 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QNet: A Quantum-native Sequence Encoder Architecture
Oct 31, 2022
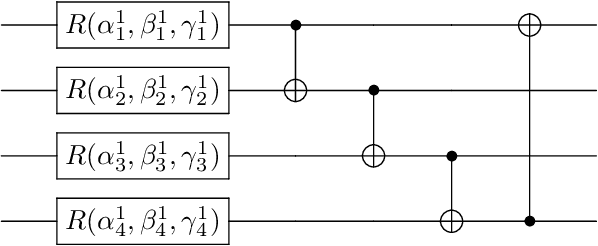
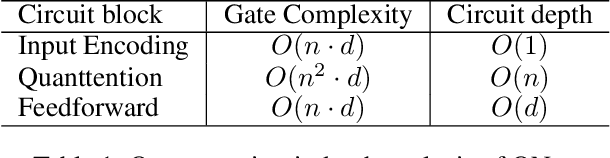
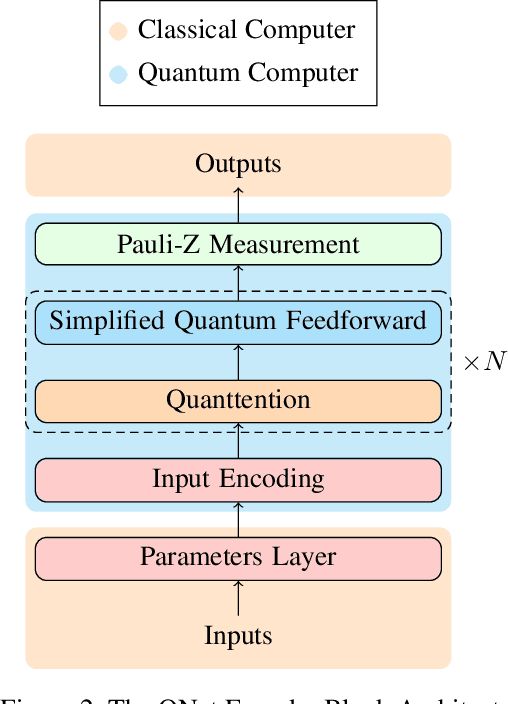
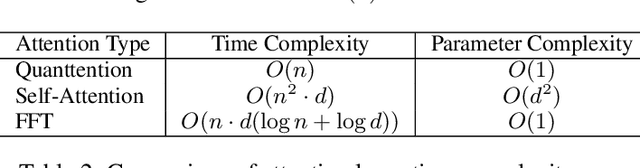
This work investigates how current quantum computers can improve the performance of natural language processing tasks. To achieve this goal, we proposed QNet, a novel sequence encoder model entirely inferences on the quantum computer using a minimum number of qubits. QNet is inspired by Transformer, the state-of-the-art neural network model based on the attention mechanism to relate the tokens. While the attention mechanism requires time complexity of $O(n^2 \cdot d)$ to perform matrix multiplication operations, QNet has merely $O(n+d)$ quantum circuit depth, where $n$ and $d$ represent the length of the sequence and the embedding size, respectively. To employ QNet on the NISQ devices, ResQNet, a quantum-classical hybrid model composed of several QNet blocks linked by residual connections, is introduced. We evaluate ResQNet on various natural language processing tasks, including text classification, rating score prediction, and named entity recognition. ResQNet exhibits a 6% to 818% performance gain on all these tasks over classical state-of-the-art models using the exact embedding dimensions. In summary, this work demonstrates the advantage of quantum computing in natural language processing tasks.
