 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Meta-Learning-Based KKL Observer Design for Nonlinear Dynamical Systems
Oct 30, 2023
The theory of Kazantzis-Kravaris/Luenberger (KKL) observer design introduces a methodology that uses a nonlinear transformation map and its left inverse to estimate the state of a nonlinear system through the introduction of a linear observer state space. Data-driven approaches using artificial neural networks have demonstrated the ability to accurately approximate these transformation maps. This paper presents a novel approach to observer design for nonlinear dynamical systems through meta-learning, a concept in machine learning that aims to optimize learning models for fast adaptation to a distribution of tasks through an improved focus on the intrinsic properties of the underlying learning problem. We introduce a framework that leverages information from measurements of the system output to design a learning-based KKL observer capable of online adaptation to a variety of system conditions and attributes. To validate the effectiveness of our approach, we present comprehensive experimental results for the estimation of nonlinear system states with varying initial conditions and internal parameters, demonstrating high accuracy, generalization capability, and robustness against noise.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.
FATA-Trans: Field And Time-Aware Transformer for Sequential Tabular Data
Oct 20, 2023Sequential tabular data is one of the most commonly used data types in real-world applications. Different from conventional tabular data, where rows in a table are independent, sequential tabular data contains rich contextual and sequential information, where some fields are dynamically changing over time and others are static. Existing transformer-based approaches analyzing sequential tabular data overlook the differences between dynamic and static fields by replicating and filling static fields into each transformer, and ignore temporal information between rows, which leads to three major disadvantages: (1) computational overhead, (2) artificially simplified data for masked language modeling pre-training task that may yield less meaningful representations, and (3) disregarding the temporal behavioral patterns implied by time intervals. In this work, we propose FATA-Trans, a model with two field transformers for modeling sequential tabular data, where each processes static and dynamic field information separately. FATA-Trans is field- and time-aware for sequential tabular data. The field-type embedding in the method enables FATA-Trans to capture differences between static and dynamic fields. The time-aware position embedding exploits both order and time interval information between rows, which helps the model detect underlying temporal behavior in a sequence. Our experiments on three benchmark datasets demonstrate that the learned representations from FATA-Trans consistently outperform state-of-the-art solutions in the downstream tasks. We also present visualization studies to highlight the insights captured by the learned representations, enhancing our understanding of the underlying data. Our codes are available at https://github.com/zdy93/FATA-Trans.
Social Commonsense-Guided Search Query Generation for Open-Domain Knowledge-Powered Conversations
Oct 22, 2023Open-domain dialog involves generating search queries that help obtain relevant knowledge for holding informative conversations. However, it can be challenging to determine what information to retrieve when the user is passive and does not express a clear need or request. To tackle this issue, we present a novel approach that focuses on generating internet search queries that are guided by social commonsense. Specifically, we leverage a commonsense dialog system to establish connections related to the conversation topic, which subsequently guides our query generation. Our proposed framework addresses passive user interactions by integrating topic tracking, commonsense response generation and instruction-driven query generation. Through extensive evaluations, we show that our approach overcomes limitations of existing query generation techniques that rely solely on explicit dialog information, and produces search queries that are more relevant, specific, and compelling, ultimately resulting in more engaging responses.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023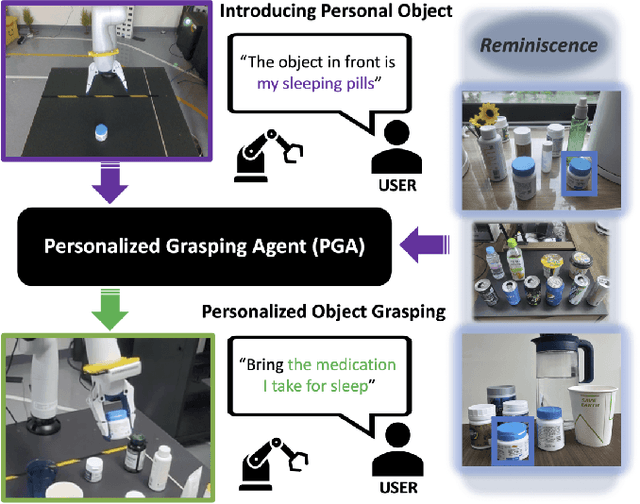
