 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOPOS: High-Fidelity and Efficient Industry-Grade 3D Head Generation
May 14, 2026High-fidelity 3D head generation plays a crucial role in the film, animation and video game industries. In industrial pipelines, studios typically enforce a fixed reference topology across all head assets, as such a clean and uniform topology is a prerequisite for production-level rigging, skinning and animation. In this paper, we present TOPOS, a framework tailored for single image conditioned 3D head generation that jointly recovers geometry and appearance under such an industry-standard topology. In contrast to general 3D generative models which produce triangle meshes with inconsistent topology and numerous vertices, hindering semantic correspondence and asset-level reuse, TOPOS generates head meshes with a fixed, studio-style topology, enabling consistent vertex-level correspondence across all generated heads. To model heads under this unified topology, we proposed a novel variational autoencoder structure, termed TOPOS-VAE. Inspired by multi-model large language models (MLLMs), our TOPOS-VAE leverages the Perceiver Resampler to convert input pointclouds sampled from head meshes of diverse topologies into the target reference topology. Building upon TOPOS-VAE's structured latent space, we train a rectified flow transformer, TOPOS-DiT, to efficiently generate high-fidelity head meshes from a single image. We further present TOPOS-Texture, an end-to-end module that produces relightable UV texture maps from the same portrait image via fine-tuning a multimodal image generative model. The generated textures are spatially aligned with the underlying mesh geometry and faithfully preserve high-frequency appearance details. Extensive experiments demonstrate that TOPOS achieves state-of-the-art performance on 3D head generation, surpassing both classical face reconstruction methods and general 3D object generative models, highlighting its effectiveness for digital human creation.
High-Fidelity Single-Image Head Modeling with Industry-Grade Topology
May 06, 2026We present a single-image head mesh reconstruction framework that addresses the longstanding challenge of simultaneously preserving facial identity and producing industry-grade topology. Our framework adopts a coarse-to-fine optimization pipeline that refines a rigged template across three stages -- rig, joint, and vertex -- achieving stable convergence and consistent topology. To mitigate the ill-posed nature of single-image 3D face reconstruction and ensure identity preservation, we employ a normal consistency objective jointly with landmark alignment. To further preserve local surface structure and enforce topological regularity, we introduce geometry-aware constraints based on Gaussian curvature and conformal consistency, along with auxiliary regularizations that correct fine artifacts such as lip seams and eyelid discontinuities. Our hierarchical optimization with geometry-aware regularization yields meshes with semantically meaningful edge flow and industry-grade topology. After geometry reconstruction, we extract UV-space texture and normal maps to preserve appearance details for visualization and downstream use. In a user study with 22 professional technical artists, our results were assessed as approaching industry-grade usability, and 95% of participants ranked our method as the top-performing approach, underscoring its effectiveness for real-world digital human production.
Monocular Building Height Estimation from PhiSat-2 Imagery: Dataset and Method
Apr 02, 2026Monocular building height estimation from optical imagery is important for urban morphology characterization but remains challenging due to ambiguous height cues, large inter-city variations in building morphology, and the long-tailed distribution of building heights. PhiSat-2 is a promising open-access data source for this task because of its global coverage, 4.75 m spatial resolution, and seven-band spectral observations, yet its potential has not been systematically evaluated. To address this gap, we construct a PhiSat-2-Height dataset (PHDataset) and propose a Two-Stream Ordinal Network (TSONet). PHDataset contains 9,475 co-registered image-label patch pairs from 26 cities worldwide. TSONet jointly models footprint segmentation and height estimation, and introduces a Cross-Stream Exchange Module (CSEM) and a Feature-Enhanced Bin Refinement (FEBR) module for footprint-aware feature interaction and ordinal height refinement. Experiments on PHDataset show that TSONet achieves the best overall performance, reducing MAE and RMSE by 13.2% and 9.7%, and improving IoU and F1-score by 14.0% and 10.1% over the strongest competing results. Ablation studies further verify the effectiveness of CSEM, FEBR, and the joint use of ordinal regression and footprint assistance. Additional analyses and patch-level comparison with publicly available building height products indicate that PhiSat-2 benefits monocular building height estimation through its balanced combination of building-relevant spatial detail and multispectral observations. Overall, this study confirms the potential of PhiSat-2 for monocular building height estimation and provides a dedicated dataset and an effective method for future research.
