 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text": models, code, and papers
Soulstyler: Using Large Language Model to Guide Image Style Transfer for Target Object
Nov 29, 2023
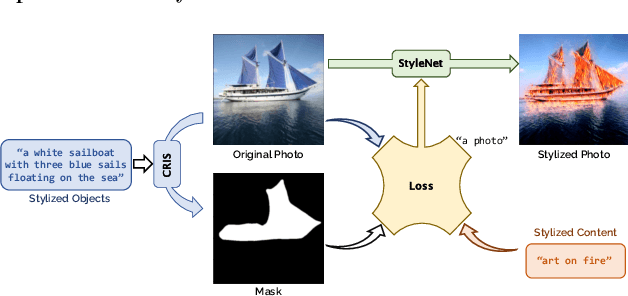
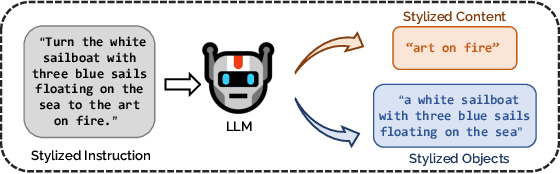
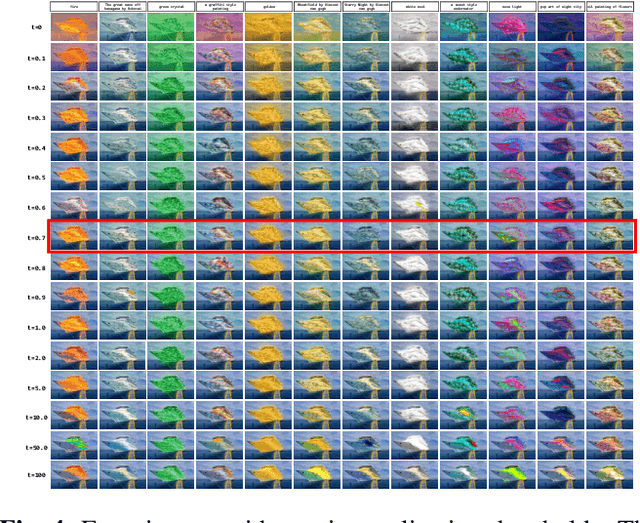
Image style transfer occupies an important place in both computer graphics and computer vision. However, most current methods require reference to stylized images and cannot individually stylize specific objects. To overcome this limitation, we propose the "Soulstyler" framework, which allows users to guide the stylization of specific objects in an image through simple textual descriptions. We introduce a large language model to parse the text and identify stylization goals and specific styles. Combined with a CLIP-based semantic visual embedding encoder, the model understands and matches text and image content. We also introduce a novel localized text-image block matching loss that ensures that style transfer is performed only on specified target objects, while non-target regions remain in their original style. Experimental results demonstrate that our model is able to accurately perform style transfer on target objects according to textual descriptions without affecting the style of background regions. Our code will be available at https://github.com/yisuanwang/Soulstyler.
Unsupervised Keypoints from Pretrained Diffusion Models
Nov 29, 2023Unsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple datasets: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. Our code is publicly available and can be found through our project page: https://ubc-vision.github.io/StableKeypoints/
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Nov 26, 2023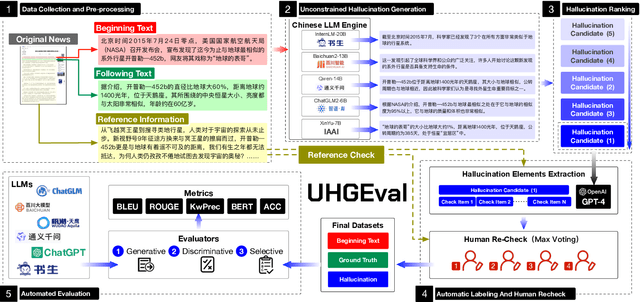
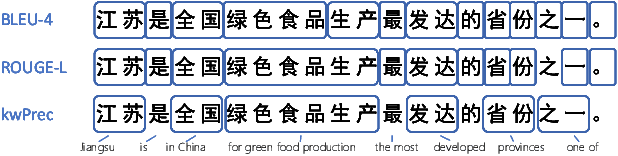

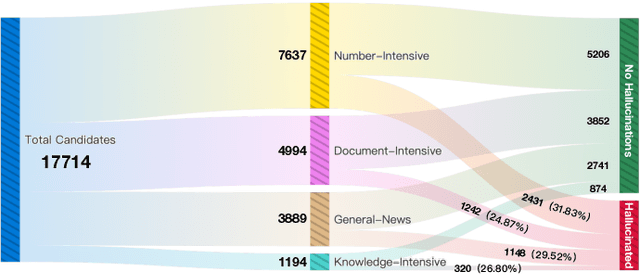
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
PEEKABOO: Interactive Video Generation via Masked-Diffusion
Dec 12, 2023Recently there has been a lot of progress in text-to-video generation, with state-of-the-art models being capable of generating high quality, realistic videos. However, these models lack the capability for users to interactively control and generate videos, which can potentially unlock new areas of application. As a first step towards this goal, we tackle the problem of endowing diffusion-based video generation models with interactive spatio-temporal control over their output. To this end, we take inspiration from the recent advances in segmentation literature to propose a novel spatio-temporal masked attention module - Peekaboo. This module is a training-free, no-inference-overhead addition to off-the-shelf video generation models which enables spatio-temporal control. We also propose an evaluation benchmark for the interactive video generation task. Through extensive qualitative and quantitative evaluation, we establish that Peekaboo enables control video generation and even obtains a gain of upto 3.8x in mIoU over baseline models.
