 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discovering Communication Pattern Shifts in Large-Scale Networks using Encoder Embedding and Vertex Dynamics
May 03, 2023
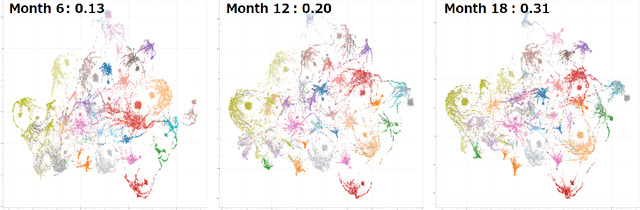
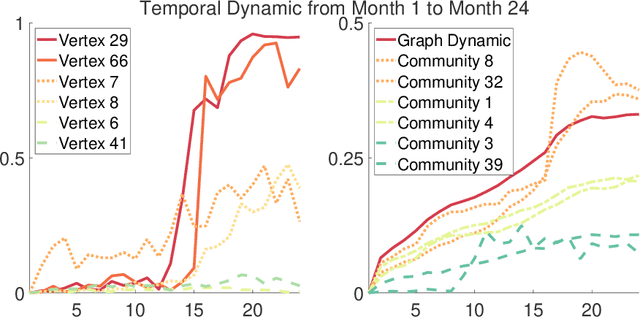
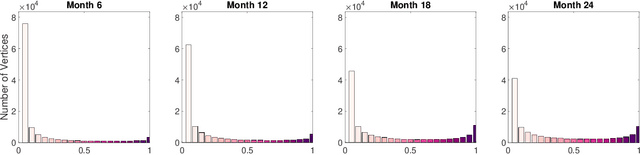
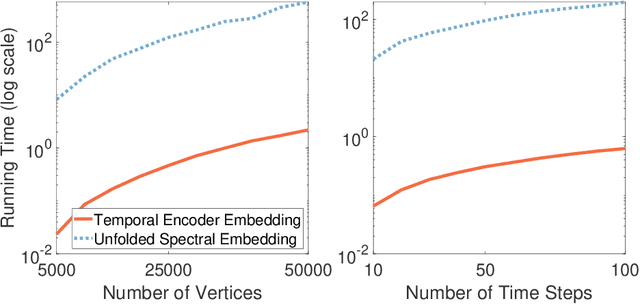
The analysis of large-scale time-series network data, such as social media and email communications, remains a significant challenge for graph analysis methodology. In particular, the scalability of graph analysis is a critical issue hindering further progress in large-scale downstream inference. In this paper, we introduce a novel approach called "temporal encoder embedding" that can efficiently embed large amounts of graph data with linear complexity. We apply this method to an anonymized time-series communication network from a large organization spanning 2019-2020, consisting of over 100 thousand vertices and 80 million edges. Our method embeds the data within 10 seconds on a standard computer and enables the detection of communication pattern shifts for individual vertices, vertex communities, and the overall graph structure. Through supporting theory and synthesis studies, we demonstrate the theoretical soundness of our approach under random graph models and its numerical effectiveness through simulation studies.
An End-to-end Pipeline for 3D Slide-wise Multi-stain Renal Pathology Registration
May 19, 2023Tissue examination and quantification in a 3D context on serial section whole slide images (WSIs) were laborintensive and time-consuming tasks. Our previous study proposed a novel registration-based method (Map3D) to automatically align WSIs to the same physical space, reducing the human efforts of screening serial sections from WSIs. However, the registration performance of our Map3D method was only evaluated on single-stain WSIs with large-scale kidney tissue samples. In this paper, we provide a Docker for an end-to-end 3D slide-wise registration pipeline on needle biopsy serial sections in a multi-stain paradigm. The contribution of this study is three-fold: (1) We release a containerized Docker for an end-to-end multi-stain WSI registration. (2) We prove that the Map3D pipeline is capable of sectional registration from multi-stain WSI. (3) We verify that the Map3D pipeline can also be applied to needle biopsy tissue samples. The source code and the Docker have been made publicly available at https://github.com/hrlblab/Map3D.
