 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURDF+: An Enhanced URDF for Robots with Kinematic Loops
Nov 29, 2024



Designs incorporating kinematic loops are becoming increasingly prevalent in the robotics community. Despite the existence of dynamics algorithms to deal with the effects of such loops, many modern simulators rely on dynamics libraries that require robots to be represented as kinematic trees. This requirement is reflected in the de facto standard format for describing robots, the Universal Robot Description Format (URDF), which does not support kinematic loops resulting in closed chains. This paper introduces an enhanced URDF, termed URDF+, which addresses this key shortcoming of URDF while retaining the intuitive design philosophy and low barrier to entry that the robotics community values. The URDF+ keeps the elements used by URDF to describe open chains and incorporates new elements to encode loop joints. We also offer an accompanying parser that processes the system models coming from URDF+ so that they can be used with recursive rigid-body dynamics algorithms for closed-chain systems that group bodies into local, decoupled loops. This parsing process is fully automated, ensuring optimal grouping of constrained bodies without requiring manual specification from the user. We aim to advance the robotics community towards this elegant solution by developing efficient and easy-to-use software tools.
Cafe-Mpc: A Cascaded-Fidelity Model Predictive Control Framework with Tuning-Free Whole-Body Control
Mar 14, 2024



This work introduces an optimization-based locomotion control framework for on-the-fly synthesis of complex dynamic maneuvers. At the core of the proposed framework is a cascaded-fidelity model predictive controller (Cafe-Mpc). Cafe-Mpc strategically relaxes the planning problem along the prediction horizon (i.e., with descending model fidelity, increasingly coarse time steps, and relaxed constraints) for computational and performance gains. This problem is numerically solved with an efficient customized multiple-shooting iLQR (MS-iLQR) solver that is tailored for hybrid systems. The action-value function from Cafe-Mpc is then used as the basis for a new value-function-based whole-body control (VWBC) technique that avoids additional tuning for the WBC. In this respect, the proposed framework unifies whole-body MPC and more conventional whole-body quadratic programming (QP), which have been treated as separate components in previous works. We study the effects of the cascaded relaxations in Cafe-Mpc on the tracking performance and required computation time. We also show that the Cafe-Mpc, if configured appropriately, advances the performance of whole-body MPC without necessarily increasing computational cost. Further, we show the superior performance of the proposed VWBC over the Riccati feedback controller in terms of constraint handling. The proposed framework enables accomplishing for the first time gymnastic-style running barrel rolls on the MIT Mini Cheetah. Video: https://youtu.be/YiNqrgj9mb8.
Recursive Rigid-Body Dynamics Algorithms for Systems with Kinematic Loops
Nov 22, 2023



We propose a novel approach for generalizing the following rigid-body dynamics algorithms: Recursive Newton-Euler Algorithm, Articulated-Body Algorithm, and Extended-Force-Propagator Algorithm. The classic versions of these recursive algorithms require systems to have an open chain structure. Dealing with closed-chains has, conventionally, required different algorithms. In this paper, we demonstrate that the classic recursive algorithms can be modified to work for closed-chain mechanisms. The critical insight of our generalized algorithms is the clustering of bodies involved in local loop constraints. Clustering bodies enables loop constraints to be resolved locally, i.e., only when that group of bodies is encountered during a forward or backward pass. This local treatment avoids the need for large-scale matrix factorization. We provide self-contained derivations of the algorithms using familiar, physically meaningful concepts. Overall, our approach provides a foundation for simulating robotic systems with traditionally difficult-to-simulate designs, such as geared motors, differential drives, and four-bar mechanisms. The performance of our library of algorithms is validated numerically in C++ on various modern legged robots: the MIT Mini Cheetah, the MIT Humanoid, the UIUC Tello Humanoid, and a modified version of the JVRC-1 Humanoid. Our algorithms are shown to outperform state-of-the-art algorithms for computing constrained rigid-body dynamics.
A Unified Perspective on Multiple Shooting In Differential Dynamic Programming
Sep 28, 2023



