 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GPS Attack Detection and Mitigation for Safe Autonomous Driving using Image and Map based Lateral Direction Localization
Oct 09, 2023
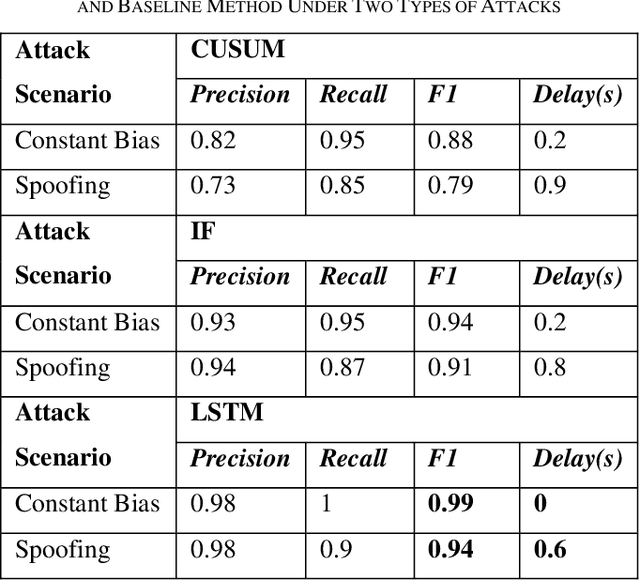
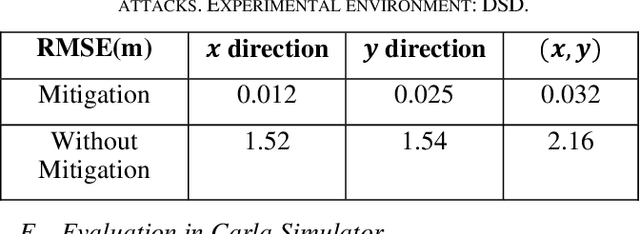
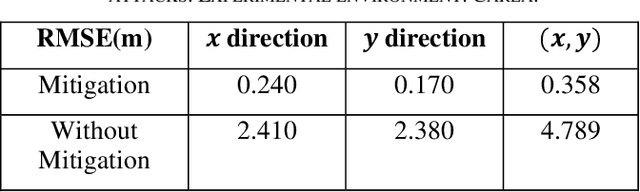
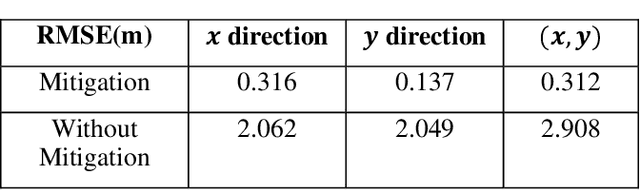
The accuracy and robustness of vehicle localization are critical for achieving safe and reliable high-level autonomy. Recent results show that GPS is vulnerable to spoofing attacks, which is one major threat to autonomous driving. In this paper, a novel anomaly detection and mitigation method against GPS attacks that utilizes onboard camera and high-precision maps is proposed to ensure accurate vehicle localization. First, lateral direction localization in driving lanes is calculated by camera-based lane detection and map matching respectively. Then, a real-time detector for GPS spoofing attack is developed to evaluate the localization data. When the attack is detected, a multi-source fusion-based localization method using Unscented Kalman filter is derived to mitigate GPS attack and improve the localization accuracy. The proposed method is validated in various scenarios in Carla simulator and open-source public dataset to demonstrate its effectiveness in timely GPS attack detection and data recovery.
