 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Jun 21, 2022
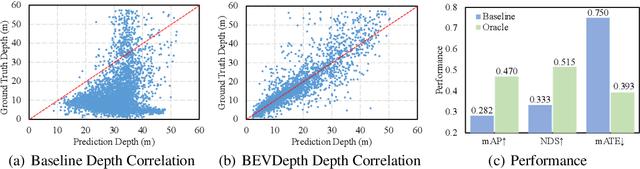
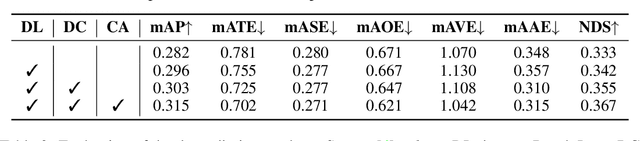
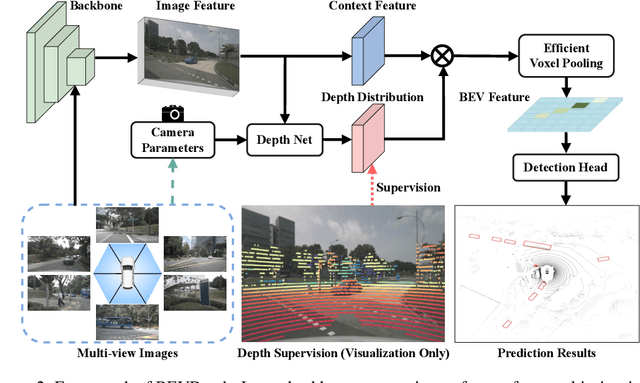
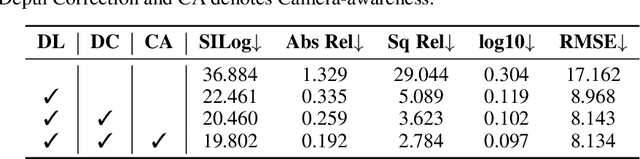
In this research, we propose a new 3D object detector with a trustworthy depth estimation, dubbed BEVDepth, for camera-based Bird's-Eye-View (BEV) 3D object detection. By a thorough analysis of recent approaches, we discover that the depth estimation is implicitly learned without camera information, making it the de-facto fake-depth for creating the following pseudo point cloud. BEVDepth gets explicit depth supervision utilizing encoded intrinsic and extrinsic parameters. A depth correction sub-network is further introduced to counteract projecting-induced disturbances in depth ground truth. To reduce the speed bottleneck while projecting features from image-view into BEV using estimated depth, a quick view-transform operation is also proposed. Besides, our BEVDepth can be easily extended with input from multi-frame. Without any bells and whistles, BEVDepth achieves the new state-of-the-art 60.0% NDS on the challenging nuScenes test set while maintaining high efficiency. For the first time, the performance gap between the camera and LiDAR is largely reduced within 10% NDS.
Bi-Static Sensing for Near-Field RIS Localization
Jun 28, 2022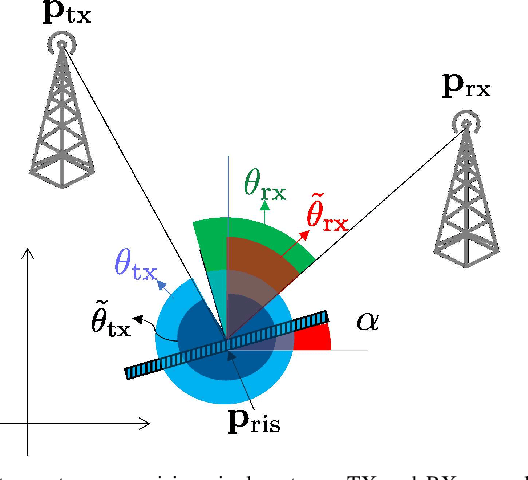

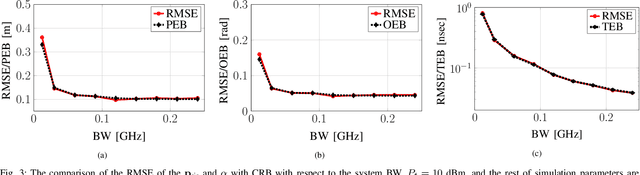
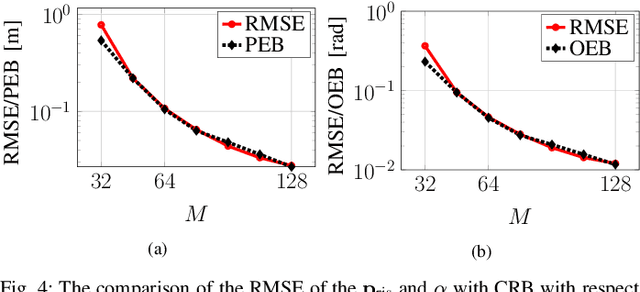
We address the localization of a reconfigurable intelligent surface (RIS) for a single-input single-output multi-carrier system using bi-static sensing between a fixed transmitter and a fixed receiver. Due to the deployment of RISs with a large dimension, near-field (NF) scenarios