 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuFFIN: Multifaceted Pronunciation Feedback Model with Interactive Hierarchical Neural Modeling
Oct 06, 2025Computer-assisted pronunciation training (CAPT) manages to facilitate second-language (L2) learners to practice pronunciation skills by offering timely and instructive feedback. To examine pronunciation proficiency from multiple facets, existing methods for CAPT broadly fall into two categories: mispronunciation detection and diagnosis (MDD) as well as automatic pronunciation assessment (APA). The former aims to pinpoint phonetic pronunciation errors and provide diagnostic feedback, while the latter seeks instead to quantify pronunciation proficiency pertaining to various aspects. Despite the natural complementarity between MDD and APA, researchers and practitioners, however, often treat them as independent tasks with disparate modeling paradigms. In light of this, we in this paper first introduce MuFFIN, a Multi-Faceted pronunciation Feedback model with an Interactive hierarchical Neural architecture, to jointly address the tasks of MDD and APA. To better capture the nuanced distinctions between phonemes in the feature space, a novel phoneme-contrastive ordinal regularization mechanism is then put forward to optimize the proposed model to generate more phoneme-discriminative features while factoring in the ordinality of the aspect scores. In addition, to address the intricate data imbalance problem in MDD, we design a simple yet effective training objective, which is specifically tailored to perturb the outputs of a phoneme classifier with the phoneme-specific variations, so as to better render the distribution of predicted phonemes meanwhile considering their mispronunciation characteristics. A series of experiments conducted on the Speechocean762 benchmark dataset demonstrates the efficacy of our method in relation to several cutting-edge baselines, showing state-of-the-art performance on both the APA and MDD tasks.
Automated Speaking Assessment of Conversation Tests with Novel Graph-based Modeling on Spoken Response Coherence
Sep 11, 2024Automated speaking assessment in conversation tests (ASAC) aims to evaluate the overall speaking proficiency of an L2 (second-language) speaker in a setting where an interlocutor interacts with one or more candidates. Although prior ASAC approaches have shown promising performance on their respective datasets, there is still a dearth of research specifically focused on incorporating the coherence of the logical flow within a conversation into the grading model. To address this critical challenge, we propose a hierarchical graph model that aptly incorporates both broad inter-response interactions (e.g., discourse relations) and nuanced semantic information (e.g., semantic words and speaker intents), which is subsequently fused with contextual information for the final prediction. Extensive experimental results on the NICT-JLE benchmark dataset suggest that our proposed modeling approach can yield considerable improvements in prediction accuracy with respect to various assessment metrics, as compared to some strong baselines. This also sheds light on the importance of investigating coherence-related facets of spoken responses in ASAC.
An Effective Context-Balanced Adaptation Approach for Long-Tailed Speech Recognition
Sep 10, 2024



End-to-end (E2E) automatic speech recognition (ASR) models have become standard practice for various commercial applications. However, in real-world scenarios, the long-tailed nature of word distribution often leads E2E ASR models to perform well on common words but fall short in recognizing uncommon ones. Recently, the notion of a contextual adapter (CA) was proposed to infuse external knowledge represented by a context word list into E2E ASR models. Although CA can improve recognition performance on rare words, two crucial data imbalance problems remain. First, when using low-frequency words as context words during training, since these words rarely occur in the utterance, CA becomes prone to overfit on attending to the <no-context> token due to higher-frequency words not being present in the context list. Second, the long-tailed distribution within the context list itself still causes the model to perform poorly on low-frequency context words. In light of this, we explore in-depth the impact of altering the context list to have words with different frequency distributions on model performance, and meanwhile extend CA with a simple yet effective context-balanced learning objective. A series of experiments conducted on the AISHELL-1 benchmark dataset suggests that using all vocabulary words from the training corpus as the context list and pairing them with our balanced objective yields the best performance, demonstrating a significant reduction in character error rate (CER) by up to 1.21% and a more pronounced 9.44% reduction in the error rate of zero-shot words.
