 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Factual Correctness: Mitigating Preference-Inconsistent Explanations in Explainable Recommendation
Mar 03, 2026LLM-based explainable recommenders can produce fluent explanations that are factually correct, yet still justify items using attributes that conflict with a user's historical preferences. Such preference-inconsistent explanations yield logically valid but unconvincing reasoning and are largely missed by standard hallucination or faithfulness metrics. We formalize this failure mode and propose PURE, a preference-aware reasoning framework following a select-then-generate paradigm. Instead of only improving generation, PURE intervenes in evidence selection, it selects a compact set of multi-hop item-centric reasoning paths that are both factually grounded and aligned with user preference structure, guided by user intent, specificity, and diversity to suppress generic, weakly personalized evidence. The selected evidence is then injected into LLM generation via structure-aware prompting that preserves relational constraints. To measure preference inconsistency, we introduce a feature-level, user-centric evaluation metric that reveals misalignment overlooked by factuality-based measures. Experiments on three real-world datasets show that PURE consistently reduces preference-inconsistent explanations and factual hallucinations while maintaining competitive recommendation accuracy, explanation quality, and inference efficiency. These results highlight that trustworthy explanations require not only factual correctness but also justification aligned with user preferences.
Split Two-Tower Model for Efficient and Privacy-Preserving Cross-device Federated Recommendation
Jun 28, 2022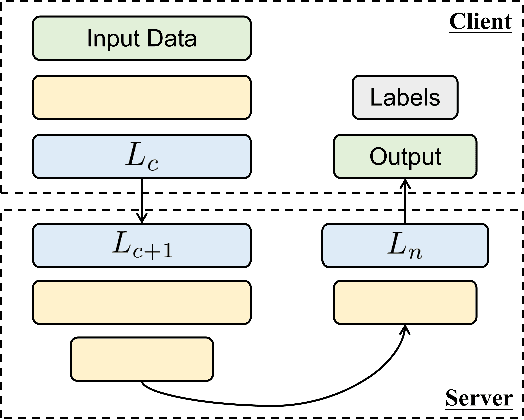

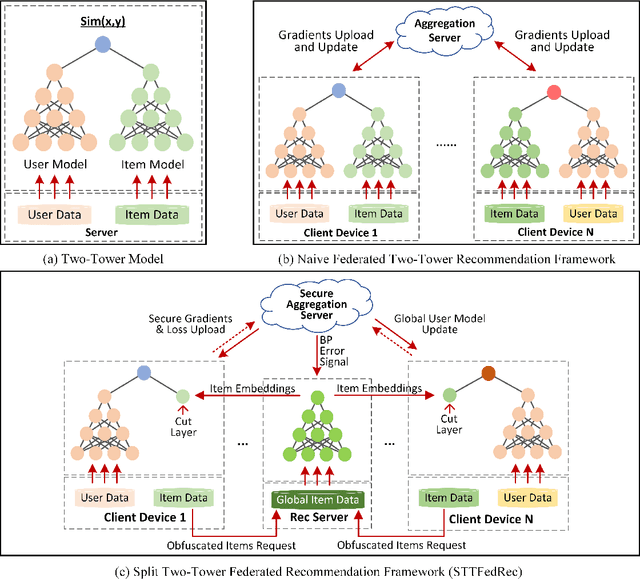
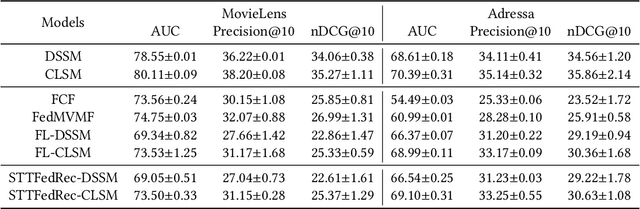
Federated Recommendation can mitigate the systematical privacy risks of traditional recommendation since it allows the model training and online inferring without centralized user data collection. Most existing works assume that all user devices are available and adequate to participate in the Federated Learning. However, in practice, the complex recommendation models designed for accurate prediction and massive item data cause a high computation and communication cost to the resource-constrained user device, resulting in poor performance or training failure. Therefore, how to effectively compress the computation and communication overhead to achieve efficient federated recommendations across ubiquitous mobile devices remains a significant challenge. This paper introduces split learning into the two-tower recommendation models and proposes STTFedRec, a privacy-preserving and efficient cross-device federated recommendation framework. STTFedRec achieves local computation reduction by splitting the training and computation of the item model from user devices to a performance-powered server. The server with the item model provides low-dimensional item embeddings instead of raw item data to the user devices for local training and online inferring, achieving server broadcast compression. The user devices only need to perform similarity calculations with cached user embeddings to achieve efficient online inferring. We also propose an obfuscated item request strategy and multi-party circular secret sharing chain to enhance the privacy protection of model training. The experiments conducted on two public datasets demonstrate that STTFedRec improves the average computation time and communication size of the baseline models by about 40 times and 42 times in the best-case scenario with balanced recommendation accuracy.
