 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning for Solving Stochastic Vehicle Routing Problem with Time Windows
Feb 15, 2024
This paper introduces a reinforcement learning approach to optimize the Stochastic Vehicle Routing Problem with Time Windows (SVRP), focusing on reducing travel costs in goods delivery. We develop a novel SVRP formulation that accounts for uncertain travel costs and demands, alongside specific customer time windows. An attention-based neural network trained through reinforcement learning is employed to minimize routing costs. Our approach addresses a gap in SVRP research, which traditionally relies on heuristic methods, by leveraging machine learning. The model outperforms the Ant-Colony Optimization algorithm, achieving a 1.73% reduction in travel costs. It uniquely integrates external information, demonstrating robustness in diverse environments, making it a valuable benchmark for future SVRP studies and industry application.
Survival modeling using deep learning, machine learning and statistical methods: A comparative analysis for predicting mortality after hospital admission
Mar 04, 2024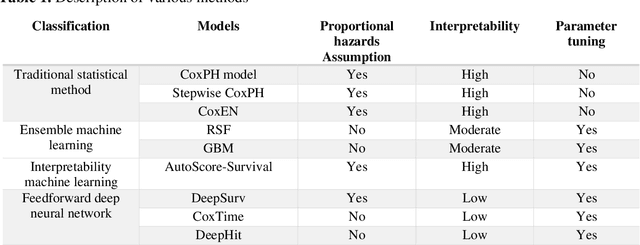
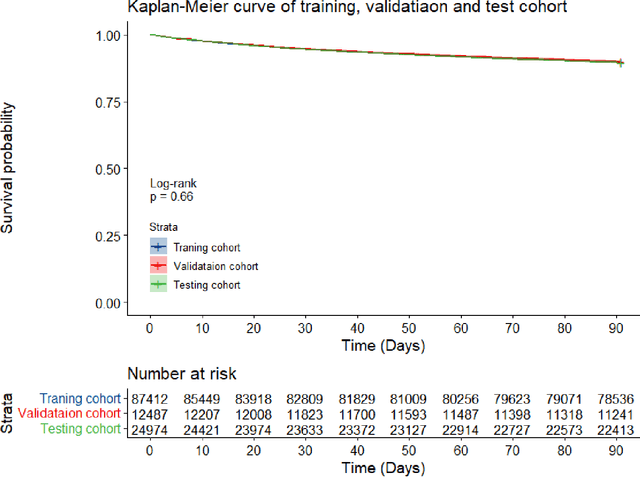
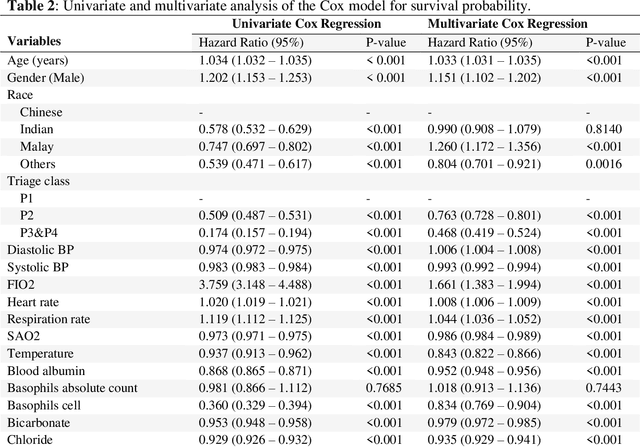
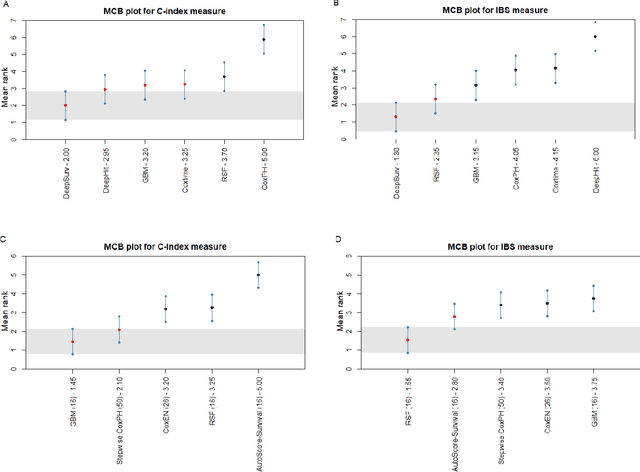
Survival analysis is essential for studying time-to-event outcomes and providing a dynamic understanding of the probability of an event occurring over time. Various survival analysis techniques, from traditional statistical models to state-of-the-art machine learning algorithms, support healthcare intervention and policy decisions. However, there remains ongoing discussion about their comparative performance. We conducted a comparative study of several survival analysis methods, including Cox proportional hazards (CoxPH), stepwise CoxPH, elastic net penalized Cox model, Random Survival Forests (RSF), Gradient Boosting machine (GBM) learning, AutoScore-Survival, DeepSurv, time-dependent Cox model based on neural network (CoxTime), and DeepHit survival neural network. We applied the concordance index (C-index) for model goodness-of-fit, and integral Brier scores (IBS) for calibration, and considered the model interpretability. As a case study, we performed a retrospective analysis of patients admitted through the emergency department of a tertiary hospital from 2017 to 2019, predicting 90-day all-cause mortality based on patient demographics, clinicopathological features, and historical data. The results of the C-index indicate that deep learning achieved