are likely to occur, especially for indoor applications, and are the focus of this work. We first derive the Cramer-Rao bounds (CRBs) on the estimation error of the RIS position and orientation and the time of arrival (TOA) for the path transmitter-RIS-receiver. We propose a multi-stage low-complexity estimator for RIS localization purposes. In this proposed estimator, we first perform a line search to estimate the TOA. Then, we use the far-field approximation of the NF signal model to implicitly estimate the angle of arrival and the angle of departure at the RIS center. Finally, the RIS position and orientation estimate are refined via a quasi-Newton method. Simulation results reveal that the proposed estimator can attain the CRBs. We also investigate the effects of several influential factors on the accuracy of the proposed estimator like the RIS size, transmitted power, system bandwidth, and RIS position and orientation.
Entropy-based Discovery of Summary Causal Graphs in Time Series
May 21, 2021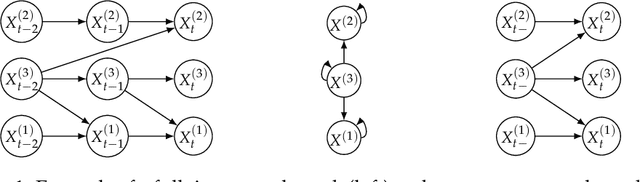
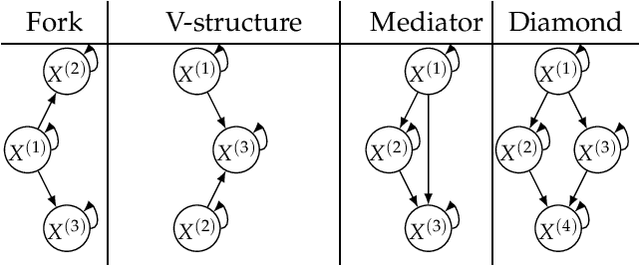
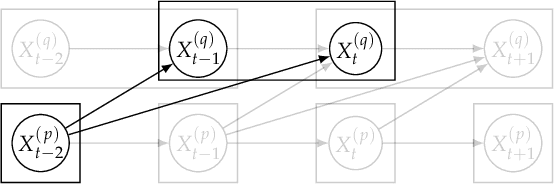
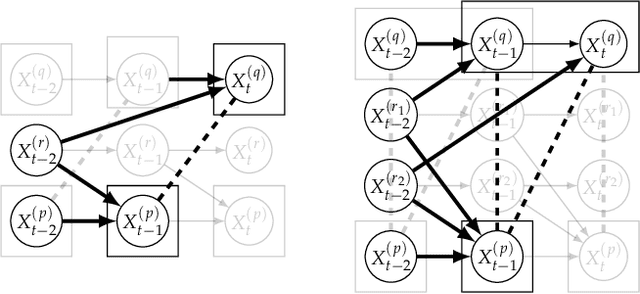
We address in this study the problem of learning a summary causal graph on time series with potentially different sampling rates. To do so, we first propose a new temporal mutual information measure defined on a window-based representation of time series. We then show how this measure relates to an entropy reduction principle that can be seen as a special case of the Probabilistic Raising Principle. We finally combine these two ingredients in a PC-like algorithm to construct the summary causal graph. This algorithm is evaluated on several datasets that shows both its efficacy and efficiency.