* 6 pages, 4 figures
S$^3$HQA: A Three-Stage Approach for Multi-hop Text-Table Hybrid Question Answering
May 19, 2023
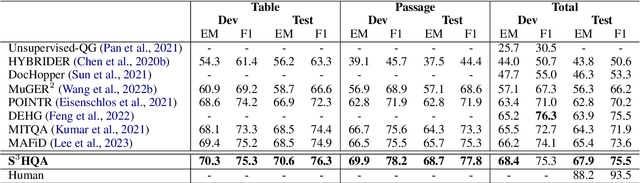
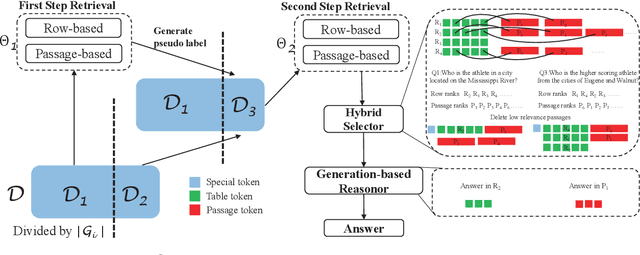
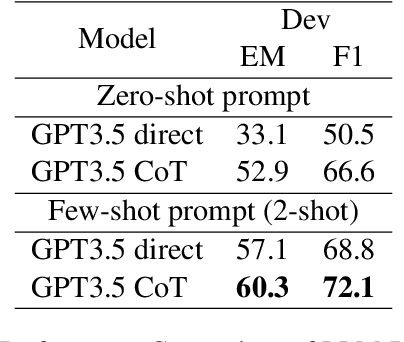
Answering multi-hop questions over hybrid factual knowledge from the given text and table (TextTableQA) is a challenging task. Existing models mainly adopt a retriever-reader framework, which have several deficiencies, such as noisy labeling in training retriever, insufficient utilization of heterogeneous information over text and table, and deficient ability for different reasoning operations. In this paper, we propose a three-stage TextTableQA framework S3HQA, which comprises of retriever, selector, and reasoner. We use a retriever with refinement training to solve the noisy labeling problem. Then, a hybrid selector considers the linked relationships between heterogeneous data to select the most relevant factual knowledge. For the final stage, instead of adapting a reading comprehension module like in previous methods, we employ a generation-based reasoner to obtain answers. This includes two approaches: a row-wise generator and an LLM prompting generator~(first time used in this task). The experimental results demonstrate that our method achieves competitive results in the few-shot setting. When trained on the full dataset, our approach outperforms all baseline methods, ranking first on the HybridQA leaderboard.
Complexity of Neural Network Training and ETR: Extensions with Effectively Continuous Functions
May 19, 2023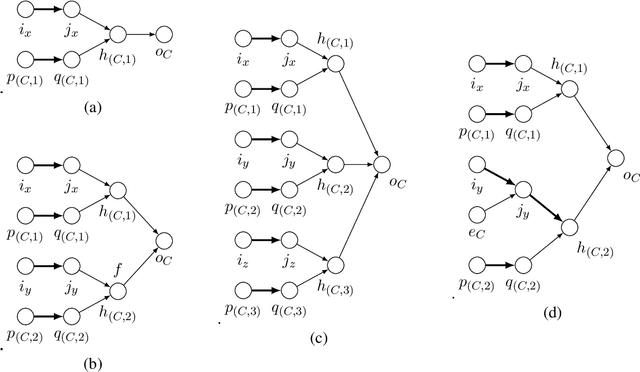
We study the complexity of the problem of training neural networks defined via various activation functions. The training problem is known to be existsR-complete with respect to linear activation functions and the ReLU activation function. We consider the complexity of the problem with respect to the sigmoid activation function and other effectively continuous functions. We show that these training problems are polynomial-time many-one bireducible to the existential theory of the reals extended with the corresponding activation functions. In particular, we establish that the sigmoid activation function leads to the existential theory of the reals with the exponential function. It is thus open, and equivalent with the decidability of the existential theory of the reals with the exponential function, whether training neural networks using the sigmoid activation function is algorithmically solvable. In contrast, we obtain that the training problem is undecidable if sinusoidal activation functions are considered. Finally, we obtain general upper bounds for the complexity of the training problem in the form of low levels of the arithmetical hierarchy.