comparable performance, with DeepSurv producing the best discrimination (DeepSurv: 0.893; CoxTime: 0.892; DeepHit: 0.891). The calibration of DeepSurv (IBS: 0.041) performed the best, followed by RSF (IBS: 0.042) and GBM (IBS: 0.0421), all using the full variables. Moreover, AutoScore-Survival, using a minimal variable subset, is easy to interpret, and can achieve good discrimination and calibration (C-index: 0.867; IBS: 0.044). While all models were satisfactory, DeepSurv exhibited the best discrimination and calibration. In addition, AutoScore-Survival offers a more parsimonious model and excellent interpretability.
Tuning-Free Accountable Intervention for LLM Deployment -- A Metacognitive Approach
Mar 08, 2024

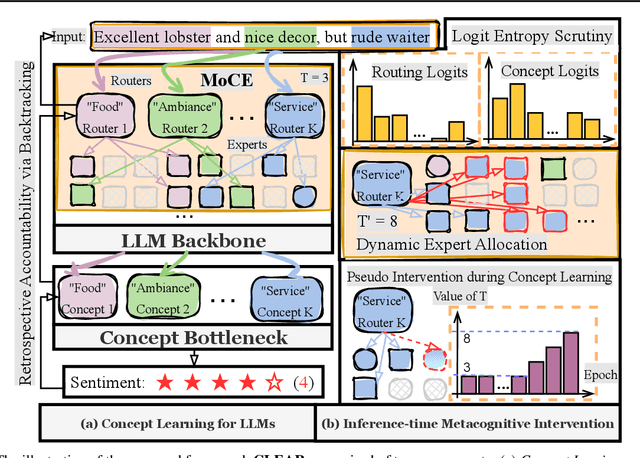
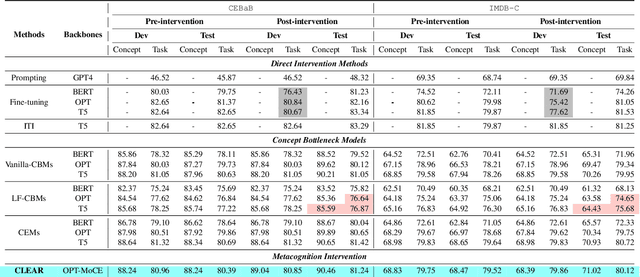
Large Language Models (LLMs) have catalyzed transformative advances across a spectrum of natural language processing tasks through few-shot or zero-shot prompting, bypassing the need for parameter tuning. While convenient, this modus operandi aggravates ``hallucination'' concerns, particularly given the enigmatic ``black-box'' nature behind their gigantic model sizes. Such concerns are exacerbated in high-stakes applications (e.g., healthcare), where unaccountable decision errors can lead to devastating consequences. In contrast, human decision-making relies on nuanced cognitive processes, such as the ability to sense and adaptively correct misjudgments through conceptual understanding. Drawing inspiration from human cognition, we propose an innovative \textit{metacognitive} approach, dubbed \textbf{CLEAR}, to equip LLMs with capabilities for self-aware error identification and correction. Our framework facilitates the construction of concept-specific sparse subnetworks that illuminate transparent decision pathways. This provides a novel interface for model \textit{intervention} after deployment. Our intervention offers compelling advantages: (\textit{i})~at deployment or inference time, our metacognitive LLMs can self-consciously identify potential mispredictions with minimum human involvement, (\textit{ii})~the model has the capability to self-correct its errors efficiently, obviating the need for additional tuning, and (\textit{iii})~the rectification procedure is not only self-explanatory but also user-friendly, enhancing the interpretability and accessibility of the model. By integrating these metacognitive features, our approach pioneers a new path toward engendering greater trustworthiness and accountability in the deployment of LLMs.