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 04, 2021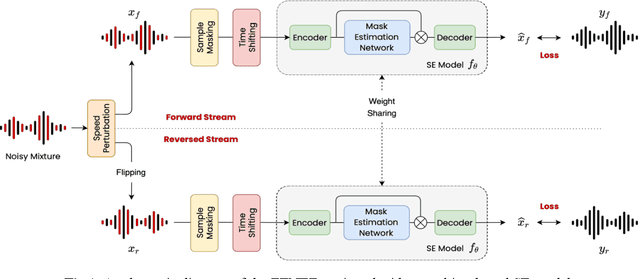
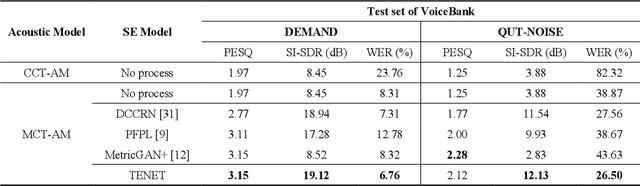
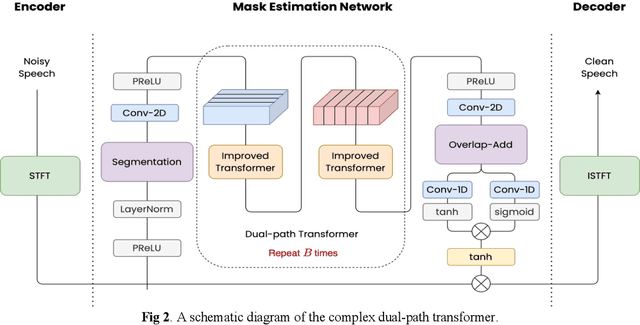
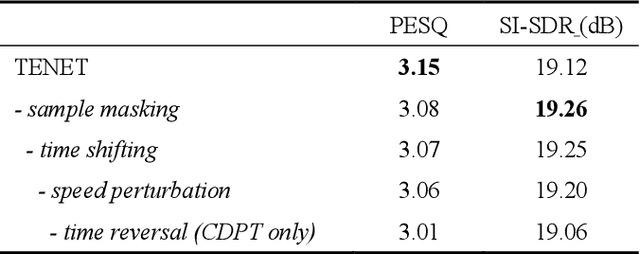
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.
On Evaluating Power Loss with HATSGA Algorithm for Power Network Reconfiguration in the Smart Grid
May 14, 2022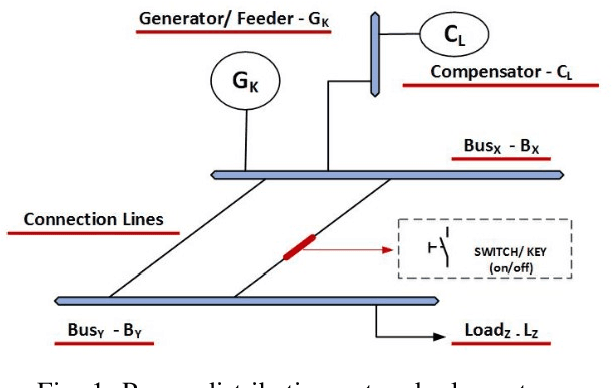
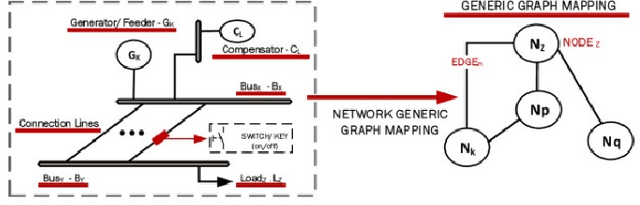
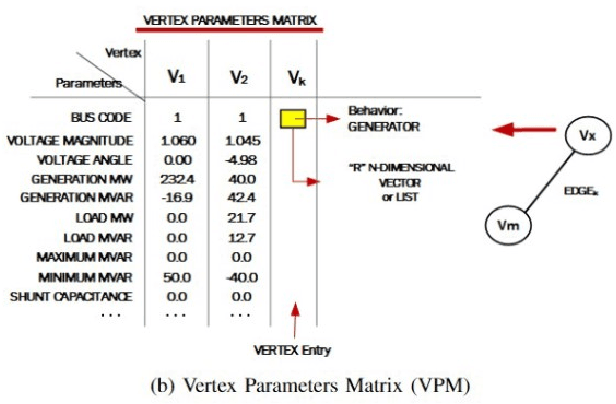
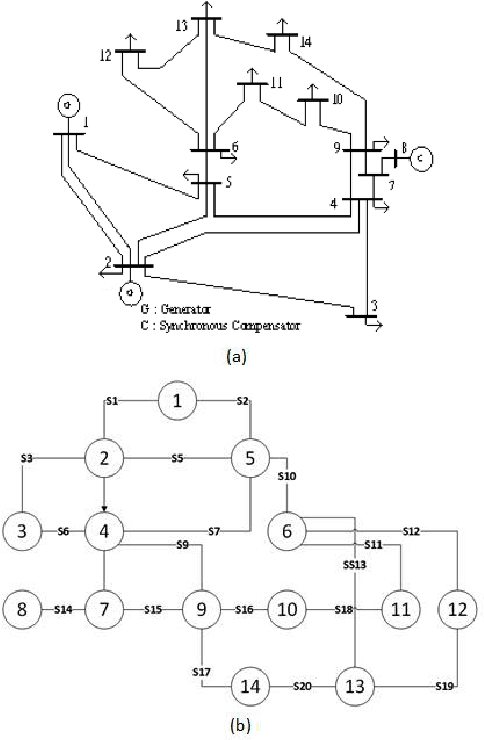
This paper presents the power network reconfiguration algorithm HATSGA with a "R" modeling approach and evaluates its behavior in computing new reconfiguration topologies for the power network in the Smart Grid context. The modeling of the power distribution network with the language "R" is used to represent the network and support the computation of distinct algorithm configurations towards the evaluation of new reconfiguration topologies. The HATSGA algorithm adopts a hybrid Tabu Search and Genetic Algorithm strategy and can be configured in different ways to compute network reconfiguration solutions. The evaluation of power loss with HATSGA uses the IEEE 14-Bus topology as the power test scenario. The evaluation of reconfiguration