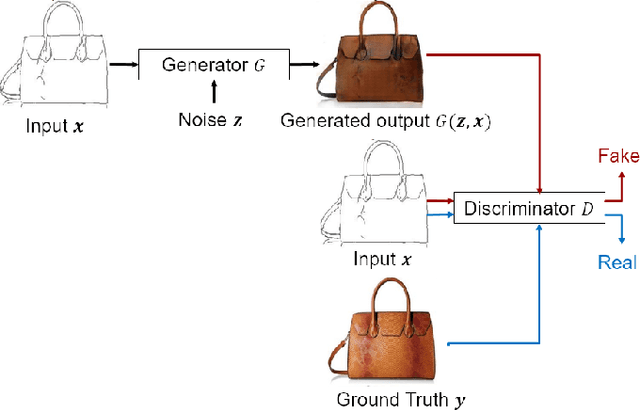
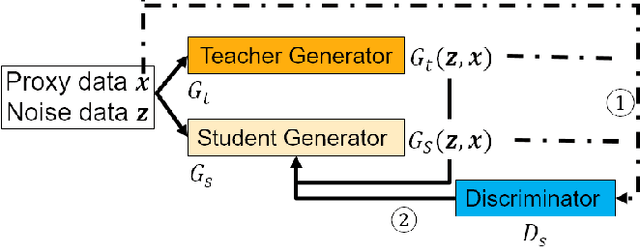
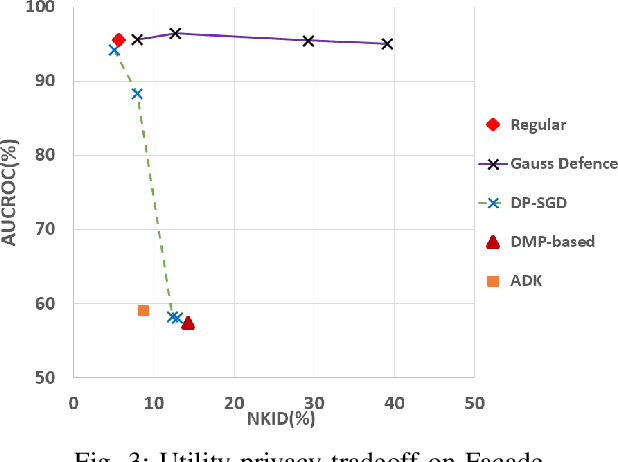
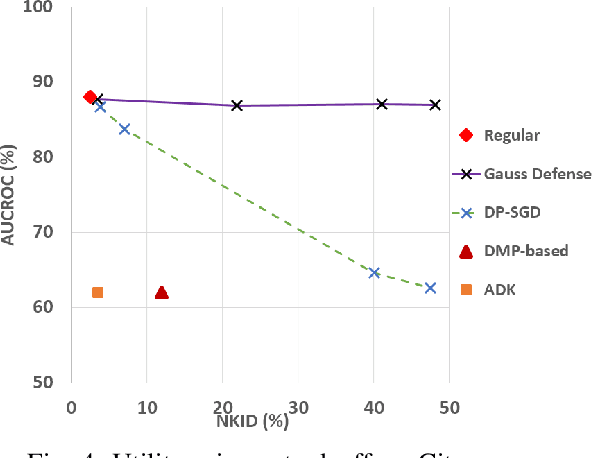
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.
Practical Noise Simulation for RGB Images
Jan 30, 2022This document describes a noise generator that simulates realistic noise found in smartphone cameras. The generator simulates Poissonian-Gaussian noise whose parameters have been estimated on the Smartphone Image Denoising Dataset (SIDD). The generator is available online, and is currently being used in compressed-domain denoising exploration experiments in JPEG AI.
