 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rank-One Prior: Toward Real-Time Scene Recovery
Mar 31, 2021


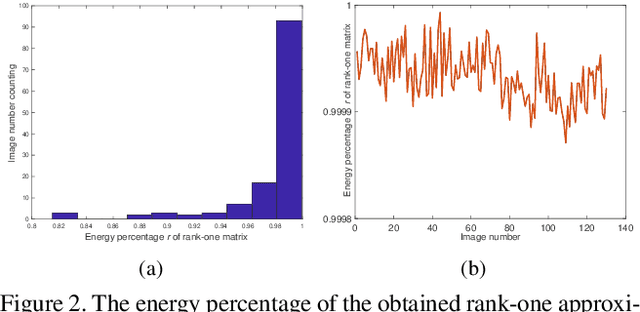
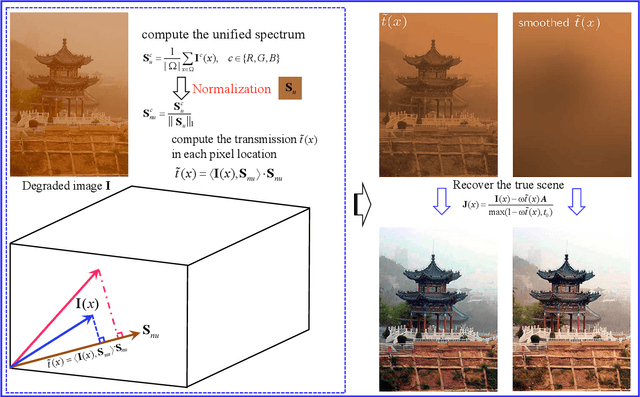
Scene recovery is a fundamental imaging task for several practical applications, e.g., video surveillance and autonomous vehicles, etc. To improve visual quality under different weather/imaging conditions, we propose a real-time light correction method to recover the degraded scenes in the cases of sandstorms, underwater, and haze. The heart of our work is that we propose an intensity projection strategy to estimate the transmission. This strategy is motivated by a straightforward rank-one transmission prior. The complexity of transmission estimation is $O(N)$ where $N$ is the size of the single image. Then we can recover the scene in real-time. Comprehensive experiments on different types of weather/imaging conditions illustrate that our method outperforms competitively several state-of-the-art imaging methods in terms of efficiency and robustness.
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022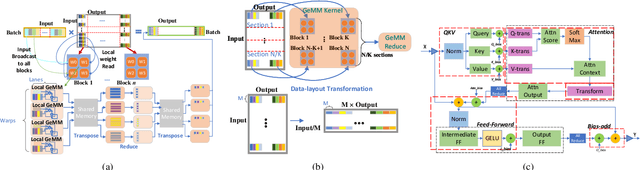
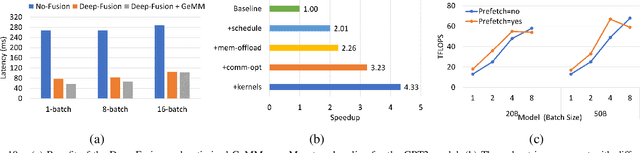
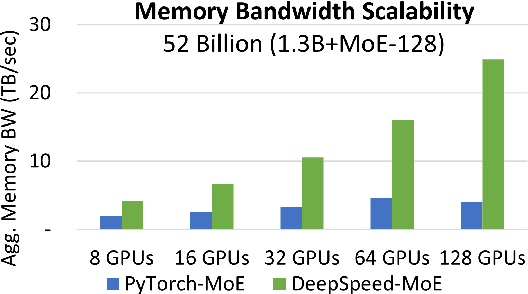
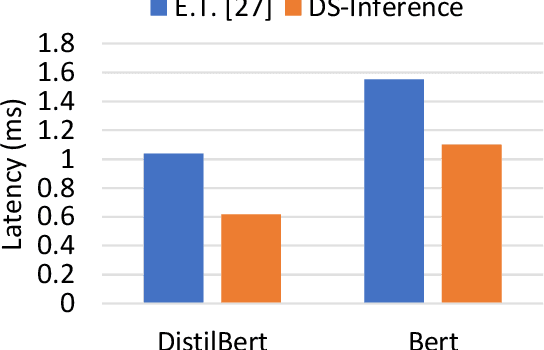
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
Cracking White-box DNN Watermarks via Invariant Neuron Transforms
May 19, 2022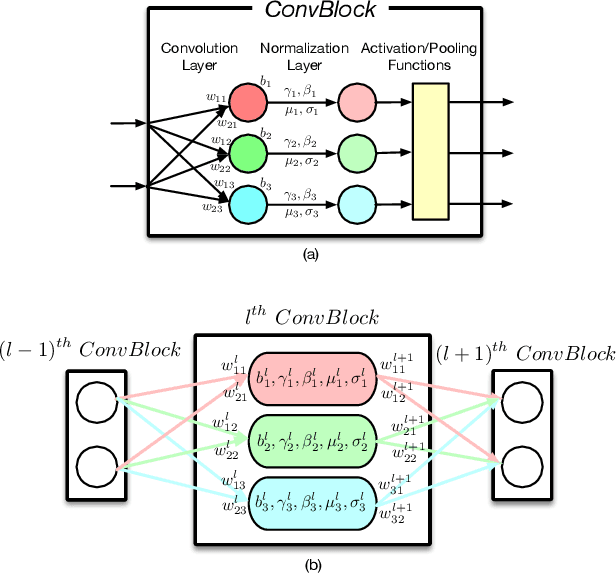
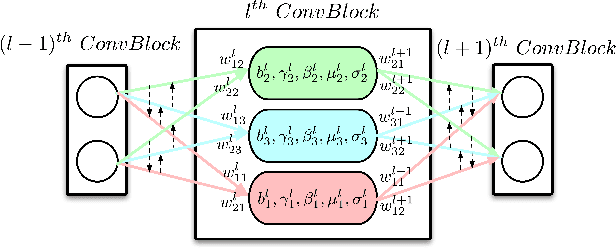
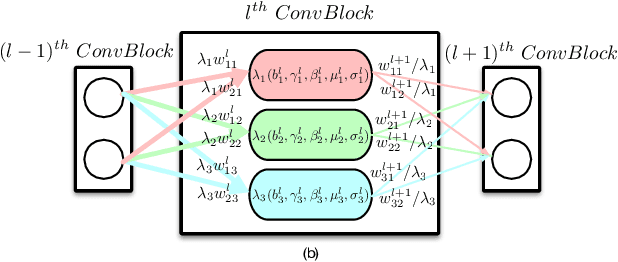
Recently, how to protect the Intellectual Property (IP) of deep neural networks (DNN) becomes a major concern for the AI industry. To combat potential model piracy, recent works explore various watermarking strategies to embed secret identity messages into the prediction behaviors or the internals (e.g., weights and neuron activation) of the target model. Sacrificing less functionality and involving more knowledge about the target model, the latter branch of watermarking schemes (i.e., white-box model watermarking) is claimed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts and applications in the industry. In this paper, we present the first effective removal attack which cracks almost all the existing white-box watermarking schemes with provably no performance overhead and no required prior knowledge. By analyzing these IP protection mechanisms at the granularity of neurons, we for the first time discover their common dependence on a set of fragile features of a local neuron group, all of which can be arbitrarily tampered by our proposed chain of invariant neuron transforms. On $9$ state-of-the-art white-box watermarking schemes and a broad set of industry-level DNN architectures, our attack for the first time reduces the embedded identity message in the protected models to be almost random. Meanwhile, unlike known removal attacks, our attack requires no prior knowledge on the training data distribution or the adopted watermark algorithms, and leaves model functionality intact.