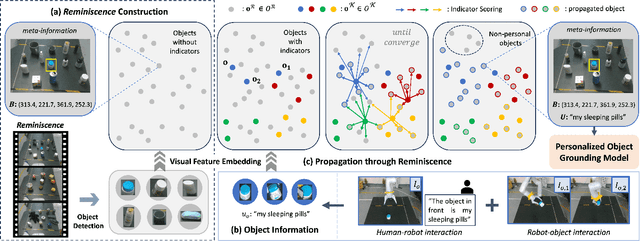
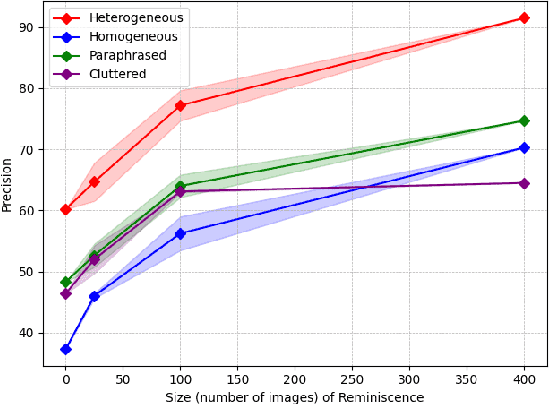
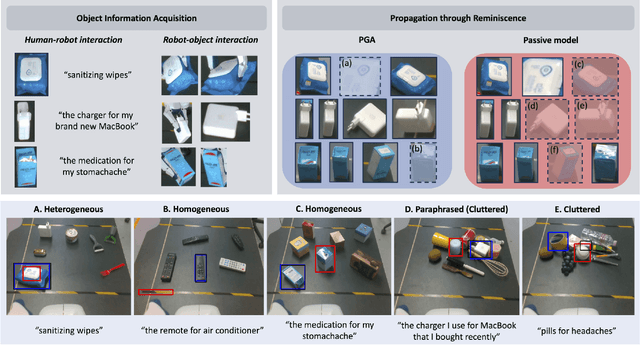
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.
Responsible Emergent Multi-Agent Behavior
Nov 02, 2023Responsible AI has risen to the forefront of the AI research community. As neural network-based learning algorithms continue to permeate real-world applications, the field of Responsible AI has played a large role in ensuring that such systems maintain a high-level of human-compatibility. Despite this progress, the state of the art in Responsible AI has ignored one crucial point: human problems are multi-agent problems. Predominant approaches largely consider the performance of a single AI system in isolation, but human problems are, by their very nature, multi-agent. From driving in traffic to negotiating economic policy, human problem-solving involves interaction and the interplay of the actions and motives of multiple individuals. This dissertation develops the study of responsible emergent multi-agent behavior, illustrating how researchers and practitioners can better understand and shape multi-agent learning with respect to three pillars of Responsible AI: interpretability, fairness, and robustness. First, I investigate multi-agent interpretability, presenting novel techniques for understanding emergent multi-agent behavior at multiple levels of granularity. With respect to low-level interpretability, I examine the extent to which implicit communication emerges as an aid to coordination in multi-agent populations. I introduce a novel curriculum-driven method for learning high-performing policies in difficult, sparse reward environments and show through a measure of position-based social influence that multi-agent teams that learn sophisticated coordination strategies exchange significantly more information through implicit signals than lesser-coordinated agents. Then, at a high-level, I study concept-based interpretability in the context of multi-agent learning. I propose a novel method for learning intrinsically interpretable, concept-based policies and show that it enables...
REAL: Resilience and Adaptation using Large Language Models on Autonomous Aerial Robots
Nov 02, 2023Large Language Models (LLMs) pre-trained on internet-scale datasets have shown impressive capabilities in code understanding, synthesis, and general purpose question-and-answering. Key to their performance is the substantial prior knowledge acquired during training and their ability to reason over extended sequences of symbols, often presented in natural language. In this work, we aim to harness the extensive long-term reasoning, natural language comprehension, and the available prior knowledge of LLMs for increased resilience and adaptation in autonomous mobile robots. We introduce REAL, an approach for REsilience and Adaptation using LLMs. REAL provides a strategy to employ LLMs as a part of the mission planning and control framework of an autonomous robot. The LLM employed by REAL provides (i) a source of prior knowledge to increase resilience for challenging scenarios that the system had not been explicitly designed for; (ii) a way to interpret natural-language and other log/diagnostic information available in the autonomy stack, for mission planning; (iii) a way to adapt the control inputs using minimal user-provided prior knowledge about the dynamics/kinematics of the robot. We integrate REAL in the autonomy stack of a real multirotor, querying onboard an offboard LLM at 0.1-1.0 Hz as part the robot's mission planning and control feedback loops. We demonstrate in real-world experiments the ability of the LLM to reduce the position tracking errors of a multirotor under the presence of (i) errors in the parameters of the controller and (ii) unmodeled dynamics. We also show (iii) decision making to avoid potentially dangerous scenarios (e.g., robot oscillates) that had not been explicitly accounted for in the initial prompt design.