Photorealistic Video Generation with Diffusion Models
Dec 11, 2023We present W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. Our approach has two key design decisions. First, we use a causal encoder to jointly compress images and videos within a unified latent space, enabling training and generation across modalities. Second, for memory and training efficiency, we use a window attention architecture tailored for joint spatial and spatiotemporal generative modeling. Taken together these design decisions enable us to achieve state-of-the-art performance on established video (UCF-101 and Kinetics-600) and image (ImageNet) generation benchmarks without using classifier free guidance. Finally, we also train a cascade of three models for the task of text-to-video generation consisting of a base latent video diffusion model, and two video super-resolution diffusion models to generate videos of $512 \times 896$ resolution at $8$ frames per second.
Humans and language models diverge when predicting repeating text
Oct 23, 2023Language models that are trained on the next-word prediction task have been shown to accurately model human behavior in word prediction and reading speed. In contrast with these findings, we present a scenario in which the performance of humans and LMs diverges. We collected a dataset of human next-word predictions for five stimuli that are formed by repeating spans of text. Human and GPT-2 LM predictions are strongly aligned in the first presentation of a text span, but their performance quickly diverges when memory (or in-context learning) begins to play a role. We traced the cause of this divergence to specific attention heads in a middle layer. Adding a power-law recency bias to these attention heads yielded a model that performs much more similarly to humans. We hope that this scenario will spur future work in bringing LMs closer to human behavior.
Few-Shot Learning from Augmented Label-Uncertain Queries in Bongard-HOI
Dec 17, 2023Detecting human-object interactions (HOI) in a few-shot setting remains a challenge. Existing meta-learning methods struggle to extract representative features for classification due to the limited data, while existing few-shot HOI models rely on HOI text labels for classification. Moreover, some query images may display visual similarity to those outside their class, such as similar backgrounds between different HOI classes. This makes learning more challenging, especially with limited samples. Bongard-HOI (Jiang et al. 2022) epitomizes this HOI few-shot problem, making it the benchmark we focus on in this paper. In our proposed method, we introduce novel label-uncertain query augmentation techniques to enhance the diversity of the query inputs, aiming to distinguish the positive HOI class from the negative ones. As these augmented inputs may or may not have the same class label as the original inputs, their class label is unknown. Those belonging to a different class become hard samples due to their visual similarity to the original ones. Additionally, we introduce a novel pseudo-label generation technique that enables a mean teacher model to learn from the augmented label-uncertain inputs. We propose to augment the negative support set for the student model to enrich the semantic information, fostering diversity that challenges and enhances the student's learning. Experimental results demonstrate that our method sets a new state-of-the-art (SOTA) performance by achieving 68.74% accuracy on the Bongard-HOI benchmark, a significant improvement over the existing SOTA of 66.59%. In our evaluation on HICO-FS, a more general few-shot recognition dataset, our method achieves 73.27% accuracy, outperforming the previous SOTA of 71.20% in the 5-way 5-shot task.