ConPCO: Preserving Phoneme Characteristics for Automatic Pronunciation Assessment Leveraging Contrastive Ordinal Regularization
Jun 05, 2024Automatic pronunciation assessment (APA) manages to evaluate the pronunciation proficiency of a second language (L2) learner in a target language. Existing efforts typically draw on regression models for proficiency score prediction, where the models are trained to estimate target values without explicitly accounting for phoneme-awareness in the feature space. In this paper, we propose a contrastive phonemic ordinal regularizer (ConPCO) tailored for regression-based APA models to generate more phoneme-discriminative features while considering the ordinal relationships among the regression targets. The proposed ConPCO first aligns the phoneme representations of an APA model and textual embeddings of phonetic transcriptions via contrastive learning. Afterward, the phoneme characteristics are retained by regulating the distances between inter- and intra-phoneme categories in the feature space while allowing for the ordinal relationships among the output targets. We further design and develop a hierarchical APA model to evaluate the effectiveness of our method. Extensive experiments conducted on the speechocean762 benchmark dataset suggest the feasibility and efficacy of our approach in relation to some cutting-edge baselines.
DANCER: Entity Description Augmented Named Entity Corrector for Automatic Speech Recognition
Apr 11, 2024



End-to-end automatic speech recognition (E2E ASR) systems often suffer from mistranscription of domain-specific phrases, such as named entities, sometimes leading to catastrophic failures in downstream tasks. A family of fast and lightweight named entity correction (NEC) models for ASR have recently been proposed, which normally build on phonetic-level edit distance algorithms and have shown impressive NEC performance. However, as the named entity (NE) list grows, the problems of phonetic confusion in the NE list are exacerbated; for example, homophone ambiguities increase substantially. In view of this, we proposed a novel Description Augmented Named entity CorrEctoR (dubbed DANCER), which leverages entity descriptions to provide additional information to facilitate mitigation of phonetic confusion for NEC on ASR transcription. To this end, an efficient entity description augmented masked language model (EDA-MLM) comprised of a dense retrieval model is introduced, enabling MLM to adapt swiftly to domain-specific entities for the NEC task. A series of experiments conducted on the AISHELL-1 and Homophone datasets confirm the effectiveness of our modeling approach. DANCER outperforms a strong baseline, the phonetic edit-distance-based NEC model (PED-NEC), by a character error rate (CER) reduction of about 7% relatively on AISHELL-1 for named entities. More notably, when tested on Homophone that contain named entities of high phonetic confusion, DANCER offers a more pronounced CER reduction of 46% relatively over PED-NEC for named entities.
Preserving Phonemic Distinctions for Ordinal Regression: A Novel Loss Function for Automatic Pronunciation Assessment
Oct 04, 2023



Automatic pronunciation assessment (APA) manages to quantify the pronunciation proficiency of a second language (L2) learner in a language. Prevailing approaches to APA normally leverage neural models trained with a regression loss function, such as the mean-squared error (MSE) loss, for proficiency level prediction. Despite most regression models can effectively capture the ordinality of proficiency levels in the feature space, they are confronted with a primary obstacle that different phoneme categories with the same proficiency level are inevitably forced to be close to each other, retaining less phoneme-discriminative information. On account of this, we devise a phonemic contrast ordinal (PCO) loss for training regression-based APA models, which aims to preserve better phonemic distinctions between phoneme categories meanwhile considering ordinal relationships of the regression target output. Specifically, we introduce a phoneme-distinct regularizer into the MSE loss, which encourages feature representations of different phoneme categories to be far apart while simultaneously pulling closer the representations belonging to the same phoneme category by means of weighted distances. An extensive set of experiments carried out on the speechocean762 benchmark dataset suggest the feasibility and effectiveness of our model in relation to some existing state-of-the-art models.
AVATAR: Robust Voice Search Engine Leveraging Autoregressive Document Retrieval and Contrastive Learning
Sep 04, 2023



Voice, as input, has progressively become popular on mobiles and seems to transcend almost entirely text input. Through voice, the voice search (VS) system can provide a more natural way to meet user's information needs. However, errors from the automatic speech recognition (ASR) system can be catastrophic to the VS system. Building on the recent advanced lightweight autoregressive retrieval model, which has the potential to be deployed on mobiles, leading to a more secure and personal VS assistant. This paper presents a novel study of VS leveraging autoregressive retrieval and tackles the crucial problems facing VS, viz. the performance drop caused by ASR noise, via data augmentations and contrastive learning, showing how explicit and implicit modeling the noise patterns can alleviate the problems. A series of experiments conducted on the Open-Domain Question Answering (ODSQA) confirm our approach's effectiveness and robustness in relation to some strong baseline systems.
