 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning language encoding models on slow fMRI improves prediction for fast ECoG
May 19, 2026Neuroscientists have recently turned to intracranial brain recording methods, like electrocorticography (ECoG), for human experiments because of the fine spatial and temporal resolution that they afford. Models trained on this data, however, are fundamentally restricted by the patient populations that can receive the implants necessary for recording. We propose using non-invasive fMRI to bridge the gap in training data. Using spoken language representations fine-tuned on fMRI, we build encoding models of ECoG. These representations showed improved prediction performance in ECoG, even though the temporal resolution of fMRI is two orders of magnitude worse. Prediction improved in frequency bands well beyond what is directly measured in fMRI. Next, to test the procedure's generalization ability, we fine-tuned models on fMRI responses that were temporally downsampled by a factor of 2. Despite the loss in resolution, these models were able to predict fMRI and ECoG responses at levels comparable to the original fMRI-tuned models. Finally, we showed that ECoG performance steadily scales with the amount of fMRI-tuning data. Our results show that "slow" data like fMRI can be a valuable resource for building better models of "fast" brain data like ECoG. In the future, integrating across multiple recording methods may further improve performance in other applications, like decoding.
BrainWavLM: Fine-tuning Speech Representations with Brain Responses to Language
Feb 13, 2025



Speech encoding models use auditory representations to predict how the human brain responds to spoken language stimuli. Most performant encoding models linearly map the hidden states of artificial neural networks to brain data, but this linear restriction may limit their effectiveness. In this work, we use low-rank adaptation (LoRA) to fine-tune a WavLM-based encoding model end-to-end on a brain encoding objective, producing a model we name BrainWavLM. We show that fine-tuning across all of cortex improves average encoding performance with greater stability than without LoRA. This improvement comes at the expense of low-level regions like auditory cortex (AC), but selectively fine-tuning on these areas improves performance in AC, while largely retaining gains made in the rest of cortex. Fine-tuned models generalized across subjects, indicating that they learned robust brain-like representations of the speech stimuli. Finally, by training linear probes, we showed that the brain data strengthened semantic representations in the speech model without any explicit annotations. Our results demonstrate that brain fine-tuning produces best-in-class speech encoding models, and that non-linear methods have the potential to bridge the gap between artificial and biological representations of semantics.
Crafting Interpretable Embeddings by Asking LLMs Questions
May 26, 2024Large language models (LLMs) have rapidly improved text embeddings for a growing array of natural-language processing tasks. However, their opaqueness and proliferation into scientific domains such as neuroscience have created a growing need for interpretability. Here, we ask whether we can obtain interpretable embeddings through LLM prompting. We introduce question-answering embeddings (QA-Emb), embeddings where each feature represents an answer to a yes/no question asked to an LLM. Training QA-Emb reduces to selecting a set of underlying questions rather than learning model weights. We use QA-Emb to flexibly generate interpretable models for predicting fMRI voxel responses to language stimuli. QA-Emb significantly outperforms an established interpretable baseline, and does so while requiring very few questions. This paves the way towards building flexible feature spaces that can concretize and evaluate our understanding of semantic brain representations. We additionally find that QA-Emb can be effectively approximated with an efficient model, and we explore broader applications in simple NLP tasks.
Humans and language models diverge when predicting repeating text
Oct 23, 2023Language models that are trained on the next-word prediction task have been shown to accurately model human behavior in word prediction and reading speed. In contrast with these findings, we present a scenario in which the performance of humans and LMs diverges. We collected a dataset of human next-word predictions for five stimuli that are formed by repeating spans of text. Human and GPT-2 LM predictions are strongly aligned in the first presentation of a text span, but their performance quickly diverges when memory (or in-context learning) begins to play a role. We traced the cause of this divergence to specific attention heads in a middle layer. Adding a power-law recency bias to these attention heads yielded a model that performs much more similarly to humans. We hope that this scenario will spur future work in bringing LMs closer to human behavior.
Scaling laws for language encoding models in fMRI
May 22, 2023Representations from transformer-based unidirectional language models are known to be effective at predicting brain responses to natural language. However, most studies comparing language models to brains have used GPT-2 or similarly sized language models. Here we tested whether larger open-source models such as those from the OPT and LLaMA families are better at predicting brain responses recorded using fMRI. Mirroring scaling results from other contexts, we found that brain prediction performance scales log-linearly with model size from 125M to 30B parameter models, with ~15% increased encoding performance as measured by correlation with a held-out test set across 3 subjects. Similar log-linear behavior was observed when scaling the size of the fMRI training set. We also characterized scaling for acoustic encoding models that use HuBERT, WavLM, and Whisper, and we found comparable improvements with model size. A noise ceiling analysis of these large, high-performance encoding models showed that performance is nearing the theoretical maximum for brain areas such as the precuneus and higher auditory cortex. These results suggest that increasing scale in both models and data will yield incredibly effective models of language processing in the brain, enabling better scientific understanding as well as applications such as decoding.
Brain encoding models based on multimodal transformers can transfer across language and vision
May 20, 2023



