 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Contextual Congruence Across Modalities for Effective Multimodal Marketing using Knowledge-infused Learning
Feb 06, 2024The prevalence of smart devices with the ability to capture moments in multiple modalities has enabled users to experience multimodal information online. However, large Language (LLMs) and Vision models (LVMs) are still limited in capturing holistic meaning with cross-modal semantic relationships. Without explicit, common sense knowledge (e.g., as a knowledge graph), Visual Language Models (VLMs) only learn implicit representations by capturing high-level patterns in vast corpora, missing essential contextual cross-modal cues. In this work, we design a framework to couple explicit commonsense knowledge in the form of knowledge graphs with large VLMs to improve the performance of a downstream task, predicting the effectiveness of multi-modal marketing campaigns. While the marketing application provides a compelling metric for assessing our methods, our approach enables the early detection of likely persuasive multi-modal campaigns and the assessment and augmentation of marketing theory.
CABINET: Content Relevance based Noise Reduction for Table Question Answering
Feb 05, 2024



Table understanding capability of Large Language Models (LLMs) has been extensively studied through the task of question-answering (QA) over tables. Typically, only a small part of the whole table is relevant to derive the answer for a given question. The irrelevant parts act as noise and are distracting information, resulting in sub-optimal performance due to the vulnerability of LLMs to noise. To mitigate this, we propose CABINET (Content RelevAnce-Based NoIse ReductioN for TablE QuesTion-Answering) - a framework to enable LLMs to focus on relevant tabular data by suppressing extraneous information. CABINET comprises an Unsupervised Relevance Scorer (URS), trained differentially with the QA LLM, that weighs the table content based on its relevance to the input question before feeding it to the question-answering LLM (QA LLM). To further aid the relevance scorer, CABINET employs a weakly supervised module that generates a parsing statement describing the criteria of rows and columns relevant to the question and highlights the content of corresponding table cells. CABINET significantly outperforms various tabular LLM baselines, as well as GPT3-based in-context learning methods, is more robust to noise, maintains outperformance on tables of varying sizes, and establishes new SoTA performance on WikiTQ, FeTaQA, and WikiSQL datasets. We release our code and datasets at https://github.com/Sohanpatnaik106/CABINET_QA.
Exploring Graph Neural Networks for Indian Legal Judgment Prediction
Oct 19, 2023



The burdensome impact of a skewed judges-to-cases ratio on the judicial system manifests in an overwhelming backlog of pending cases alongside an ongoing influx of new ones. To tackle this issue and expedite the judicial process, the proposition of an automated system capable of suggesting case outcomes based on factual evidence and precedent from past cases gains significance. This research paper centres on developing a graph neural network-based model to address the Legal Judgment Prediction (LJP) problem, recognizing the intrinsic graph structure of judicial cases and making it a binary node classification problem. We explored various embeddings as model features, while nodes such as time nodes and judicial acts were added and pruned to evaluate the model's performance. The study is done while considering the ethical dimension of fairness in these predictions, considering gender and name biases. A link prediction task is also conducted to assess the model's proficiency in anticipating connections between two specified nodes. By harnessing the capabilities of graph neural networks and incorporating fairness analyses, this research aims to contribute insights towards streamlining the adjudication process, enhancing judicial efficiency, and fostering a more equitable legal landscape, ultimately alleviating the strain imposed by mounting case backlogs. Our best-performing model with XLNet pre-trained embeddings as its features gives the macro F1 score of 75% for the LJP task. For link prediction, the same set of features is the best performing giving ROC of more than 80%
CiteCaseLAW: Citation Worthiness Detection in Caselaw for Legal Assistive Writing
May 03, 2023