Differential Dynamic Programming (DDP) is an efficient computational tool for solving nonlinear optimal control problems. It was originally designed as a single shooting method and thus is sensitive to the initial guess supplied. This work considers the extension of DDP to multiple shooting (MS), improving its robustness to initial guesses. A novel derivation is proposed that accounts for the defect between shooting segments during the DDP backward pass, while still maintaining quadratic convergence locally. The derivation enables unifying multiple previous MS algorithms, and opens the door to many smaller algorithmic improvements. A penalty method is introduced to strategically control the step size, further improving the convergence performance. An adaptive merit function and a more reliable acceptance condition are employed for globalization. The effects of these improvements are benchmarked for trajectory optimization with a quadrotor, an acrobot, and a manipulator. MS-DDP is also demonstrated for use in Model Predictive Control (MPC) for dynamic jumping with a quadruped robot, showing its benefits over a single shooting approach.
Hybrid Volitional Control of a Robotic Transtibial Prosthesis using a Phase Variable Impedance Controller
Sep 27, 2023For robotic transtibial prosthesis control, the global kinematics of the tibia can be used to monitor the progression of the gait cycle and command smooth and continuous actuation. In this work, these global tibia kinematics are used to define a phase variable impedance controller (PVIC), which is then implemented as the nonvolitional base controller within a hybrid volitional control framework (PVI-HVC). The gait progression estimation and biomechanic performance of one able-bodied individual walking on a robotic ankle prosthesis via a bypass adapter are compared for three control schemes: a passive benchmark controller, PVIC, and PVI-HVC. The different actuation of each controller had a direct effect on the global tibia kinematics, but the average deviation between the estimated and ground truth gait percentage were 1.6%, 1.8%, and 2.1%, respectively, for each controller. Both PVIC and PVI-HVC produced good agreement with able-bodied kinematic and kinetic references. As designed, PVI-HVC results were similar to those of PVIC when the user used low volitional intent, but yielded higher peak plantarflexion, peak torque, and peak power when the user commanded high volitional input in late stance. This additional torque and power also allowed the user to volitionally and continuously achieve activities beyond level walking, such as ascending ramps, avoiding obstacles, standing on tip-toes, and tapping the foot. In this way, PVI-HVC offers the kinetic and kinematic performance of the PVIC during level ground walking, along with the freedom to volitionally pursue alternative activities.
Multi-Shooting Differential Dynamic Programming for Hybrid Systems using Analytical Derivatives
Jul 24, 2023



Differential Dynamic Programming (DDP) is a popular technique used to generate motion for dynamic-legged robots in the recent past. However, in most cases, only the first-order partial derivatives of the underlying dynamics are used, resulting in the iLQR approach. Neglecting the second-order terms often slows down the convergence rate compared to full DDP. Multi-Shooting is another popular technique to improve robustness, especially if the dynamics are highly non-linear. In this work, we consider Multi-Shooting DDP for trajectory optimization of a bounding gait for a simplified quadruped model. As the main contribution, we develop Second-Order analytical partial derivatives of the rigid-body contact dynamics, extending our previous results for fixed/floating base models with multi-DoF joints. Finally, we show the benefits of a novel Quasi-Newton method for approximating second-order derivatives of the dynamics, leading to order-of-magnitude speedups in the convergence compared to the full DDP method.
On Second-Order Derivatives of Rigid-Body Dynamics: Theory & Implementation
Feb 12, 2023Model-based control for robots has increasingly been dependent on optimization-based methods like Differential Dynamic Programming and iterative LQR (iLQR). These methods can form the basis of Model-Predictive Control (MPC), which is commonly used for controlling legged robots. Computing the partial derivatives of the dynamics is often the most expensive part of these algorithms, regardless of whether analytical methods, Finite Difference, Automatic Differentiation (AD), or Chain-Rule accumulation is used. Since the second-order derivatives of dynamics result in tensor computations, they are often ignored, leading to the use of iLQR, instead of the full second-order DDP method. In this paper, we present analytical methods to compute the second-order derivatives of inverse and forward dynamics for open-chain rigid-body systems with multi-DoF joints and fixed/floating bases. An extensive comparison of accuracy and run-time performance with AD and other methods is provided, including the consideration of code-generation techniques in C/C++ to speed up the computations. For the 36 DoF ATLAS humanoid, the second-order Inverse, and the Forward dynamics derivatives take approx 200 mu s, and approx 2.1 ms respectively, resulting in a 3x speedup over the AD approach.
Optimization-Based Control for Dynamic Legged Robots
Nov 21, 2022



In a world designed for legs, quadrupeds, bipeds, and humanoids have the opportunity to impact emerging robotics applications from logistics, to agriculture, to home assistance. The goal of this survey is to cover the recent progress toward these applications that has been driven by model-based optimization for the real-time generation and control of movement. The majority of the research community has converged on the idea of generating locomotion control laws by solving an optimal control problem (OCP) in either a model-based or data-driven manner. However, solving the most general of these problems online remains intractable due to complexities from intermittent unidirectional contacts with the environment, and from the many degrees of freedom of legged robots. This survey covers methods that have been pursued to make these OCPs computationally tractable, with specific focus on how environmental contacts are treated, how the model can be simplified, and how these choices affect the numerical solution methods employed. The survey focuses on model-based optimization, covering its recent use in a stand alone fashion, and suggesting avenues for combination with learning-based formulations to further accelerate progress in this growing field.
CACTO: Continuous Actor-Critic with Trajectory Optimization -- Towards global optimality
Nov 12, 2022



