 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FeatSense -- A Feature-based Registration Algorithm with GPU-accelerated TSDF-Mapping Backend for NVIDIA Jetson Boards
Oct 09, 2023



This paper presents FeatSense, a feature-based GPU-accelerated SLAM system for high resolution LiDARs, combined with a map generation algorithm for real-time generation of large Truncated Signed Distance Fields (TSDFs) on embedded hardware. FeatSense uses LiDAR point cloud features for odometry estimation and point cloud registration. The registered point clouds are integrated into a global Truncated Signed Distance Field (TSDF) representation. FeatSense is intended to run on embedded systems with integrated GPU-accelerator like NVIDIA Jetson boards. In this paper, we present a real-time capable TSDF-SLAM system specially tailored for close coupled CPU/GPU systems. The implementation is evaluated in various structured and unstructured environments and benchmarked against existing reference datasets. The main contribution of this paper is the ability to register up to 128 scan lines of an Ouster OS1-128 LiDAR at 10Hz on a NVIDIA AGX Xavier while achieving a TSDF map generation speedup by a factor of 100 compared to previous work on the same power budget.
Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse Problems
Oct 18, 2023Scientific imaging problems are often severely ill-posed, and hence have significant intrinsic uncertainty. Accurately quantifying the uncertainty in the solutions to such problems is therefore critical for the rigorous interpretation of experimental results as well as for reliably using the reconstructed images as scientific evidence. Unfortunately, existing imaging methods are unable to quantify the uncertainty in the reconstructed images in a manner that is robust to experiment replications. This paper presents a new uncertainty quantification methodology based on an equivariant formulation of the parametric bootstrap algorithm that leverages symmetries and invariance properties commonly encountered in imaging problems. Additionally, the proposed methodology is general and can be easily applied with any image reconstruction technique, including unsupervised training strategies that can be trained from observed data alone, thus enabling uncertainty quantification in situations where there is no ground truth data available. We demonstrate the proposed approach with a series of numerical experiments and through comparisons with alternative uncertainty quantification strategies from the state-of-the-art, such as Bayesian strategies involving score-based diffusion models and Langevin samplers. In all our experiments, the proposed method delivers remarkably accurate high-dimensional confidence regions and outperforms the competing approaches in terms of estimation accuracy, uncertainty quantification accuracy, and computing time.
Controllable Data Generation Via Iterative Data-Property Mutual Mappings
Oct 11, 2023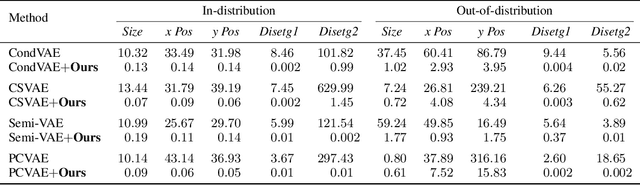
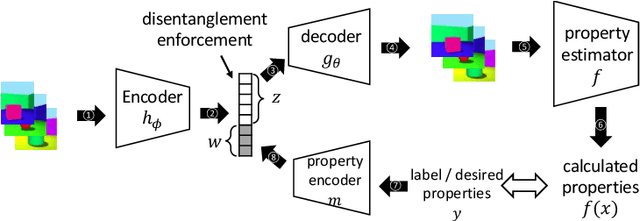
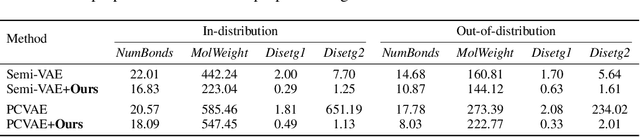