Encoding models have been used to assess how the human brain represents concepts in language and vision. While language and vision rely on similar concept representations, current encoding models are typically trained and tested on brain responses to each modality in isolation. Recent advances in multimodal pretraining have produced transformers that can extract aligned representations of concepts in language and vision. In this work, we used representations from multimodal transformers to train encoding models that can transfer across fMRI responses to stories and movies. We found that encoding models trained on brain responses to one modality can successfully predict brain responses to the other modality, particularly in cortical regions that represent conceptual meaning. Further analysis of these encoding models revealed shared semantic dimensions that underlie concept representations in language and vision. Comparing encoding models trained using representations from multimodal and unimodal transformers, we found that multimodal transformers learn more aligned representations of concepts in language and vision. Our results demonstrate how multimodal transformers can provide insights into the brain's capacity for multimodal processing.
Explaining black box text modules in natural language with language models
May 17, 2023



Large language models (LLMs) have demonstrated remarkable prediction performance for a growing array of tasks. However, their rapid proliferation and increasing opaqueness have created a growing need for interpretability. Here, we ask whether we can automatically obtain natural language explanations for black box text modules. A "text module" is any function that maps text to a scalar continuous value, such as a submodule within an LLM or a fitted model of a brain region. "Black box" indicates that we only have access to the module's inputs/outputs. We introduce Summarize and Score (SASC), a method that takes in a text module and returns a natural language explanation of the module's selectivity along with a score for how reliable the explanation is. We study SASC in 3 contexts. First, we evaluate SASC on synthetic modules and find that it often recovers ground truth explanations. Second, we use SASC to explain modules found within a pre-trained BERT model, enabling inspection of the model's internals. Finally, we show that SASC can generate explanations for the response of individual fMRI voxels to language stimuli, with potential applications to fine-grained brain mapping. All code for using SASC and reproducing results is made available on Github.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