A Novel Energy based Model Mechanism for Multi-modal Aspect-Based Sentiment Analysis
Dec 15, 2023
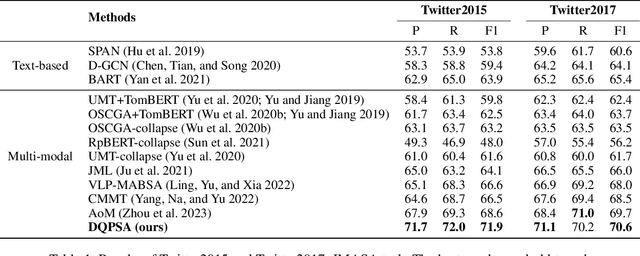
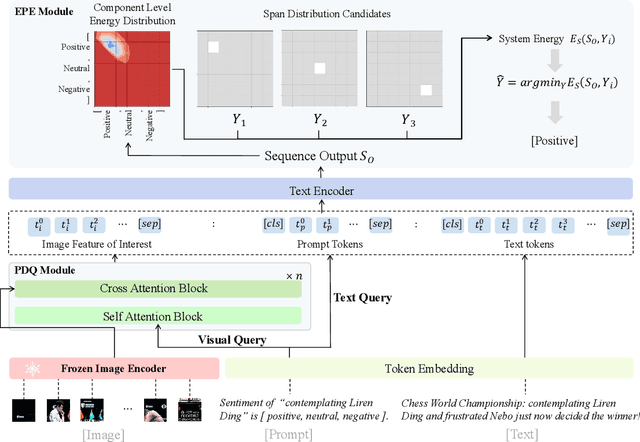
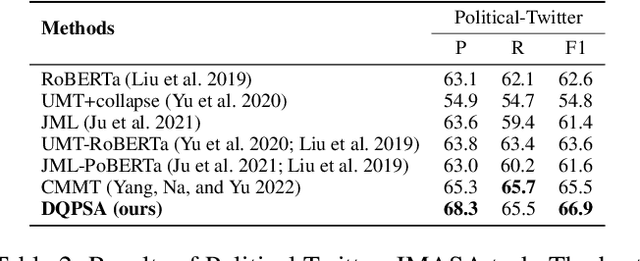
Multi-modal aspect-based sentiment analysis (MABSA) has recently attracted increasing attention. The span-based extraction methods, such as FSUIE, demonstrate strong performance in sentiment analysis due to their joint modeling of input sequences and target labels. However, previous methods still have certain limitations: (i) They ignore the difference in the focus of visual information between different analysis targets (aspect or sentiment). (ii) Combining features from uni-modal encoders directly may not be sufficient to eliminate the modal gap and can cause difficulties in capturing the image-text pairwise relevance. (iii) Existing span-based methods for MABSA ignore the pairwise relevance of target span boundaries. To tackle these limitations, we propose a novel framework called DQPSA for multi-modal sentiment analysis. Specifically, our model contains a Prompt as Dual Query (PDQ) module that uses the prompt as both a visual query and a language query to extract prompt-aware visual information and strengthen the pairwise relevance between visual information and the analysis target. Additionally, we introduce an Energy-based Pairwise Expert (EPE) module that models the boundaries pairing of the analysis target from the perspective of an Energy-based Model. This expert predicts aspect or sentiment span based on pairwise stability. Experiments on three widely used benchmarks demonstrate that DQPSA outperforms previous approaches and achieves a new state-of-the-art performance.
Automated Evaluation of Personalized Text Generation using Large Language Models
Oct 17, 2023Personalized text generation presents a specialized mechanism for delivering content that is specific to a user's personal context. While the research progress in this area has been rapid, evaluation still presents a challenge. Traditional automated metrics such as BLEU and ROUGE primarily measure lexical similarity to human-written references, and are not able to distinguish personalization from other subtle semantic aspects, thus falling short of capturing the nuances of personalized generated content quality. On the other hand, human judgments are costly to obtain, especially in the realm of personalized evaluation. Inspired by these challenges, we explore the use of large language models (LLMs) for evaluating personalized text generation, and examine their ability to understand nuanced user context. We present AuPEL, a novel evaluation method that distills three major semantic aspects of the generated text: personalization, quality and relevance, and automatically measures these aspects. To validate the effectiveness of AuPEL, we design carefully controlled experiments and compare the accuracy of the evaluation judgments made by LLMs versus that of judgements made by human annotators, and conduct rigorous analyses of the consistency and sensitivity of the proposed metric. We find that, compared to existing evaluation metrics, AuPEL not only distinguishes and ranks models based on their personalization abilities more accurately, but also presents commendable consistency and efficiency for this task. Our work suggests that using LLMs as the evaluators of personalized text generation is superior to traditional text similarity metrics, even though interesting new challenges still remain.
MedXChat: Bridging CXR Modalities with a Unified Multimodal Large Model
Dec 04, 2023Despite the success of Large Language Models (LLMs) in general image tasks, a gap persists in the medical field for a multimodal large model adept at handling the nuanced diversity of medical images. Addressing this, we propose MedXChat, a unified multimodal large model designed for seamless interactions between medical assistants and users. MedXChat encompasses three key functionalities: CXR(Chest X-ray)-to-Report generation, CXR-based visual question-answering (VQA), and Text-to-CXR synthesis. Our contributions are as follows. Firstly, our model showcases exceptional cross-task adaptability, displaying adeptness across all three defined tasks and outperforming the benchmark models on the MIMIC dataset in medical multimodal applications. Secondly, we introduce an innovative Text-to-CXR synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Comprehensive experiments validate MedXChat's synergistic enhancement across all tasks. Our instruction data and model will be open-sourced.