 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Jan 09, 2024



The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Dec 18, 2023



This study examines 4-bit quantization methods like GPTQ in large language models (LLMs), highlighting GPTQ's overfitting and limited enhancement in Zero-Shot tasks. While prior works merely focusing on zero-shot measurement, we extend task scope to more generative categories such as code generation and abstractive summarization, in which we found that INT4 quantization can significantly underperform. However, simply shifting to higher precision formats like FP6 has been particularly challenging, thus overlooked, due to poor performance caused by the lack of sophisticated integration and system acceleration strategies on current AI hardware. Our results show that FP6, even with a coarse-grain quantization scheme, performs robustly across various algorithms and tasks, demonstrating its superiority in accuracy and versatility. Notably, with the FP6 quantization, \codestar-15B model performs comparably to its FP16 counterpart in code generation, and for smaller models like the 406M it closely matches their baselines in summarization. Neither can be achieved by INT4. To better accommodate various AI hardware and achieve the best system performance, we propose a novel 4+2 design for FP6 to achieve similar latency to the state-of-the-art INT4 fine-grain quantization. With our design, FP6 can become a promising solution to the current 4-bit quantization methods used in LLMs.
ZeroQuant-HERO: Hardware-Enhanced Robust Optimized Post-Training Quantization Framework for W8A8 Transformers
Oct 26, 2023



Quantization techniques are pivotal in reducing the memory and computational demands of deep neural network inference. Existing solutions, such as ZeroQuant, offer dynamic quantization for models like BERT and GPT but overlook crucial memory-bounded operators and the complexities of per-token quantization. Addressing these gaps, we present a novel, fully hardware-enhanced robust optimized post-training W8A8 quantization framework, ZeroQuant-HERO. This framework uniquely integrates both memory bandwidth and compute-intensive operators, aiming for optimal hardware performance. Additionally, it offers flexibility by allowing specific INT8 modules to switch to FP16/BF16 mode, enhancing accuracy.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023



ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.
Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases
Jan 27, 2023



Improving the deployment efficiency of transformer-based language models has been challenging given their high computation and memory cost. While INT8 quantization has recently been shown to be effective in reducing both the memory cost and latency while preserving model accuracy, it remains unclear whether we can leverage INT4 (which doubles peak hardware throughput) to achieve further latency improvement. In this work, we fully investigate the feasibility of using INT4 quantization for language models, and show that using INT4 introduces no or negligible accuracy degradation for encoder-only and encoder-decoder models, but causes a significant accuracy drop for decoder-only models. To materialize the performance gain using INT4, we develop a highly-optimized end-to-end INT4 encoder inference pipeline supporting different quantization strategies. Our INT4 pipeline is $8.5\times$ faster for latency-oriented scenarios and up to $3\times$ for throughput-oriented scenarios compared to the inference of FP16, and improves the SOTA BERT INT8 performance from FasterTransformer by up to $1.7\times$. We also provide insights into the failure cases when applying INT4 to decoder-only models, and further explore the compatibility of INT4 quantization with other compression techniques, like pruning and layer reduction.