A Probabilistic Hadamard U-Net for MRI Bias Field Correction
Mar 08, 2024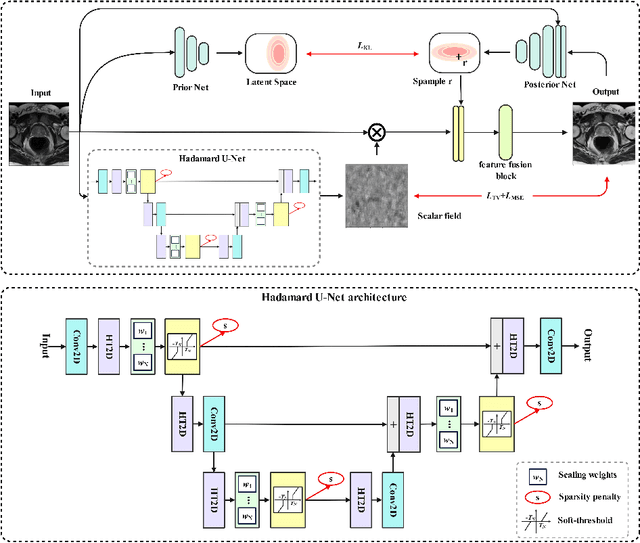
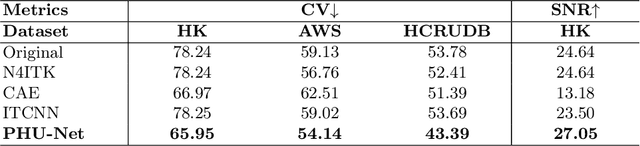
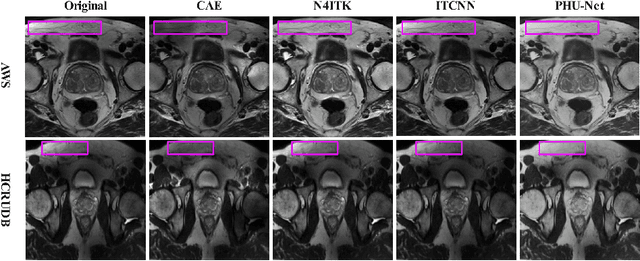
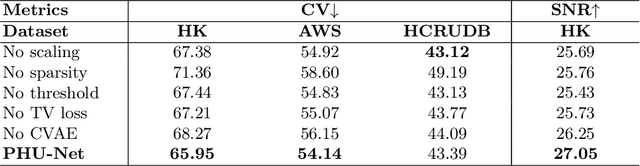
Magnetic field inhomogeneity correction remains a challenging task in MRI analysis. Most established techniques are designed for brain MRI by supposing that image intensities in the identical tissue follow a uniform distribution. Such an assumption cannot be easily applied to other organs, especially those that are small in size and heterogeneous in texture (large variations in intensity), such as the prostate. To address this problem, this paper proposes a probabilistic Hadamard U-Net (PHU-Net) for prostate MRI bias field correction. First, a novel Hadamard U-Net (HU-Net) is introduced to extract the low-frequency scalar field, multiplied by the original input to obtain the prototypical corrected image. HU-Net converts the input image from the time domain into the frequency domain via Hadamard transform. In the frequency domain, high-frequency components are eliminated using the trainable filter (scaling layer), hard-thresholding layer, and sparsity penalty. Next, a conditional variational autoencoder is used to encode possible bias field-corrected variants into a low-dimensional latent space. Random samples drawn from latent space are then incorporated with a prototypical corrected image to generate multiple plausible images. Experimental results demonstrate the effectiveness of PHU-Net in correcting bias-field in prostate MRI with a fast inference speed. It has also been shown that prostate MRI segmentation accuracy improves with the high-quality corrected images from PHU-Net. The code will be available in the final version of this manuscript.
