 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVista4D: Video Reshooting with 4D Point Clouds
Apr 23, 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
MOSS-VoiceGenerator: Create Realistic Voices with Natural Language Descriptions
Mar 30, 2026Voice design from natural language aims to generate speaker timbres directly from free-form textual descriptions, allowing users to create voices tailored to specific roles, personalities, and emotions. Such controllable voice creation benefits a wide range of downstream applications-including storytelling, game dubbing, role-play agents, and conversational assistants, making it a significant task for modern Text-to-Speech models. However, existing models are largely trained on carefully recorded studio data, which produces speech that is clean and well-articulated, yet lacks the lived-in qualities of real human voices. To address these limitations, we present MOSS-VoiceGenerator, an open-source instruction-driven voice generation model that creates new timbres directly from natural language prompts. Motivated by the hypothesis that exposure to real-world acoustic variation produces more perceptually natural voices, we train on large-scale expressive speech data sourced from cinematic content. Subjective preference studies demonstrate its superiority in overall performance, instruction-following, and naturalness compared to other voice design models.
MOSS-TTSD: Text to Spoken Dialogue Generation
Mar 20, 2026Spoken dialogue generation is crucial for applications like podcasts, dynamic commentary, and entertainment content, but poses significant challenges compared to single-utterance text-to-speech (TTS). Key requirements include accurate turn-taking, cross-turn acoustic consistency, and long-form stability, which current models often fail to address due to a lack of dialogue context modeling. To bridge this gap, we present MOSS-TTSD, a spoken dialogue synthesis model designed for expressive, multi-party conversational speech across multiple languages. With enhanced long-context modeling, MOSS-TTSD generates long-form spoken conversations from dialogue scripts with explicit speaker tags, supporting up to 60 minutes of single-pass synthesis, multi-party dialogue with up to 5 speakers, and zero-shot voice cloning from a short reference audio clip. The model supports various mainstream languages, including English and Chinese, and is adapted to several long-form scenarios. Additionally, to address limitations of existing evaluation methods, we propose TTSD-eval, an objective evaluation framework based on forced alignment that measures speaker attribution accuracy and speaker similarity without relying on speaker diarization tools. Both objective and subjective evaluation results show that MOSS-TTSD surpasses strong open-source and proprietary baselines in dialogue synthesis.
MOSS-TTS Technical Report
Mar 18, 2026This technical report presents MOSS-TTS, a speech generation foundation model built on a scalable recipe: discrete audio tokens, autoregressive modeling, and large-scale pretraining. Built on MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24 kHz audio to 12.5 fps with variable-bitrate RVQ and unified semantic-acoustic representations, we release two complementary generators: MOSS-TTS, which emphasizes structural simplicity, scalability, and long-context/control-oriented deployment, and MOSS-TTS-Local-Transformer, which introduces a frame-local autoregressive module for higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio. Across multilingual and open-domain settings, MOSS-TTS supports zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, smooth code-switching, and stable long-form generation. This report summarizes the design, training recipe, and empirical characteristics of the released models.
Virtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Oct 16, 2025We introduce a framework that enables both multi-view character consistency and 3D camera control in video diffusion models through a novel customization data pipeline. We train the character consistency component with recorded volumetric capture performances re-rendered with diverse camera trajectories via 4D Gaussian Splatting (4DGS), lighting variability obtained with a video relighting model. We fine-tune state-of-the-art open-source video diffusion models on this data to provide strong multi-view identity preservation, precise camera control, and lighting adaptability. Our framework also supports core capabilities for virtual production, including multi-subject generation using two approaches: joint training and noise blending, the latter enabling efficient composition of independently customized models at inference time; it also achieves scene and real-life video customization as well as control over motion and spatial layout during customization. Extensive experiments show improved video quality, higher personalization accuracy, and enhanced camera control and lighting adaptability, advancing the integration of video generation into virtual production. Our project page is available at: https://eyeline-labs.github.io/Virtually-Being.
PhysAnimator: Physics-Guided Generative Cartoon Animation
Jan 27, 2025