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022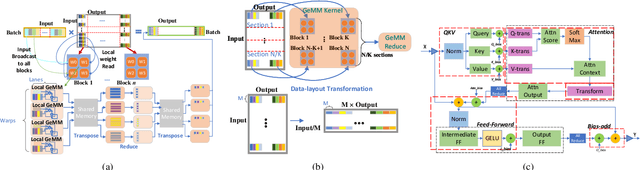
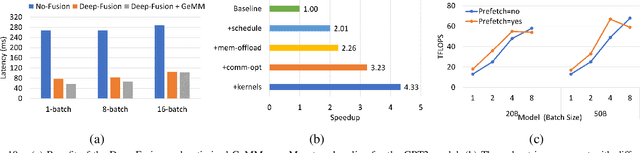
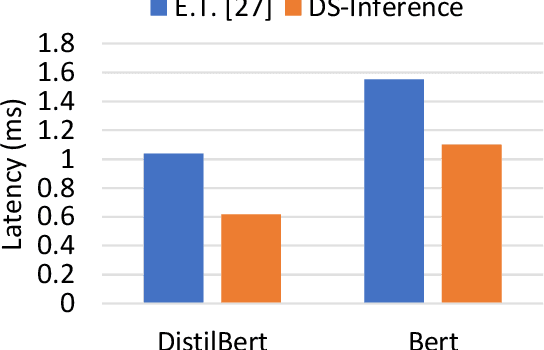
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
Jun 04, 2022



How to efficiently serve ever-larger trained natural language models in practice has become exceptionally challenging even for powerful cloud servers due to their prohibitive memory/computation requirements. In this work, we present an efficient and affordable post-training quantization approach to compress large Transformer-based models, termed as ZeroQuant. ZeroQuant is an end-to-end quantization and inference pipeline with three main components: (1) a fine-grained hardware-friendly quantization scheme for both weight and activations; (2) a novel affordable layer-by-layer knowledge distillation algorithm (LKD) even without the access to the original training data; (3) a highly-optimized quantization system backend support to remove the quantization/dequantization overhead. As such, we are able to show that: (1) ZeroQuant can reduce the precision for weights and activations to INT8 in a cost-free way for both BERT and GPT3-style models with minimal accuracy impact, which leads to up to 5.19x/4.16x speedup on those models compared to FP16 inference; (2) ZeroQuant plus LKD affordably quantize the weights in the fully-connected module to INT4 along with INT8 weights in the attention module and INT8 activations, resulting in 3x memory footprint reduction compared to the FP16 model; (3) ZeroQuant can be directly applied to two of the largest open-sourced language models, including GPT-J6B and GPT-NeoX20, for which our INT8 model achieves similar accuracy as the FP16 model but achieves up to 5.2x better efficiency.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022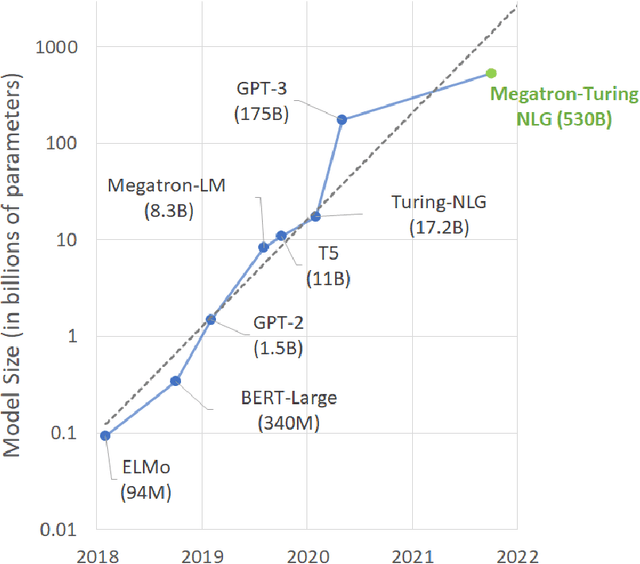
