 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Image Enhancement Network for Mobile Devices Using Self-Feature Extraction and Dense Modulation
May 02, 2022
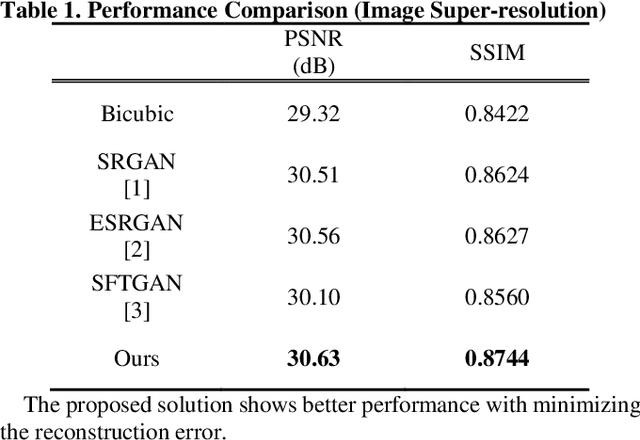
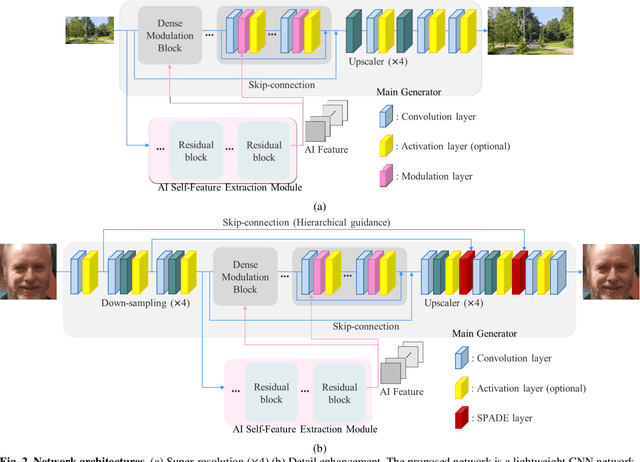

Convolutional neural network (CNN) based image enhancement methods such as super-resolution and detail enhancement have achieved remarkable performances. However, amounts of operations including convolution and parameters within the networks cost high computing power and need huge memory resource, which limits the applications with on-device requirements. Lightweight image enhancement network should restore details, texture, and structural information from low-resolution input images while keeping their fidelity. To address these issues, a lightweight image enhancement network is proposed. The proposed network include self-feature extraction module which produces modulation parameters from low-quality image itself, and provides them to modulate the features in the network. Also, dense modulation block is proposed for unit block of the proposed network, which uses dense connections of concatenated features applied in modulation layers. Experimental results demonstrate better performance over existing approaches in terms of both quantitative and qualitative evaluations.
Attention-based Ensemble for Deep Metric Learning
Aug 31, 2018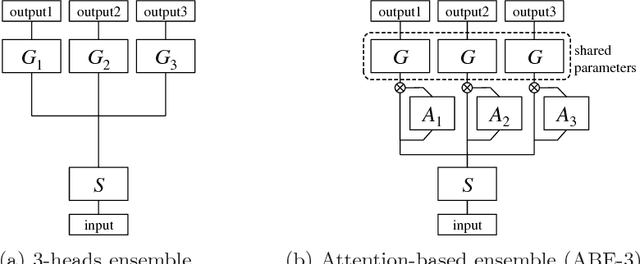
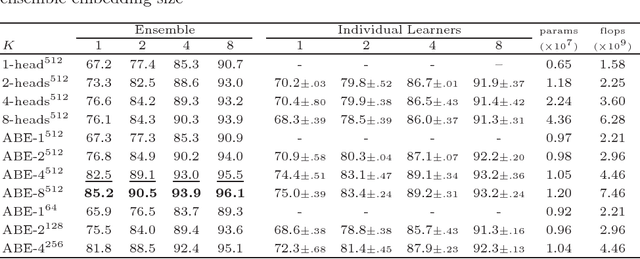
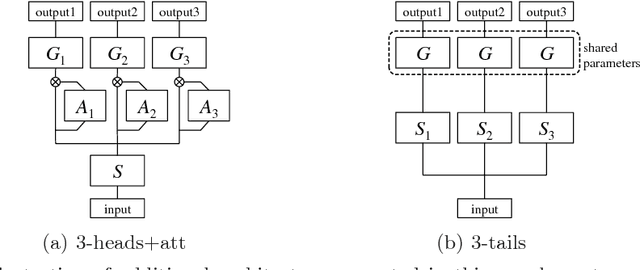

Deep metric learning aims to learn an embedding function, modeled as deep neural network. This embedding function usually puts semantically similar images close while dissimilar images far from each other in the learned embedding space. Recently, ensemble has been applied to deep metric learning to yield state-of-the-art results. As one important aspect of ensemble, the learners should be diverse in their feature embeddings. To this end, we propose an attention-based ensemble, which uses multiple attention masks, so that each learner can attend to different parts of the object. We also propose a divergence loss, which encourages diversity among the learners. The proposed method is applied to the standard benchmarks of deep metric learning and experimental results show that it outperforms the state-of-the-art methods by a significant margin on image retrieval tasks.