AutoBag: Learning to Open Plastic Bags and Insert Objects
Oct 31, 2022


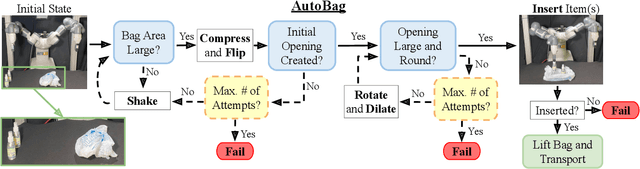
Thin plastic bags are ubiquitous in retail stores, healthcare, food handling, recycling, homes, and school lunchrooms. They are challenging both for perception (due to specularities and occlusions) and for manipulation (due to the dynamics of their 3D deformable structure). We formulate the task of manipulating common plastic shopping bags with two handles from an unstructured initial state to a state where solid objects can be inserted into the bag for transport. We propose a self-supervised learning framework where a dual-arm robot learns to recognize the handles and rim of plastic bags using UV-fluorescent markings; at execution time, the robot does not use UV markings or UV light. We propose Autonomous Bagging (AutoBag), where the robot uses the learned perception model to open plastic bags through iterative manipulation. We present novel metrics to evaluate the quality of a bag state and new motion primitives for reorienting and opening bags from visual observations. In physical experiments, a YuMi robot using AutoBag is able to open bags and achieve a success rate of 16/30 for inserting at least one item across a variety of initial bag configurations. Supplementary material is available at https://sites.google.com/view/autobag .
Learning Modular Robot Locomotion from Demonstrations
Oct 31, 2022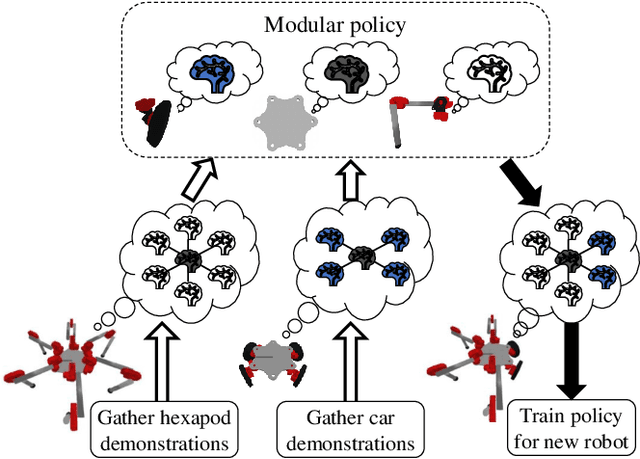
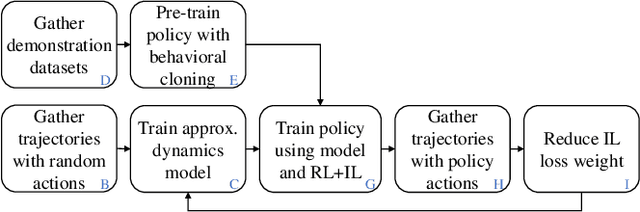
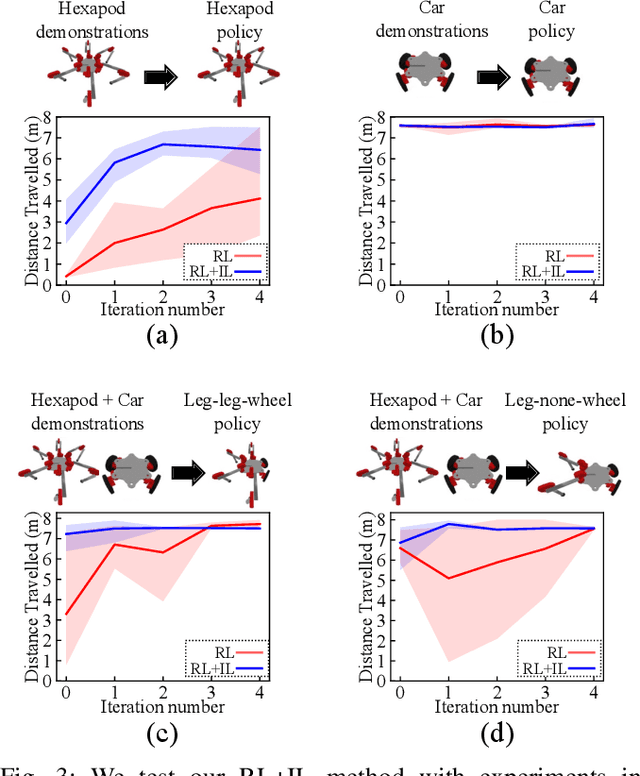
Modular robots can be reconfigured to create a variety of designs from a small set of components. But constructing a robot's hardware on its own is not enough -- each robot needs a controller. One could create controllers for some designs individually, but developing policies for additional designs can be time consuming. This work presents a method that uses demonstrations from one set of designs to accelerate policy learning for additional designs. We leverage a learning framework in which a graph neural network is made up of modular components, each component corresponds to a type of module (e.g., a leg, wheel, or body) and these components can be recombined to learn from multiple designs at once. In this paper we develop a combined reinforcement and imitation learning algorithm. Our method is novel because the policy is optimized to both maximize a reward for one design, and simultaneously imitate demonstrations from different designs, within one objective function. We show that when the modular policy is optimized with this combined objective, demonstrations from one set of designs influence how the policy behaves on a different design, decreasing the number of training iterations needed.