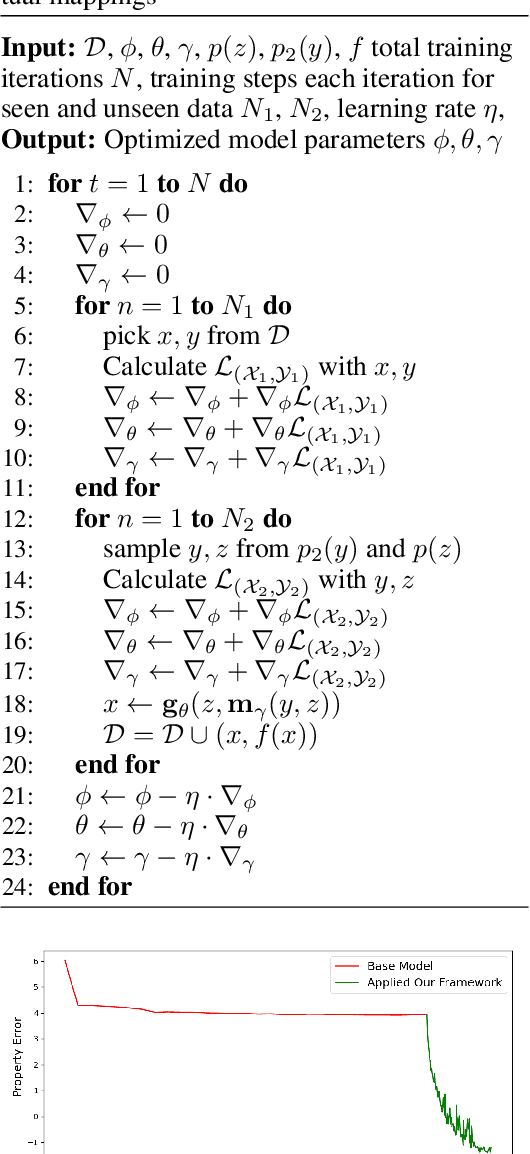
Deep generative models have been widely used for their ability to generate realistic data samples in various areas, such as images, molecules, text, and speech. One major goal of data generation is controllability, namely to generate new data with desired properties. Despite growing interest in the area of controllable generation, significant challenges still remain, including 1) disentangling desired properties with unrelated latent variables, 2) out-of-distribution property control, and 3) objective optimization for out-of-distribution property control. To address these challenges, in this paper, we propose a general framework to enhance VAE-based data generators with property controllability and ensure disentanglement. Our proposed objective can be optimized on both data seen and unseen in the training set. We propose a training procedure to train the objective in a semi-supervised manner by iteratively conducting mutual mappings between the data and properties. The proposed framework is implemented on four VAE-based controllable generators to evaluate its performance on property error, disentanglement, generation quality, and training time. The results indicate that our proposed framework enables more precise control over the properties of generated samples in a short training time, ensuring the disentanglement and keeping the validity of the generated samples.
Studying speed-accuracy trade-offs in best-of-n collective decision-making through heterogeneous mean-field modelling
Oct 20, 2023To succeed in their objectives, groups of individuals must be able to make quick and accurate collective decisions on the best among alternatives with different qualities. Group-living animals aim to do that all the time. Plants and fungi are thought to do so too. Swarms of autonomous robots can also be programmed to make best-of-n decisions for solving tasks collaboratively. Ultimately, humans critically need it and so many times they should be better at it! Despite their simplicity, mathematical tractability made models like the voter model (VM) and the local majority rule model (MR) useful to describe in simple terms such collective decision-making processes. To reach a consensus, individuals change their opinion by interacting with neighbours in their social network. At least among animals and robots, options with a better quality are exchanged more often and therefore spread faster than lower-quality options, leading to the collective selection of the best option. With our work, we study the impact of individuals making errors in pooling others' opinions caused, for example, to reduce the cognitive load. Our analysis in grounded on the introduction of a model that generalises the two existing VM and MR models, showing a speed-accuracy trade-off regulated by the cognitive effort of individuals. We also investigate the impact of the interaction network topology on the collective dynamics. To do so, we extend our model and, by using the heterogeneous mean-field approach, we show that another speed-accuracy trade-off is regulated by network connectivity. An interesting result is that reduced network connectivity corresponds to an increase in collective decision accuracy