Modulation Design and Optimization for RIS-Assisted Symbiotic Radios
Nov 02, 2023In reconfigurable intelligent surface (RIS)-assisted symbiotic radio (SR), the RIS acts as a secondary transmitter by modulating its information bits over the incident primary signal and simultaneously assists the primary transmission, then a cooperative receiver is used to jointly decode the primary and secondary signals. Most existing works of SR focus on using RIS to enhance the reflecting link while ignoring the ambiguity problem for the joint detection caused by the multiplication relationship of the primary and secondary signals. Particularly, in case of a blocked direct link, joint detection will suffer from severe performance loss due to the ambiguity, when using the conventional on-off keying and binary phase shift keying modulation schemes for RIS. To address this issue, we propose a novel modulation scheme for RIS-assisted SR that divides the phase-shift matrix into two components: the symbol-invariant and symbol-varying components, which are used to assist the primary transmission and carry the secondary signal, respectively. To design these two components, we focus on the detection of the composite signal formed by the primary and secondary signals, through which a problem of minimizing the bit error rate (BER) of the composite signal is formulated to improve both the BER performance of the primary and secondary ones. By solving the problem, we derive the closed-form solution of the optimal symbol-invariant and symbol-varying components, which is related to the channel strength ratio of the direct link to the reflecting link. Moreover, theoretical BER performance is analyzed. Finally, simulation results show the superiority of the proposed modulation scheme over its conventional counterpart.
Collaborative Large Language Model for Recommender Systems
Nov 02, 2023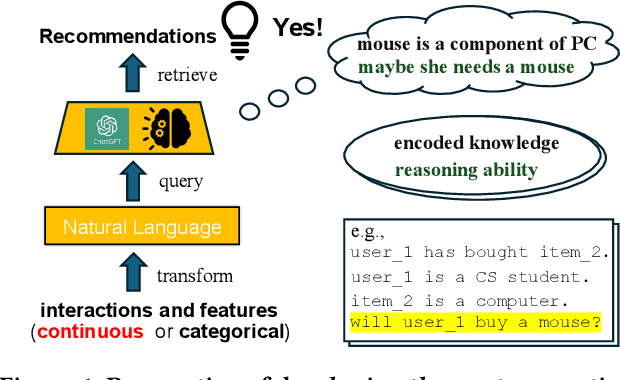
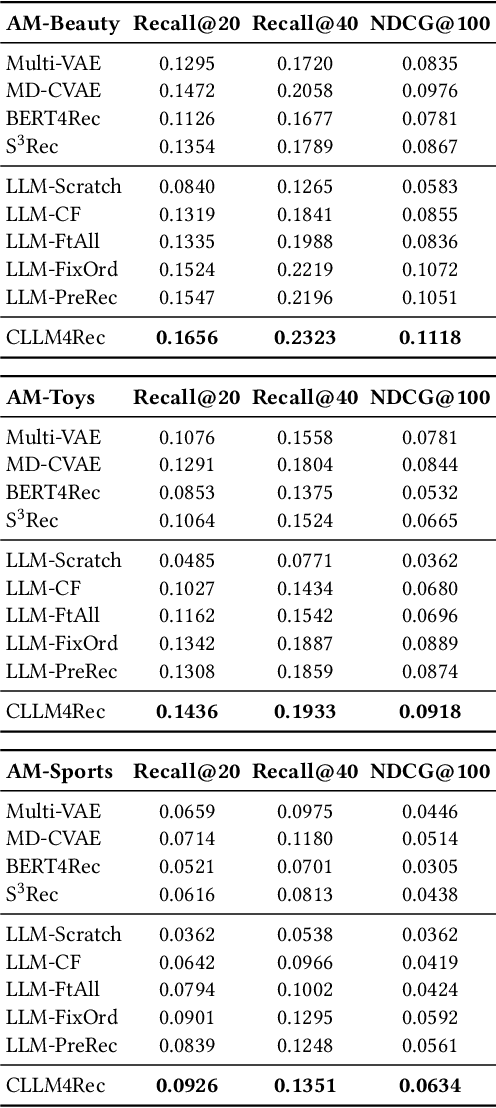
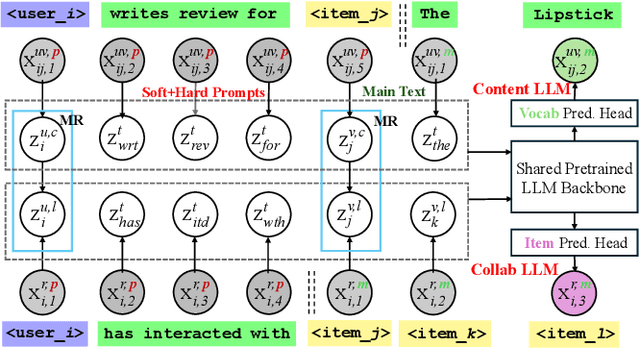
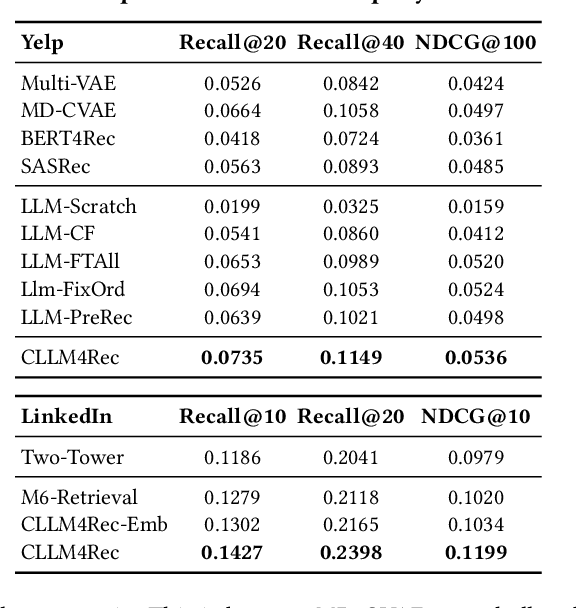
Recently, there is a growing interest in developing next-generation recommender systems (RSs) based on pretrained large language models (LLMs), fully utilizing their encoded knowledge and reasoning ability. However, the semantic gap between natural language and recommendation tasks is still not well addressed, leading to multiple issues such as spuriously-correlated user/item descriptors, ineffective language modeling on user/item contents, and inefficient recommendations via auto-regression, etc. In this paper, we propose CLLM4Rec, the first generative RS that tightly integrates the LLM paradigm and ID paradigm of RS, aiming to address the above challenges simultaneously. We first extend the vocabulary of pretrained LLMs with user/item ID tokens to faithfully model the user/item collaborative and content semantics. Accordingly, in the pretraining