 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Diffusion Policies for Offline Reinforcement Learning
May 31, 2023
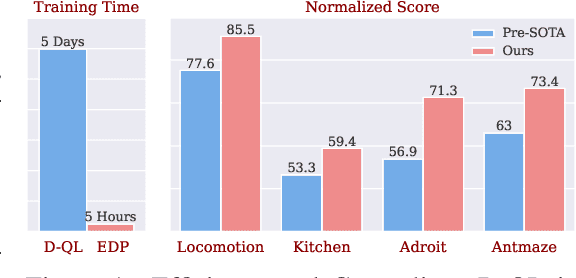
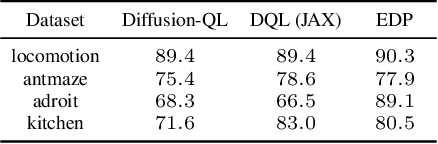
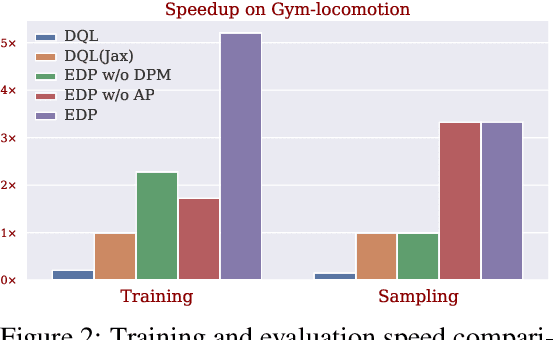
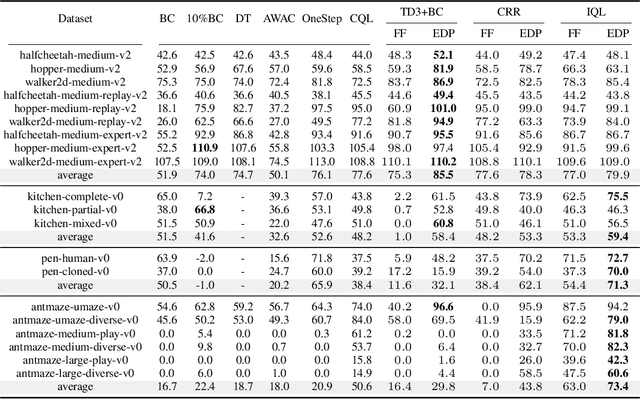
Offline reinforcement learning (RL) aims to learn optimal policies from offline datasets, where the parameterization of policies is crucial but often overlooked. Recently, Diffsuion-QL significantly boosts the performance of offline RL by representing a policy with a diffusion model, whose success relies on a parametrized Markov Chain with hundreds of steps for sampling. However, Diffusion-QL suffers from two critical limitations. 1) It is computationally inefficient to forward and backward through the whole Markov chain during training. 2) It is incompatible with maximum likelihood-based RL algorithms (e.g., policy gradient methods) as the likelihood of diffusion models is intractable. Therefore, we propose efficient diffusion policy (EDP) to overcome these two challenges. EDP approximately constructs actions from corrupted ones at training to avoid running the sampling chain. We conduct extensive experiments on the D4RL benchmark. The results show that EDP can reduce the diffusion policy training time from 5 days to 5 hours on gym-locomotion tasks. Moreover, we show that EDP is compatible with various offline RL algorithms (TD3, CRR, and IQL) and achieves new state-of-the-art on D4RL by large margins over previous methods. Our code is available at https://github.com/sail-sg/edp.