A Survey of Application of Machine Learning in Wireless Indoor Positioning Systems
Mar 07, 2024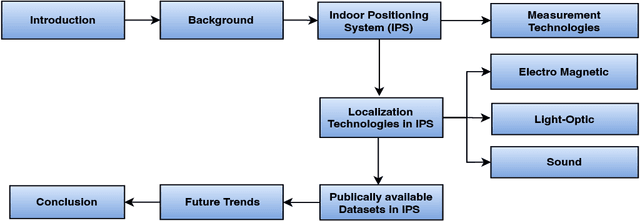
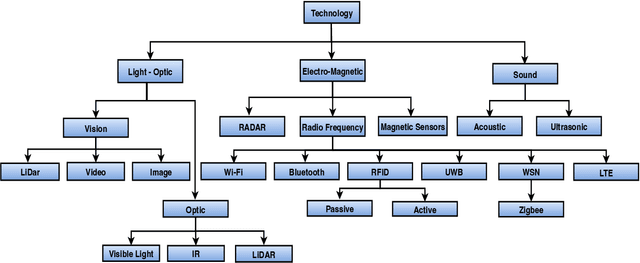
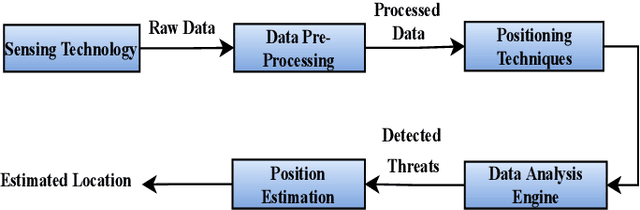
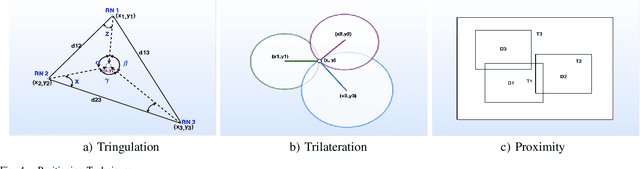
Indoor human positioning has become increasingly important for applications such as health monitoring, breath monitoring, human identification, safety and rescue operations, and security surveillance. However, achieving robust indoor human positioning remains challenging due to various constraints. Numerous attempts have been made in the literature to develop efficient indoor positioning systems (IPSs), with a growing focus on machine learning (ML) based techniques. This paper aims to compare and analyze current ML-based wireless techniques and approaches for indoor positioning, providing a comprehensive review of enabling technologies for human detection, positioning, and activity recognition. The study explores different input measurement data, including RSSI, TDOA, etc., for various IPSs. Key positioning techniques such as RSSI-based fingerprinting, Angle-based, and Time-based approaches are examined in conjunction with various ML methods. The survey compares the positioning accuracy, scalability, and algorithm complexity, with the goal of determining the suitable technology in various services. Finally, the paper compares distinct datasets focused on indoor localization, which have been published using diverse technologies. Overall, the paper presents a comprehensive comparison of existing techniques and localization models.