STOPNet: Multiview-based 6-DoF Suction Detection for Transparent Objects on Production Lines
Oct 09, 2023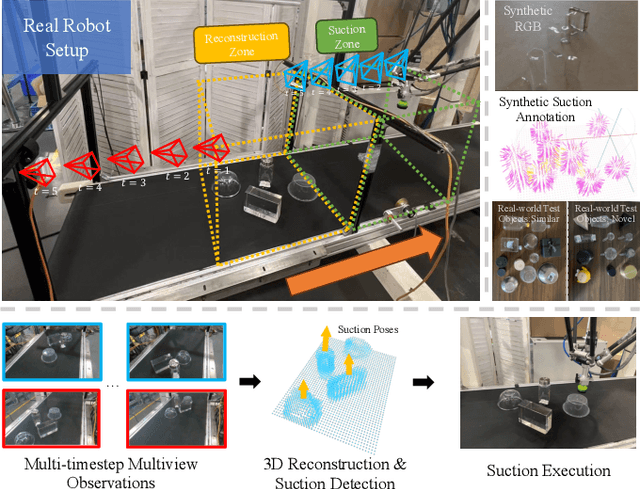
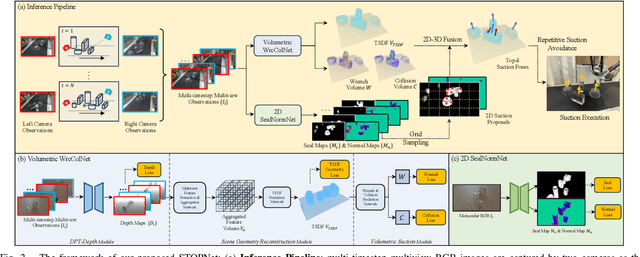
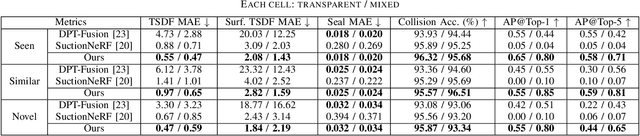
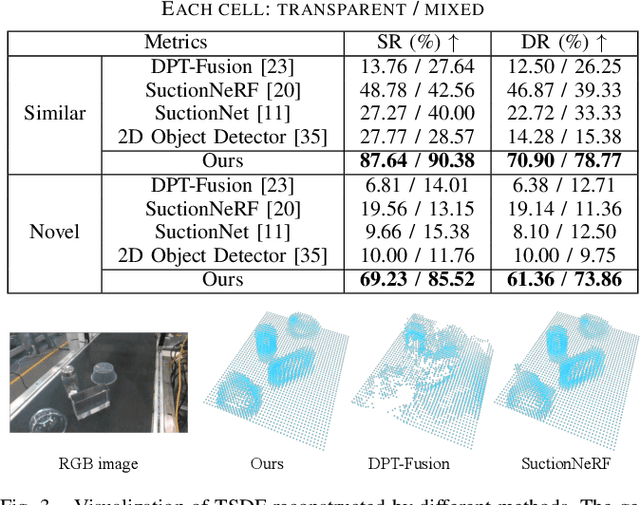
In this work, we present STOPNet, a framework for 6-DoF object suction detection on production lines, with a focus on but not limited to transparent objects, which is an important and challenging problem in robotic systems and modern industry. Current methods requiring depth input fail on transparent objects due to depth cameras' deficiency in sensing their geometry, while we proposed a novel framework to reconstruct the scene on the production line depending only on RGB input, based on multiview stereo. Compared to existing works, our method not only reconstructs the whole 3D scene in order to obtain high-quality 6-DoF suction poses in real time but also generalizes to novel environments, novel arrangements and novel objects, including challenging transparent objects, both in simulation and the real world. Extensive experiments in simulation and the real world show that our method significantly surpasses the baselines and has better generalizability, which caters to practical industrial needs.