topologies with minimum power loss with HATSGA indicates that an efficient solution can be reached with a feasible computational time. This suggests that HATSGA can be potentially used for computing reconfiguration network topologies and, beyond that, it can be used for autonomic self-healing management approaches where a feasible computational time is required.
* 7 pp
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
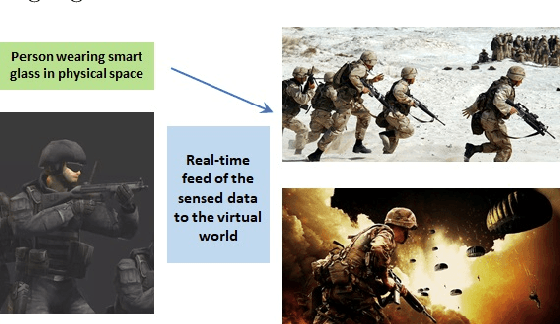
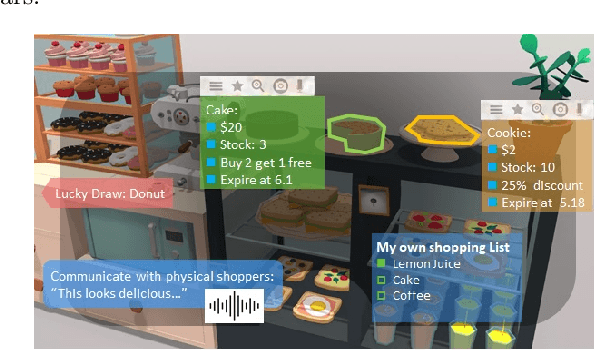

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
Federated Learning for Energy-limited Wireless Networks: A Partial Model Aggregation Approach
Apr 20, 2022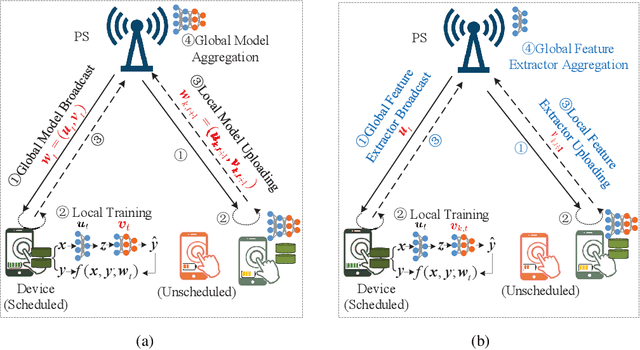
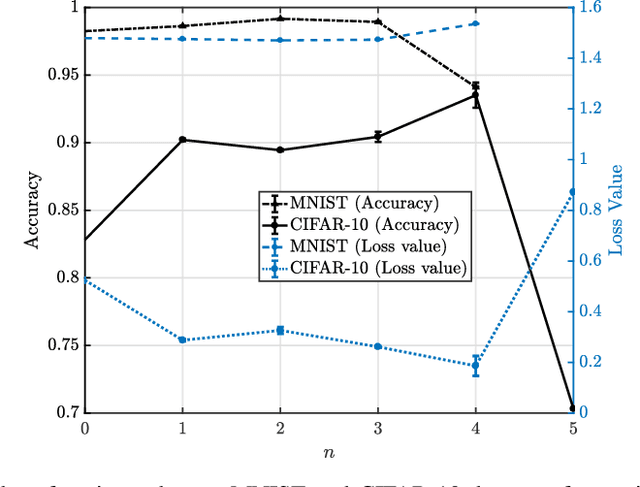
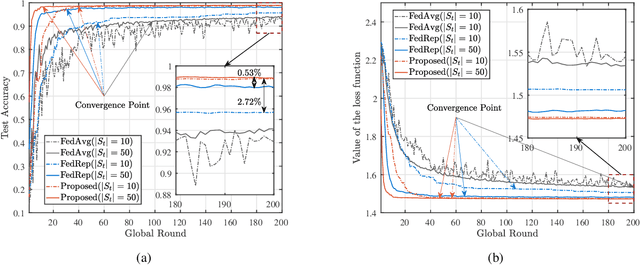
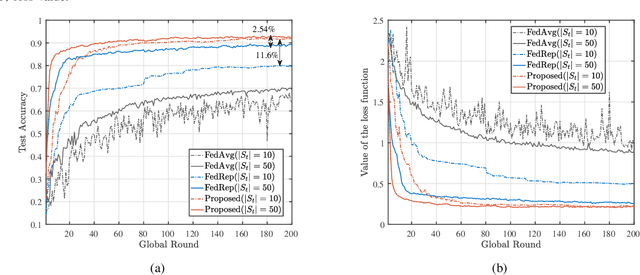
The limited communication resources, e.g., bandwidth and energy, and data heterogeneity across devices are two of the main bottlenecks for federated learning (FL). To tackle these challenges, we first devise a novel FL framework with partial model aggregation (PMA), which only aggregates the lower layers of neural networks responsible for feature extraction while the upper layers corresponding to complex pattern recognition remain at devices for personalization. The proposed PMA-FL is able to address the data heterogeneity and reduce the transmitted information in wireless channels. We then obtain a convergence bound of the framework under a non-convex loss function setting. With the aid of this bound, we define a new objective function, named the scheduled data sample volume, to transfer the original inexplicit optimization problem into a tractable one for device scheduling, bandwidth allocation, computation and communication time division. Our analysis reveals that the optimal time division is achieved when the communication and computation parts of PMA-FL have the same power. We also develop a bisection method to solve the optimal bandwidth allocation policy and use the set expansion algorithm to address the optimal device scheduling. Compared with the state-of-the-art benchmarks, the proposed PMA-FL improves 2.72% and 11.6% accuracy on two typical heterogeneous datasets, i.e., MINIST and CIFAR-10, respectively. In addition, the proposed joint dynamic device scheduling and resource optimization approach achieve slightly higher accuracy than the considered benchmarks, but they provide a satisfactory energy and time reduction: 29% energy or 20% time reduction on the MNIST; and 25% energy or 12.5% time reduction on the CIFAR-10.