Graphologue: Exploring Large Language Model Responses with Interactive Diagrams
May 19, 2023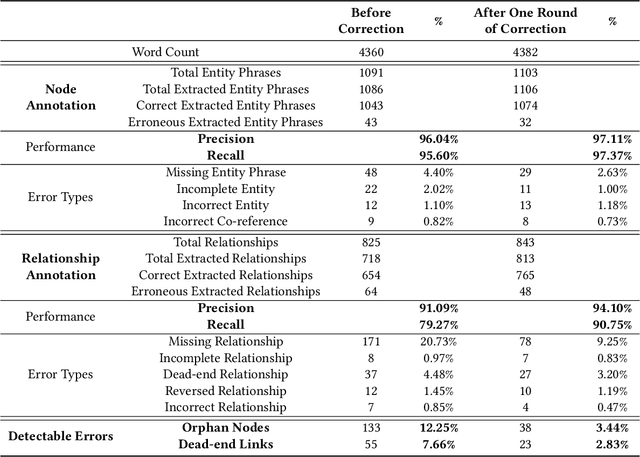
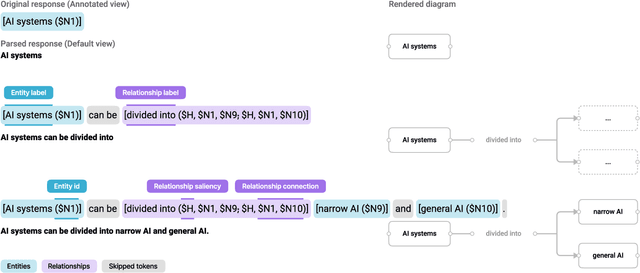
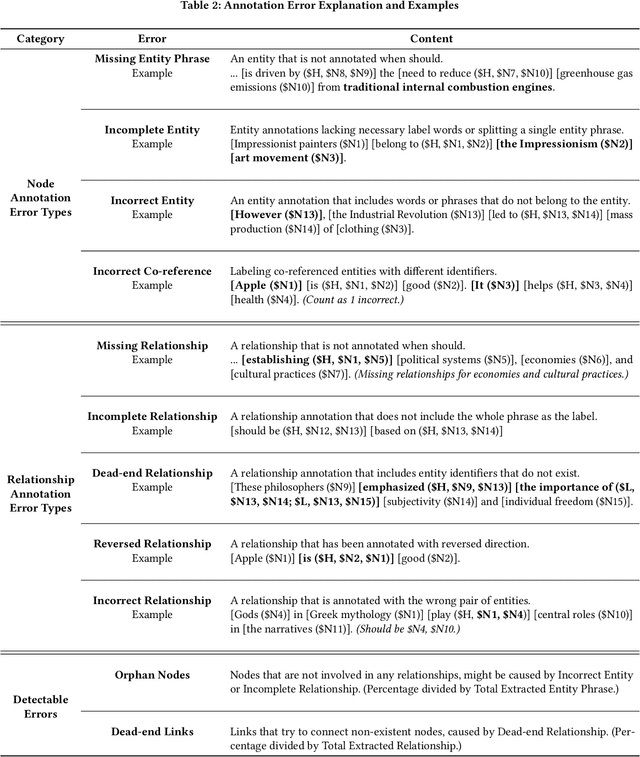
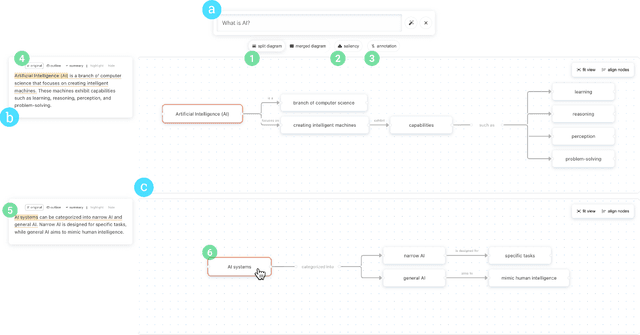
Large language models (LLMs) have recently soared in popularity due to their ease of access and the unprecedented intelligence exhibited on diverse applications. However, LLMs like ChatGPT present significant limitations in supporting complex information tasks due to the insufficient affordances of the text-based medium and linear conversational structure. Through a formative study with ten participants, we found that LLM interfaces often present long-winded responses, making it difficult for people to quickly comprehend and interact flexibly with various pieces of information, particularly during more complex tasks. We present Graphologue, an interactive system that converts text-based responses from LLMs into graphical diagrams to facilitate information-seeking and question-answering tasks. Graphologue employs novel prompting strategies and interface designs to extract entities and relationships from LLM responses and constructs node-link diagrams in real-time. Further, users can interact with the diagrams to flexibly adjust the graphical presentation and to submit context-specific prompts to obtain more information. Utilizing diagrams, Graphologue enables graphical, non-linear dialogues between humans and LLMs, facilitating information exploration, organization, and comprehension.