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
May 31, 2023

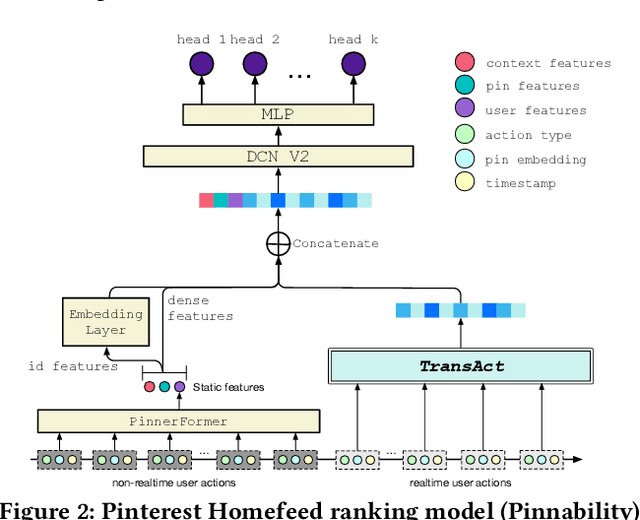

Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.
AQE: Argument Quadruplet Extraction via a Quad-Tagging Augmented Generative Approach
May 31, 2023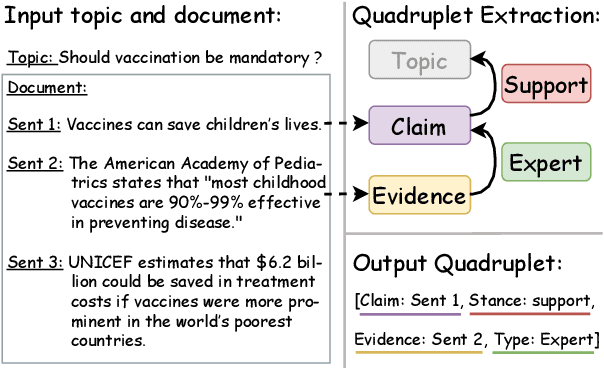
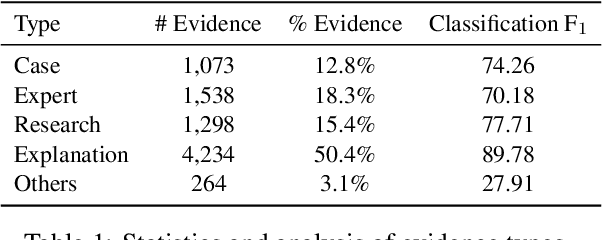
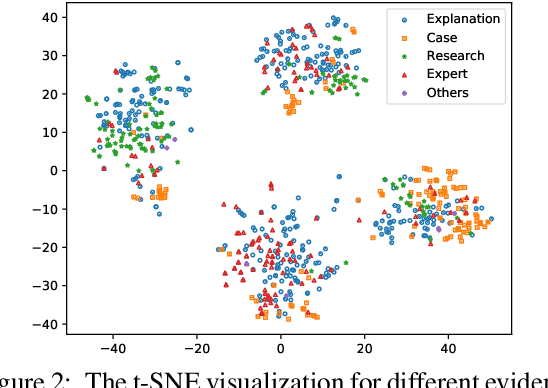
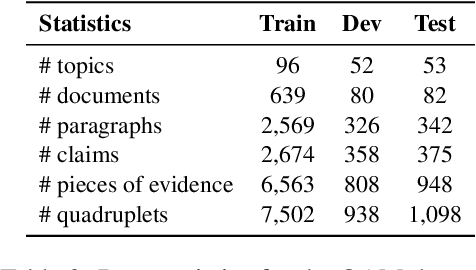
Argument mining involves multiple sub-tasks that automatically identify argumentative elements, such as claim detection, evidence extraction, stance classification, etc. However, each subtask alone is insufficient for a thorough understanding of the argumentative structure and reasoning process. To learn a complete view of an argument essay and capture the interdependence among argumentative components, we need to know what opinions people hold (i.e., claims), why those opinions are valid (i.e., supporting evidence), which source the evidence comes from (i.e., evidence type), and how those claims react to the debating topic (i.e., stance). In this work, we for the first time propose a challenging argument quadruplet extraction task (AQE), which can provide an all-in-one extraction of four argumentative components, i.e., claims, evidence, evidence types, and stances. To support this task, we construct a large-scale and challenging dataset. However, there is no existing method that can solve the argument quadruplet extraction. To fill this gap, we propose a novel quad-tagging augmented generative approach, which leverages a quadruplet tagging module to augment the training of the generative framework. The experimental results on our dataset demonstrate the empirical superiority of our proposed approach over several strong baselines.