Binary Classification with Confidence Difference
Oct 09, 2023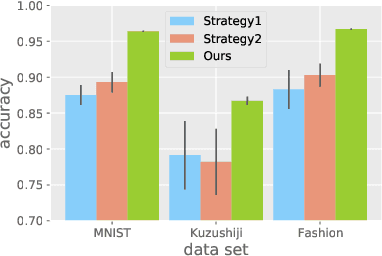

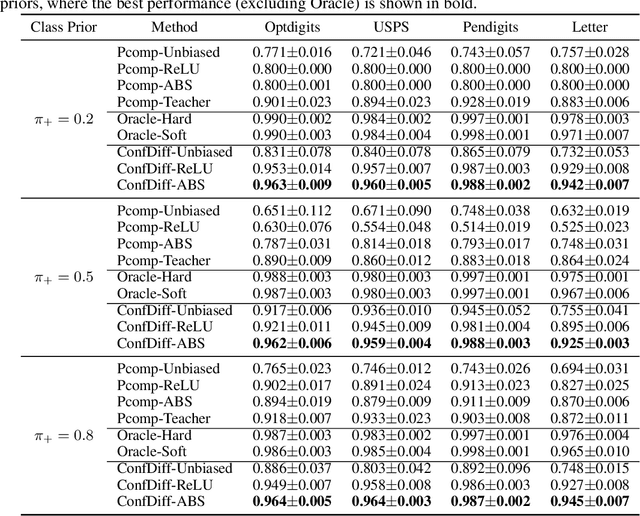
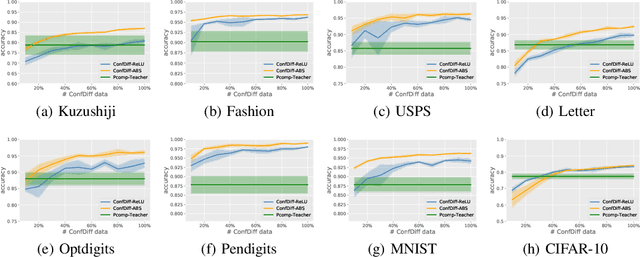
Recently, learning with soft labels has been shown to achieve better performance than learning with hard labels in terms of model generalization, calibration, and robustness. However, collecting pointwise labeling confidence for all training examples can be challenging and time-consuming in real-world scenarios. This paper delves into a novel weakly supervised binary classification problem called confidence-difference (ConfDiff) classification. Instead of pointwise labeling confidence, we are given only unlabeled data pairs with confidence difference that specifies the difference in the probabilities of being positive. We propose a risk-consistent approach to tackle this problem and show that the estimation error bound achieves the optimal convergence rate. We also introduce a risk correction approach to mitigate overfitting problems, whose consistency and convergence rate are also proven. Extensive experiments on benchmark data sets and a real-world recommender system data set validate the effectiveness of our proposed approaches in exploiting the supervision information of the confidence difference.
Geometry-Aware Safety-Critical Local Reactive Controller for Robot Navigation in Unknown and Cluttered Environments
Oct 09, 2023
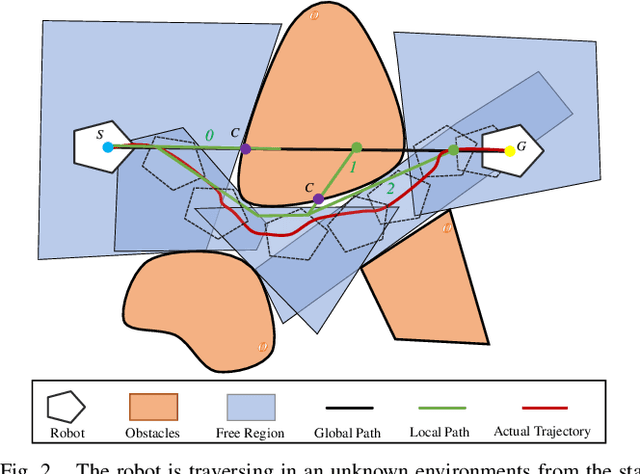
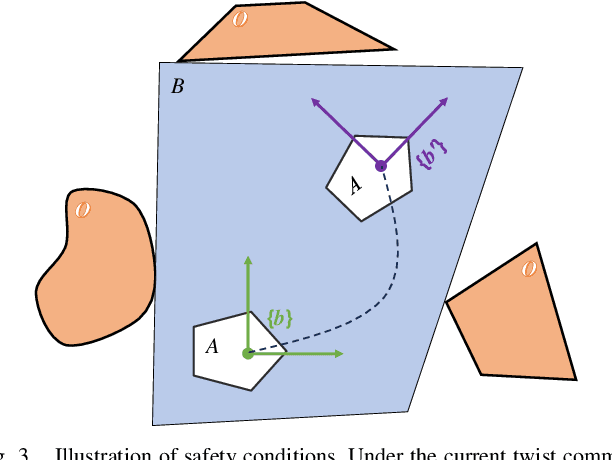
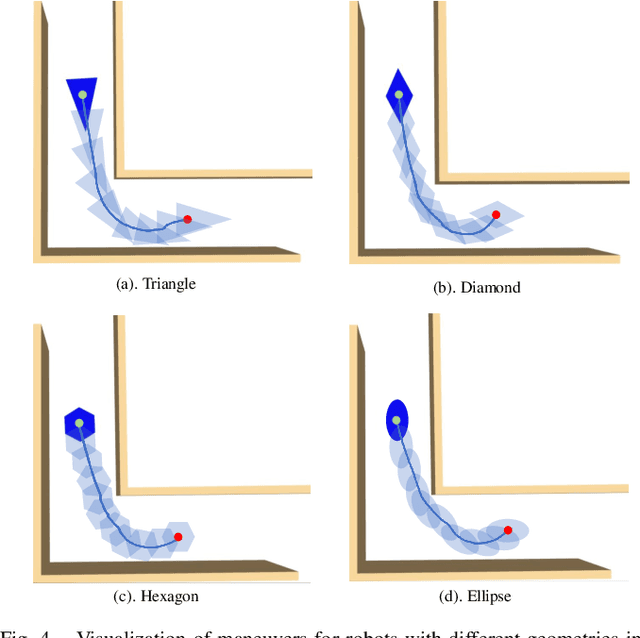
This work proposes a safety-critical local reactive controller that enables the robot to navigate in unknown and cluttered environments. In particular, the trajectory tracking task is formulated as a constrained polynomial optimization problem. Then, safety constraints are imposed on the control variables invoking the notion of polynomial positivity certificates in conjunction with their Sum-of-Squares (SOS) approximation, thereby confining the robot motion inside the locally extracted convex free region. It is noteworthy that, in the process of devising the proposed safety constraints, the geometry of the robot can be approximated using any shape that can be characterized with a set of polynomial functions. The optimization problem is further convexified into a semidefinite program (SDP) leveraging truncated multi-sequences (tms) and moment relaxation, which favorably facilitates the effective use of off-the-shelf conic programming solvers, such that real-time performance is attainable. Various robot navigation tasks are investigated to demonstrate the effectiveness of the proposed approach in terms of safety and tracking performance.