Learning Sequence Descriptor based on Spatiotemporal Attention for Visual Place Recognition
May 19, 2023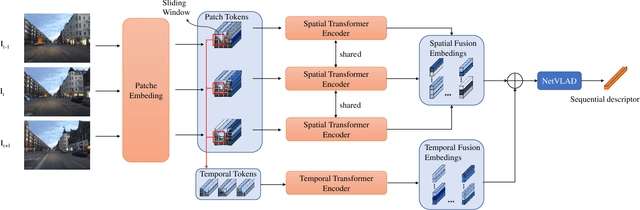
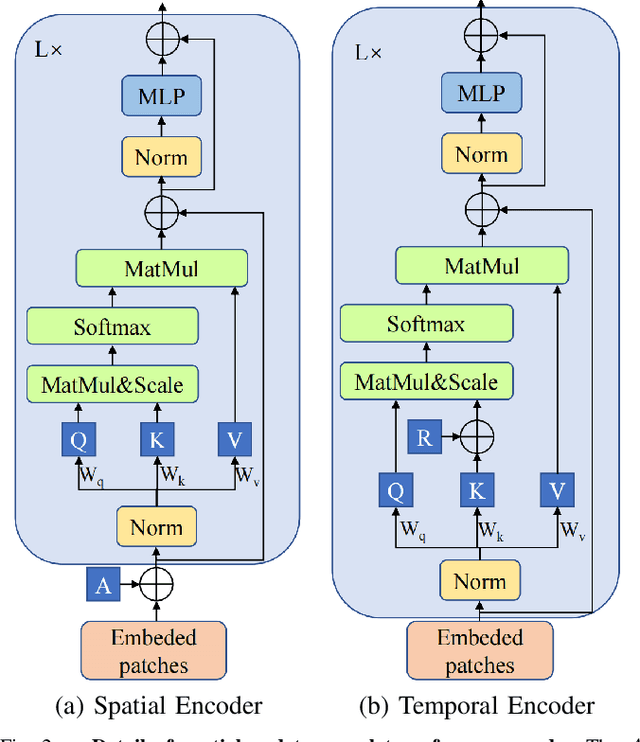
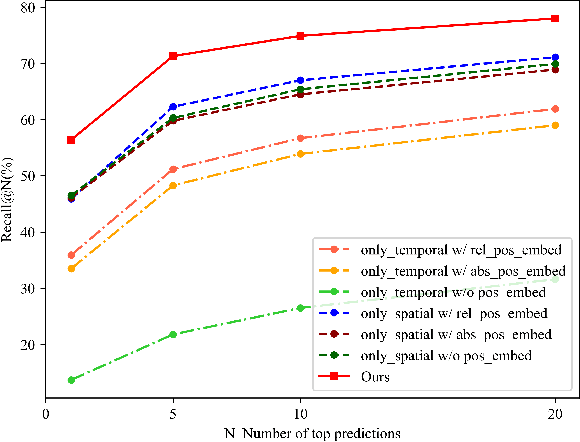
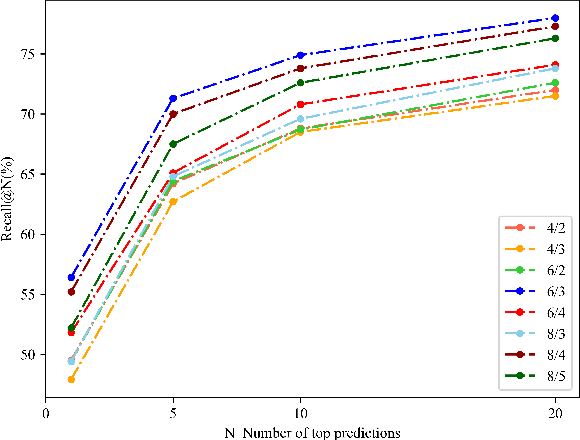
Sequence-based visual place recognition (sVPR) aims to match frame sequences with frames stored in a reference map for localization. Existing methods include sequence matching and sequence descriptor-based retrieval. The former is based on the assumption of constant velocity, which is difficult to hold in real scenarios and does not get rid of the intrinsic single frame descriptor mismatch. The latter solves this problem by extracting a descriptor for the whole sequence, but current sequence descriptors are only constructed by feature aggregation of multi-frames, with no temporal information interaction. In this paper, we propose a sequential descriptor extraction method to fuse spatiotemporal information effectively and generate discriminative descriptors. Specifically, similar features on the same frame focu on each other and learn space structure, and the same local regions of different frames learn local feature changes over time. And we use sliding windows to control the temporal self-attention range and adpot relative position encoding to construct the positional relationships between different features, which allows our descriptor to capture the inherent dynamics in the frame sequence and local feature motion.
Medical supervised masked autoencoders: Crafting a better masking strategy and efficient fine-tuning schedule for medical image classification
May 10, 2023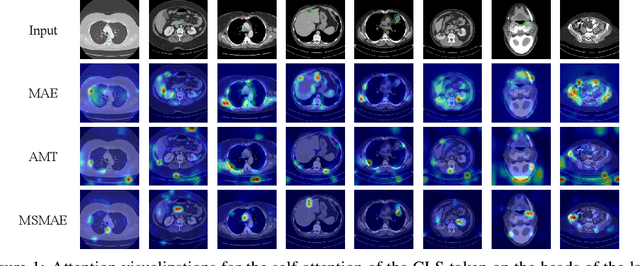
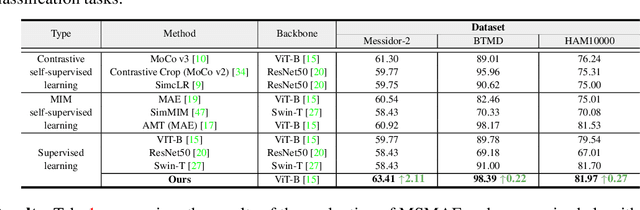