ROSARL: Reward-Only Safe Reinforcement Learning
May 31, 2023
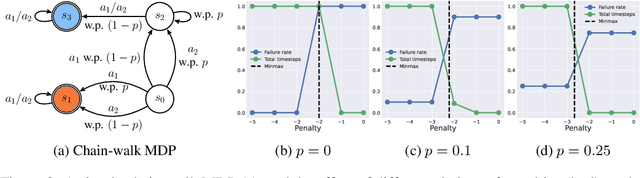
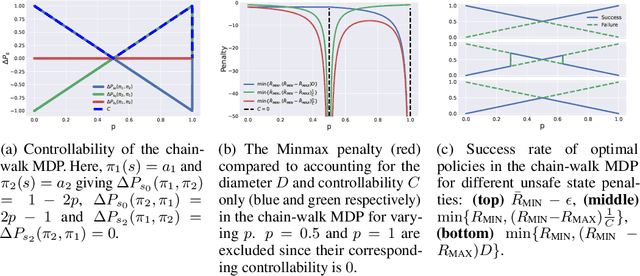

An important problem in reinforcement learning is designing agents that learn to solve tasks safely in an environment. A common solution is for a human expert to define either a penalty in the reward function or a cost to be minimised when reaching unsafe states. However, this is non-trivial, since too small a penalty may lead to agents that reach unsafe states, while too large a penalty increases the time to convergence. Additionally, the difficulty in designing reward or cost functions can increase with the complexity of the problem. Hence, for a given environment with a given set of unsafe states, we are interested in finding the upper bound of rewards at unsafe states whose optimal policies minimise the probability of reaching those unsafe states, irrespective of task rewards. We refer to this exact upper bound as the "Minmax penalty", and show that it can be obtained by taking into account both the controllability and diameter of an environment. We provide a simple practical model-free algorithm for an agent to learn this Minmax penalty while learning the task policy, and demonstrate that using it leads to agents that learn safe policies in high-dimensional continuous control environments.
Computation with Sequences in the Brain
Jun 06, 2023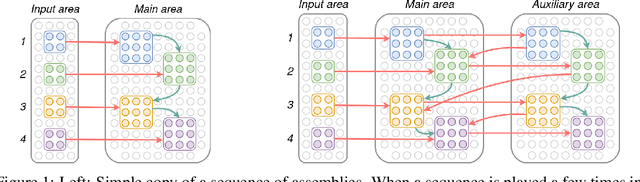
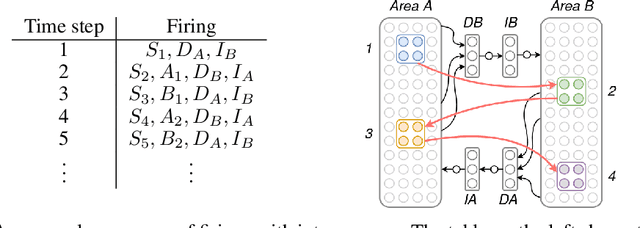
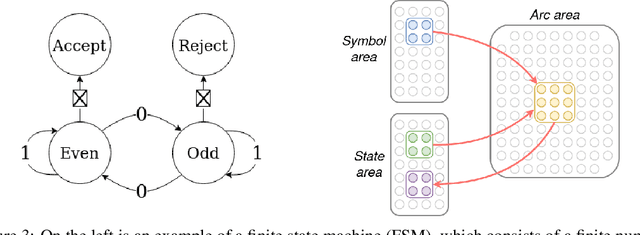
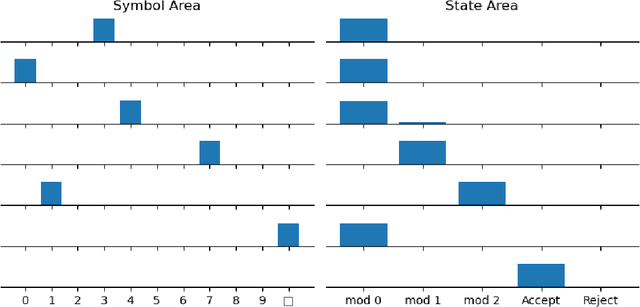
Even as machine learning exceeds human-level performance on many applications, the generality, robustness, and rapidity of the brain's learning capabilities remain unmatched. How cognition arises from neural activity is a central open question in neuroscience, inextricable from the study of intelligence itself. A simple formal model of neural activity was proposed in Papadimitriou [2020] and has been subsequently shown, through both mathematical proofs and simulations, to be capable of implementing certain simple cognitive operations via the creation and manipulation of assemblies of neurons. However, many intelligent behaviors rely on