Optimal Randomized Approximations for Matrix based Renyi's Entropy
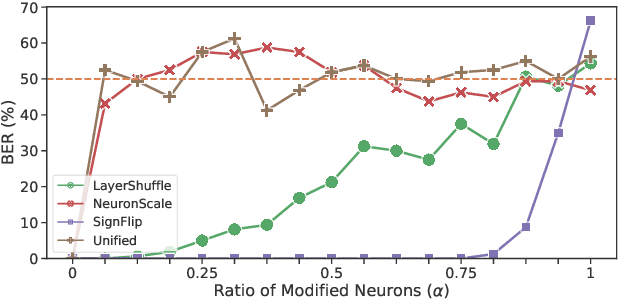
May 16, 2022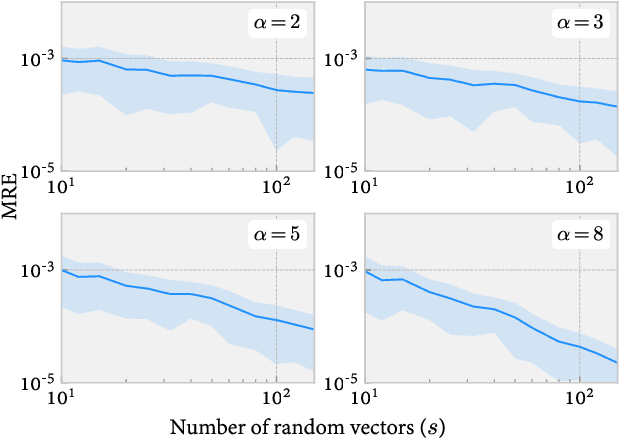
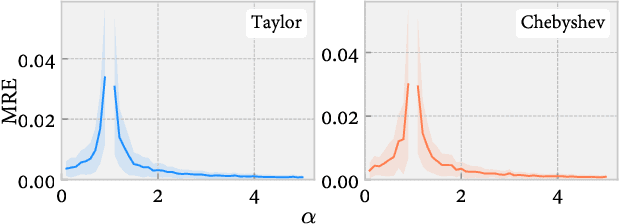
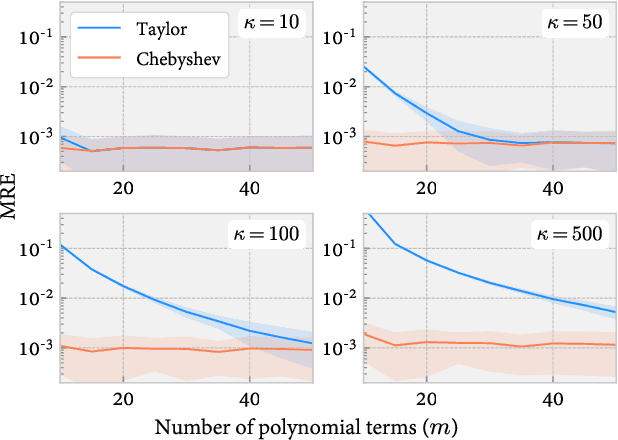
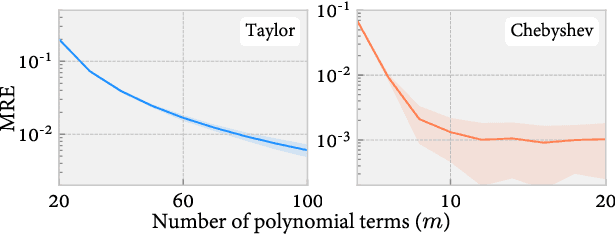
The Matrix-based Renyi's entropy enables us to directly measure information quantities from given data without the costly probability density estimation of underlying distributions, thus has been widely adopted in numerous statistical learning and inference tasks. However, exactly calculating this new information quantity requires access to the eigenspectrum of a semi-positive definite (SPD) matrix $A$ which grows linearly with the number of samples $n$, resulting in a $O(n^3)$ time complexity that is prohibitive for large-scale applications. To address this issue, this paper takes advantage of stochastic trace approximations for matrix-based Renyi's entropy with arbitrary $\alpha \in R^+$ orders, lowering the complexity by converting the entropy approximation to a matrix-vector multiplication problem. Specifically, we develop random approximations for integer order $\alpha$ cases and polynomial series approximations (Taylor and Chebyshev) for non-integer $\alpha$ cases, leading to a $O(n^2sm)$ overall time complexity, where $s,m \ll n$ denote the number of vector queries and the polynomial order respectively. We theoretically establish statistical guarantees for all approximation algorithms and give explicit order of s and m with respect to the approximation error $\varepsilon$, showing optimal convergence rate for both parameters up to a logarithmic factor. Large-scale simulations and real-world applications validate the effectiveness of the developed approximations, demonstrating remarkable speedup with negligible loss in accuracy.
SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking
Jun 16, 2021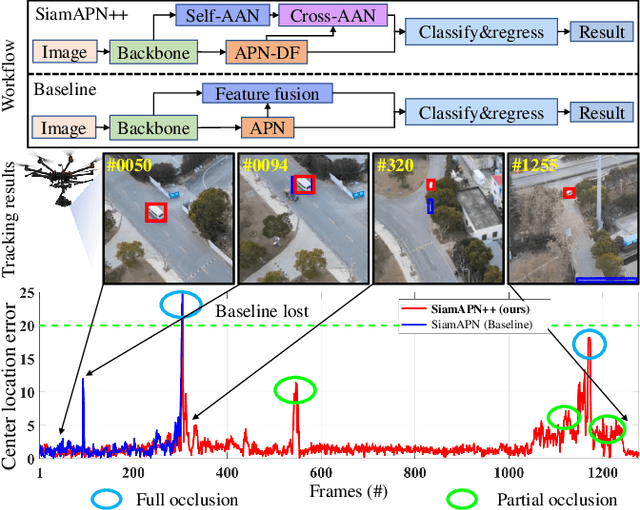
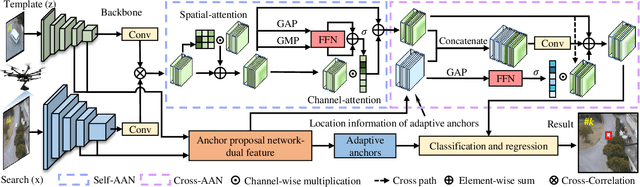
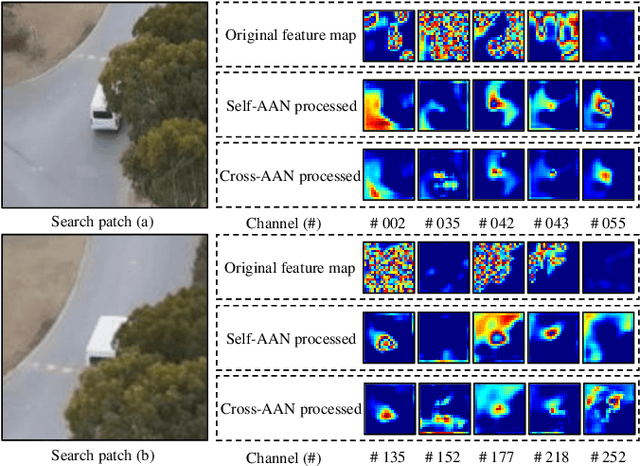
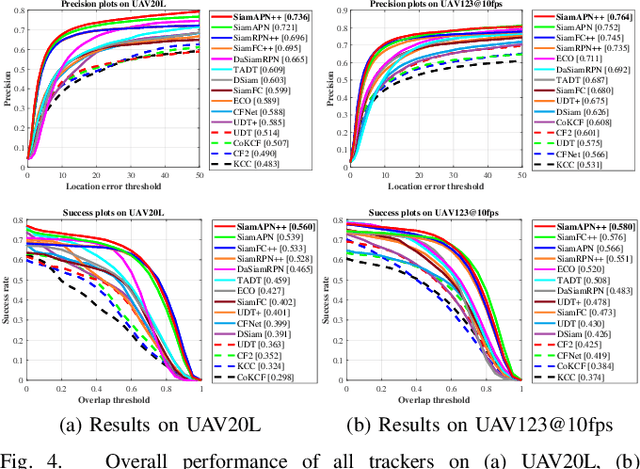
Recently, the Siamese-based method has stood out from multitudinous tracking methods owing to its state-of-the-art (SOTA) performance. Nevertheless, due to various special challenges in UAV tracking, \textit{e.g.}, severe occlusion, and fast motion, most existing Siamese-based trackers hardly combine superior performance with high efficiency. To this concern, in this paper, a novel attentional Siamese tracker (SiamAPN++) is proposed for real-time UAV tracking. By virtue of the attention mechanism, the attentional aggregation network (AAN) is conducted with self-AAN and cross-AAN, raising the expression ability of features eventually. The former AAN aggregates and models the self-semantic interdependencies of the single feature map via spatial and channel dimensions. The latter aims to aggregate the cross-interdependencies of different semantic features including the location information of anchors. In addition, the dual features version of the anchor proposal network is proposed to raise the robustness of proposing anchors, increasing the perception ability to objects with various scales. Experiments on two well-known authoritative benchmarks are conducted, where SiamAPN++ outperforms its baseline SiamAPN and other SOTA trackers. Besides, real-world tests onboard a typical embedded platform demonstrate that SiamAPN++ achieves promising tracking results with real-time speed.