This paper presents a novel algorithm for the continuous control of dynamical systems that combines Trajectory Optimization (TO) and Reinforcement Learning (RL) in a single framework. The motivations behind this algorithm are the two main limitations of TO and RL when applied to continuous nonlinear systems to minimize a non-convex cost function. Specifically, TO can get stuck in poor local minima when the search is not initialized close to a ``good'' minimum. On the other hand, when dealing with continuous state and control spaces, the RL training process may be excessively long and strongly dependent on the exploration strategy. Thus, our algorithm learns a ``good'' control policy via TO-guided RL policy search that, when used as initial guess provider for TO, makes the trajectory optimization process less prone to converge to poor local optima. Our method is validated on several reaching problems featuring non-convex obstacle avoidance with different dynamical systems, including a car model with 6d state, and a 3-joint planar manipulator. Our results show the great capabilities of CACTO in escaping local minima, while being more computationally efficient than the DDPG RL algorithm.
Versatile Real-Time Motion Synthesis via Kino-Dynamic MPC with Hybrid-Systems DDP
Sep 28, 2022
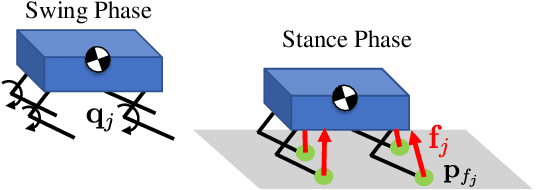
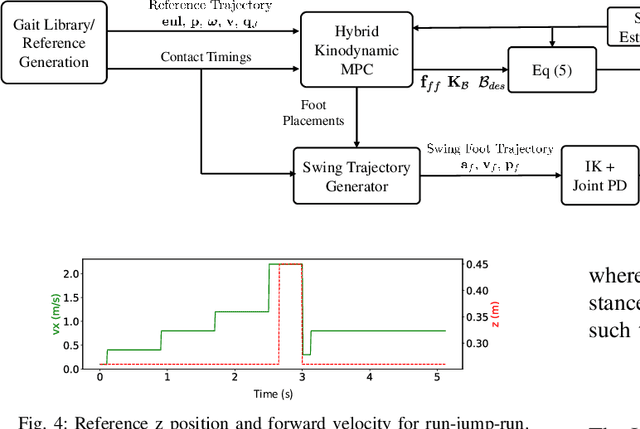
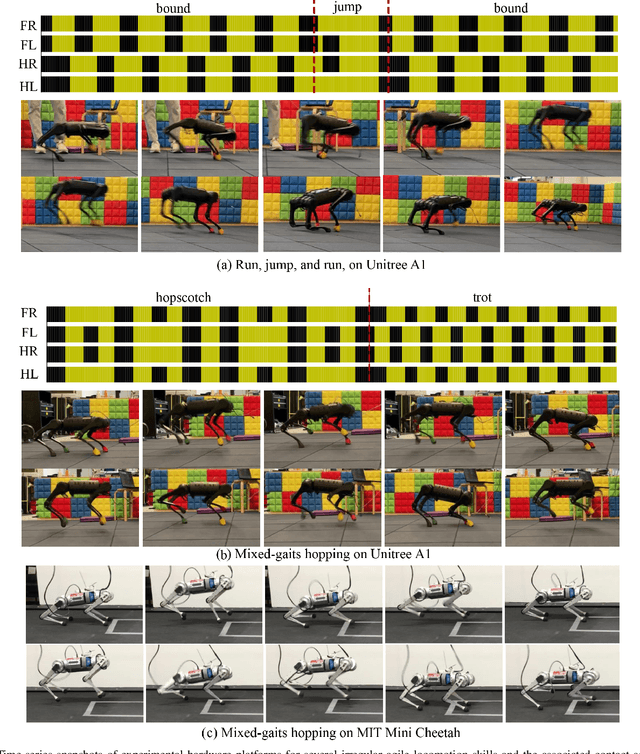
Specialized motions such as jumping are often achieved on quadruped robots by solving a trajectory optimization problem once and executing the trajectory using a tracking controller. This approach is in parallel with Model Predictive Control (MPC) strategies that commonly control regular gaits via online re-planning. In this work, we present a nonlinear MPC (NMPC) technique that unlocks on-the-fly re-planning of specialized motion skills and regular locomotion within a unified framework. The NMPC reasons about a hybrid kinodynamic model, and is solved using a variant of a constrained Differential Dynamic Programming (DDP) solver. The proposed NMPC enables the robot to perform a variety of agile skills like jumping, bounding, and trotting, and the rapid transition between these skills. We evaluated the proposed algorithm with three challenging motion sequences that combine multiple agile skills, on two quadruped platforms, Unitree A1, and MIT Mini Cheetah, showing its effectiveness and generality.