 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Learning of Mesh and Appearance via 3D Gaussian Splatting
May 11, 2024



Accurately reconstructing a 3D scene including explicit geometry information is both attractive and challenging. Geometry reconstruction can benefit from incorporating differentiable appearance models, such as Neural Radiance Fields and 3D Gaussian Splatting (3DGS). In this work, we propose a learnable scene model that incorporates 3DGS with an explicit geometry representation, namely a mesh. Our model learns the mesh and appearance in an end-to-end manner, where we bind 3D Gaussians to the mesh faces and perform differentiable rendering of 3DGS to obtain photometric supervision. The model creates an effective information pathway to supervise the learning of the scene, including the mesh. Experimental results demonstrate that the learned scene model not only achieves state-of-the-art rendering quality but also supports manipulation using the explicit mesh. In addition, our model has a unique advantage in adapting to scene updates, thanks to the end-to-end learning of both mesh and appearance.
Dynamic Appearance Particle Neural Radiance Field
Oct 11, 2023



Neural Radiance Fields (NeRFs) have shown great potential in modelling 3D scenes. Dynamic NeRFs extend this model by capturing time-varying elements, typically using deformation fields. The existing dynamic NeRFs employ a similar Eulerian representation for both light radiance and deformation fields. This leads to a close coupling of appearance and motion and lacks a physical interpretation. In this work, we propose Dynamic Appearance Particle Neural Radiance Field (DAP-NeRF), which introduces particle-based representation to model the motions of visual elements in a dynamic 3D scene. DAP-NeRF consists of superposition of a static field and a dynamic field. The dynamic field is quantised as a collection of {\em appearance particles}, which carries the visual information of a small dynamic element in the scene and is equipped with a motion model. All components, including the static field, the visual features and motion models of the particles, are learned from monocular videos without any prior geometric knowledge of the scene. We develop an efficient computational framework for the particle-based model. We also construct a new dataset to evaluate motion modelling. Experimental results show that DAP-NeRF is an effective technique to capture not only the appearance but also the physically meaningful motions in a 3D dynamic scene.
Normal Transformer: Extracting Surface Geometry from LiDAR Points Enhanced by Visual Semantics
Nov 19, 2022High-quality estimation of surface normal can help reduce ambiguity in many geometry understanding problems, such as collision avoidance and occlusion inference. This paper presents a technique for estimating the normal from 3D point clouds and 2D colour images. We have developed a transformer neural network that learns to utilise the hybrid information of visual semantic and 3D geometric data, as well as effective learning strategies. Compared to existing methods, the information fusion of the proposed method is more effective, which is supported by experiments. We have also built a simulation environment of outdoor traffic scenes in a 3D rendering engine to obtain annotated data to train the normal estimator. The model trained on synthetic data is tested on the real scenes in the KITTI dataset. And subsequent tasks built upon the estimated normal directions in the KITTI dataset show that the proposed estimator has advantage over existing methods.
On Learning and Learned Representation with Dynamic Routing in Capsule Networks
Oct 08, 2018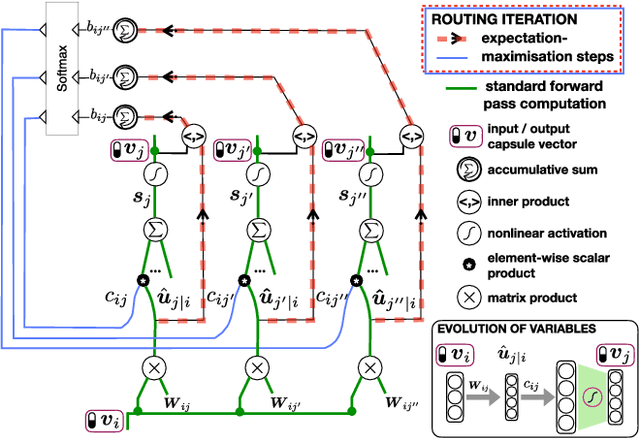


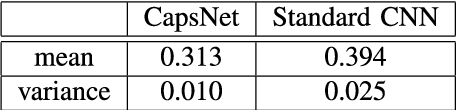
Capsule Networks (CapsNet) are recently proposed multi-stage computational models specialized for entity representation and discovery in image data. CapsNet employs iterative routing that shapes how the information cascades through different levels of interpretations. In this work, we investigate i) how the routing affects the CapsNet model fitting, ii) how the representation by capsules helps discover global structures in data distribution and iii) how learned data representation adapts and generalizes to new tasks. Our investigation shows: i) routing operation determines the certainty with which one layer of capsules pass information to the layer above, and the appropriate level of certainty is related to the model fitness, ii) in a designed experiment using data with a known 2D structure, capsule representations allow more meaningful 2D manifold embedding than neurons in a standard CNN do and iii) compared to neurons of standard CNN, capsules of successive layers are less coupled and more adaptive to new data distribution.