 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
May 31, 2023Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach
Sep 18, 2022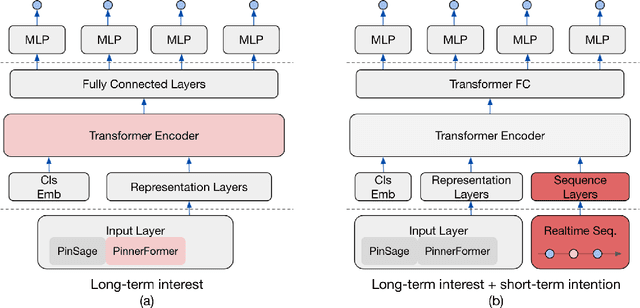
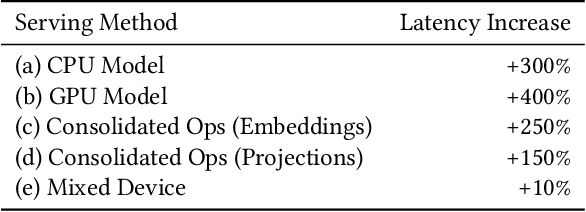
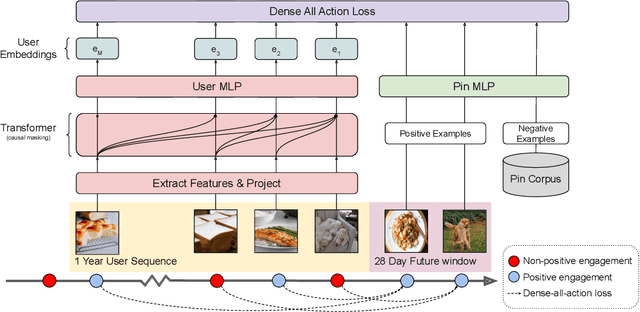

In this work, we present our journey to revolutionize the personalized recommendation engine through end-to-end learning from raw user actions. We encode user's long-term interest in Pinner- Former, a user embedding optimized for long-term future actions via a new dense all-action loss, and capture user's short-term intention by directly learning from the real-time action sequences. We conducted both offline and online experiments to validate the performance of the new model architecture, and also address the challenge of serving such a complex model using mixed CPU/GPU setup in production. The proposed system has been deployed in production at Pinterest and has delivered significant online gains across organic and Ads applications.
ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest
May 24, 2022

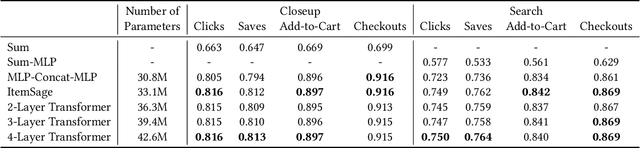
Learned embeddings for products are an important building block for web-scale e-commerce recommendation systems. At Pinterest, we build a single set of product embeddings called ItemSage to provide relevant recommendations in all shopping use cases including user, image and search based recommendations. This approach has led to significant improvements in engagement and conversion metrics, while reducing both infrastructure and maintenance cost. While most prior work focuses on building product embeddings from features coming from a single modality, we introduce a transformer-based architecture capable of aggregating information from both text and image modalities and show that it significantly outperforms single modality baselines. We also utilize multi-task learning to make ItemSage optimized for several engagement types, leading to a candidate generation system that is efficient for all of the engagement objectives of the end-to-end recommendation system. Extensive offline experiments are conducted to illustrate the effectiveness of our approach and results from online A/B experiments show substantial gains in key business metrics (up to +7% gross merchandise value/user and +11% click volume).