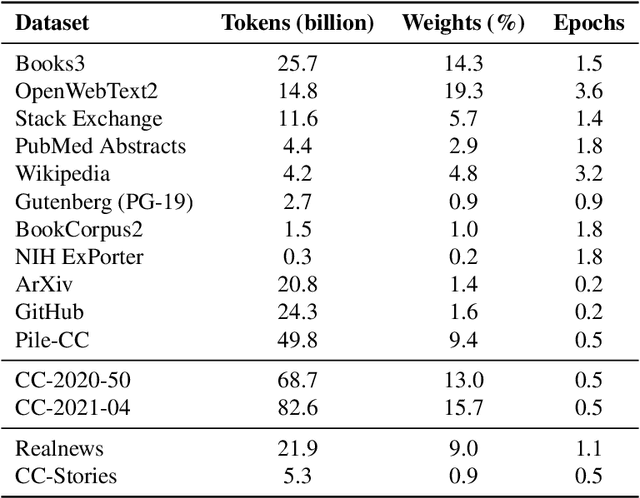
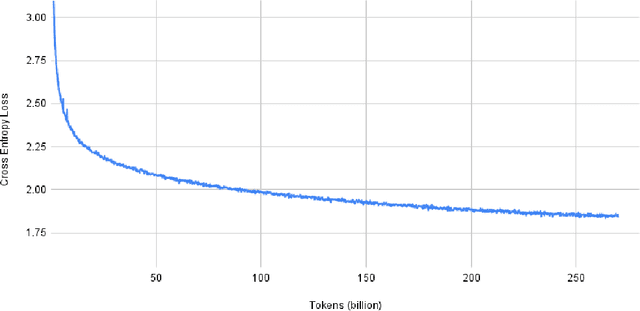
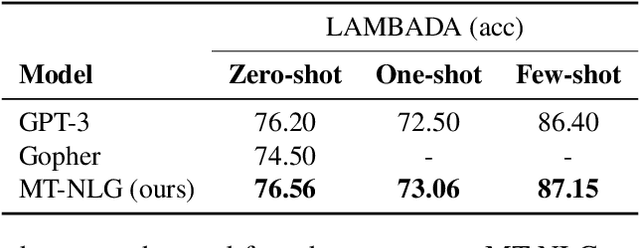
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
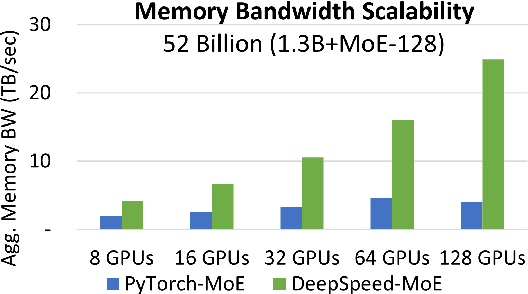
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
Jan 14, 2022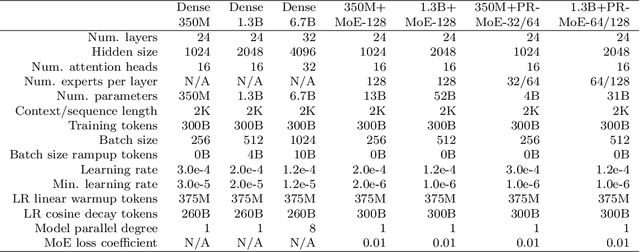
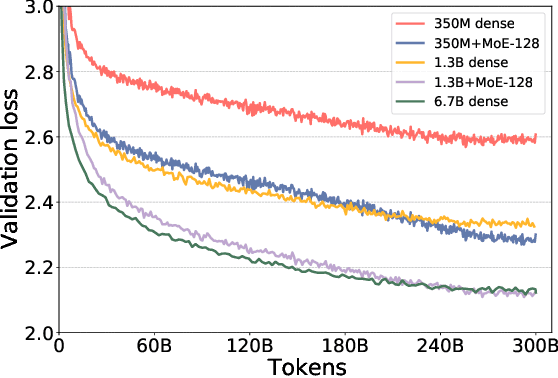
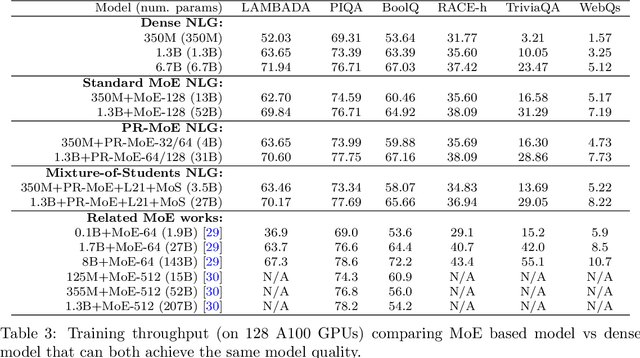
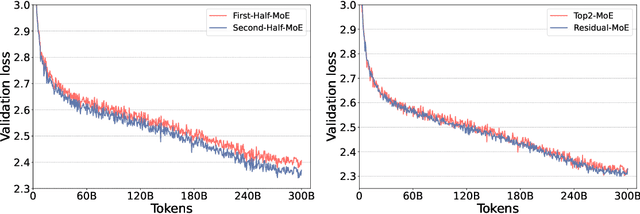
As the training of giant dense models hits the boundary on the availability and capability of the hardware resources today, Mixture-of-Experts (MoE) models become one of the most promising model architectures due to their significant training cost reduction compared to a quality-equivalent dense model. Its training cost saving is demonstrated from encoder-decoder models (prior works) to a 5x saving for auto-aggressive language models (this work along with parallel explorations). However, due to the much larger model size and unique architecture, how to provide fast MoE model inference remains challenging and unsolved, limiting its practical usage. To tackle this, we present DeepSpeed-MoE, an end-to-end MoE training and inference solution as part of the DeepSpeed library, including novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions. DeepSpeed-MoE offers an unprecedented scale and efficiency to serve massive MoE models with up to 4.5x faster and 9x cheaper inference compared to quality-equivalent dense models. We hope our innovations and systems help open a promising path to new directions in the large model landscape, a shift from dense to sparse MoE models, where training and deploying higher-quality models with fewer resources becomes more widely possible.