the ability to recognize, store, and manipulate temporal sequences of stimuli (planning, language, navigation, to list a few). Here we show that, in the same model, time can be captured naturally as precedence through synaptic weights and plasticity, and, as a result, a range of computations on sequences of assemblies can be carried out. In particular, repeated presentation of a sequence of stimuli leads to the memorization of the sequence through corresponding neural assemblies: upon future presentation of any stimulus in the sequence, the corresponding assembly and its subsequent ones will be activated, one after the other, until the end of the sequence. Finally, we show that any finite state machine can be learned in a similar way, through the presentation of appropriate patterns of sequences. Through an extension of this mechanism, the model can be shown to be capable of universal computation. We support our analysis with a number of experiments to probe the limits of learning in this model in key ways. Taken together, these results provide a concrete hypothesis for the basis of the brain's remarkable abilities to compute and learn, with sequences playing a vital role.
Fast Submodular Function Maximization
May 15, 2023Submodular functions have many real-world applications, such as document summarization, sensor placement, and image segmentation. For all these applications, the key building block is how to compute the maximum value of a submodular function efficiently. We consider both the online and offline versions of the problem: in each iteration, the data set changes incrementally or is not changed, and a user can issue a query to maximize the function on a given subset of the data. The user can be malicious, issuing queries based on previous query results to break the competitive ratio for the online algorithm. Today, the best-known algorithm for online submodular function maximization has a running time of $O(n k d^2)$ where $n$ is the total number of elements, $d$ is the feature dimension and $k$ is the number of elements to be selected. We propose a new method based on a novel search tree data structure. Our algorithm only takes $\widetilde{O}(nk + kd^2 + nd)$ time.