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
Exploring Graph Neural Networks for Indian Legal Judgment Prediction
Oct 19, 2023The burdensome impact of a skewed judges-to-cases ratio on the judicial system manifests in an overwhelming backlog of pending cases alongside an ongoing influx of new ones. To tackle this issue and expedite the judicial process, the proposition of an automated system capable of suggesting case outcomes based on factual evidence and precedent from past cases gains significance. This research paper centres on developing a graph neural network-based model to address the Legal Judgment Prediction (LJP) problem, recognizing the intrinsic graph structure of judicial cases and making it a binary node classification problem. We explored various embeddings as model features, while nodes such as time nodes and judicial acts were added and pruned to evaluate the model's performance. The study is done while considering the ethical dimension of fairness in these predictions, considering gender and name biases. A link prediction task is also conducted to assess the model's proficiency in anticipating connections between two specified nodes. By harnessing the capabilities of graph neural networks and incorporating fairness analyses, this research aims to contribute insights towards streamlining the adjudication process, enhancing judicial efficiency, and fostering a more equitable legal landscape, ultimately alleviating the strain imposed by mounting case backlogs. Our best-performing model with XLNet pre-trained embeddings as its features gives the macro F1 score of 75% for the LJP task. For link prediction, the same set of features is the best performing giving ROC of more than 80%
Variational Inference for SDEs Driven by Fractional Noise
Oct 19, 2023We present a novel variational framework for performing inference in (neural) stochastic differential equations (SDEs) driven by Markov-approximate fractional Brownian motion (fBM). SDEs offer a versatile tool for modeling real-world continuous-time dynamic systems with inherent noise and randomness. Combining SDEs with the powerful inference capabilities of variational methods, enables the learning of representative function distributions through stochastic gradient descent. However, conventional SDEs typically assume the underlying noise to follow a Brownian motion (BM), which hinders their ability to capture long-term dependencies. In contrast, fractional Brownian motion (fBM) extends BM to encompass non-Markovian dynamics, but existing methods for inferring fBM parameters are either computationally demanding or statistically inefficient. In this paper, building upon the Markov approximation of fBM, we derive the evidence lower bound essential for efficient variational inference of posterior path measures, drawing from the well-established field of stochastic analysis. Additionally, we provide a closed-form expression to determine optimal approximation