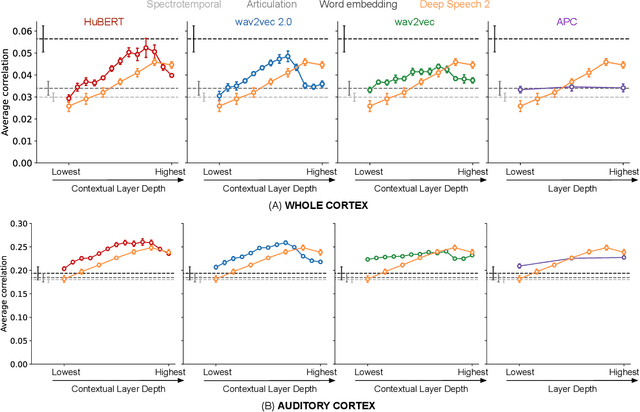
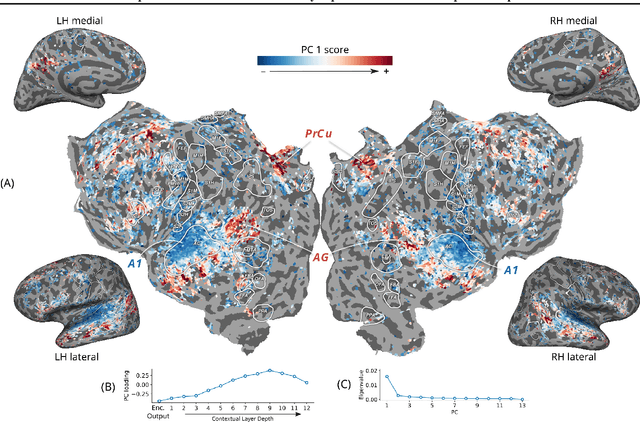
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
Physically Plausible Pose Refinement using Fully Differentiable Forces
May 17, 2021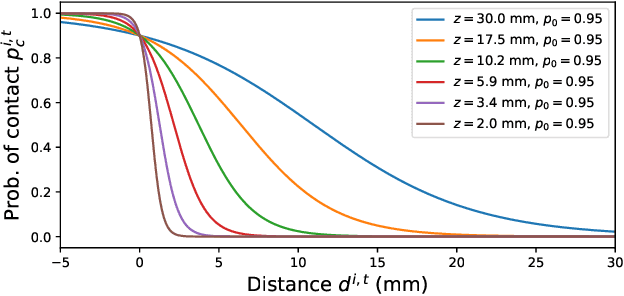
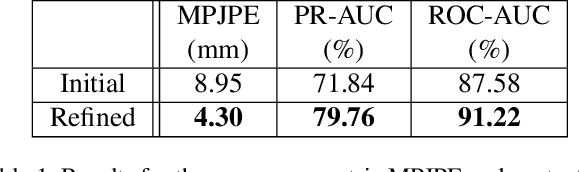
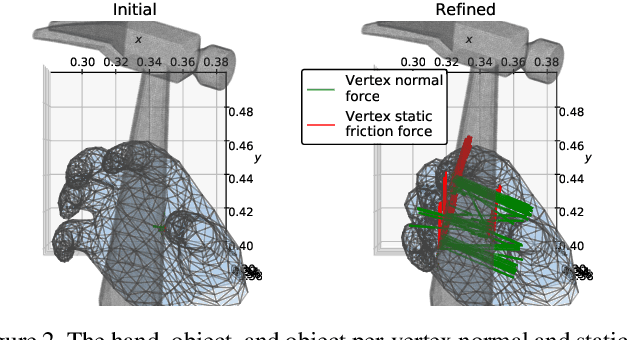
All hand-object interaction is controlled by forces that the two bodies exert on each other, but little work has been done in modeling these underlying forces when doing pose and contact estimation from RGB/RGB-D data. Given the pose of the hand and object from any pose estimation system, we propose an end-to-end differentiable model that refines pose estimates by learning the forces experienced by the object at each vertex in its mesh. By matching the learned net force to an estimate of net force based on finite differences of position, this model is able to find forces that accurately describe the movement of the object, while resolving issues like mesh interpenetration and lack of contact. Evaluating on the ContactPose dataset, we show this model successfully corrects poses and finds contact maps that better match the ground truth, despite not using any RGB or depth image data.
Multi-timescale representation learning in LSTM Language Models
Sep 27, 2020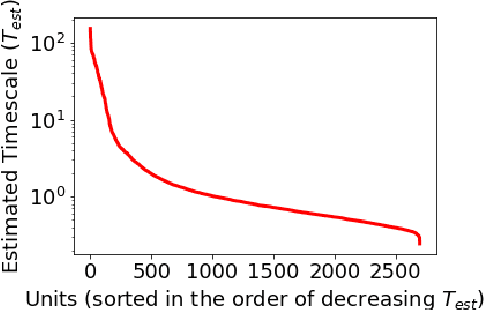
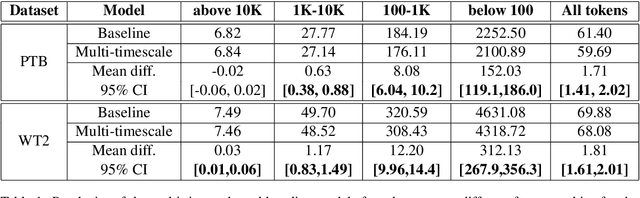
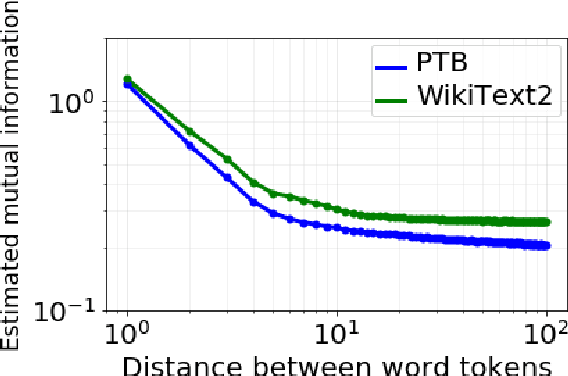

Although neural language models are effective at capturing statistics of natural language, their representations are challenging to interpret. In particular, it is unclear how these models retain information over multiple timescales. In this work, we construct explicitly multi-timescale language models by manipulating the input and forget gate biases in a long short-term memory (LSTM) network. The distribution of timescales is selected to approximate power law statistics of natural language through a combination of exponentially decaying memory cells. We then empirically analyze the timescale of information routed through each part of the model using word ablation experiments and forget gate visualizations. These experiments show that the multi-timescale model successfully learns representations at the desired timescales, and that the distribution includes longer timescales than a standard LSTM. Further, information about high-,mid-, and low-frequency words is routed preferentially through units with the appropriate timescales. Thus we show how to construct language models with interpretable representations of different information timescales.