Wild ToFu: Improving Range and Quality of Indirect Time-of-Flight Depth with RGB Fusion in Challenging Environments
Dec 07, 2021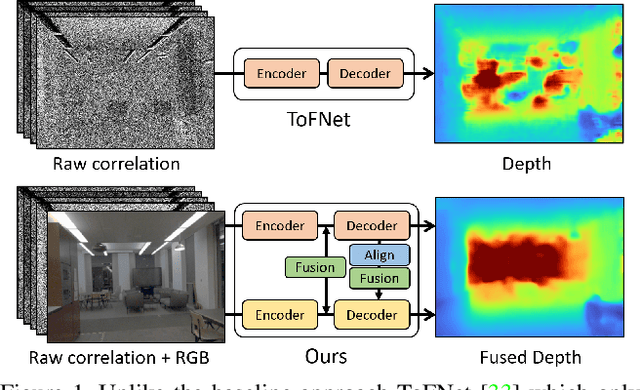

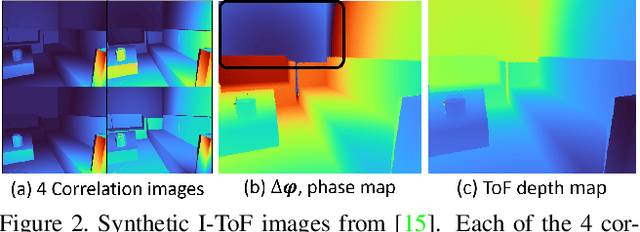
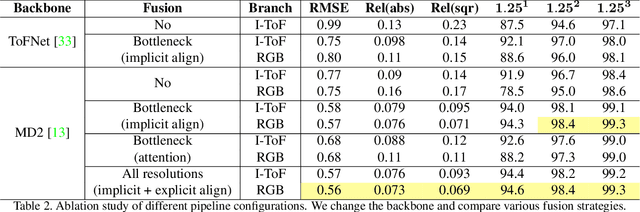
Indirect Time-of-Flight (I-ToF) imaging is a widespread way of depth estimation for mobile devices due to its small size and affordable price. Previous works have mainly focused on quality improvement for I-ToF imaging especially curing the effect of Multi Path Interference (MPI). These investigations are typically done in specifically constrained scenarios at close distance, indoors and under little ambient light. Surprisingly little work has investigated I-ToF quality improvement in real-life scenarios where strong ambient light and far distances pose difficulties due to an extreme amount of induced shot noise and signal sparsity, caused by the attenuation with limited sensor power and light scattering. In this work, we propose a new learning based end-to-end depth prediction network which takes noisy raw I-ToF signals as well as an RGB image and fuses their latent representation based on a multi step approach involving both implicit and explicit alignment to predict a high quality long range depth map aligned to the RGB viewpoint. We test our approach on challenging real-world scenes and show more than 40% RMSE improvement on the final depth map compared to the baseline approach.
Real-time safety assessment of trajectories for autonomous driving
May 05, 2021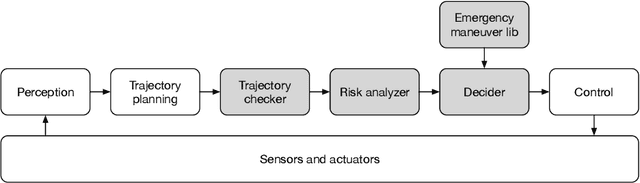
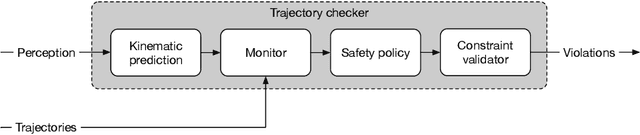
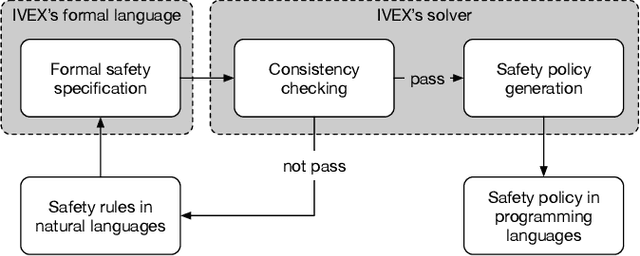
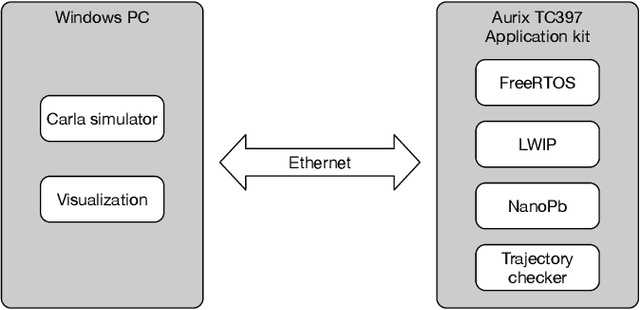
Autonomous vehicles (AVs) must always have a safe motion to guarantee that they are not causing any accidents. In an AV system, the motion of the vehicle is represented as a trajectory. A trajectory planning component is responsible to compute such a trajectory at run-time, taking into account the perception information about the environment, the dynamics of the vehicles, the predicted future states of other road users and a number of safety aspects. Due to the enormous amount of information to be considered, trajectory planning algorithms are complex, which makes it non-trivial to guarantee the safety of all planned trajectories. In this way, it is necessary to have an extra component to assess the safety of the planned trajectories at run-time. Such trajectory safety assessment component gives