Motion Memory: Leveraging Past Experiences to Accelerate Future Motion Planning
Oct 09, 2023When facing a new motion-planning problem, most motion planners solve it from scratch, e.g., via sampling and exploration or starting optimization from a straight-line path. However, most motion planners have to experience a variety of planning problems throughout their lifetimes, which are yet to be leveraged for future planning. In this paper, we present a simple but efficient method called Motion Memory, which allows different motion planners to accelerate future planning using past experiences. Treating existing motion planners as either a closed or open box, we present a variety of ways that Motion Memory can contribute to reduce the planning time when facing a new planning problem. We provide extensive experiment results with three different motion planners on three classes of planning problems with over 30,000 problem instances and show that planning speed can be significantly reduced by up to 89% with the proposed Motion Memory technique and with increasing past planning experiences.
LangNav: Language as a Perceptual Representation for Navigation
Oct 11, 2023
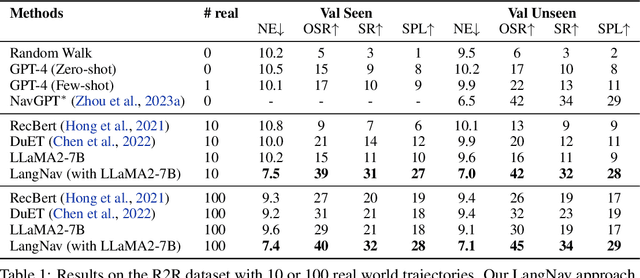
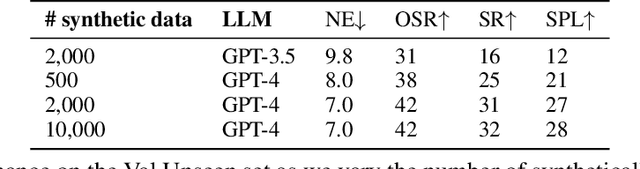
We explore the use of language as a perceptual representation for vision-and-language navigation. Our approach uses off-the-shelf vision systems (for image captioning and object detection) to convert an agent's egocentric panoramic view at each time step into natural language descriptions. We then finetune a pretrained language model to select an action, based on the current view and the trajectory history, that would best fulfill the navigation instructions. In contrast to the standard setup which adapts a pretrained language model to work directly with continuous visual features from pretrained vision models, our approach instead uses (discrete) language as the perceptual representation. We explore two use cases of our language-based navigation (LangNav) approach on the R2R vision-and-language navigation benchmark: generating synthetic trajectories from a prompted large language model (GPT-4) with which to finetune a smaller language model; and sim-to-real transfer where we transfer a policy learned on a simulated environment (ALFRED) to a real-world environment (R2R). Our approach is found to improve upon strong baselines that rely on visual features in settings where only a few gold trajectories (10-100) are available, demonstrating the potential of using language as a perceptual representation for navigation tasks.