Distilling Knowledge for Short-to-Long Term Trajectory Prediction
May 15, 2023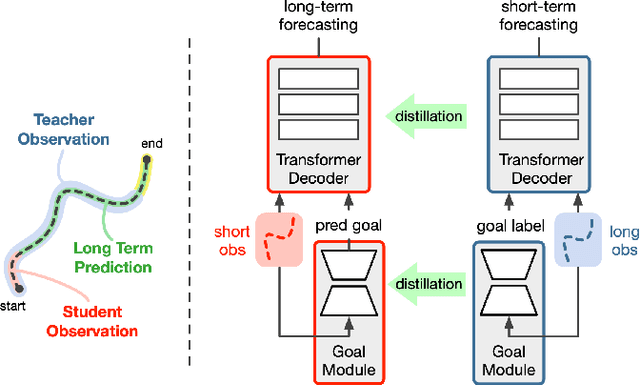
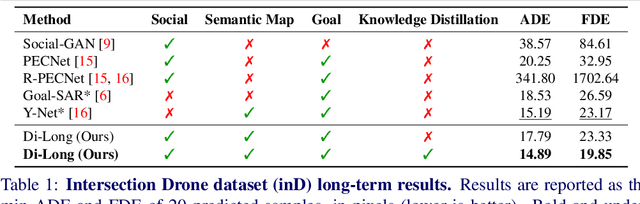
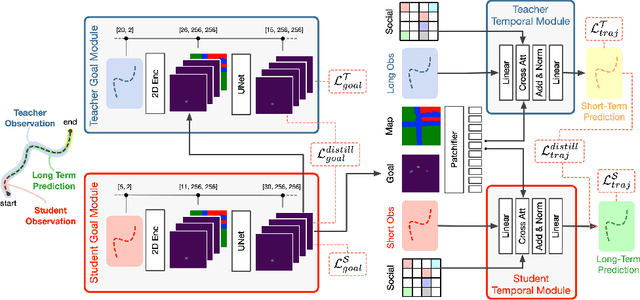
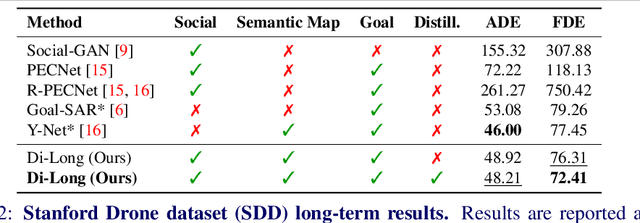
Long-term trajectory forecasting is a challenging problem in the field of computer vision and machine learning. In this paper, we propose a new method dubbed Di-Long ("Distillation for Long-Term trajectory") for long-term trajectory forecasting, which is based on knowledge distillation. Our approach involves training a student network to solve the long-term trajectory forecasting problem, whereas the teacher network from which the knowledge is distilled has a longer observation, and solves a short-term trajectory prediction problem by regularizing the student's predictions. Specifically, we use a teacher model to generate plausible trajectories for a shorter time horizon, and then distill the knowledge from the teacher model to a student model that solves the problem for a much higher time horizon. Our experiments show that the proposed Di-Long approach is beneficial for long-term forecasting, and our model achieves state-of-the-art performance on the Intersection Drone Dataset (inD) and the Stanford Drone Dataset (SDD).
Mechanical Property Design of Bio-compatible Mg alloys using Machine-Learning Algorithms
May 20, 2023
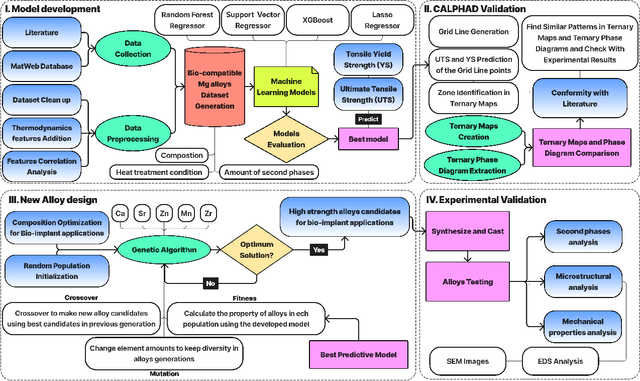
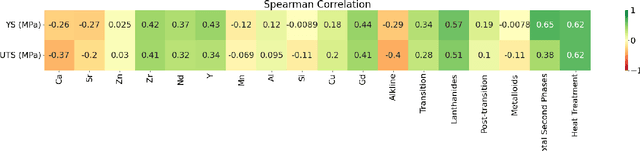

Magnesium alloys are attractive options for temporary bio-implants because of their biocompatibility, controlled corrosion rate, and similarity to natural bone in terms of stiffness and density. Nevertheless, their low mechanical strength hinders their use as cardiovascular stents and bone substitutes. While it is possible to engineer alloys with the desired mechanical strength, optimizing the mechanical properties of biocompatible magnesium alloys using conventional experimental methods is time-consuming and expensive. Therefore, Artificial Intelligence (AI) can be leveraged to streamline the alloy design process and reduce the required time. In this study, a machine learning model was developed to predict the yield strength (YS) of biocompatible magnesium alloys with an $R^2$ accuracy of 91\%. The predictive model was then validated using the CALPHAD technique and thermodynamics calculations. Next, the predictive model was employed as the fitness function of a genetic algorithm to optimize the alloy composition for high-strength biocompatible magnesium implants. As a result, two alloys were proposed and synthesized, exhibiting YS values of 108 and 113 MPa, respectively. These values were substantially higher than those of conventional magnesium biocompatible alloys and closer to the YS and compressive strength of natural bone. Finally, the synthesized alloys were subjected to microstructure analysis and mechanical property testing to validate and evaluate the performance of the proposed AI-based alloy design approach for creating alloys with specific properties suitable for diverse applications.
