 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: Abstractions for Communicating Efficiently
Sep 30, 2024A central but unresolved aspect of problem-solving in AI is the capability to introduce and use abstractions, something humans excel at. Work in cognitive science has demonstrated that humans tend towards higher levels of abstraction when engaged in collaborative task-oriented communication, enabling gradually shorter and more information-efficient utterances. Several computational methods have attempted to replicate this phenomenon, but all make unrealistic simplifying assumptions about how abstractions are introduced and learned. Our method, Abstractions for Communicating Efficiently (ACE), overcomes these limitations through a neuro-symbolic approach. On the symbolic side, we draw on work from library learning for proposing abstractions. We combine this with neural methods for communication and reinforcement learning, via a novel use of bandit algorithms for controlling the exploration and exploitation trade-off in introducing new abstractions. ACE exhibits similar tendencies to humans on a collaborative construction task from the cognitive science literature, where one agent (the architect) instructs the other (the builder) to reconstruct a scene of block-buildings. ACE results in the emergence of an efficient language as a by-product of collaborative communication. Beyond providing mechanistic insights into human communication, our work serves as a first step to providing conversational agents with the ability for human-like communicative abstractions.
Learning Efficient Recursive Numeral Systems via Reinforcement Learning
Sep 11, 2024



The emergence of mathematical concepts, such as number systems, is an understudied area in AI for mathematics and reasoning. It has previously been shown Carlsson et al. (2021) that by using reinforcement learning (RL), agents can derive simple approximate and exact-restricted numeral systems. However, it is a major challenge to show how more complex recursive numeral systems, similar to the one utilised in English, could arise via a simple learning mechanism such as RL. Here, we introduce an approach towards deriving a mechanistic explanation of the emergence of recursive number systems where we consider an RL agent which directly optimizes a lexicon under a given meta-grammar. Utilising a slightly modified version of the seminal meta-grammar of Hurford (1975), we demonstrate that our RL agent can effectively modify the lexicon towards Pareto-optimal configurations which are comparable to those observed within human numeral systems.
Scalable Multi-Agent Reinforcement Learning for Warehouse Logistics with Robotic and Human Co-Workers
Dec 22, 2022



This project leverages advances in multi-agent reinforcement learning (MARL) to improve the efficiency and flexibility of order-picking systems for commercial warehouses. We envision a warehouse of the future in which dozens of mobile robots and human pickers work together to collect and deliver items within the warehouse. The fundamental problem we tackle, called the order-picking problem, is how these worker agents must coordinate their movement and actions in the warehouse to maximise performance (e.g. order throughput) under given resource constraints. Established industry methods using heuristic approaches require large engineering efforts