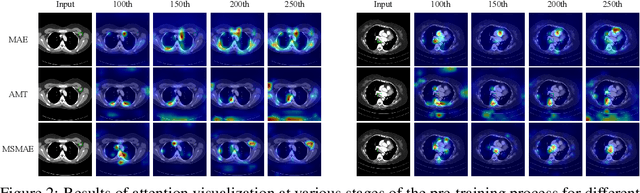
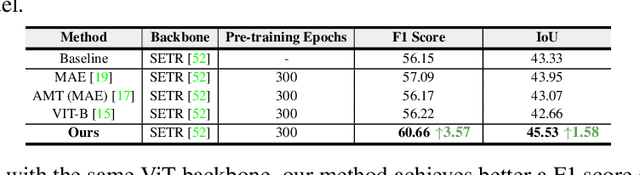
Masked autoencoders (MAEs) have displayed significant potential in the classification and semantic segmentation of medical images in the last year. Due to the high similarity of human tissues, even slight changes in medical images may represent diseased tissues, necessitating fine-grained inspection to pinpoint diseased tissues. The random masking strategy of MAEs is likely to result in areas of lesions being overlooked by the model. At the same time, inconsistencies between the pre-training and fine-tuning phases impede the performance and efficiency of MAE in medical image classification. To address these issues, we propose a medical supervised masked autoencoder (MSMAE) in this paper. In the pre-training phase, MSMAE precisely masks medical images via the attention maps obtained from supervised training, contributing to the representation learning of human tissue in the lesion area. During the fine-tuning phase, MSMAE is also driven by attention to the accurate masking of medical images. This improves the computational efficiency of the MSMAE while increasing the difficulty of fine-tuning, which indirectly improves the quality of MSMAE medical diagnosis. Extensive experiments demonstrate that MSMAE achieves state-of-the-art performance in case with three official medical datasets for various diseases. Meanwhile, transfer learning for MSMAE also demonstrates the great potential of our approach for medical semantic segmentation tasks. Moreover, the MSMAE accelerates the inference time in the fine-tuning phase by 11.2% and reduces the number of floating-point operations (FLOPs) by 74.08% compared to a traditional MAE.