Conversational speech recognition leveraging effective fusion methods for cross-utterance language modeling
Nov 05, 2021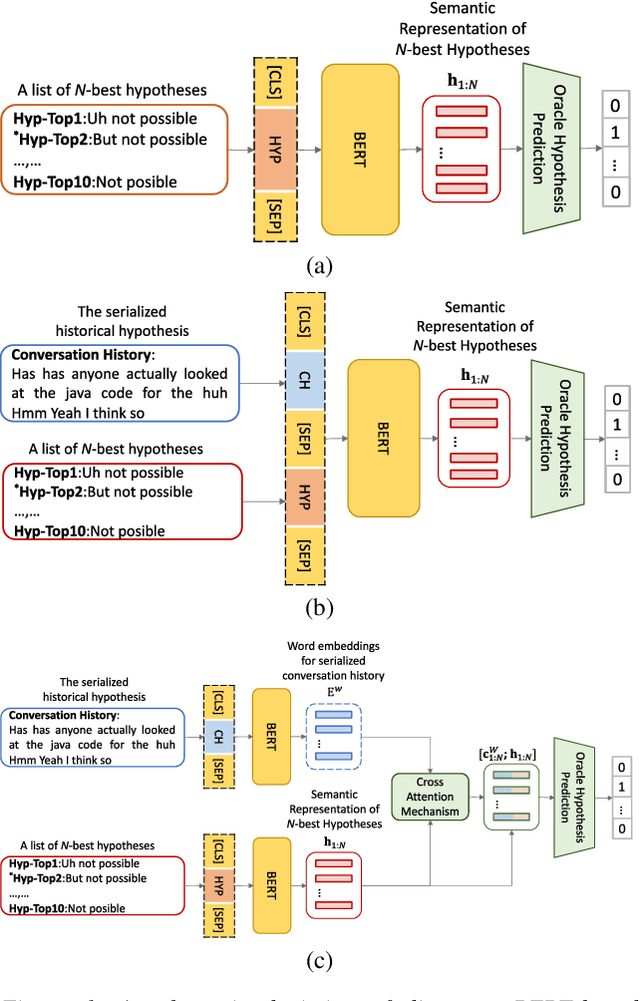
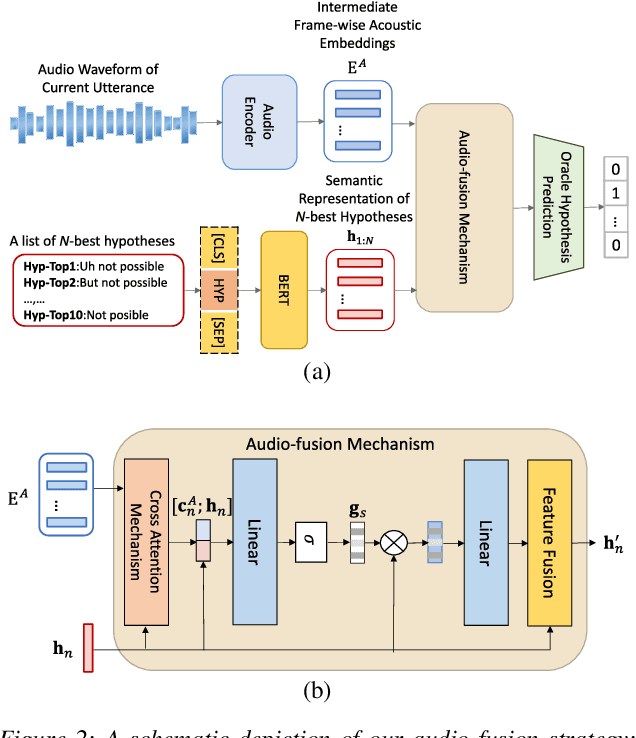

Conversational speech normally is embodied with loose syntactic structures at the utterance level but simultaneously exhibits topical coherence relations across consecutive utterances. Prior work has shown that capturing longer context information with a recurrent neural network or long short-term memory language model (LM) may suffer from the recent bias while excluding the long-range context. In order to capture the long-term semantic interactions among words and across utterances, we put forward disparate conversation history fusion methods for language modeling in automatic speech recognition (ASR) of conversational speech. Furthermore, a novel audio-fusion mechanism is introduced, which manages to fuse and utilize the acoustic embeddings of a current utterance and the semantic content of its corresponding conversation history in a cooperative way. To flesh out our ideas, we frame the ASR N-best hypothesis rescoring task as a prediction problem, leveraging BERT, an iconic pre-trained LM, as the ingredient vehicle to facilitate selection of the oracle hypothesis from a given N-best hypothesis list. Empirical experiments conducted on the AMI benchmark dataset seem to demonstrate the feasibility and efficacy of our methods in relation to some current top-of-line methods.