a diverse observation on the safety of AV trajectories and ensures that the AV only follows safe trajectories. We use the term trajectory checker to refer to the trajectory safety assessment component. The trajectory checker must evaluate planned trajectories against various safety rules, taking into account a large number of possibilities, including the worst-case behavior of other traffic participants. This must be done while guaranteeing hard real-time performance since the safety assessment is carried out while the vehicle is moving and in constant interaction with the environment. In this paper, we present a prototype of the trajectory checker we have developed at IVEX. We show how our approach works smoothly and accomplishes real-time constraints embedded in an Infineon Aurix TC397B automotive platform. Finally, we measure the performance of our trajectory checker prototype against a set of NCAPS-inspired scenarios.
Weakly-supervised High-fidelity Ultrasound Video Synthesis with Feature Decoupling
Jul 01, 2022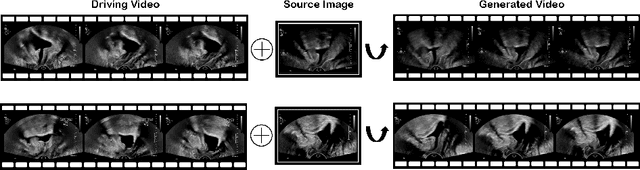
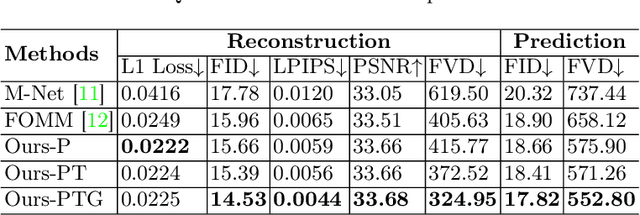
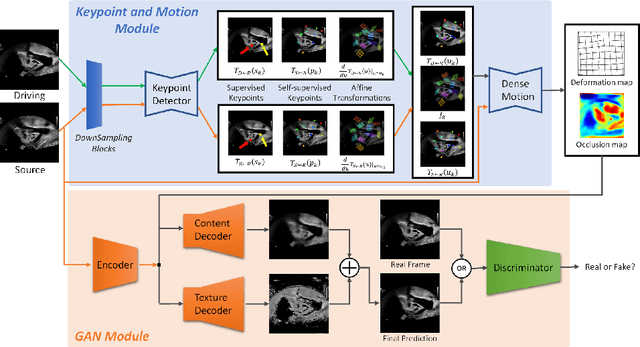

Ultrasound (US) is widely used for its advantages of real-time imaging, radiation-free and portability. In clinical practice, analysis and diagnosis often rely on US sequences rather than a single image to obtain dynamic anatomical information. This is challenging for novices to learn because practicing with adequate videos from patients is clinically unpractical. In this paper, we propose a novel framework to synthesize high-fidelity US videos. Specifically, the synthesis videos are generated by animating source content images based on the motion of given driving videos. Our highlights are three-fold. First, leveraging the advantages of self- and fully-supervised learning, our proposed system is trained in weakly-supervised manner for keypoint detection. These keypoints then provide vital information for handling complex high dynamic motions in US videos. Second, we decouple content and texture learning using the dual decoders to effectively reduce the model learning difficulty. Last, we adopt the adversarial training strategy with GAN losses for further improving the sharpness of the generated videos, narrowing the gap between real and synthesis videos. We validate our method on a large in-house pelvic dataset with high dynamic motion. Extensive evaluation metrics and user study prove the effectiveness of our proposed method.