Evacuation Management Framework towards Smart City-wide Intelligent Emergency Interactive Response System
Mar 07, 2024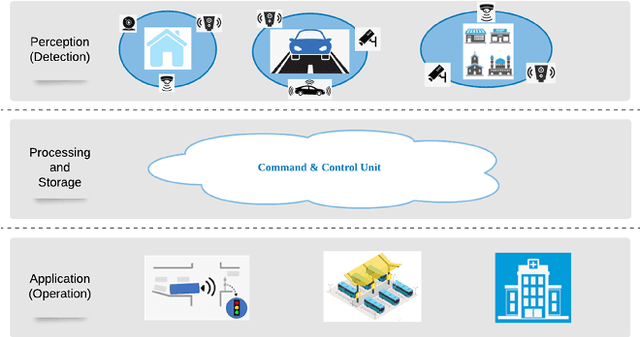
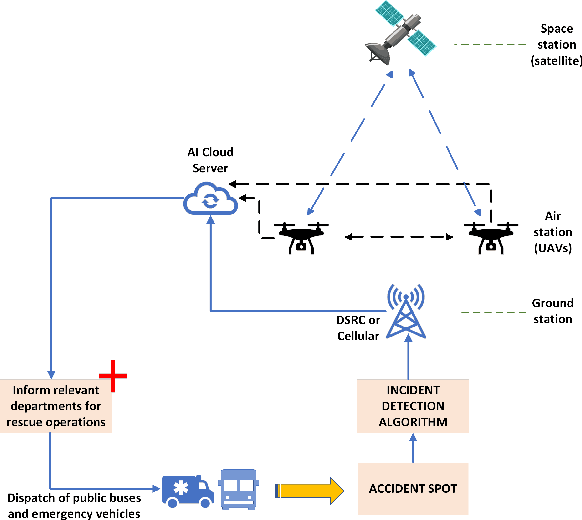
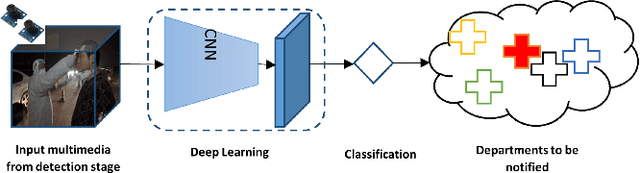
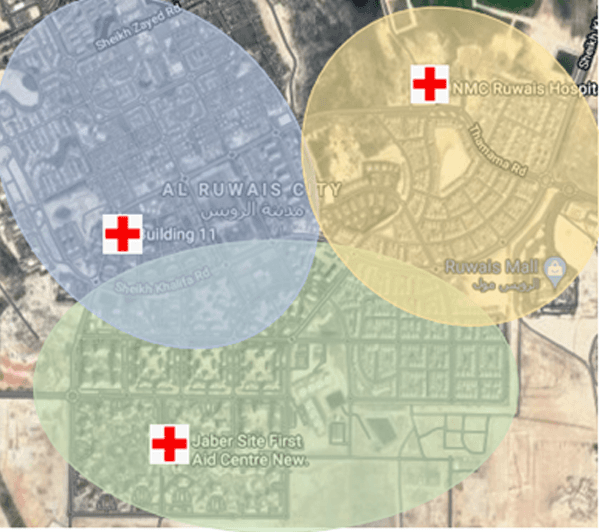
A smart city solution toward future 6G network deployment allows small and medium sized enterprises (SMEs), industry, and government entities to connect with the infrastructures and play a crucial role in enhancing emergency preparedness with advanced sensors. The objective of this work is to propose a set of coordinated technological solutions to transform an existing emergency response system into an intelligent interactive system, thereby improving the public services and the quality of life for residents at home, on road, in hospitals, transport hubs, etc. In this context, we consider a city wide view from three different application scenes that are closely related to peoples daily life, to optimize the actions taken at relevant departments. Therefore, using artificial intelligence (AI) and machine learning (ML) techniques to enable the next generation connected vehicle experiences, we specifically focus on accidents happening in indoor households, urban roads, and at large public facilities. This smart interactive response system will benefit from advanced sensor fusion and AI by formulating a real time dynamic model.
