 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time series generation for option pricing on quantum computers using tensor network
Feb 27, 2024
Finance, especially option pricing, is a promising industrial field that might benefit from quantum computing. While quantum algorithms for option pricing have been proposed, it is desired to devise more efficient implementations of costly operations in the algorithms, one of which is preparing a quantum state that encodes a probability distribution of the underlying asset price. In particular, in pricing a path-dependent option, we need to generate a state encoding a joint distribution of the underlying asset price at multiple time points, which is more demanding. To address these issues, we propose a novel approach using Matrix Product State (MPS) as a generative model for time series generation. To validate our approach, taking the Heston model as a target, we conduct numerical experiments to generate time series in the model. Our findings demonstrate the capability of the MPS model to generate paths in the Heston model, highlighting its potential for path-dependent option pricing on quantum computers.
Cafe-Mpc: A Cascaded-Fidelity Model Predictive Control Framework with Tuning-Free Whole-Body Control
Mar 14, 2024

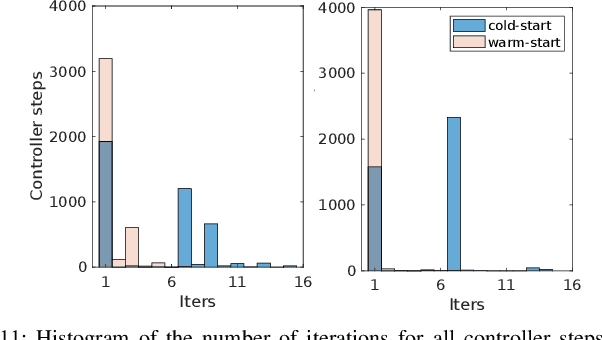
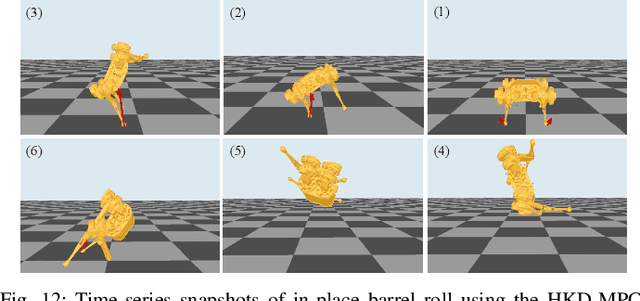
This work introduces an optimization-based locomotion control framework for on-the-fly synthesis of complex dynamic maneuvers. At the core of the proposed framework is a cascaded-fidelity model predictive controller (Cafe-Mpc). Cafe-Mpc strategically relaxes the planning problem along the prediction horizon (i.e., with descending model fidelity, increasingly coarse time steps, and relaxed constraints) for computational and performance gains. This problem is numerically solved with an efficient customized multiple-shooting iLQR (MS-iLQR) solver that is tailored for hybrid systems. The action-value function from Cafe-Mpc is then used as the basis for a new value-function-based whole-body control (VWBC) technique that avoids additional tuning for the WBC. In this respect, the proposed framework unifies whole-body MPC and more conventional whole-body quadratic programming (QP), which have been treated as separate components in previous works. We study the effects of the cascaded relaxations in Cafe-Mpc on the tracking performance and required computation time. We also show that the Cafe-Mpc, if configured appropriately, advances the performance of whole-body MPC without necessarily increasing computational cost. Further, we show the superior performance of the proposed VWBC over the Riccati feedback controller in terms of constraint handling. The proposed framework enables accomplishing for the first time gymnastic-style running barrel rolls on the MIT Mini Cheetah. Video: https://youtu.be/YiNqrgj9mb8.
ContiFormer: Continuous-Time Transformer for Irregular Time Series Modeling
Feb 16, 2024Modeling continuous-time dynamics on irregular time series is critical to account for data evolution and correlations that occur continuously. Traditional methods including recurrent neural networks or Transformer models leverage inductive bias via powerful neural architectures to capture complex patterns. However, due to their discrete characteristic, they have limitations in generalizing to continuous-time data paradigms. Though neural ordinary differential equations (Neural ODEs) and their variants have shown promising results in dealing with irregular time series, they often fail to capture the intricate correlations within these sequences. It is challenging yet demanding to concurrently model the relationship between input data points and capture the dynamic changes of the continuous-time system. To tackle this problem, we propose ContiFormer that extends the relation modeling of vanilla Transformer to the continuous-time domain, which explicitly incorporates the modeling abilities of continuous dynamics of Neural ODEs with the attention mechanism of Transformers. We mathematically characterize the expressive power of ContiFormer and illustrate that, by curated designs of function hypothesis, many Transformer variants specialized in irregular time series modeling can be covered as a special case of ContiFormer. A wide range of experiments on both synthetic and real-world datasets have illustrated the superior modeling capacities and prediction performance of ContiFormer on irregular time series data. The project link is https://seqml.github.io/contiformer/.