* 9 pages, 5 figures
MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest
May 21, 2022

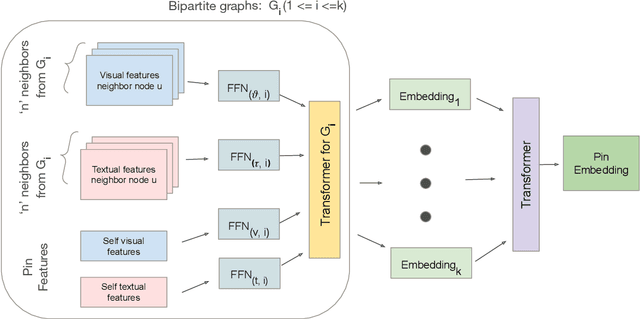
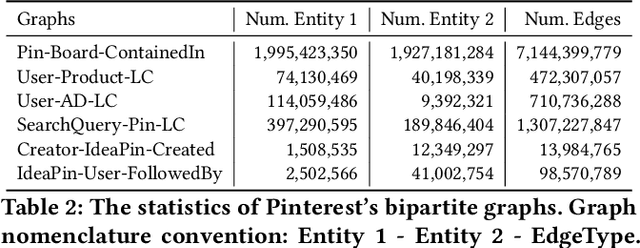
Graph Convolutional Networks (GCN) can efficiently integrate graph structure and node features to learn high-quality node embeddings. These embeddings can then be used for several tasks such as recommendation and search. At Pinterest, we have developed and deployed PinSage, a data-efficient GCN that learns pin embeddings from the Pin-Board graph. The Pin-Board graph contains pin and board entities and the graph captures the pin belongs to a board interaction. However, there exist several entities at Pinterest such as users, idea pins, creators, and there exist heterogeneous interactions among these entities such as add-to-cart, follow, long-click. In this work, we show that training deep learning models on graphs that captures these diverse interactions would result in learning higher-quality pin embeddings than training PinSage on only the Pin-Board graph. To that end, we model the diverse entities and their diverse interactions through multiple bipartite graphs and propose a novel data-efficient MultiBiSage model. MultiBiSage can capture the graph structure of multiple bipartite graphs to learn high-quality pin embeddings. We take this pragmatic approach as it allows us to utilize the existing infrastructure developed