to optimise for innately variable warehouse configurations. In contrast, the MARL framework can be flexibly applied to any warehouse configuration (e.g. size, layout, number/types of workers, item replenishment frequency) and the agents learn via a process of trial-and-error how to optimally cooperate with one another. This paper details the current status of the R&D effort initiated by Dematic and the University of Edinburgh towards a general-purpose and scalable MARL solution for the order-picking problem in realistic warehouses.
Federated Meta-Learning for Traffic Steering in O-RAN
Sep 13, 2022
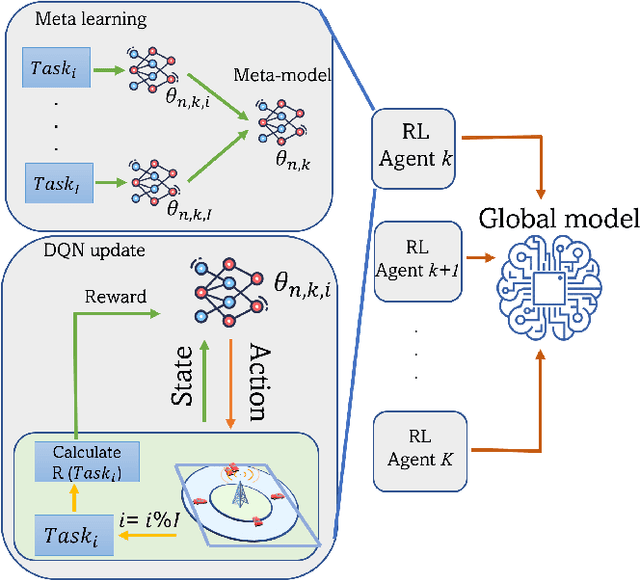
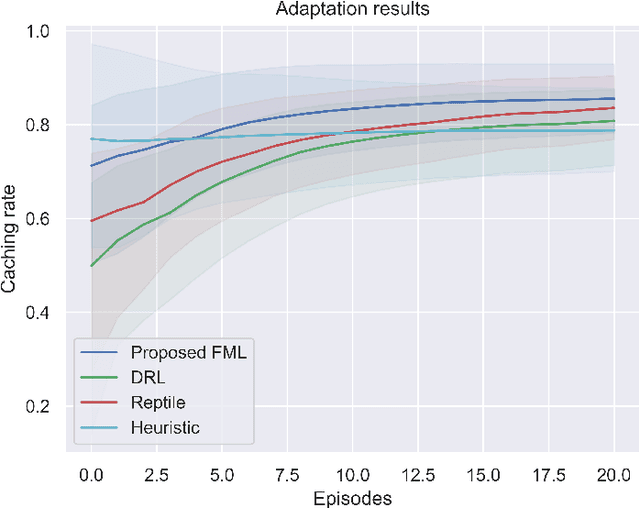
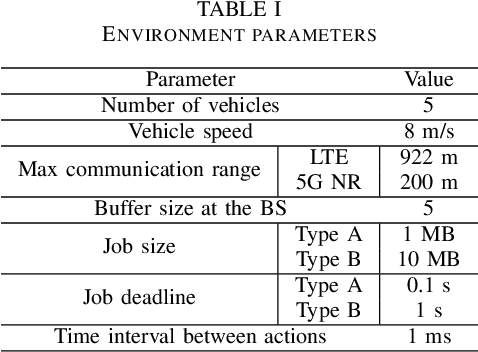
The vision of 5G lies in providing high data rates, low latency (for the aim of near-real-time applications), significantly increased base station capacity, and near-perfect quality of service (QoS) for users, compared to LTE networks. In order to provide such services, 5G systems will support various combinations of access technologies such as LTE, NR, NR-U and Wi-Fi. Each radio access technology (RAT) provides different types of access, and these should be allocated and managed optimally among the users. Besides resource management, 5G systems will also support a dual connectivity service. The orchestration of the network therefore becomes a more difficult problem for system managers with respect to legacy access technologies. In this paper, we propose an algorithm for RAT allocation based on federated meta-learning (FML), which enables RAN intelligent controllers (RICs) to adapt more quickly to dynamically changing environments. We have designed a simulation environment which contains LTE and 5G NR service technologies. In the simulation, our objective is to fulfil UE demands within the deadline of transmission to provide higher QoS values. We compared our proposed algorithm with a single RL agent, the Reptile algorithm and a rule-based heuristic method. Simulation results show that the proposed FML method achieves higher caching rates at first deployment round 21% and 12% respectively. Moreover, proposed approach adapts to new tasks and environments most quickly amongst the compared methods.
Effects of Reward Shaping on Curriculum Learning in Goal Conditioned Tasks
Jun 06, 2022
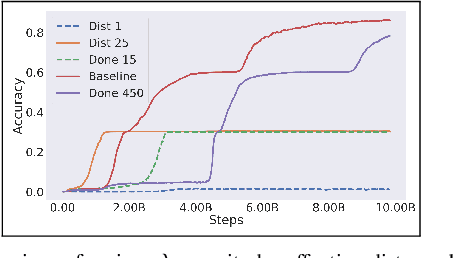
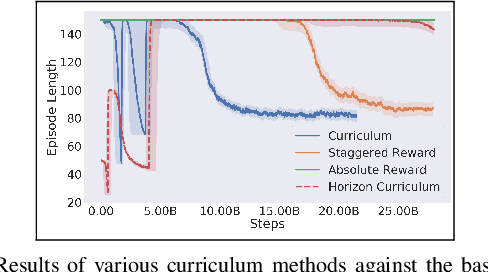
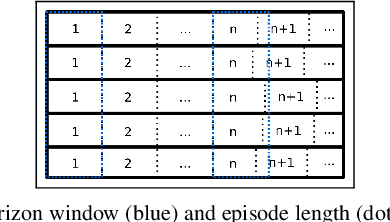
Real-time control for robotics is a popular research area in the reinforcement learning (RL) community. Through the use of techniques such as reward shaping, researchers have managed to train online agents across a multitude of domains. Despite these advances, solving goal-oriented tasks still require complex architectural changes or heavy constraints to be placed on the problem. To address this issue, recent works have explored how curriculum learning can be used to separate a complex task into sequential sub-goals, hence enabling the learning of a problem that may otherwise be too difficult to learn from scratch. In this article, we present how curriculum learning, reward shaping, and a high number of efficiently parallelized environments can be coupled together to solve the problem of multiple cube stacking. Finally, we extend the best configuration identified on a higher complexity environment with differently shaped objects.