Integrated Sensing, Computation, and Communication for UAV-assisted Federated Edge Learning
Jun 05, 2023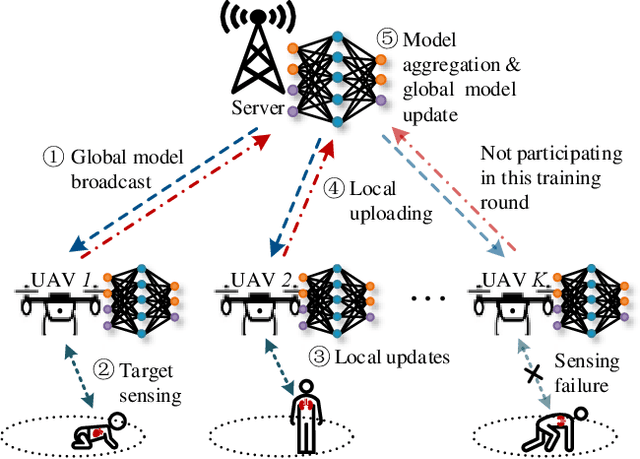
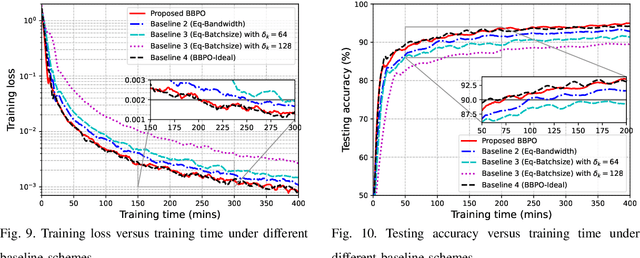
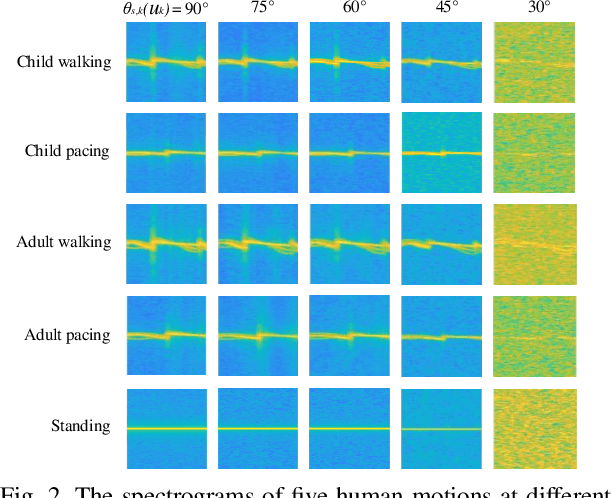
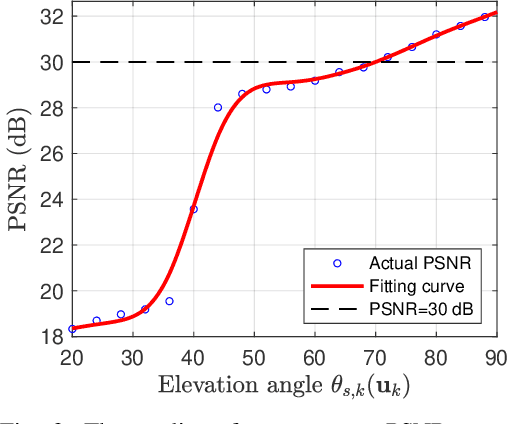
Federated edge learning (FEEL) enables privacy-preserving model training through periodic communication between edge devices and the server. Unmanned Aerial Vehicle (UAV)-mounted edge devices are particularly advantageous for FEEL due to their flexibility and mobility in efficient data collection. In UAV-assisted FEEL, sensing, computation, and communication are coupled and compete for limited onboard resources, and UAV deployment also affects sensing and communication performance. Therefore, the joint design of UAV deployment and resource allocation is crucial to achieving the optimal training performance. In this paper, we address the problem of joint UAV deployment design and resource allocation for FEEL via a concrete case study of human motion recognition based on wireless sensing. We first analyze the impact of UAV deployment on the sensing quality and identify a threshold value for the sensing elevation angle that guarantees a satisfactory quality of data samples. Due to the non-ideal sensing channels, we consider the probabilistic sensing model, where the successful sensing probability of each UAV is determined by its position. Then, we derive the upper bound of the FEEL training loss as a function of the sensing probability. Theoretical results suggest that the convergence rate can be improved if UAVs have a uniform successful sensing probability. Based on this analysis, we formulate a training time minimization problem by jointly optimizing UAV deployment, integrated sensing, computation, and communication (ISCC) resources under a desirable optimality gap constraint. To solve this challenging mixed-integer non-convex problem, we apply the alternating optimization technique, and propose the bandwidth, batch size, and position optimization (BBPO) scheme to optimize these three decision variables alternately.