A Novel Privacy-Preserved Recommender System Framework based on Federated Learning
Nov 11, 2020
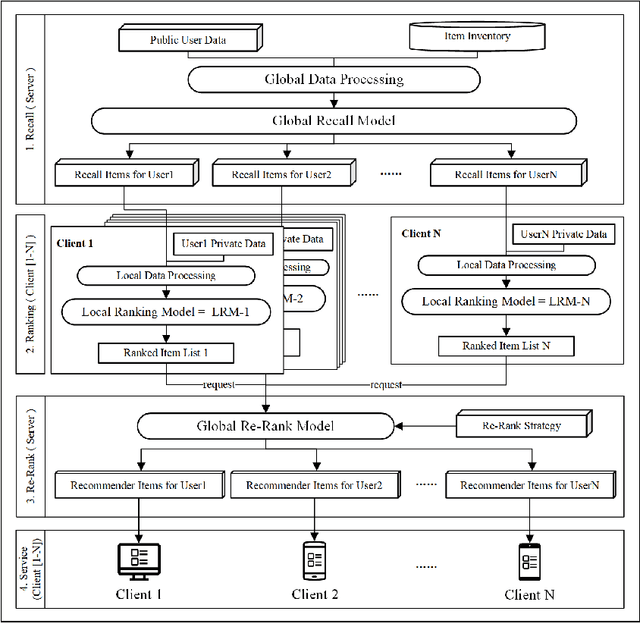
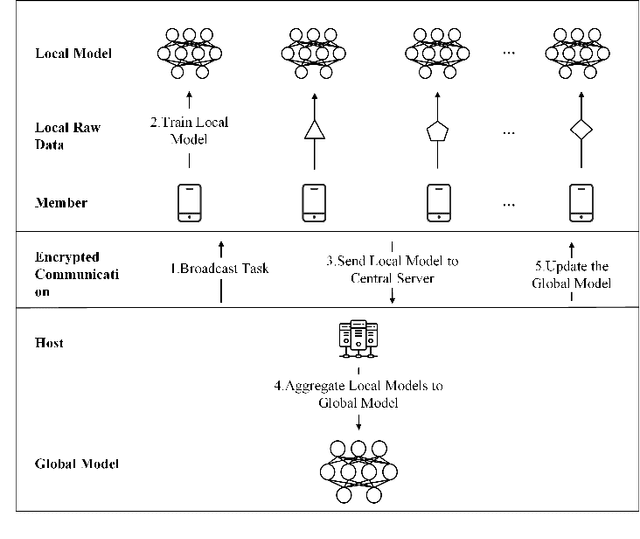
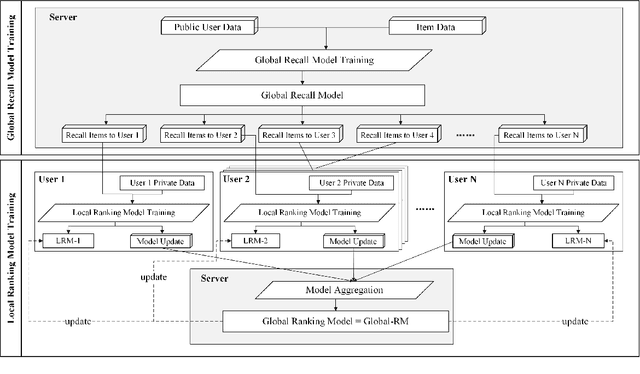
Recommender System (RS) is currently an effective way to solve information overload. To meet users' next click behavior, RS needs to collect users' personal information and behavior to achieve a comprehensive and profound user preference perception. However, these centrally collected data are privacy-sensitive, and any leakage may cause severe problems to both users and service providers. This paper proposed a novel privacy-preserved recommender system framework (PPRSF), through the application of federated learning paradigm, to enable the recommendation algorithm to be trained and carry out inference without centrally collecting users' private data. The PPRSF not only able to reduces the privacy leakage risk, satisfies legal and regulatory requirements but also allows various recommendation algorithms to be applied.