GAMEOPT: Optimal Real-time Multi-Agent Planning and Control at Dynamic Intersections
Feb 23, 2022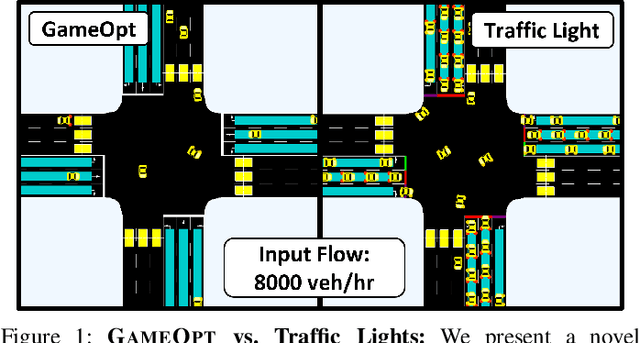
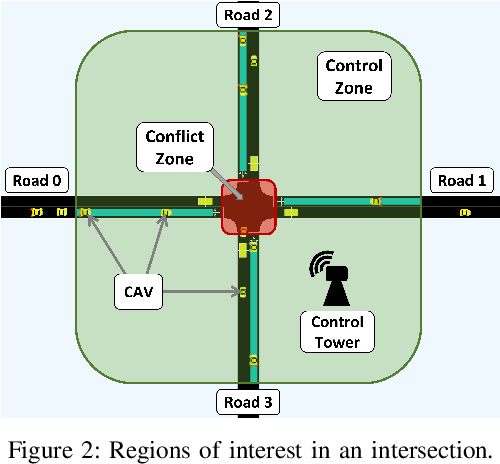
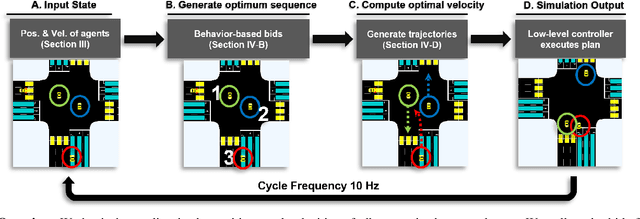
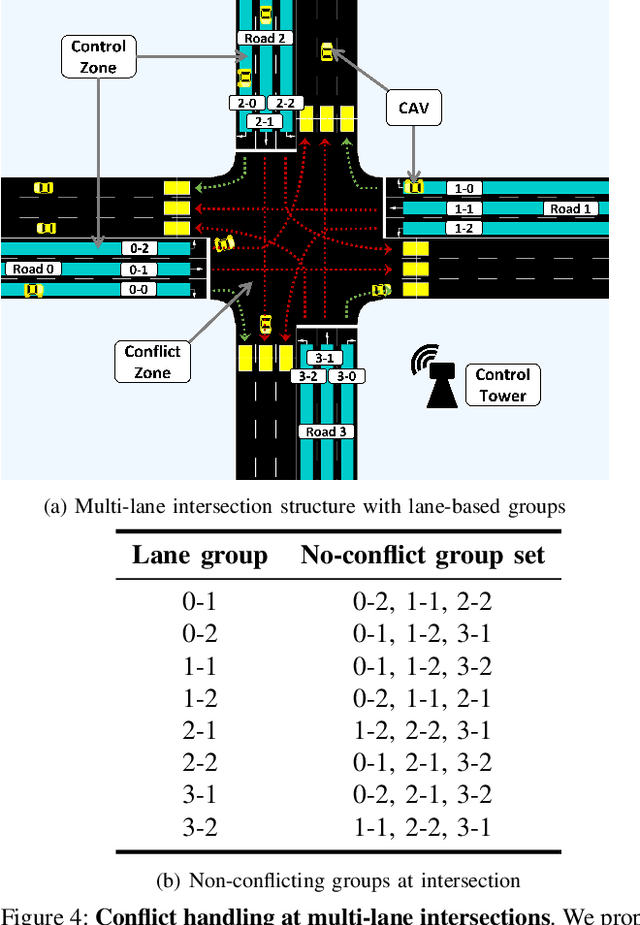
Non-signalized intersections are one of the more complex, prone to accident scenarios faced in modern transportation networks. Cooperation among Connected Autonomous Vehicles (CAVs) is a promising approach to intersection control which provides increased safety, efficiency and fairness. We propose a novel hierarchical approach to navigating these dynamic, multi-lane, intersections. Our algorithm consists of a hierarchical formulation that first uses an auction mechanism to generate a priority order over all the agents, followed by an optimization-based trajectory planner that computes the optimal velocity commands that respects the priority order. The coupling of an auction mechanism for generating a vehicle entrance sequence and an optimization mechanism for trajectory planning, allows for real-time capable operation in high density multi-agent traffic, while providing formal guarantees in terms of fairness, safety, and efficiency. Our approach can operate at real-time speeds ($<10$ milliseconds), which is at least $40\times$ faster than prior methods. Tested on the SUMO simulator, our algorithm reduces congestion by at least $60\%$, time taken to reach the goal by $75\%$, and fuel consumption by $33\%$, compared to auction-based approaches and signaled approaches using traffic-lights and stop signs.