Guided Attention for Interpretable Motion Captioning
Oct 11, 2023While much effort has been invested in generating human motion from text, relatively few studies have been dedicated to the reverse direction, that is, generating text from motion. Much of the research focuses on maximizing generation quality without any regard for the interpretability of the architectures, particularly regarding the influence of particular body parts in the generation and the temporal synchronization of words with specific movements and actions. This study explores the combination of movement encoders with spatio-temporal attention models and proposes strategies to guide the attention during training to highlight perceptually pertinent areas of the skeleton in time. We show that adding guided attention with adaptive gate leads to interpretable captioning while improving performance compared to higher parameter-count non-interpretable SOTA systems. On the KIT MLD dataset, we obtain a BLEU@4 of 24.4% (SOTA+6%), a ROUGE-L of 58.30% (SOTA +14.1%), a CIDEr of 112.10 (SOTA +32.6) and a Bertscore of 41.20% (SOTA +18.20%). On HumanML3D, we obtain a BLEU@4 of 25.00 (SOTA +2.7%), a ROUGE-L score of 55.4% (SOTA +6.1%), a CIDEr of 61.6 (SOTA -10.9%), a Bertscore of 40.3% (SOTA +2.5%). Our code implementation and reproduction details will be soon available at https://github.com/rd20karim/M2T-Interpretable/tree/main.
Ontology Enrichment for Effective Fine-grained Entity Typing
Oct 11, 2023
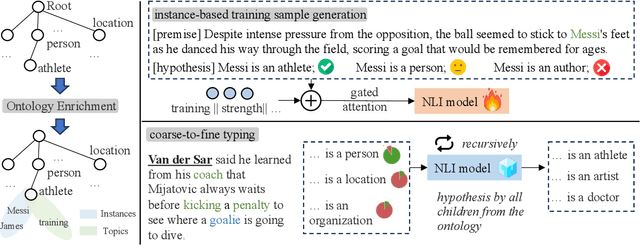
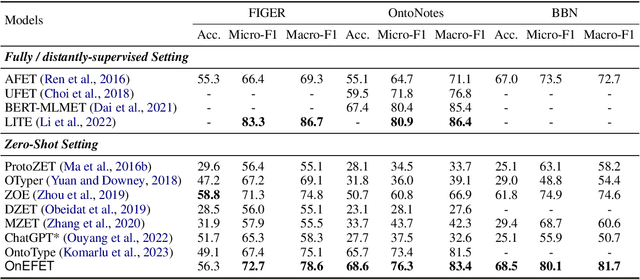
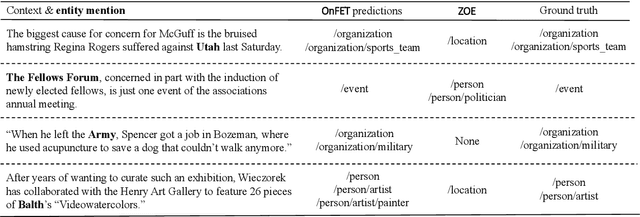
Fine-grained entity typing (FET) is the task of identifying specific entity types at a fine-grained level for entity mentions based on their contextual information. Conventional methods for FET require extensive human annotation, which is time-consuming and costly. Recent studies have been developing weakly supervised or zero-shot approaches. We study the setting of zero-shot FET where only an ontology is provided. However, most existing ontology structures lack rich supporting information and even contain ambiguous relations, making them ineffective in guiding FET. Recently developed language models, though promising in various few-shot and zero-shot NLP tasks, may face challenges in zero-shot FET due to their lack of interaction with task-specific ontology. In this study, we propose OnEFET, where we (1) enrich each node in the ontology structure with two types of extra information: instance information for training sample augmentation and topic information to relate types to contexts, and (2) develop a coarse-to-fine typing algorithm that exploits the enriched information by training an entailment model with contrasting topics and instance-based augmented training samples. Our experiments show that OnEFET achieves high-quality fine-grained entity typing without human annotation, outperforming existing zero-shot methods by a large margin and rivaling supervised methods.