Efficient Bayesian Network Structure Learning via Parameterized Local Search on Topological Orderings
Apr 06, 2022
In Bayesian Network Structure Learning (BNSL), one is given a variable set and parent scores for each variable and aims to compute a DAG, called Bayesian network, that maximizes the sum of parent scores, possibly under some structural constraints. Even very restricted special cases of BNSL are computationally hard, and, thus, in practice heuristics such as local search are used. A natural approach for a local search algorithm is a hill climbing strategy, where one replaces a given BNSL solution by a better solution within some pre-defined neighborhood as long as this is possible. We study ordering-based local search, where a solution is described via a topological ordering of the variables. We show that given such a topological ordering, one can compute an optimal DAG whose ordering is within inversion distance $r$ in subexponential FPT time; the parameter $r$ allows to balance between solution quality and running time of the local search algorithm. This running time bound can be achieved for BNSL without structural constraints and for all structural constraints that can be expressed via a sum of weights that are associated with each parent set. We also introduce a related distance called `window inversions distance' and show that the corresponding local search problem can also be solved in subexponential FPT time for the parameter $r$. For two further natural modification operations on the variable orderings, we show that algorithms with an FPT time for $r$ are unlikely. We also outline the limits of ordering-based local search by showing that it cannot be used for common structural constraints on the moralized graph of the network.
Split Two-Tower Model for Efficient and Privacy-Preserving Cross-device Federated Recommendation
Jun 28, 2022

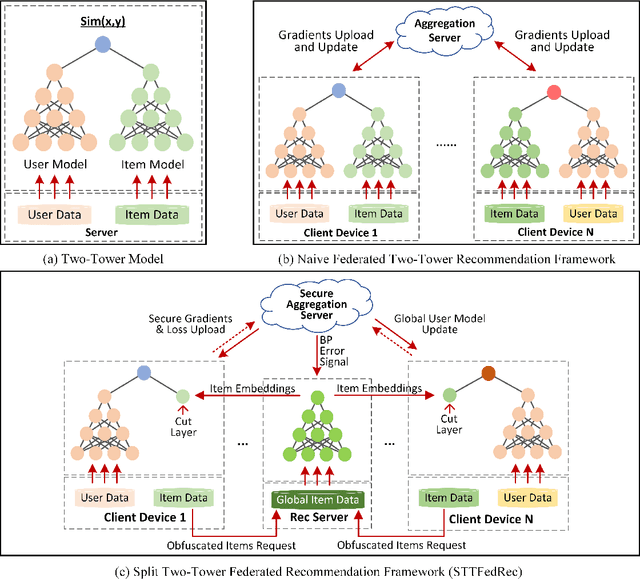
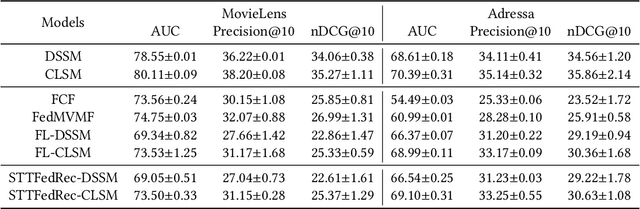
Federated Recommendation can mitigate the systematical privacy risks of traditional recommendation since it allows the model training and online inferring without centralized user data collection. Most existing works assume that all user devices are available and adequate to participate in the Federated Learning. However, in practice, the complex recommendation models designed for accurate prediction and massive item data cause a high computation and communication cost to the resource-constrained user device, resulting in poor performance or training failure. Therefore, how to effectively compress the computation and communication overhead to achieve efficient federated recommendations across ubiquitous mobile devices remains a significant challenge. This paper introduces split learning into the two-tower recommendation models and proposes STTFedRec, a privacy-preserving and efficient cross-device federated recommendation framework. STTFedRec achieves local computation reduction by splitting the training and computation of the item model from user devices to a performance-powered server. The server with the item model provides low-dimensional item embeddings instead of raw item data to the user devices for local training and online inferring, achieving server broadcast compression. The user devices only need to perform similarity calculations with cached user embeddings to achieve efficient online inferring. We also propose an obfuscated item request strategy and multi-party circular secret sharing chain to enhance the privacy protection of model training. The experiments conducted on two public datasets demonstrate that STTFedRec improves the average computation time and communication size of the baseline models by about 40 times and 42 times in the best-case scenario with balanced recommendation accuracy.