Creating hand-drawn animation sequences is labor-intensive and demands professional expertise. We introduce PhysAnimator, a novel approach for generating physically plausible meanwhile anime-stylized animation from static anime illustrations. Our method seamlessly integrates physics-based simulations with data-driven generative models to produce dynamic and visually compelling animations. To capture the fluidity and exaggeration characteristic of anime, we perform image-space deformable body simulations on extracted mesh geometries. We enhance artistic control by introducing customizable energy strokes and incorporating rigging point support, enabling the creation of tailored animation effects such as wind interactions. Finally, we extract and warp sketches from the simulation sequence, generating a texture-agnostic representation, and employ a sketch-guided video diffusion model to synthesize high-quality animation frames. The resulting animations exhibit temporal consistency and visual plausibility, demonstrating the effectiveness of our method in creating dynamic anime-style animations.
Neural Architecture Search of Hybrid Models for NPU-CIM Heterogeneous AR/VR Devices
Oct 10, 2024



Low-Latency and Low-Power Edge AI is essential for Virtual Reality and Augmented Reality applications. Recent advances show that hybrid models, combining convolution layers (CNN) and transformers (ViT), often achieve superior accuracy/performance tradeoff on various computer vision and machine learning (ML) tasks. However, hybrid ML models can pose system challenges for latency and energy-efficiency due to their diverse nature in dataflow and memory access patterns. In this work, we leverage the architecture heterogeneity from Neural Processing Units (NPU) and Compute-In-Memory (CIM) and perform diverse execution schemas to efficiently execute these hybrid models. We also introduce H4H-NAS, a Neural Architecture Search framework to design efficient hybrid CNN/ViT models for heterogeneous edge systems with both NPU and CIM. Our H4H-NAS approach is powered by a performance estimator built with NPU performance results measured on real silicon, and CIM performance based on industry IPs. H4H-NAS searches hybrid CNN/ViT models with fine granularity and achieves significant (up to 1.34%) top-1 accuracy improvement on ImageNet dataset. Moreover, results from our Algo/HW co-design reveal up to 56.08% overall latency and 41.72% energy improvements by introducing such heterogeneous computing over baseline solutions. The framework guides the design of hybrid network architectures and system architectures of NPU+CIM heterogeneous systems.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023



Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.
Taming the Expressiveness and Programmability of Graph Analytical Queries
Apr 20, 2020
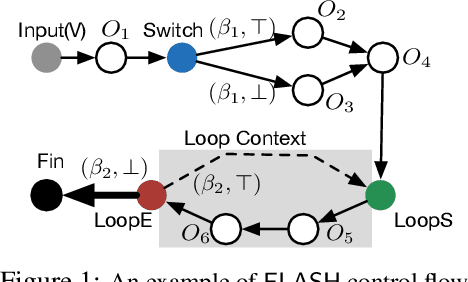
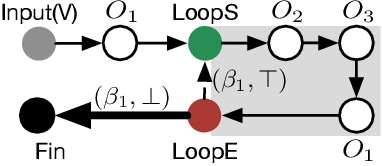
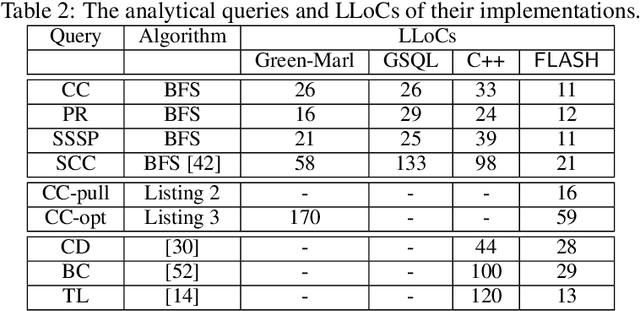
Graph database has enjoyed a boom in the last decade, and graph queries accordingly gain a lot of attentions from both the academia and industry. We focus on analytical queries in this paper. While analyzing existing domain-specific languages (DSLs) for analytical queries regarding the perspectives of completeness, expressiveness and programmability, we find out that none of existing work has achieved a satisfactory coverage of these perspectives. Motivated by this, we propose the \flash DSL, which is named after the three primitive operators Filter, LocAl and PuSH. We prove that \flash is Turing complete (completeness), and show that it achieves both good expressiveness and programmability for analytical queries. We provide an implementation of \flash based on code generation, and compare it with native C++ codes and existing DSL using representative queries. The experiment results demonstrate \flash's expressiveness, and its capability of programming complex algorithms that achieve satisfactory runtime.