at Pinterest -- such as Pixie system that can perform optimized random-walks on billion node graphs, along with existing training and deployment workflows. We train MultiBiSage on six bipartite graphs including our Pin-Board graph. Our offline metrics show that MultiBiSage significantly outperforms the deployed latest version of PinSage on multiple user engagement metrics.
PinnerFormer: Sequence Modeling for User Representation at Pinterest
May 09, 2022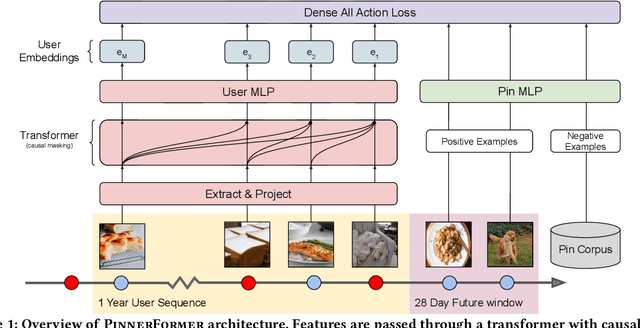
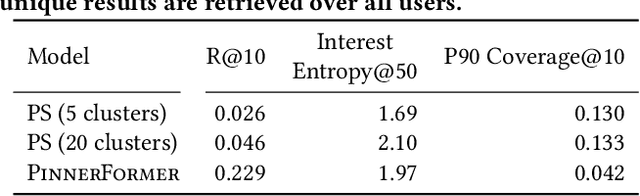
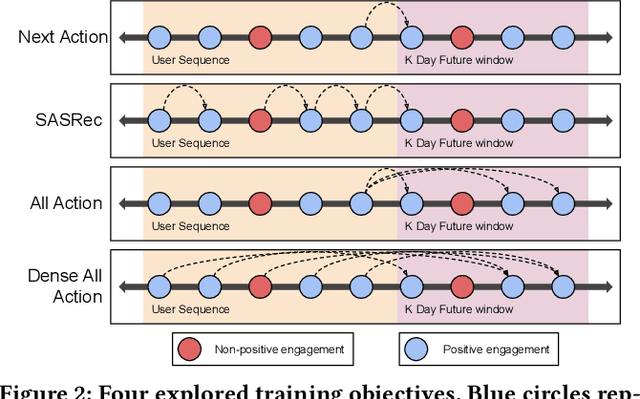
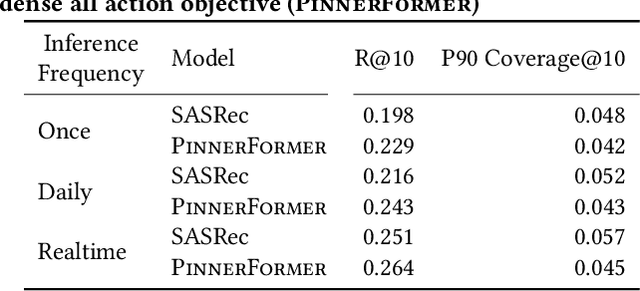
Sequential models have become increasingly popular in powering personalized recommendation systems over the past several years. These approaches traditionally model a user's actions on a website as a sequence to predict the user's next action. While theoretically simplistic, these models are quite challenging to deploy in production, commonly requiring streaming infrastructure to reflect the latest user activity and potentially managing mutable data for encoding a user's hidden state. Here we introduce PinnerFormer, a user representation trained to predict a user's future long-term engagement using a sequential model of a user's recent actions. Unlike prior approaches, we adapt our modeling to a batch infrastructure via our new dense all-action loss, modeling long-term future