Pareto-Optimal Bit Allocation for Collaborative Intelligence
Sep 25, 2020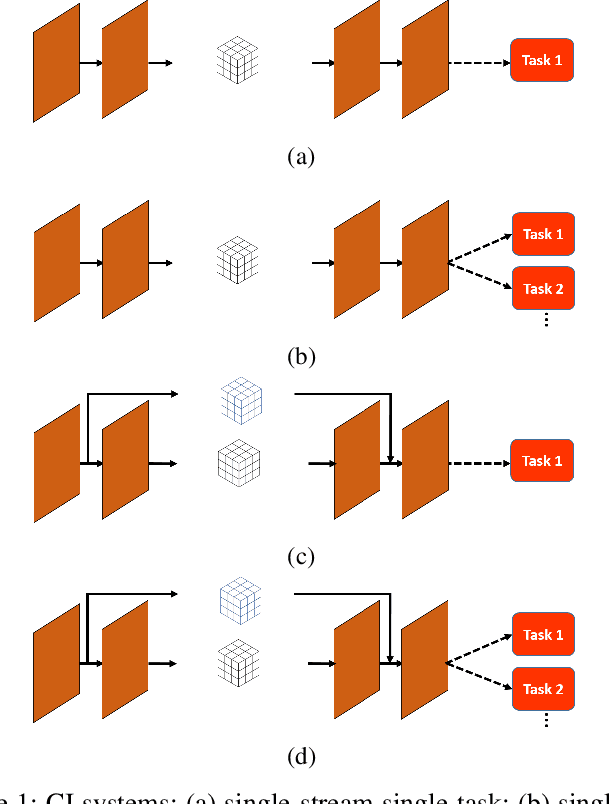
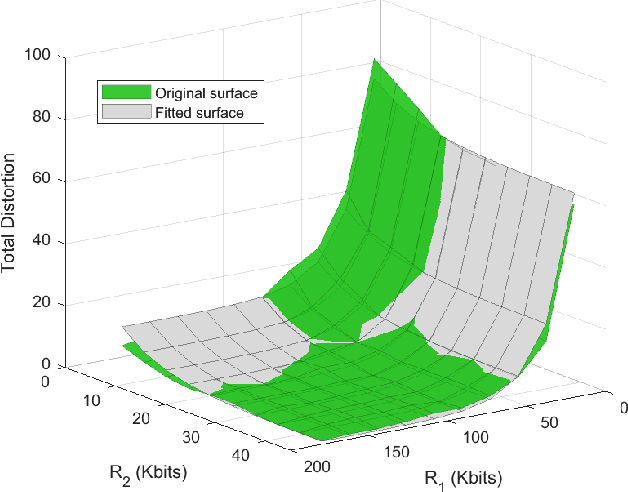
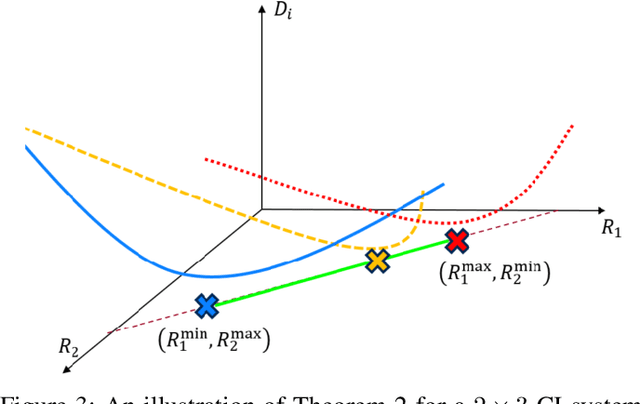
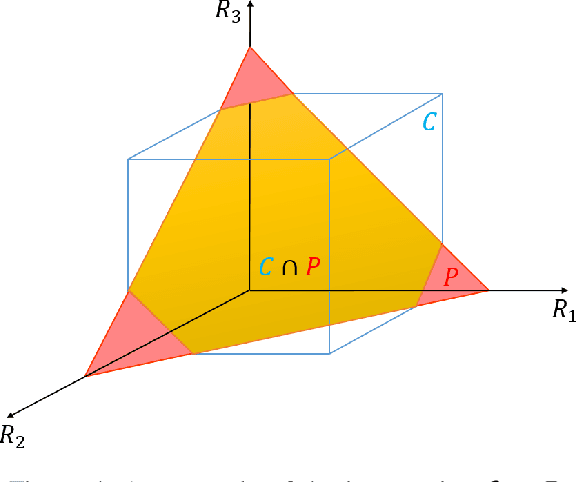
In recent studies, collaborative intelligence (CI) has emerged as a promising framework for deployment of Artificial Intelligence (AI)-based services on mobile/edge devices. In CI, the AI model (a deep neural network) is split between the edge and the cloud, and intermediate features are sent from the edge sub-model to the cloud sub-model. In this paper, we study bit allocation for feature coding in multi-stream CI systems. We model task distortion as a function of rate using convex surfaces similar to those found in distortion-rate theory. Using such models, we are able to provide closed-form bit allocation solutions for single-task systems and scalarized multi-task systems. Moreover, we provide analytical characterization of the full Pareto set for 2-stream k-task systems, and bounds on the Pareto set for 3-stream 2-task systems. Analytical results are examined on a variety of DNN models from the literature to demonstrate wide applicability of the results