HFLIC: Human Friendly Perceptual Learned Image Compression with Reinforced Transform
May 15, 2023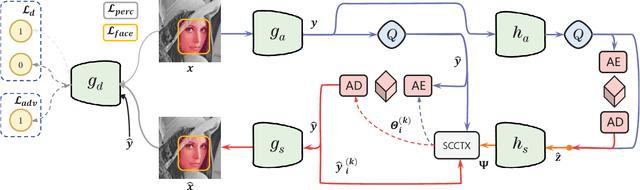
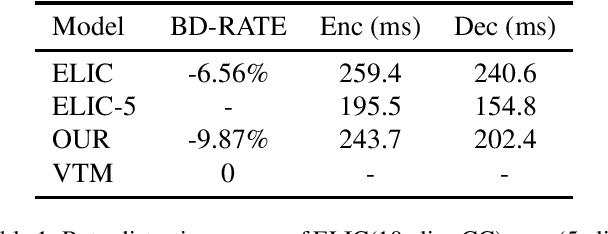
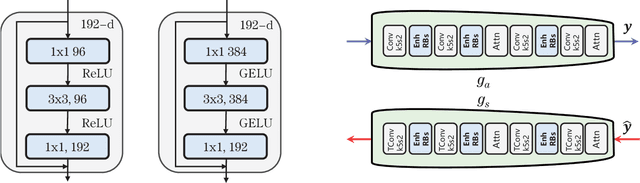
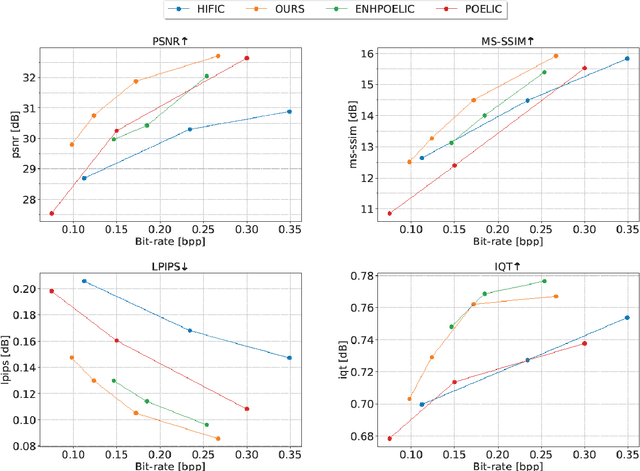
In recent years, there has been rapid development in learned image compression techniques that prioritize ratedistortion-perceptual compression, preserving fine details even at lower bit-rates. However, current learning-based image compression methods often sacrifice human-friendly compression and require long decoding times. In this paper, we propose enhancements to the backbone network and loss function of existing image compression model, focusing on improving human perception and efficiency. Our proposed approach achieves competitive subjective results compared to state-of-the-art end-to-end learned image compression methods and classic methods, while requiring less decoding time and offering human-friendly compression. Through empirical evaluation, we demonstrate the effectiveness of our proposed method in achieving outstanding performance, with more than 25% bit-rate saving at the same subjective quality.