Exploring Non-Autoregressive End-To-End Neural Modeling For English Mispronunciation Detection And Diagnosis
Nov 01, 2021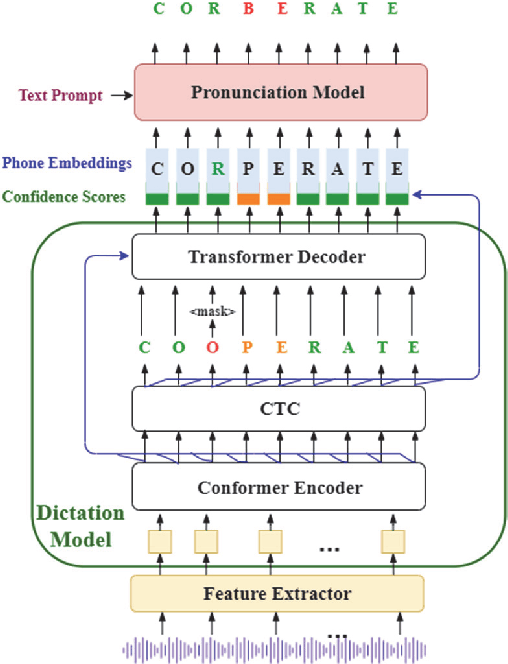
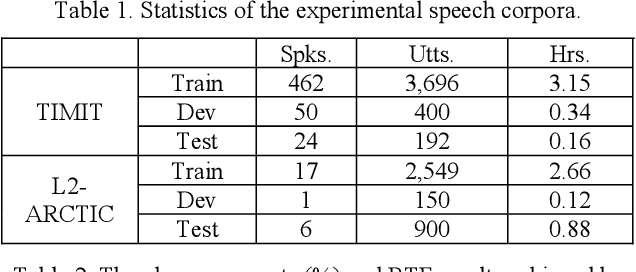
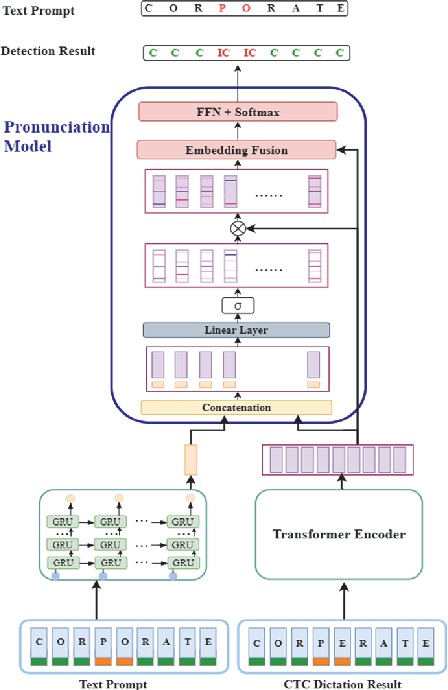
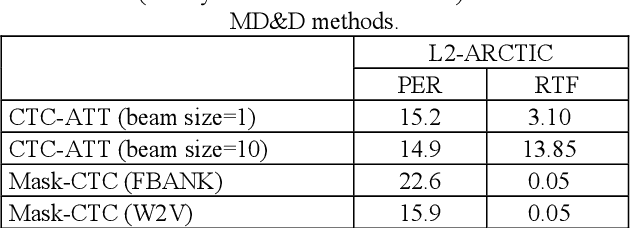
End-to-end (E2E) neural modeling has emerged as one predominant school of thought to develop computer-assisted language training (CAPT) systems, showing competitive performance to conventional pronunciation-scoring based methods. However, current E2E neural methods for CAPT are faced with at least two pivotal challenges. On one hand, most of the E2E methods operate in an autoregressive manner with left-to-right beam search to dictate the pronunciations of an L2 learners. This however leads to very slow inference speed, which inevitably hinders their practical use. On the other hand, E2E neural methods are normally data greedy and meanwhile an insufficient amount of nonnative training data would often reduce their efficacy on mispronunciation detection and diagnosis (MD&D). In response, we put forward a novel MD&D method that leverages non-autoregressive (NAR) E2E neural modeling to dramatically speed up the inference time while maintaining performance in line with the conventional E2E neural methods. In addition, we design and develop a pronunciation modeling network stacked on top of the NAR E2E models of our method to further boost the effectiveness of MD&D. Empirical experiments conducted on the L2-ARCTIC English dataset seems to validate the feasibility of our method, in comparison to some top-of-the-line E2E models and an iconic pronunciation-scoring based method built on a DNN-HMM acoustic model.