Dynamic Appearance Particle Neural Radiance Field
Oct 11, 2023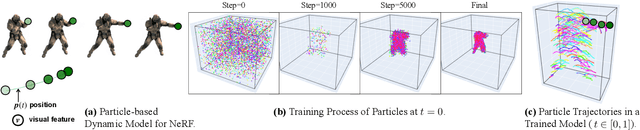
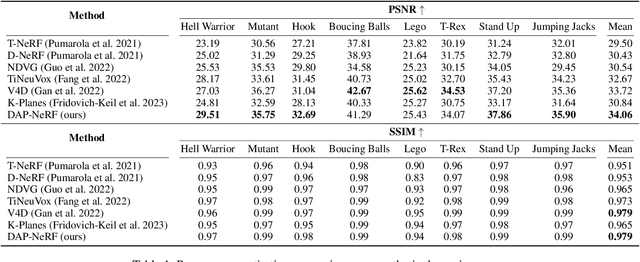
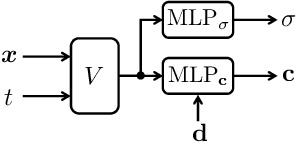
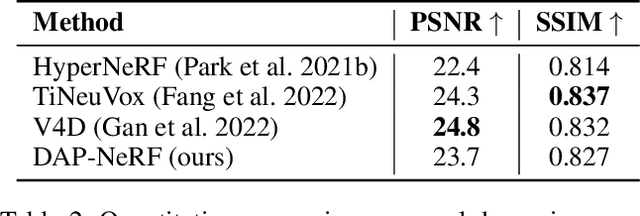
Neural Radiance Fields (NeRFs) have shown great potential in modelling 3D scenes. Dynamic NeRFs extend this model by capturing time-varying elements, typically using deformation fields. The existing dynamic NeRFs employ a similar Eulerian representation for both light radiance and deformation fields. This leads to a close coupling of appearance and motion and lacks a physical interpretation. In this work, we propose Dynamic Appearance Particle Neural Radiance Field (DAP-NeRF), which introduces particle-based representation to model the motions of visual elements in a dynamic 3D scene. DAP-NeRF consists of superposition of a static field and a dynamic field. The dynamic field is quantised as a collection of {\em appearance particles}, which carries the visual information of a small dynamic element in the scene and is equipped with a motion model. All components, including the static field, the visual features and motion models of the particles, are learned from monocular videos without any prior geometric knowledge of the scene. We develop an efficient computational framework for the particle-based model. We also construct a new dataset to evaluate motion modelling. Experimental results show that DAP-NeRF is an effective technique to capture not only the appearance but also the physically meaningful motions in a 3D dynamic scene.
Histopathological Image Classification and Vulnerability Analysis using Federated Learning
Oct 11, 2023Healthcare is one of the foremost applications of machine learning (ML). Traditionally, ML models are trained by central servers, which aggregate data from various distributed devices to forecast the results for newly generated data. This is a major concern as models can access sensitive user information, which raises privacy concerns. A federated learning (FL) approach can help address this issue: A global model sends its copy to all clients who train these copies, and the clients send the updates (weights) back to it. Over time, the global model improves and becomes more accurate. Data privacy is protected during training, as it is conducted locally on the clients' devices. However, the global model is susceptible to data poisoning. We develop a privacy-preserving FL technique for a skin cancer dataset and show that the model is prone to data poisoning attacks. Ten clients train the model, but one of them intentionally introduces flipped labels as an attack. This reduces the accuracy of the global model. As the percentage of label flipping increases, there is a noticeable decrease in accuracy. We use a stochastic gradient descent optimization algorithm to find the most optimal accuracy for the model. Although FL can protect user privacy for healthcare diagnostics, it is also vulnerable to data poisoning, which must be addressed.