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Jan 26, 2025



Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends OCSR to molecular image caption from motif level to molecule level and abstract level. We present two approaches for that, including an OCSR-based method and an end-to-end OCSR-free method. The proposed Double-Check achieves SOTA OCSR performance on real-world patent and journal article scenarios via attentive feature enhancement for local ambiguous atoms. Cascading with SMILES-based molecule understanding methods, it can leverage the power of existing task-specific models for OCSU. While Mol-VL is an end-to-end optimized VLM-based model. An OCSU dataset, Vis-CheBI20, is built based on the widely used CheBI20 dataset for training and evaluation. Extensive experimental results on Vis-CheBI20 demonstrate the effectiveness of the proposed approaches. Improving OCSR capability can lead to a better OCSU performance for OCSR-based approach, and the SOTA performance of Mol-VL demonstrates the great potential of end-to-end approach.
Modulation Design and Optimization for RIS-Assisted Symbiotic Radios
Nov 02, 2023



In reconfigurable intelligent surface (RIS)-assisted symbiotic radio (SR), the RIS acts as a secondary transmitter by modulating its information bits over the incident primary signal and simultaneously assists the primary transmission, then a cooperative receiver is used to jointly decode the primary and secondary signals. Most existing works of SR focus on using RIS to enhance the reflecting link while ignoring the ambiguity problem for the joint detection caused by the multiplication relationship of the primary and secondary signals. Particularly, in case of a blocked direct link, joint detection will suffer from severe performance loss due to the ambiguity, when using the conventional on-off keying and binary phase shift keying modulation schemes for RIS. To address this issue, we propose a novel modulation scheme for RIS-assisted SR that divides the phase-shift matrix into two components: the symbol-invariant and symbol-varying components, which are used to assist the primary transmission and carry the secondary signal, respectively. To design these two components, we focus on the detection of the composite signal formed by the primary and secondary signals, through which a problem of minimizing the bit error rate (BER) of the composite signal is formulated to improve both the BER performance of the primary and secondary ones. By solving the problem, we derive the closed-form solution of the optimal symbol-invariant and symbol-varying components, which is related to the channel strength ratio of the direct link to the reflecting link. Moreover, theoretical BER performance is analyzed. Finally, simulation results show the superiority of the proposed modulation scheme over its conventional counterpart.
NeuDA: Neural Deformable Anchor for High-Fidelity Implicit Surface Reconstruction
Mar 04, 2023



This paper studies implicit surface reconstruction leveraging differentiable ray casting. Previous works such as IDR and NeuS overlook the spatial context in 3D space when predicting and rendering the surface, thereby may fail to capture sharp local topologies such as small holes and structures. To mitigate the limitation, we propose a flexible neural implicit representation leveraging hierarchical voxel grids, namely Neural Deformable Anchor (NeuDA), for high-fidelity surface reconstruction. NeuDA maintains the hierarchical anchor grids where each vertex stores a 3D position (or anchor) instead of the direct embedding (or feature). We optimize the anchor grids such that different local geometry structures can be adaptively encoded. Besides, we dig into the frequency encoding strategies and introduce a simple hierarchical positional encoding method for the hierarchical anchor structure to flexibly exploit the properties of high-frequency and low-frequency geometry and appearance. Experiments on both the DTU and BlendedMVS datasets demonstrate that NeuDA can produce promising mesh surfaces.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Dec 04, 2022



This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
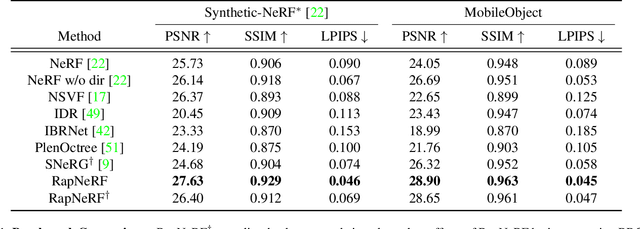
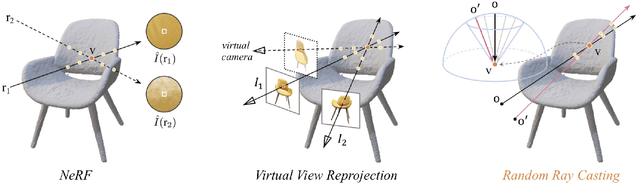
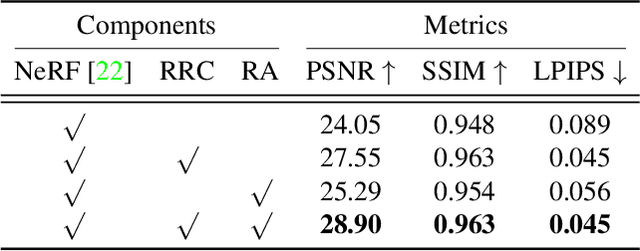
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.