That's My Point: Compact Object-centric LiDAR Pose Estimation for Large-scale Outdoor Localisation
Mar 07, 2024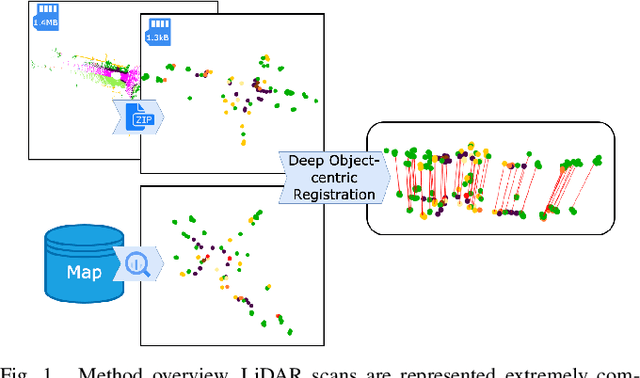
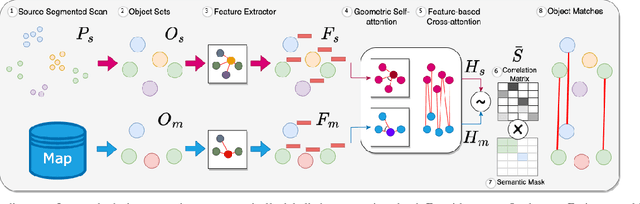
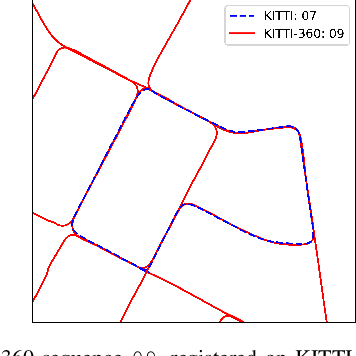
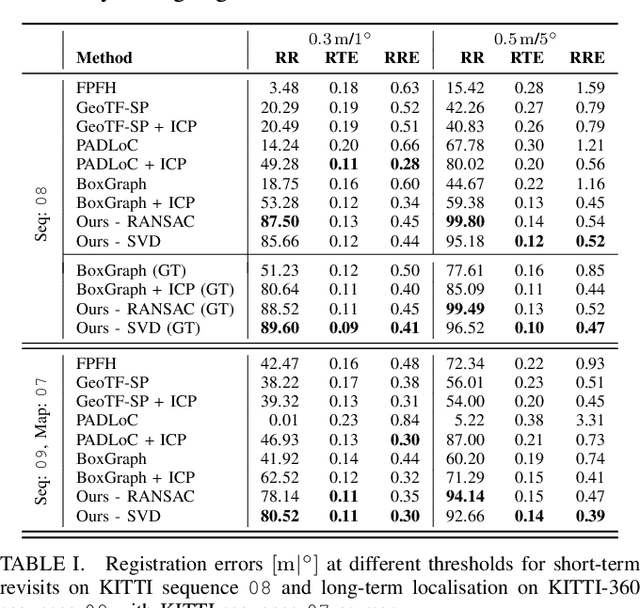
This paper is about 3D pose estimation on LiDAR scans with extremely minimal storage requirements to enable scalable mapping and localisation. We achieve this by clustering all points of segmented scans into semantic objects and representing them only with their respective centroid and semantic class. In this way, each LiDAR scan is reduced to a compact collection of four-number vectors. This abstracts away important structural information from the scenes, which is crucial for traditional registration approaches. To mitigate this, we introduce an object-matching network based on self- and cross-correlation that captures geometric and semantic relationships between entities. The respective matches allow us to recover the relative transformation between scans through weighted Singular Value Decomposition (SVD) and RANdom SAmple Consensus (RANSAC). We demonstrate that such representation is sufficient for metric localisation by registering point clouds taken under different viewpoints on the KITTI dataset, and at different periods of time localising between KITTI and KITTI-360. We achieve accurate metric estimates comparable with state-of-the-art methods with almost half the representation size, specifically 1.33 kB on average.
Machine learning and information theory concepts towards an AI Mathematician
Mar 07, 2024The current state-of-the-art in artificial intelligence is impressive, especially in terms of mastery of language, but not so much in terms of mathematical reasoning. What could be missing? Can we learn something useful about that gap from how the brains of mathematicians go about their craft? This essay builds on the idea that current deep learning mostly succeeds at system 1 abilities -- which correspond to our intuition and habitual behaviors -- but still lacks something important regarding system 2 abilities -- which include reasoning and robust uncertainty estimation. It takes an information-theoretical posture to ask questions about what constitutes an interesting mathematical statement, which could guide future work in crafting an AI mathematician. The focus is not on proving a given theorem but on discovering new and interesting conjectures. The central hypothesis is that a desirable body of theorems better summarizes the set of all provable statements, for example by having a small description length while at the same time being close (in terms of number of derivation steps) to many provable statements.