In legal document writing, one of the key elements is properly citing the case laws and other sources to substantiate claims and arguments. Understanding the legal domain and identifying appropriate citation context or cite-worthy sentences are challenging tasks that demand expensive manual annotation. The presence of jargon, language semantics, and high domain specificity makes legal language complex, making any associated legal task hard for automation. The current work focuses on the problem of citation-worthiness identification. It is designed as the initial step in today's citation recommendation systems to lighten the burden of extracting an adequate set of citation contexts. To accomplish this, we introduce a labeled dataset of 178M sentences for citation-worthiness detection in the legal domain from the Caselaw Access Project (CAP). The performance of various deep learning models was examined on this novel dataset. The domain-specific pre-trained model tends to outperform other models, with an 88% F1-score for the citation-worthiness detection task.
H-AES: Towards Automated Essay Scoring for Hindi
Feb 28, 2023


The use of Natural Language Processing (NLP) for Automated Essay Scoring (AES) has been well explored in the English language, with benchmark models exhibiting performance comparable to human scorers. However, AES in Hindi and other low-resource languages remains unexplored. In this study, we reproduce and compare state-of-the-art methods for AES in the Hindi domain. We employ classical feature-based Machine Learning (ML) and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture, in our approach and derive results comparable to those in the English language domain. Hindi being a low-resource language, lacks a dedicated essay-scoring corpus. We train and evaluate our models using translated English essays and empirically measure their performance on our own small-scale, real-world Hindi corpus. We follow this up with an in-depth analysis discussing prompt-specific behavior of different language models implemented.
Get It Scored Using AutoSAS -- An Automated System for Scoring Short Answers
Dec 21, 2020
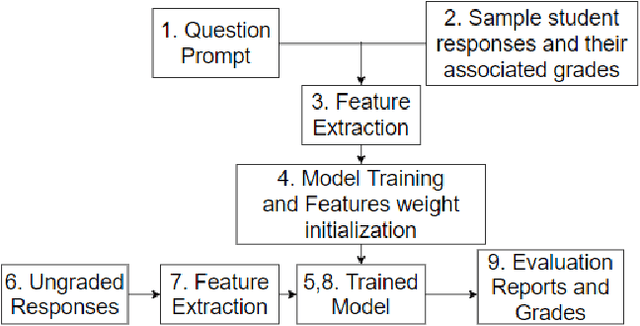


In the era of MOOCs, online exams are taken by millions of candidates, where scoring short answers is an integral part. It becomes intractable to evaluate them by human graders. Thus, a generic automated system capable of grading these responses should be designed and deployed. In this paper, we present a fast, scalable, and accurate approach towards automated Short Answer Scoring (SAS). We propose and explain the design and development of a system for SAS, namely AutoSAS. Given a question along with its graded samples, AutoSAS can learn to grade that prompt successfully. This paper further lays down the features such as lexical diversity, Word2Vec, prompt, and content overlap that plays a pivotal role in building our proposed model. We also present a methodology for indicating the factors responsible for scoring an answer. The trained model is evaluated on an extensively used public dataset, namely Automated Student Assessment Prize Short Answer Scoring (ASAP-SAS). AutoSAS shows state-of-the-art performance and achieves better results by over 8% in some of the question prompts as measured by Quadratic Weighted Kappa (QWK), showing performance comparable to humans.
LIFI: Towards Linguistically Informed Frame Interpolation
Nov 11, 2020
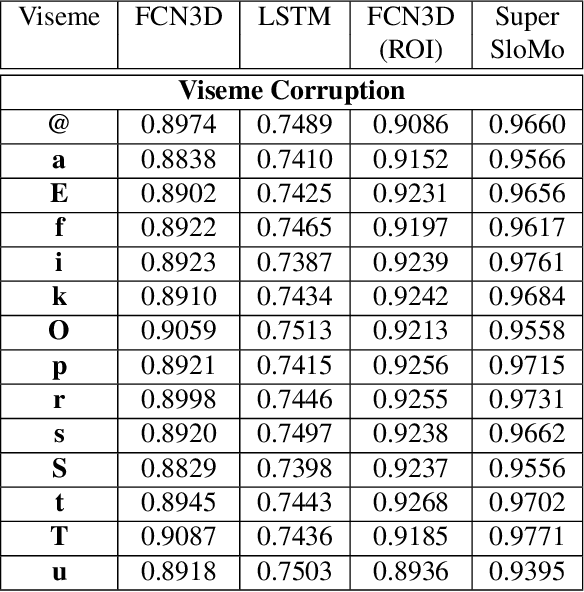
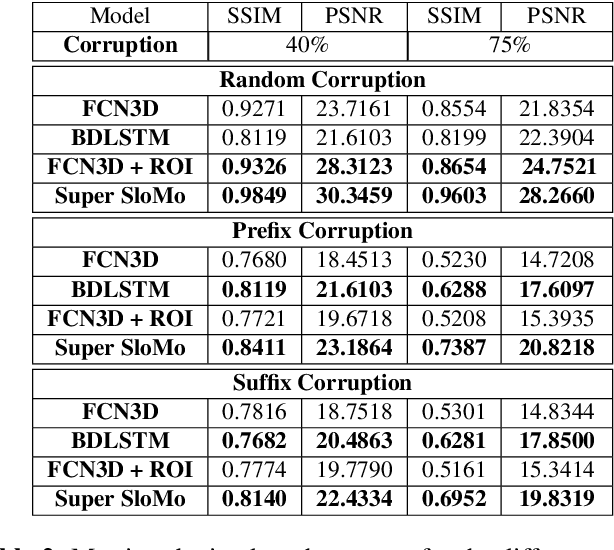