Maximum F1-score training for end-to-end mispronunciation detection and diagnosis of L2 English speech
Aug 31, 2021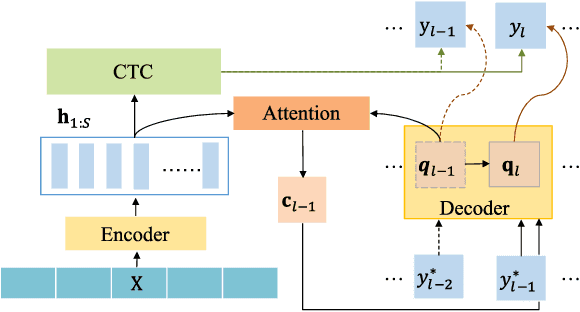
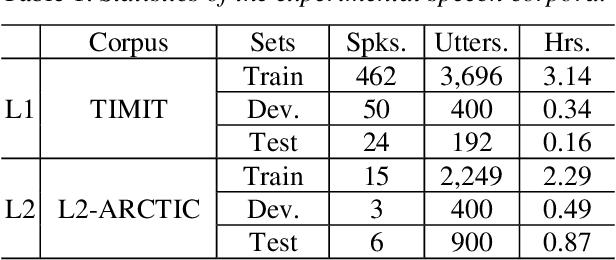

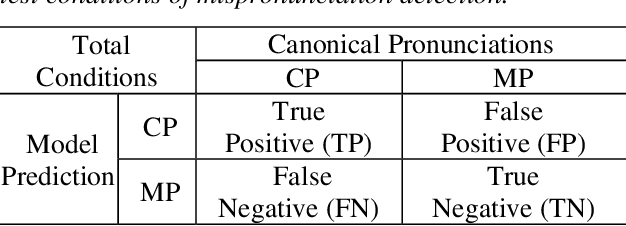
End-to-end (E2E) neural models are increasingly attracting attention as a promising modeling approach for mispronunciation detection and diagnosis (MDD). Typically, these models are trained by optimizing a cross-entropy criterion, which corresponds to improving the log-likelihood of the training data. However, there is a discrepancy between the objectives of model training and the MDD evaluation, since the performance of an MDD model is commonly evaluated in terms of F1-score instead of word error rate (WER). In view of this, we in this paper explore the use of a discriminative objective function for training E2E MDD models, which aims to maximize the expected F1-score directly. To further facilitate maximum F1-score training, we randomly perturb fractions of the labels of phonetic confusing pairs in the training utterances of L2 (second language) learners to generate artificial pronunciation error patterns for data augmentation. A series of experiments conducted on the L2-ARCTIC dataset show that our proposed method can yield considerable performance improvements in relation to some state-of-the-art E2E MDD approaches and the conventional GOP method.