QEAN: Quaternion-Enhanced Attention Network for Visual Dance Generation
Mar 18, 2024The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024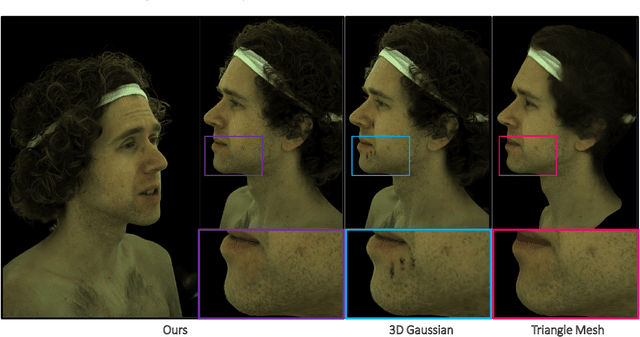
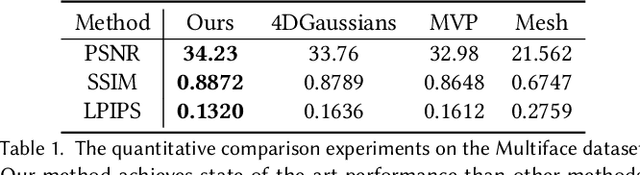


This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
Deep learning automates Cobb angle measurement compared with multi-expert observers
Mar 18, 2024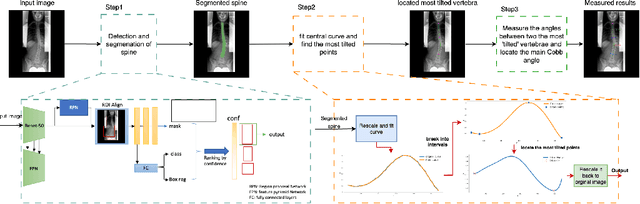
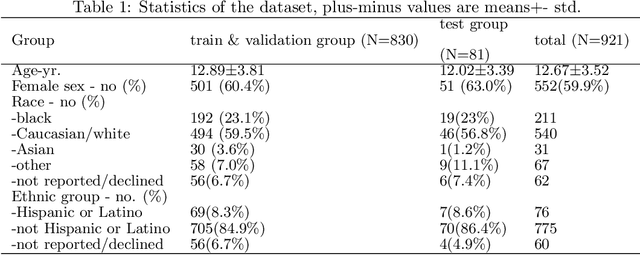
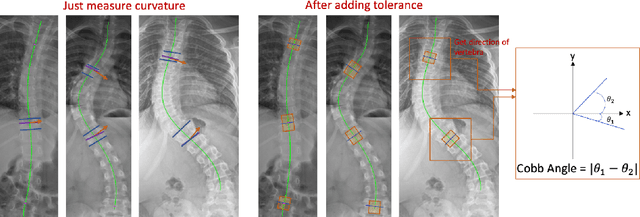

Scoliosis, a prevalent condition characterized by abnormal spinal curvature leading to deformity, requires precise assessment methods for effective diagnosis and management. The Cobb angle is a widely used scoliosis quantification method that measures the degree of curvature between the tilted vertebrae. Yet, manual measuring of Cobb angles is time-consuming and labor-intensive, fraught with significant interobserver and intraobserver variability. To address these challenges and the lack of interpretability found in certain existing automated methods, we have created fully automated software that not only precisely measures the Cobb angle but also provides clear visualizations of these measurements. This software integrates deep neural network-based spine region detection and segmentation, spine centerline identification, pinpointing the most significantly tilted vertebrae, and direct visualization of Cobb angles on the original images. Upon comparison with the assessments of 7 expert readers, our algorithm exhibited a mean deviation in Cobb angle measurements of 4.17 degrees, notably surpassing the manual approach's average intra-reader discrepancy of 5.16 degrees. The algorithm also achieved intra-class correlation coefficients (ICC) exceeding 0.96 and Pearson correlation coefficients above 0.944, reflecting robust agreement with expert assessments and superior measurement reliability. Through the comprehensive reader study and statistical analysis, we believe this algorithm not only ensures a higher consensus with expert readers but also enhances interpretability and reproducibility during assessments. It holds significant promise for clinical application, potentially aiding physicians in more accurate scoliosis assessment and diagnosis, thereby improving patient care.