Optimized Table Tokenization for Table Structure Recognition
May 05, 2023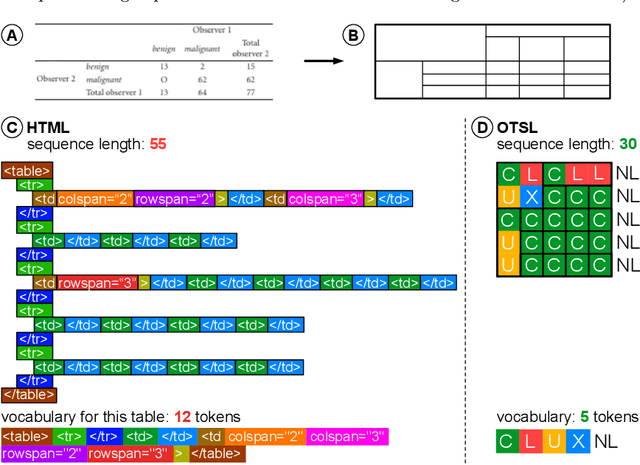
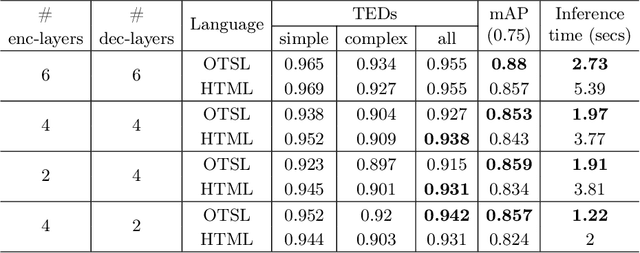
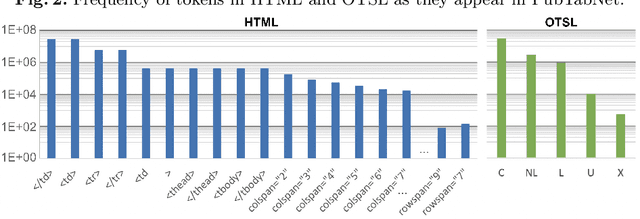
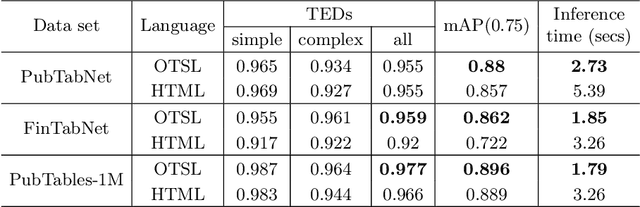
Extracting tables from documents is a crucial task in any document conversion pipeline. Recently, transformer-based models have demonstrated that table-structure can be recognized with impressive accuracy using Image-to-Markup-Sequence (Im2Seq) approaches. Taking only the image of a table, such models predict a sequence of tokens (e.g. in HTML, LaTeX) which represent the structure of the table. Since the token representation of the table structure has a significant impact on the accuracy and run-time performance of any Im2Seq model, we investigate in this paper how table-structure representation can be optimised. We propose a new, optimised table-structure language (OTSL) with a minimized vocabulary and specific rules. The benefits of OTSL are that it reduces the number of tokens to 5 (HTML needs 28+) and shortens the sequence length to half of HTML on average. Consequently, model accuracy improves significantly, inference time is halved compared to HTML-based models, and the predicted table structures are always syntactically correct. This in turn eliminates most post-processing needs.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023
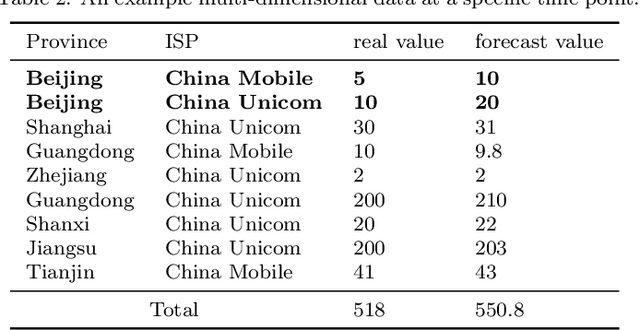
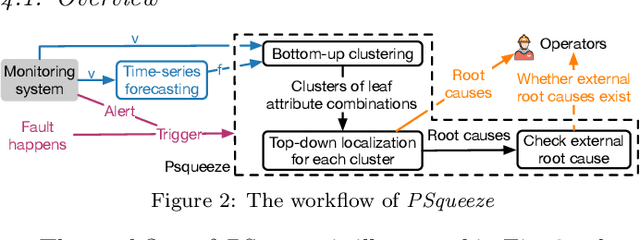

Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.