Event-guided Deblurring of Unknown Exposure Time Videos
Dec 13, 2021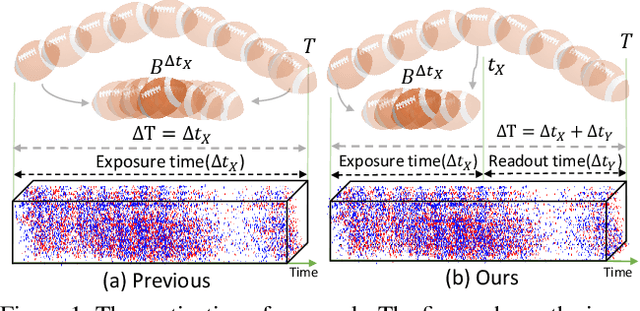

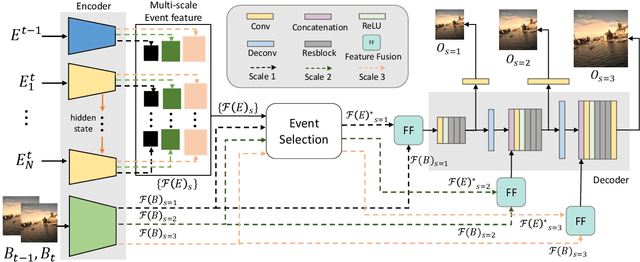
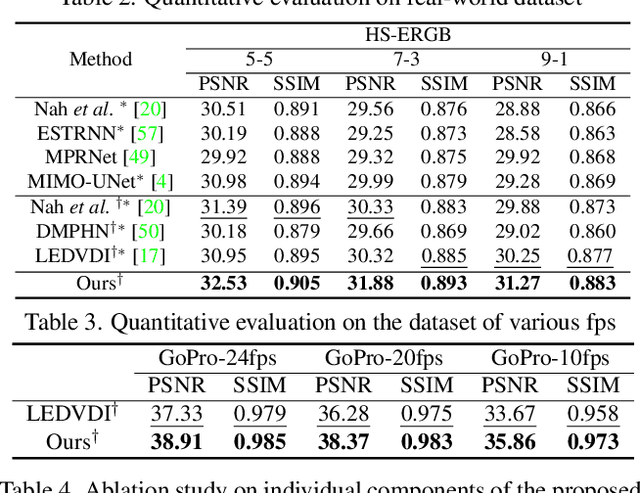
Video deblurring is a highly ill-posed problem due to the loss of motion information in the blur degradation process. Since event cameras can capture apparent motion with a high temporal resolution, several attempts have explored the potential of events for guiding video deblurring. These methods generally assume that the exposure time is the same as the reciprocal of the video frame rate. However,this is not true in real situations, and the exposure time might be unknown and dynamically varies depending on the video shooting environment(e.g., illumination condition). In this paper, we address the event-guided video deblurring assuming dynamically variable unknown exposure time of the frame-based camera. To this end, we first derive a new formulation for event-guided video deblurring by considering the exposure and readout time in the video frame acquisition process. We then propose a novel end-toend learning framework for event-guided video deblurring. In particular, we design a novel Exposure Time-based Event Selection(ETES) module to selectively use event features by estimating the cross-modal correlation between the features from blurred frames and the events. Moreover, we propose a feature