LPCSE: Neural Speech Enhancement through Linear Predictive Coding
Jun 22, 2022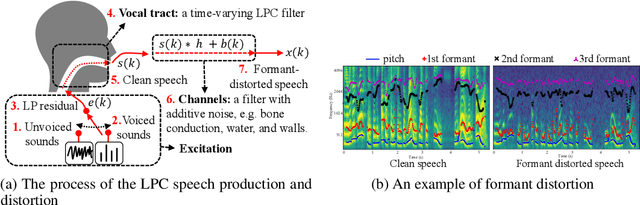
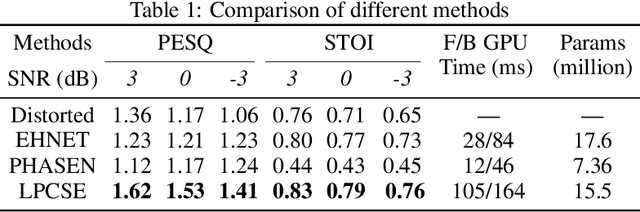
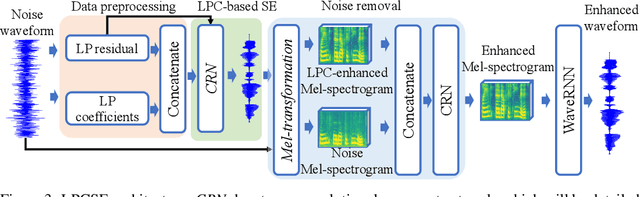
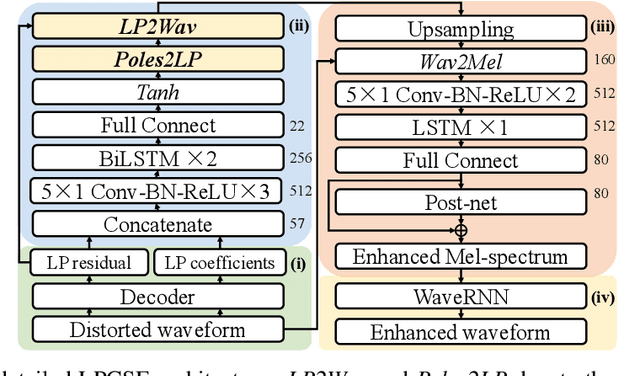
The increasingly stringent requirement on quality-of-experience in 5G/B5G communication systems has led to the emerging neural speech enhancement techniques, which however have been developed in isolation from the existing expert-rule based models of speech pronunciation and distortion, such as the classic Linear Predictive Coding (LPC) speech model because it is difficult to integrate the models with auto-differentiable machine learning frameworks. In this paper, to improve the efficiency of neural speech enhancement, we introduce an LPC-based speech enhancement (LPCSE) architecture, which leverages the strong inductive biases in the LPC speech model in conjunction with the expressive power of neural networks. Differentiable end-to-end learning is achieved in LPCSE via two novel blocks: a block that utilizes the expert rules to reduce the computational overhead when integrating the LPC speech model into neural networks, and a block that ensures the stability of the model and avoids exploding gradients in end-to-end training by mapping the Linear prediction coefficients to the filter poles. The experimental results show that LPCSE successfully restores the formants of the speeches distorted by transmission loss, and outperforms two existing neural speech enhancement methods of comparable neural network sizes in terms of the Perceptual evaluation of speech quality (PESQ) and Short-Time Objective Intelligibility (STOI) on the LJ Speech corpus.