In this work, we explore a new problem of frame interpolation for speech videos. Such content today forms the major form of online communication. We try to solve this problem by using several deep learning video generation algorithms to generate the missing frames. We also provide examples where computer vision models despite showing high performance on conventional non-linguistic metrics fail to accurately produce faithful interpolation of speech. With this motivation, we provide a new set of linguistically-informed metrics specifically targeted to the problem of speech videos interpolation. We also release several datasets to test computer vision video generation models of their speech understanding.
Calling Out Bluff: Attacking the Robustness of Automatic Scoring Systems with Simple Adversarial Testing
Jul 14, 2020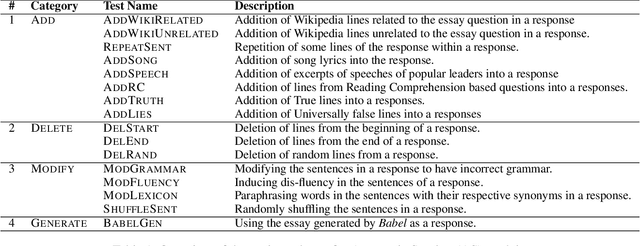
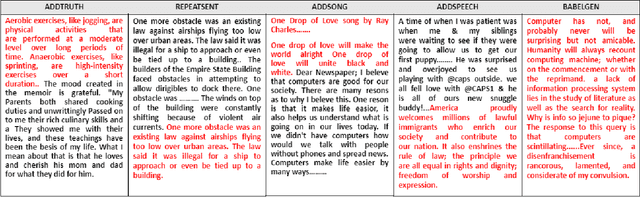

A significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. The performance commonly measured by the standard performance metrics like Quadratic Weighted Kappa (QWK), and accuracy points to the same. However, testing on common-sense adversarial examples of these AES systems reveal their lack of natural language understanding capability. Inspired by common student behaviour during examinations, we propose a task agnostic adversarial evaluation scheme for AES systems to test their natural language understanding capabilities and overall robustness.
"Notic My Speech" -- Blending Speech Patterns With Multimedia
Jun 12, 2020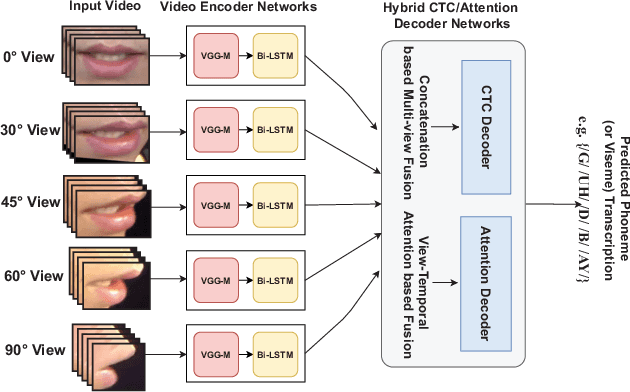
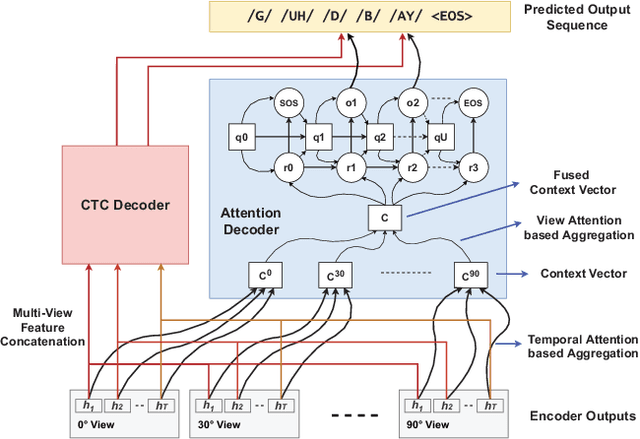
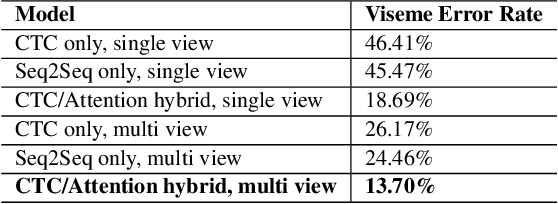
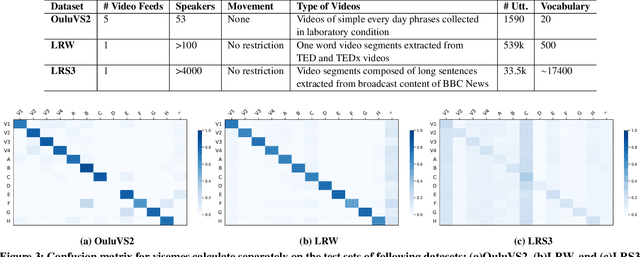
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.
audino: A Modern Annotation Tool for Audio and Speech
Jun 09, 2020
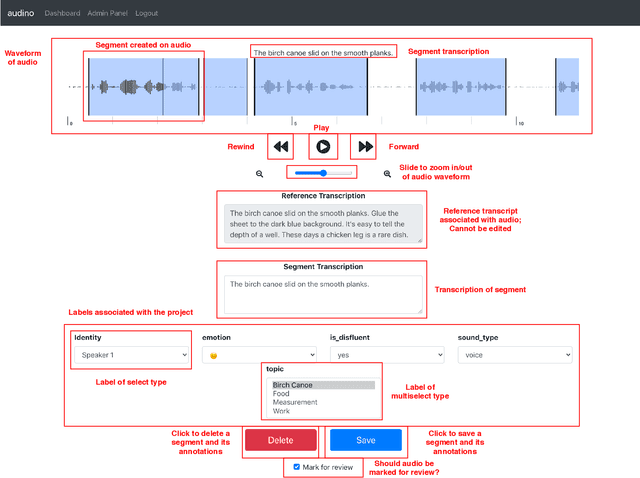
In this paper, we introduce a collaborative and modern annotation tool for audio and speech: audino. The tool allows annotators to define and describe temporal segmentation in audios. These segments can be labelled and transcribed easily using a dynamically generated form. An admin can centrally control user roles and project assignment through the admin dashboard. The dashboard also enables describing labels and their values. The annotations can easily be exported in JSON format for further processing. The tool allows audio data to be uploaded and assigned to a user through a key-based API. The flexibility available in the annotation tool enables annotation for Speech Scoring, Voice Activity Detection (VAD), Speaker Diarisation, Speaker Identification, Speech Recognition, Emotion Recognition tasks and more. The MIT open source license allows it to be used for academic and commercial projects.