actions instead of next action prediction. We show that by doing so, we significantly close the gap between batch user embeddings that are generated once a day and realtime user embeddings generated whenever a user takes an action. We describe our design decisions via extensive offline experimentation and ablations and validate the efficacy of our approach in A/B experiments showing substantial improvements in Pinterest's user retention and engagement when comparing PinnerFormer against our previous user representation. PinnerFormer is deployed in production as of Fall 2021.
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021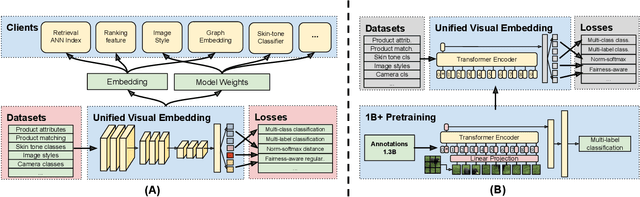
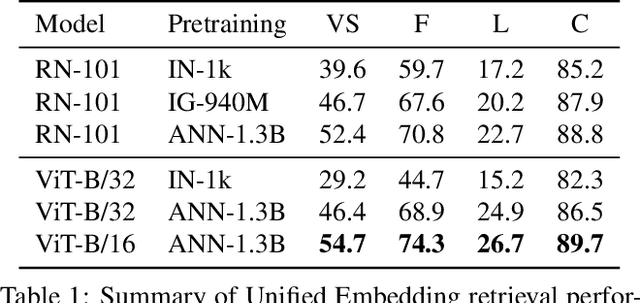

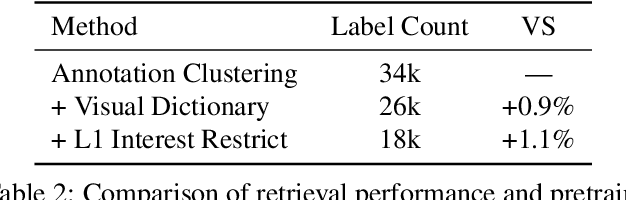
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Toward Transformer-Based Object Detection
Dec 17, 2020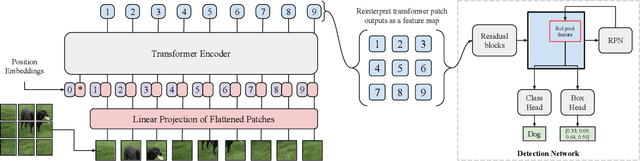
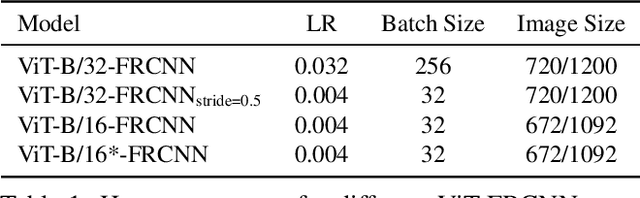
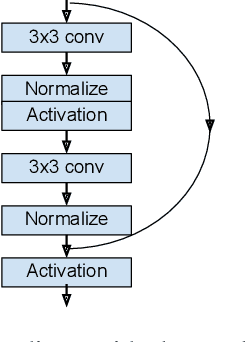
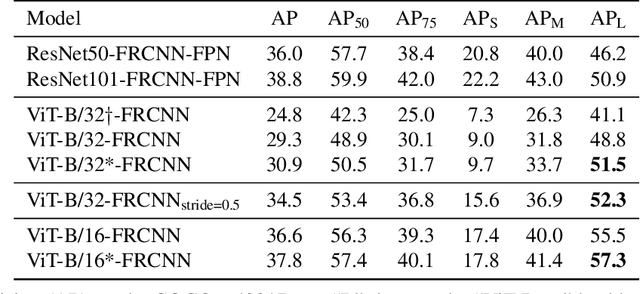
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Bootstrapping Complete The Look at Pinterest
Jun 29, 2020
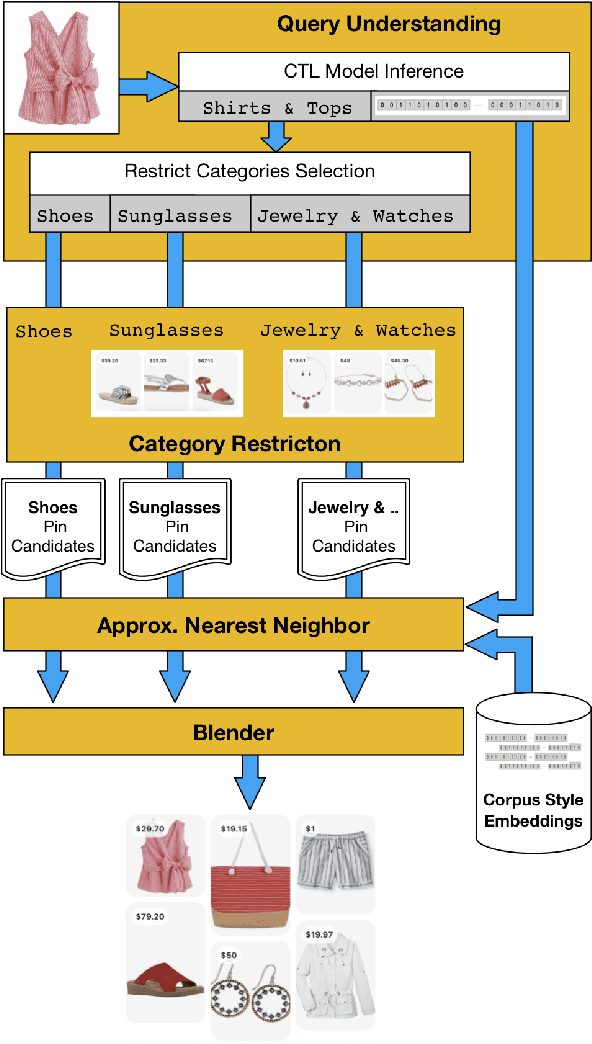
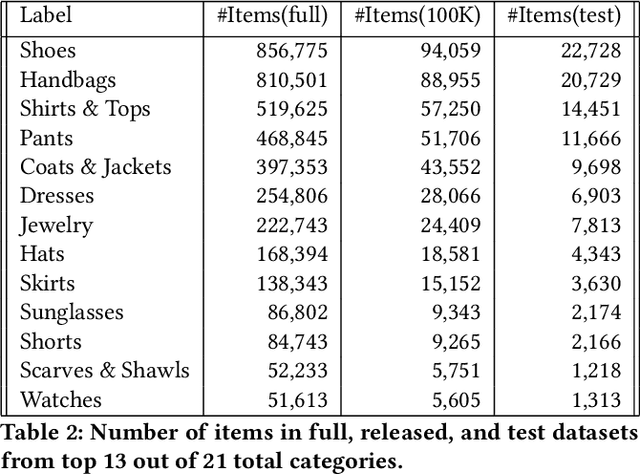
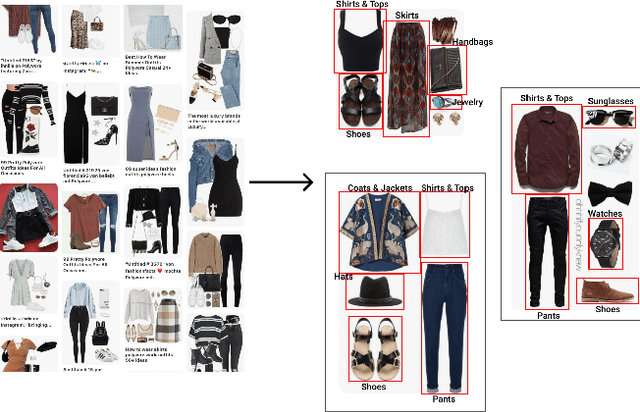