Electrocardiogram Instruction Tuning for Report Generation
Mar 07, 2024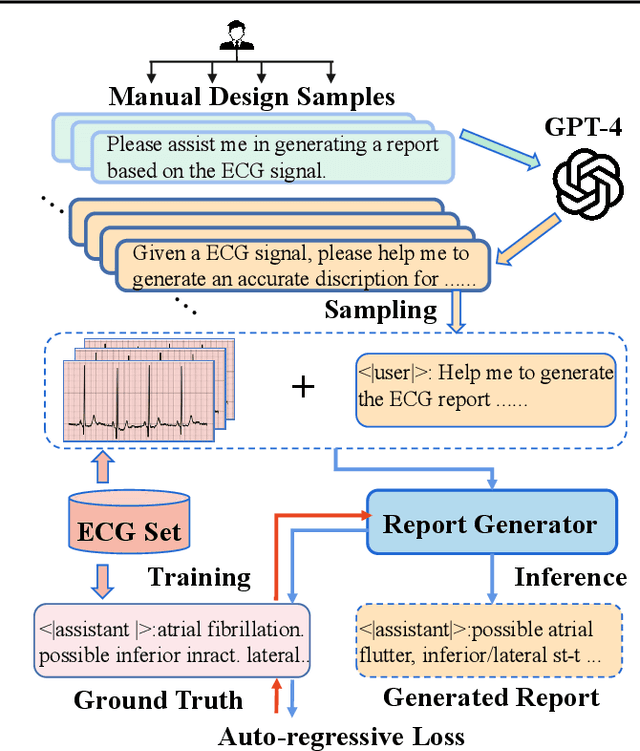
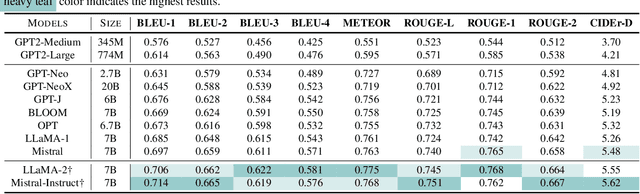
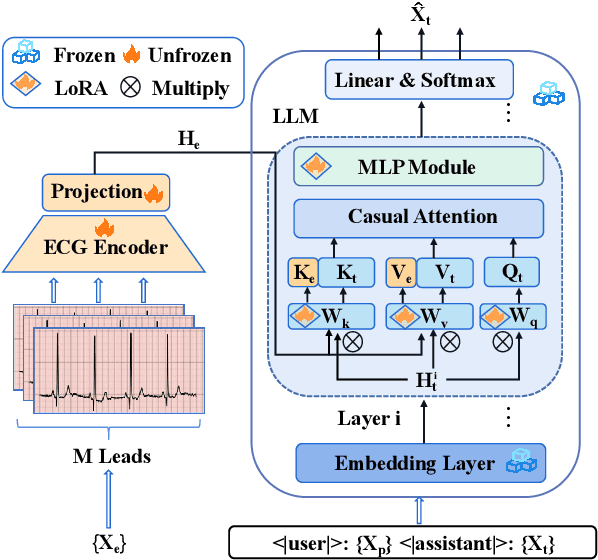

Electrocardiogram (ECG) serves as the primary non-invasive diagnostic tool for cardiac conditions monitoring, are crucial in assisting clinicians. Recent studies have concentrated on classifying cardiac conditions using ECG data but have overlooked ECG report generation, which is not only time-consuming but also requires clinical expertise. To automate ECG report generation and ensure its versatility, we propose the Multimodal ECG Instruction Tuning (MEIT) framework, the \textit{first} attempt to tackle ECG report generation with LLMs and multimodal instructions. To facilitate future research, we establish a benchmark to evaluate MEIT with various LLMs backbones across two large-scale ECG datasets. Our approach uniquely aligns the representations of the ECG signal and the report, and we conduct extensive experiments to benchmark MEIT with nine open source LLMs, using more than 800,000 ECG reports. MEIT's results underscore the superior performance of instruction-tuned LLMs, showcasing their proficiency in quality report generation, zero-shot capabilities, and resilience to signal perturbation. These findings emphasize the efficacy of our MEIT framework and its potential for real-world clinical application.
RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning
Mar 07, 2024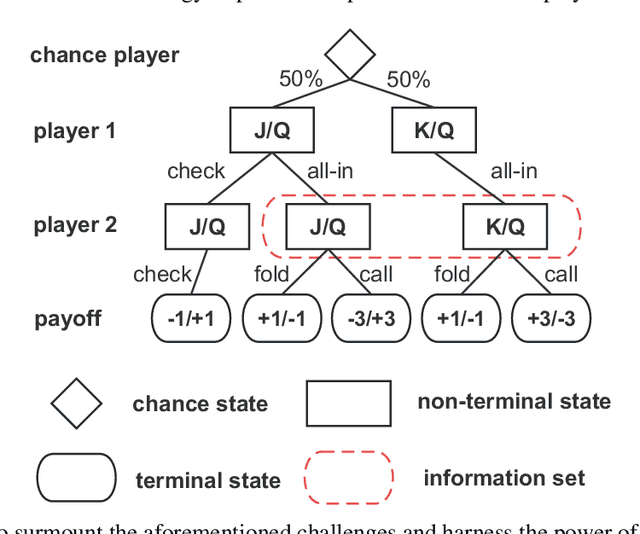
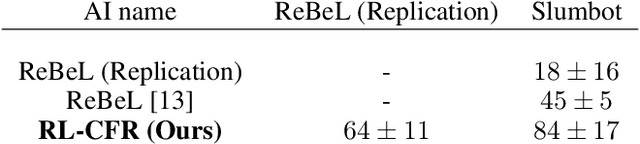
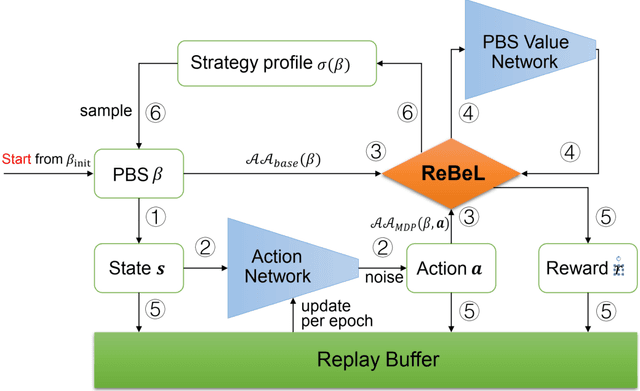
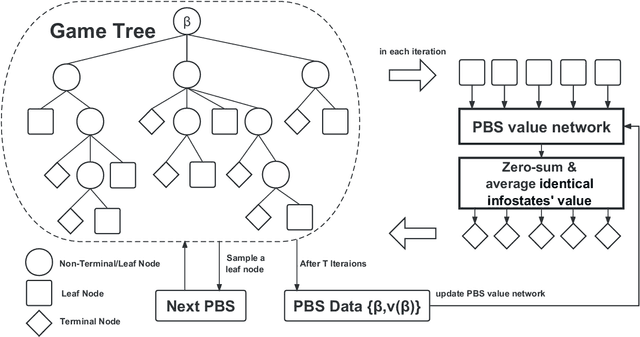
Effective action abstraction is crucial in tackling challenges associated with large action spaces in Imperfect Information Extensive-Form Games (IIEFGs). However, due to the vast state space and computational complexity in IIEFGs, existing methods often rely on fixed abstractions, resulting in sub-optimal performance. In response, we introduce RL-CFR, a novel reinforcement learning (RL) approach for dynamic action abstraction. RL-CFR builds upon our innovative Markov Decision Process (MDP) formulation, with states corresponding to public information and actions represented as feature vectors indicating specific action abstractions. The reward is defined as the expected payoff difference between the selected and default action abstractions. RL-CFR constructs a game tree with RL-guided action abstractions and utilizes counterfactual regret minimization (CFR) for strategy derivation. Impressively, it can be trained from scratch, achieving higher expected payoff without increased CFR solving time. In experiments on Heads-up No-limit Texas Hold'em, RL-CFR outperforms ReBeL's replication and Slumbot, demonstrating significant win-rate margins of $64\pm 11$ and $84\pm 17$ mbb/hand, respectively.