Cyclic Learning: Bridging Image-level Labels and Nuclei Instance Segmentation
Jun 05, 2023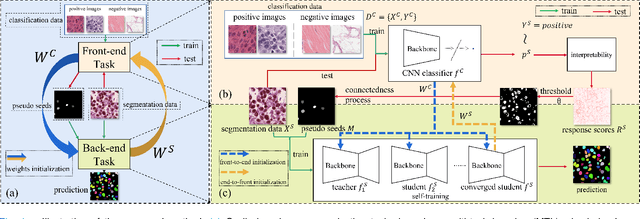



Nuclei instance segmentation on histopathology images is of great clinical value for disease analysis. Generally, fully-supervised algorithms for this task require pixel-wise manual annotations, which is especially time-consuming and laborious for the high nuclei density. To alleviate the annotation burden, we seek to solve the problem through image-level weakly supervised learning, which is underexplored for nuclei instance segmentation. Compared with most existing methods using other weak annotations (scribble, point, etc.) for nuclei instance segmentation, our method is more labor-saving. The obstacle to using image-level annotations in nuclei instance segmentation is the lack of adequate location information, leading to severe nuclei omission or overlaps. In this paper, we propose a novel image-level weakly supervised method, called cyclic learning, to solve this problem. Cyclic learning comprises a front-end classification task and a back-end semi-supervised instance segmentation task to benefit from multi-task learning (MTL). We utilize a deep learning classifier with interpretability as the front-end to convert image-level labels to sets of high-confidence pseudo masks and establish a semi-supervised architecture as the back-end to conduct nuclei instance segmentation under the supervision of these pseudo masks. Most importantly, cyclic learning is designed to circularly share knowledge between the front-end classifier and the back-end semi-supervised part, which allows the whole system to fully extract the underlying information from image-level labels and converge to a better optimum. Experiments on three datasets demonstrate the good generality of our method, which outperforms other image-level weakly supervised methods for nuclei instance segmentation, and achieves comparable performance to fully-supervised methods.