coefficients. Furthermore, we propose the use of neural networks to learn the drift, diffusion and control terms within our variational posterior, leading to the variational training of neural-SDEs. In this framework, we also optimize the Hurst index, governing the nature of our fractional noise. Beyond validation on synthetic data, we contribute a novel architecture for variational latent video prediction,-an approach that, to the best of our knowledge, enables the first variational neural-SDE application to video perception.
Flexible Handover with Real-Time Robust Dynamic Grasp Trajectory Generation
Aug 29, 2023
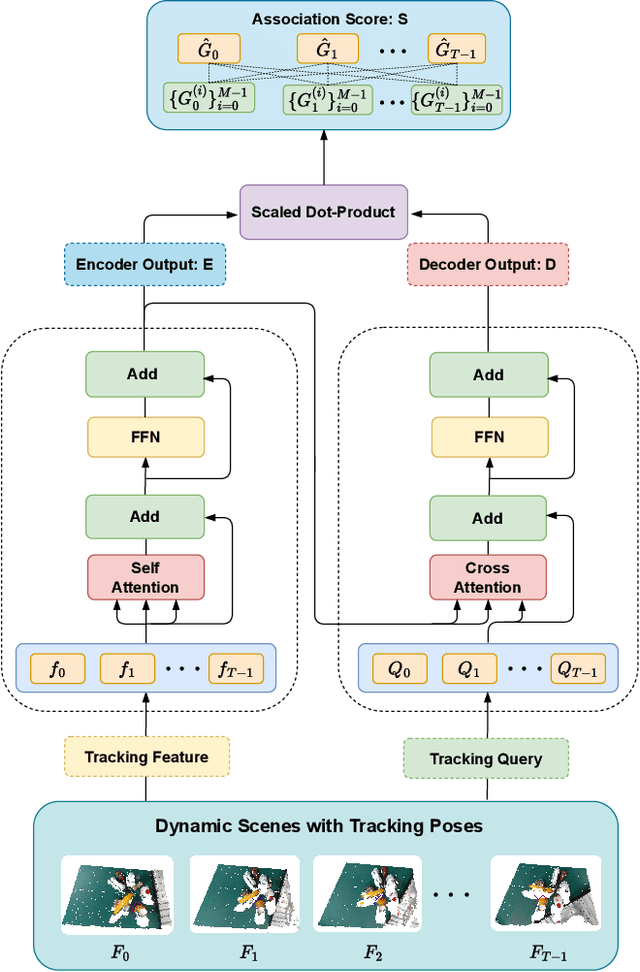
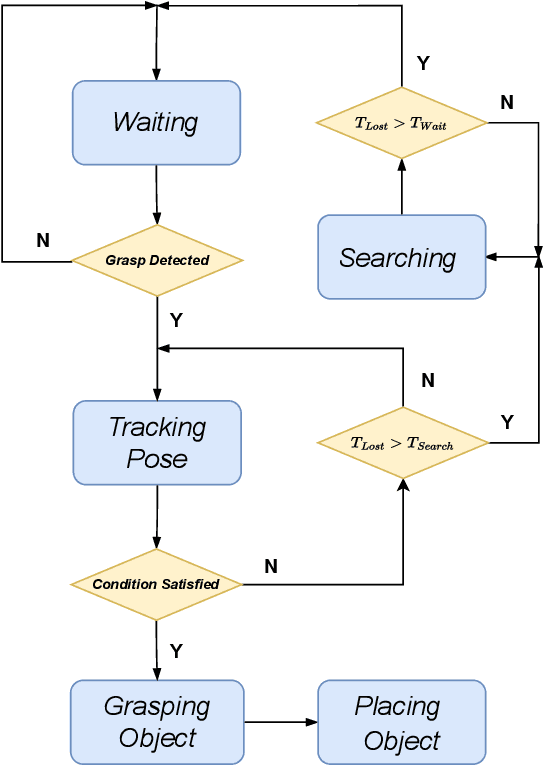

In recent years, there has been a significant effort dedicated to developing efficient, robust, and general human-to-robot handover systems. However, the area of flexible handover in the context of complex and continuous objects' motion remains relatively unexplored. In this work, we propose an approach for effective and robust flexible handover, which enables the robot to grasp moving objects with flexible motion trajectories with a high success rate. The key innovation of our approach is the generation of real-time robust grasp trajectories. We also design a future grasp prediction algorithm to enhance the system's adaptability to dynamic handover scenes. We conduct one-motion handover experiments and motion-continuous handover experiments on our novel benchmark that includes 31 diverse household objects. The system we have developed allows users to move and rotate objects in their hands within a relatively large range. The success rate of the robot grasping such moving objects is 78.15% over the entire household object benchmark.
HiCL: Hierarchical Contrastive Learning of Unsupervised Sentence Embeddings
Oct 15, 2023In this paper, we propose a hierarchical contrastive learning framework, HiCL, which considers local segment-level and global sequence-level relationships to improve training efficiency and effectiveness. Traditional methods typically encode a sequence in its entirety for contrast with others, often neglecting local representation learning, leading to challenges in generalizing to shorter texts. Conversely, HiCL improves its effectiveness by dividing the sequence into several segments and employing both local and global contrastive learning to model segment-level and sequence-level relationships. Further, considering the quadratic time complexity of transformers over input tokens, HiCL boosts training efficiency by first encoding short segments and then aggregating them to obtain the sequence representation. Extensive experiments show that HiCL enhances the prior top-performing SNCSE model across seven extensively evaluated STS tasks, with an average increase of +0.2% observed on BERT-large and +0.44% on RoBERTa-large.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023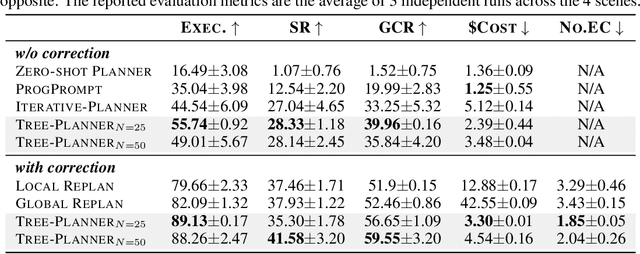
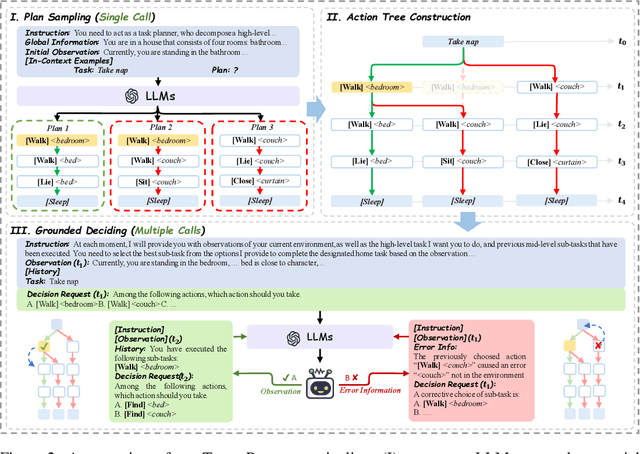
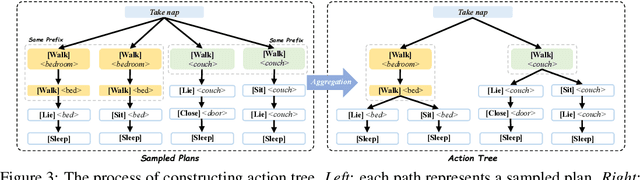

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/