A Wideband Distributed Massive MIMO Channel Sounder for Communication and Sensing
Mar 18, 2024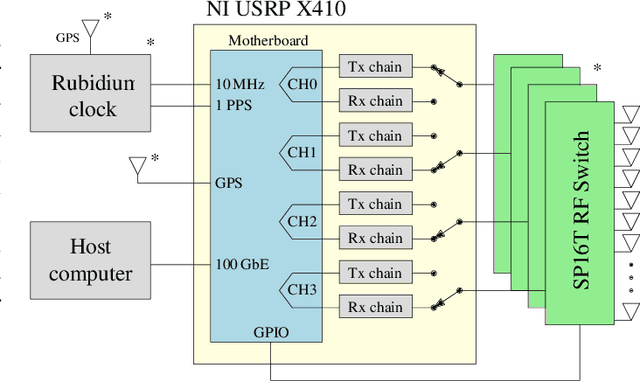
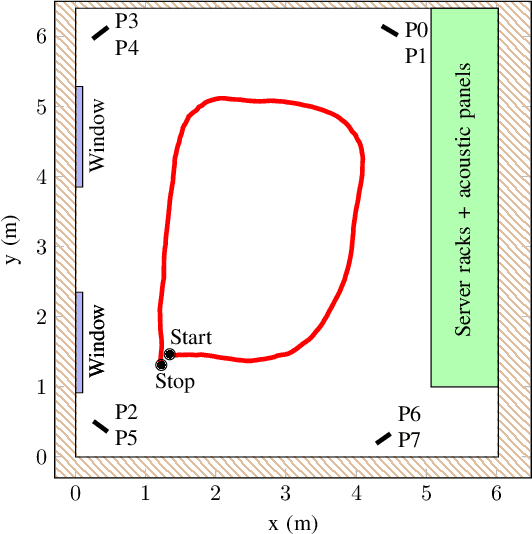
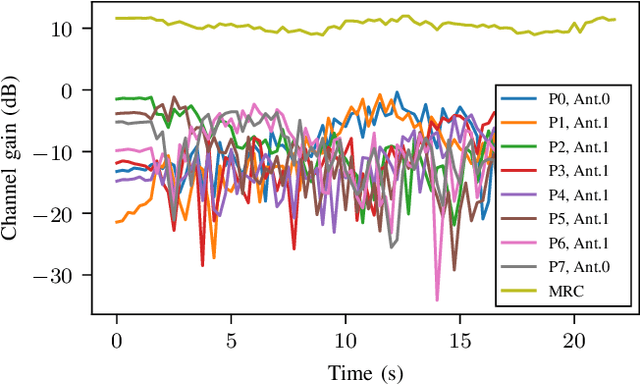
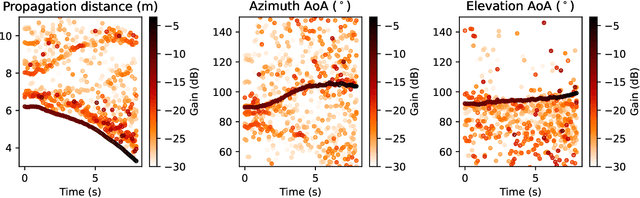
Channel sounding is a vital step in understanding wireless channels for the design and deployment of wireless communication systems. In this paper, we present the design and implementation of a coherent distributed massive MIMO channel sounder operating at 5-6 GHz with a bandwidth of 400 MHz based on the NI USRP X410. Through the integration of transceiver chains and RF switches, the design facilitates the use of a larger number of antennas without significant compromise in dynamic capability. Our current implementation is capable of measuring thousands of antenna combinations within tens of milliseconds. Every radio frequency switch is seamlessly integrated with a 16-element antenna array, making the antennas more practical to be transported and flexibly distributed. In addition, the channel sounder features real-time processing to reduce the data stream to the host computer and increase the signal-to-noise ratio. The design and implementation are verified through two measurements in an indoor laboratory environment. The first measurement entails a single-antenna robot as transmitter and 128 distributed receiving antennas. The second measurement demonstrates a passive sensing scenario with a walking person. We evaluate the results of both measurements using the super-resolution algorithm SAGE. The results demonstrate the great potential of the presented sounding system for providing high-quality radio channel measurements, contributing to high-resolution channel estimation, characterization, and active and passive sensing in realistic and dynamic scenarios.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 18, 2024![Figure 1 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure3-1.png&w=640&q=75)
Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
Prioritized Semantic Learning for Zero-shot Instance Navigation
Mar 18, 2024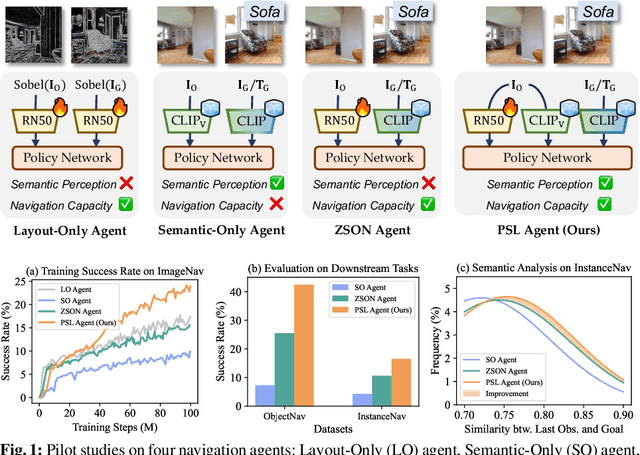
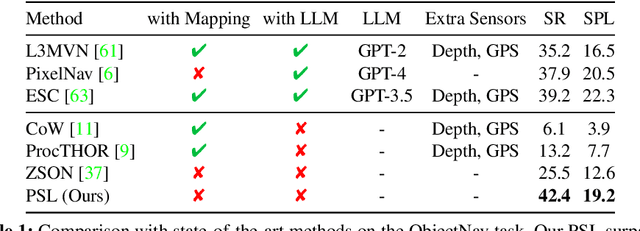
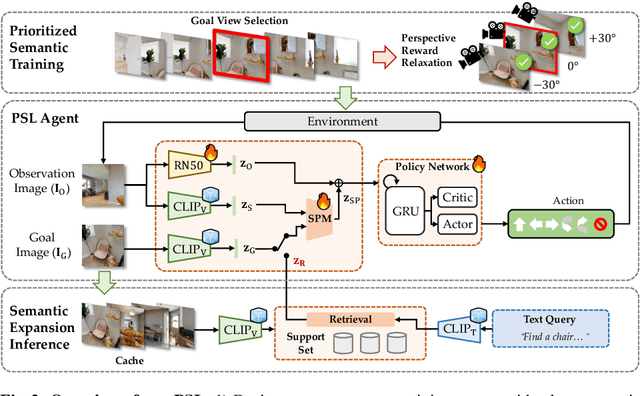

We study zero-shot instance navigation, in which the agent navigates to a specific object without using object annotations for training. Previous object navigation approaches apply the image-goal navigation (ImageNav) task (go to the location of an image) for pretraining, and transfer the agent to achieve object goals using a vision-language model. However, these approaches lead to issues of semantic neglect, where the model fails to learn meaningful semantic alignments. In this paper, we propose a Prioritized Semantic Learning (PSL) method to improve the semantic understanding ability of navigation agents. Specifically, a semantic-enhanced PSL agent is proposed and a prioritized semantic training strategy is introduced to select goal images that exhibit clear semantic supervision and relax the reward function from strict exact view matching. At inference time, a semantic expansion inference scheme is designed to preserve the same granularity level of the goal-semantic as training. Furthermore, for the popular HM3D environment, we present an Instance Navigation (InstanceNav) task that requires going to a specific object instance with detailed descriptions, as opposed to the Object Navigation (ObjectNav) task where the goal is defined merely by the object category. Our PSL agent outperforms the previous state-of-the-art by 66% on zero-shot ObjectNav in terms of success rate and is also superior on the new InstanceNav task. Code will be released at https://anonymous.4open. science/r/PSL/.
InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting
Mar 05, 2024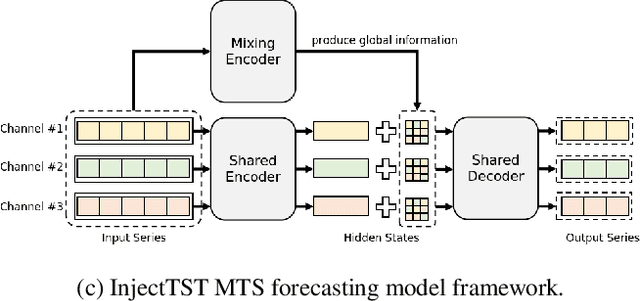
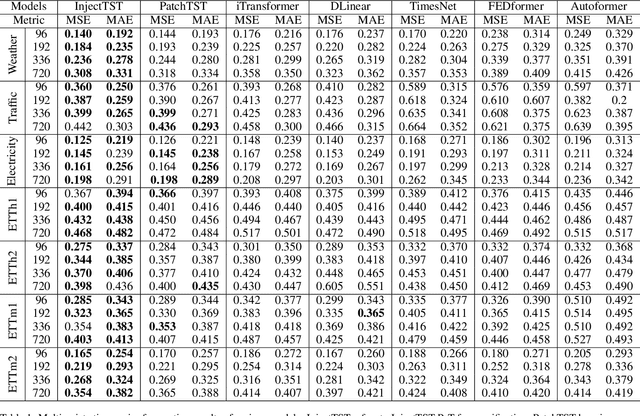
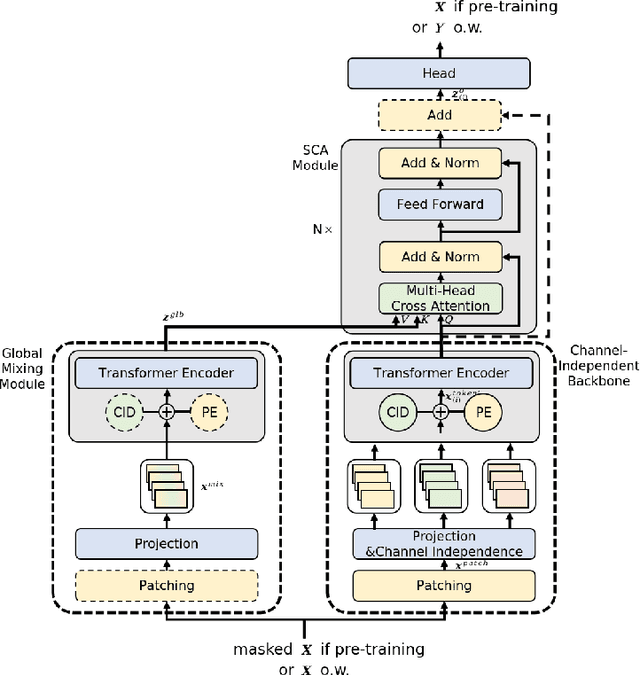
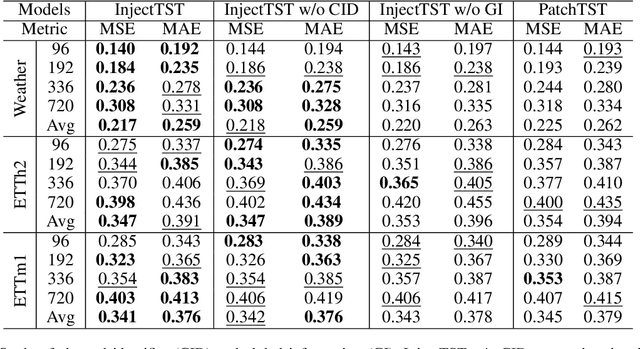
Transformer has become one of the most popular architectures for multivariate time series (MTS) forecasting. Recent Transformer-based MTS models generally prefer channel-independent structures with the observation that channel independence can alleviate noise and distribution drift issues, leading to more robustness. Nevertheless, it is essential to note that channel dependency remains an inherent characteristic of MTS, carrying valuable information. Designing a model that incorporates merits of both channel-independent and channel-mixing structures is a key to further improvement of MTS forecasting, which poses a challenging conundrum. To address the problem, an injection method for global information into channel-independent Transformer, InjectTST, is proposed in this paper. Instead of designing a channel-mixing model directly, we retain the channel-independent backbone and gradually inject global information into individual channels in a selective way. A channel identifier, a global mixing module and a self-contextual attention module are devised in InjectTST. The channel identifier can help Transformer distinguish channels for better representation. The global mixing module produces cross-channel global information. Through the self-contextual attention module, the independent channels can selectively concentrate on useful global information without robustness degradation, and channel mixing is achieved implicitly. Experiments indicate that InjectTST can achieve stable improvement compared with state-of-the-art models.