ZeRO-Offload: Democratizing Billion-Scale Model Training
Jan 18, 2021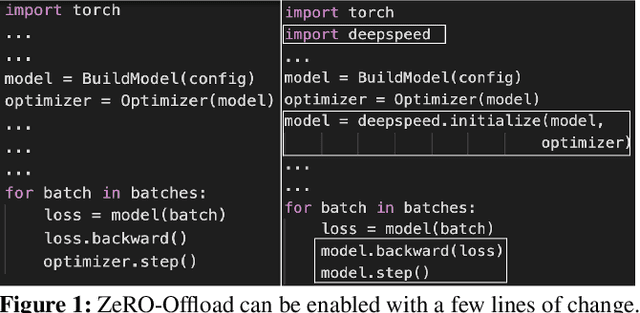
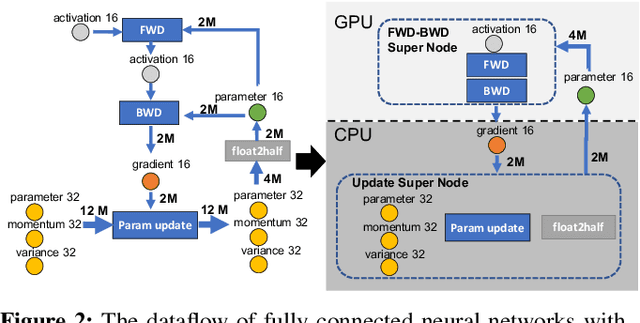
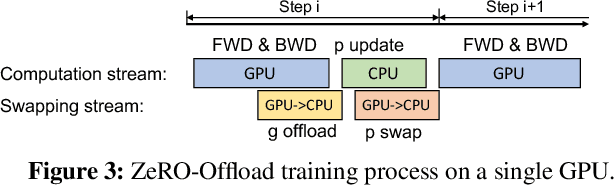
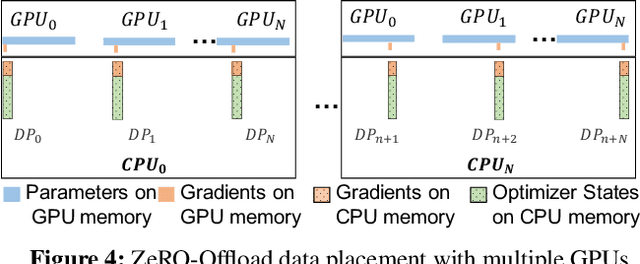
Large-scale model training has been a playing ground for a limited few requiring complex model refactoring and access to prohibitively expensive GPU clusters. ZeRO-Offload changes the large model training landscape by making large model training accessible to nearly everyone. It can train models with over 13 billion parameters on a single GPU, a 10x increase in size compared to popular framework such as PyTorch, and it does so without requiring any model change from the data scientists or sacrificing computational efficiency. ZeRO-Offload enables large model training by offloading data and compute to CPU. To preserve compute efficiency, it is designed to minimize the data movement to/from GPU, and reduce CPU compute time while maximizing memory savings on GPU. As a result, ZeRO-Offload can achieve 40 TFlops/GPU on a single NVIDIA V100 GPU for 10B parameter model compared to 30TF using PyTorch alone for a 1.4B parameter model, the largest that can be trained without running out of memory. ZeRO-Offload is also designed to scale on multiple-GPUs when available, offering near linear speedup on up to 128 GPUs. Additionally, it can work together with model parallelism to train models with over 70 billion parameters on a single DGX-2 box, a 4.5x increase in model size compared to using model parallelism alone. By combining compute and memory efficiency with ease-of-use, ZeRO-Offload democratizes large-scale model training making it accessible to even data scientists with access to just a single GPU.