stage, a novel soft+hard prompting strategy is proposed to effectively learn user/item collaborative/content token embeddings via language modeling on RS-specific corpora established from user-item interactions and user/item features, where each document is split into a prompt consisting of heterogeneous soft (user/item) tokens and hard (vocab) tokens and a main text consisting of homogeneous item tokens or vocab tokens that facilitates stable and effective language modeling. In addition, a novel mutual regularization strategy is introduced to encourage the CLLM4Rec to capture recommendation-oriented information from user/item contents. Finally, we propose a novel recommendation-oriented finetuning strategy for CLLM4Rec, where an item prediction head with multinomial likelihood is added to the pretrained CLLM4Rec backbone to predict hold-out items based on the soft+hard prompts established from masked user-item interaction history, where recommendations of multiple items can be generated efficiently.
VM-Rec: A Variational Mapping Approach for Cold-start User Recommendation
Nov 02, 2023The cold-start problem is a common challenge for most recommender systems. With extremely limited interactions of cold-start users, conventional recommender models often struggle to generate embeddings with sufficient expressivity. Moreover, the absence of auxiliary content information of users exacerbates the presence of challenges, rendering most cold-start methods difficult to apply. To address this issue, our motivation is based on the observation that if a model can generate expressive embeddings for existing users with relatively more interactions, who were also initially cold-start users, then we can establish a mapping from few initial interactions to expressive embeddings, simulating the process of generating embeddings for cold-start users. Based on this motivation, we propose a Variational Mapping approach for cold-start user Recommendation (VM-Rec). Firstly, we generate a personalized mapping function for cold-start users based on their initial interactions, and parameters of the function are generated from a variational distribution. For the sake of interpretability and computational efficiency, we model the personalized mapping function as a sparse linear model, where each parameter indicates the association to a specific existing user. Consequently, we use this mapping function to map the embeddings of existing users to an embedding of the cold-start user in the same space. The resulting embedding has similar expressivity to that of existing users and can be directly integrated into a pre-trained recommender model to predict click through rates or ranking scores. We evaluate our method based on three widely used recommender models as pre-trained base recommender models, outperforming four popular cold-start methods on two datasets under the same base model.