fusion module to effectively fuse the selected features from events and blur frames. We conduct extensive experiments on various datasets and demonstrate that our method achieves state-of-the-art performance. Our project code and pretrained models will be available.
TridentSE: Guiding Speech Enhancement with 32 Global Tokens
Oct 24, 2022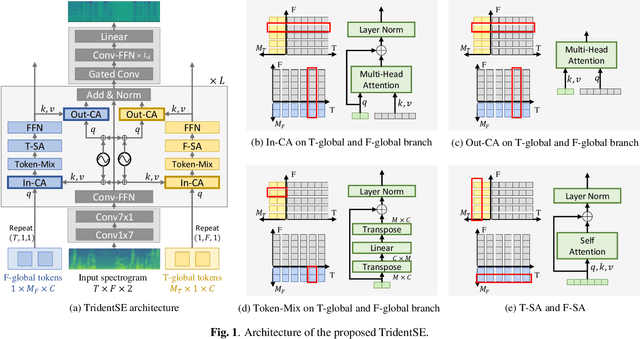
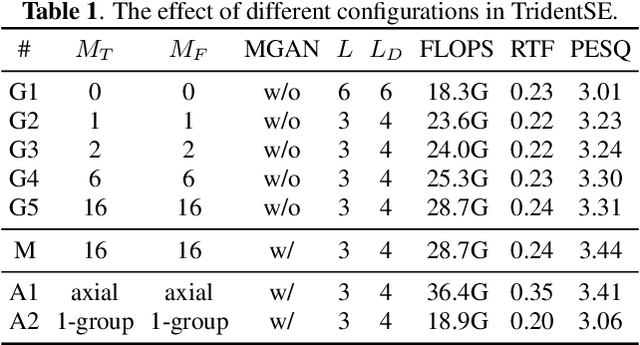
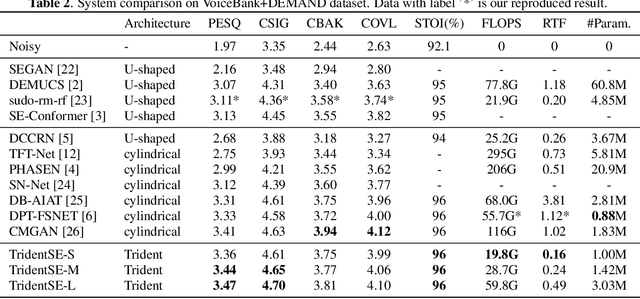
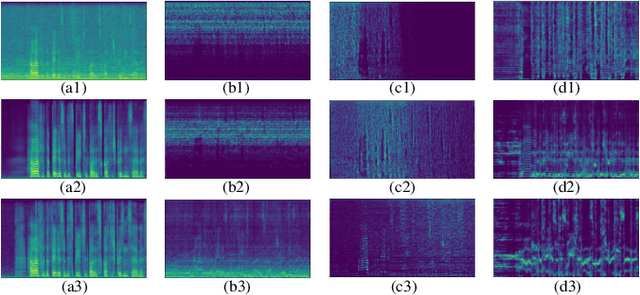
In this paper, we present TridentSE, a novel architecture for speech enhancement, which is capable of efficiently capturing both global information and local details. TridentSE maintains T-F bin level representation to capture details, and uses a small number of global tokens to process the global information. Information is propagated between the local and the global representations through cross attention modules. To capture both inter- and intra-frame information, the global tokens are divided into two groups to process along the time and the frequency axis respectively. A metric discriminator is further employed to guide our model to achieve higher perceptual quality. Even with significantly lower computational cost, TridentSE outperforms a variety of previous speech enhancement methods, achieving a PESQ of 3.47 on VoiceBank+DEMAND dataset and a PESQ of 3.44 on DNS no-reverb test set. Visualization shows that the global tokens learn diverse and interpretable global patterns.