Noisy $\ell^{0}$-Sparse Subspace Clustering on Dimensionality Reduced Data
Jun 22, 2022
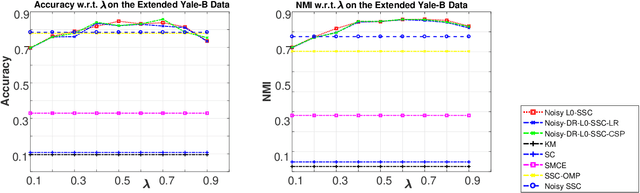
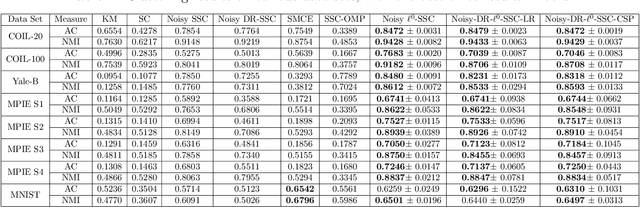
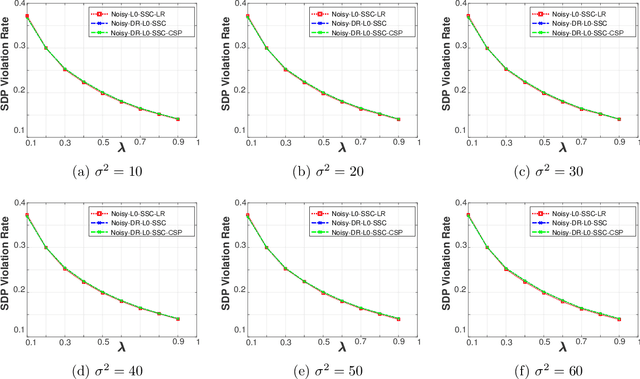
Sparse subspace clustering methods with sparsity induced by $\ell^{0}$-norm, such as $\ell^{0}$-Sparse Subspace Clustering ($\ell^{0}$-SSC)~\citep{YangFJYH16-L0SSC-ijcv}, are demonstrated to be more effective than its $\ell^{1}$ counterpart such as Sparse Subspace Clustering (SSC)~\citep{ElhamifarV13}. However, the theoretical analysis of $\ell^{0}$-SSC is restricted to clean data that lie exactly in subspaces. Real data often suffer from noise and they may lie close to subspaces. In this paper, we show that an optimal solution to the optimization problem of noisy $\ell^{0}$-SSC achieves subspace detection property (SDP), a key element with which data from different subspaces are separated, under deterministic and semi-random model. Our results provide theoretical guarantee on the correctness of noisy $\ell^{0}$-SSC in terms of SDP on noisy data for the first time, which reveals the advantage of noisy $\ell^{0}$-SSC in terms of much less restrictive condition on subspace affinity. In order to improve the efficiency of noisy $\ell^{0}$-SSC, we propose Noisy-DR-$\ell^{0}$-SSC which provably recovers the subspaces on dimensionality reduced data. Noisy-DR-$\ell^{0}$-SSC first projects the data onto a lower dimensional space by random projection, then performs noisy $\ell^{0}$-SSC on the projected data for improved efficiency. Experimental results demonstrate the effectiveness of Noisy-DR-$\ell^{0}$-SSC.
Effects of Reward Shaping on Curriculum Learning in Goal Conditioned Tasks
Jun 06, 2022
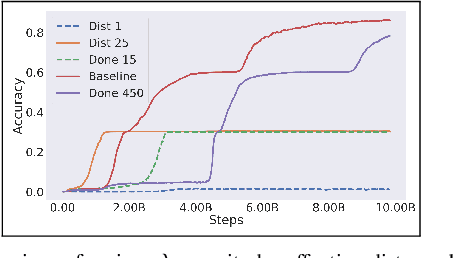
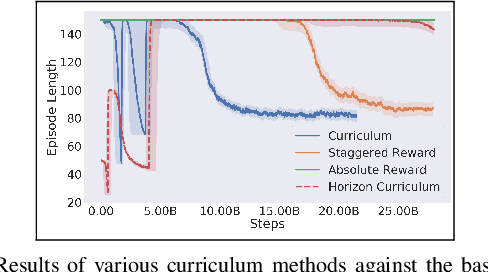
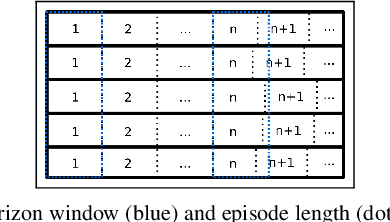
Real-time control for robotics is a popular research area in the reinforcement learning (RL) community. Through the use of techniques such as reward shaping, researchers have managed to train online agents across a multitude of domains. Despite these advances, solving goal-oriented tasks still require complex architectural changes or heavy constraints to be placed on the problem. To address this issue, recent works have explored how curriculum learning can be used to separate a complex task into sequential sub-goals, hence enabling the learning of a problem that may otherwise be too difficult to learn from scratch. In this article, we present how curriculum learning, reward shaping, and a high number of efficiently parallelized environments can be coupled together to solve the problem of multiple cube stacking. Finally, we extend the best configuration identified on a higher complexity environment with differently shaped objects.