Putting together an ideal outfit is a process that involves creativity and style intuition. This makes it a particularly difficult task to automate. Existing styling products generally involve human specialists and a highly curated set of fashion items. In this paper, we will describe how we bootstrapped the Complete The Look (CTL) system at Pinterest. This is a technology that aims to learn the subjective task of "style compatibility" in order to recommend complementary items that complete an outfit. In particular, we want to show recommendations from other categories that are compatible with an item of interest. For example, what are some heels that go well with this cocktail dress? We will introduce our outfit dataset of over 1 million outfits and 4 million objects, a subset of which we will make available to the research community, and describe the pipeline used to obtain and refresh this dataset. Furthermore, we will describe how we evaluate this subjective task and compare model performance across multiple training methods. Lastly, we will share our lessons going from experimentation to working prototype, and how to mitigate failure modes in the production environment. Our work represents one of the first examples of an industrial-scale solution for compatibility-based fashion recommendation.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020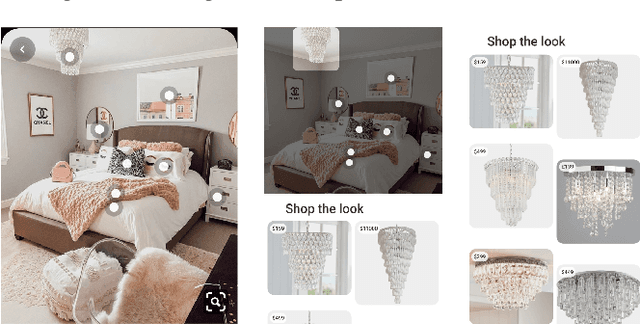

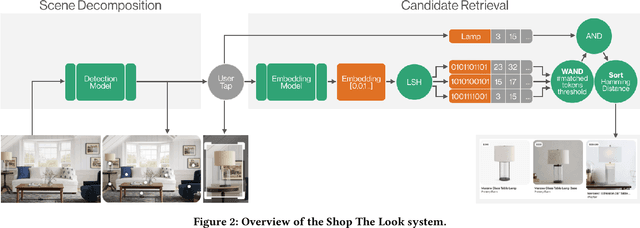
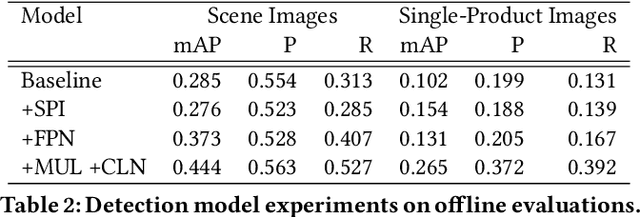
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.