Distribution Compression in Near-linear Time
Nov 17, 2021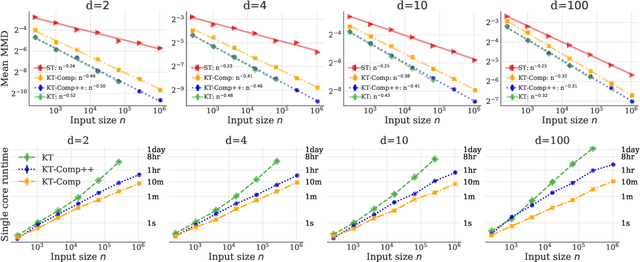
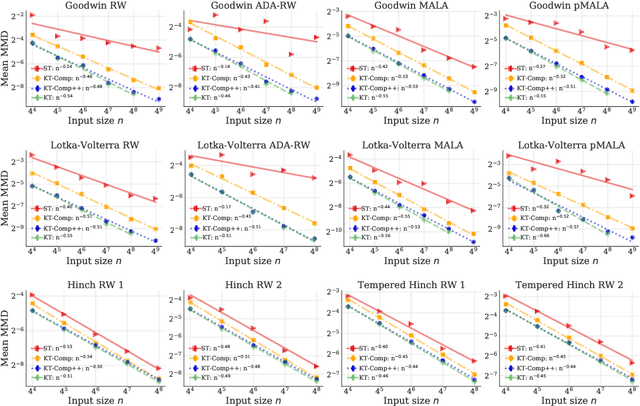
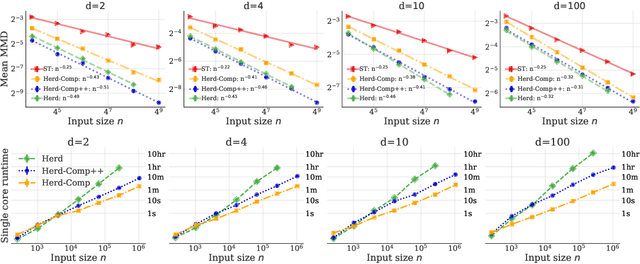
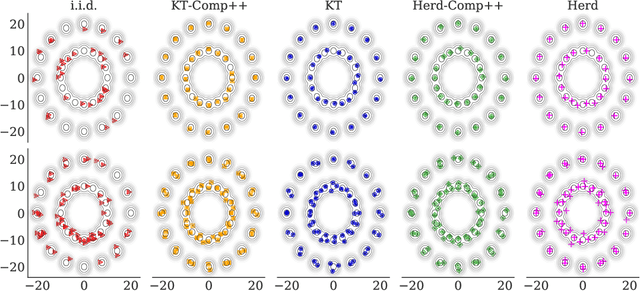
In distribution compression, one aims to accurately summarize a probability distribution $\mathbb{P}$ using a small number of representative points. Near-optimal thinning procedures achieve this goal by sampling $n$ points from a Markov chain and identifying $\sqrt{n}$ points with $\widetilde{\mathcal{O}}(1/\sqrt{n})$ discrepancy to $\mathbb{P}$. Unfortunately, these algorithms suffer from quadratic or super-quadratic runtime in the sample size $n$. To address this deficiency, we introduce Compress++, a simple meta-procedure for speeding up any thinning algorithm while suffering at most a factor of $4$ in error. When combined with the quadratic-time kernel halving and kernel thinning algorithms of Dwivedi and Mackey (2021), Compress++ delivers $\sqrt{n}$ points with $\mathcal{O}(\sqrt{\log n/n})$ integration error and better-than-Monte-Carlo maximum mean discrepancy in $\mathcal{O}(n \log^3 n)$ time and $\mathcal{O}( \sqrt{n} \log^2 n )$ space. Moreover, Compress++ enjoys the same near-linear runtime given any quadratic-time input and reduces the runtime of super-quadratic algorithms by a square-root factor. In our benchmarks with high-dimensional Monte Carlo samples and Markov chains targeting challenging differential equation posteriors, Compress++ matches or nearly matches the accuracy of its input algorithm in orders of magnitude less time.
Domain Adaptation for Time-Series Classification to Mitigate Covariate Shift
Apr 07, 2022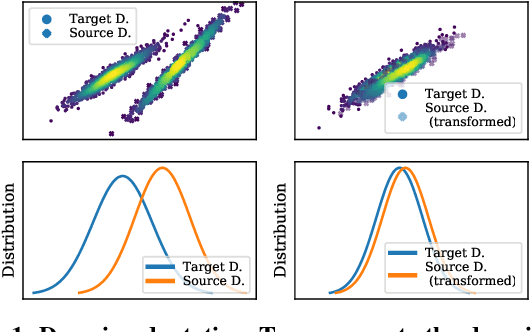
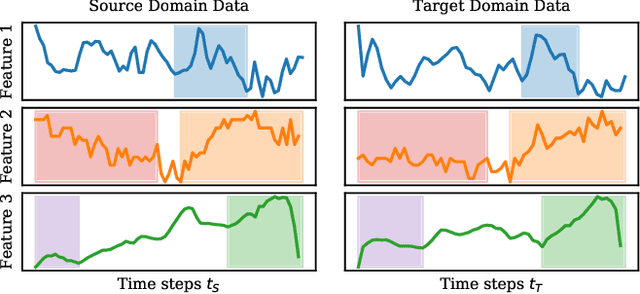
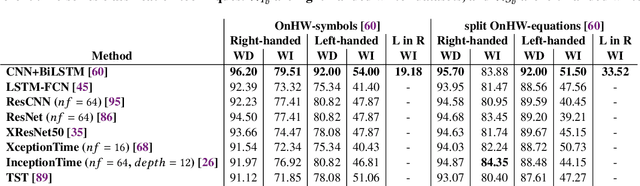
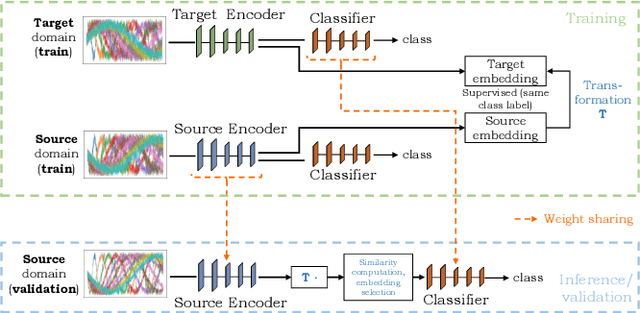
The performance of a machine learning model degrades when it is applied to data from a similar but different domain than the data it has initially been trained on. To mitigate this domain shift problem, domain adaptation (DA) techniques search for an optimal transformation that converts the (current) input data from a source domain to a target domain to learn a domain-invariant representations that reduces domain discrepancy. This paper proposes a novel supervised domain adaptation based on two steps. First, we search for an optimal class-dependent transformation from the source to the target domain from a few samples. We consider optimal transport methods such as the earth mover distance with Laplacian regularization, Sinkhorn transport and correlation alignment. Second, we use embedding similarity techniques to select the corresponding transformation at inference. We use correlation metrics and maximum mean discrepancy with higher-order moment matching techniques. We conduct an extensive evaluation on time-series datasets with domain shift including simulated and various online handwriting datasets to demonstrate the performance.
Average-Case Complexity of Tensor Decomposition for Low-Degree Polynomials
Nov 10, 2022Suppose we are given an $n$-dimensional order-3 symmetric tensor $T \in (\mathbb{R}^n)^{\otimes 3}$ that is the sum of $r$ random rank-1 terms. The problem of recovering the rank-1 components is possible in principle when $r \lesssim n^2$ but polynomial-time algorithms are only known in the regime $r \ll n^{3/2}$. Similar "statistical-computational gaps" occur in many high-dimensional inference tasks, and in recent years there has been a flurry of work on explaining the apparent computational hardness in these problems by proving lower bounds against restricted (yet powerful) models of computation such as statistical queries (SQ), sum-of-squares (SoS), and low-degree polynomials (LDP). However, no such prior work exists for tensor decomposition, largely because its hardness does not appear to be explained by a "planted versus null" testing problem. We consider a model for random order-3 tensor decomposition where one component is slightly larger in norm than the rest (to break symmetry), and the components are drawn uniformly from the hypercube. We resolve the computational complexity in the LDP model: $O(\log n)$-degree polynomial functions of the tensor entries can accurately estimate the largest component when $r \ll n^{3/2}$ but fail to do so when $r \gg n^{3/2}$. This provides rigorous evidence suggesting that the best known algorithms for tensor decomposition cannot be improved, at least by known approaches. A natural extension of the result holds for tensors of any fixed order $k \ge 3$, in which case the LDP threshold is $r \sim n^{k/2}$.
First Hitting Diffusion Models
Sep 02, 2022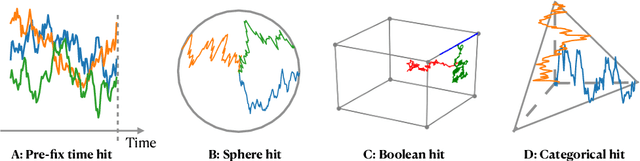
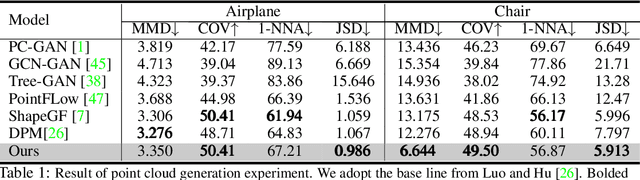
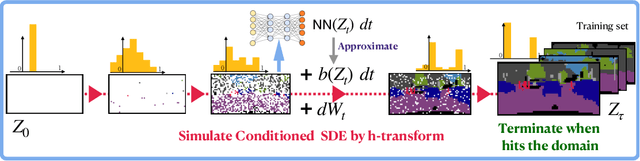
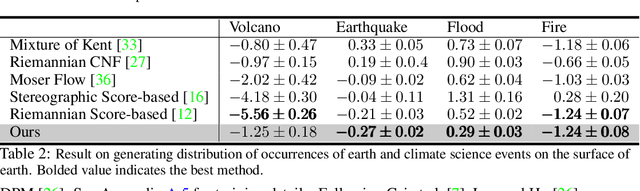
We propose a family of First Hitting Diffusion Models (FHDM), deep generative models that generate data with a diffusion process that terminates at a random first hitting time. This yields an extension of the standard fixed-time diffusion models that terminate at a pre-specified deterministic time. Although standard diffusion models are designed for continuous unconstrained data, FHDM is naturally designed to learn distributions on continuous as well as a range of discrete and structure domains. Moreover, FHDM enables instance-dependent terminate time and accelerates the diffusion process to sample higher quality data with fewer diffusion steps. Technically, we train FHDM by maximum likelihood estimation on diffusion trajectories augmented from observed data with conditional first hitting processes (i.e., bridge) derived based on Doob's $h$-transform, deviating from the commonly used time-reversal mechanism. We apply FHDM to generate data in various domains such as point cloud (general continuous distribution), climate and geographical events on earth (continuous distribution on the sphere), unweighted graphs (distribution of binary matrices), and segmentation maps of 2D images (high-dimensional categorical distribution). We observe considerable improvement compared with the state-of-the-art approaches in both quality and speed.