Exploiting Diverse Characteristics and Adversarial Ambivalence for Domain Adaptive Segmentation
Jan 07, 2021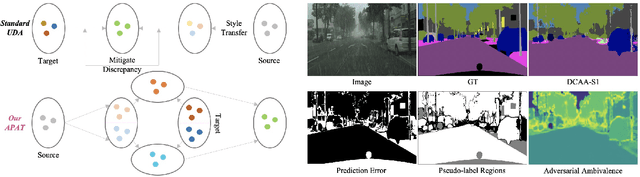
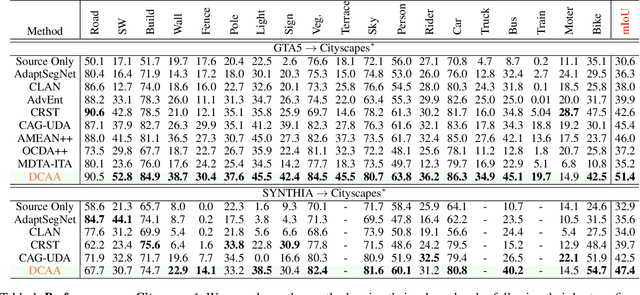
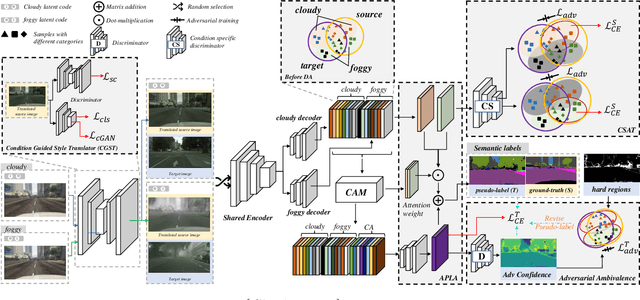
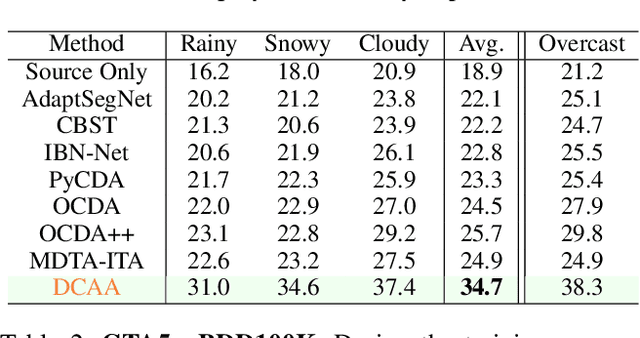
Adapting semantic segmentation models to new domains is an important but challenging problem. Recently enlightening progress has been made, but the performance of existing methods are unsatisfactory on real datasets where the new target domain comprises of heterogeneous sub-domains (e.g., diverse weather characteristics). We point out that carefully reasoning about the multiple modalities in the target domain can improve the robustness of adaptation models. To this end, we propose a condition-guided adaptation framework that is empowered by a special attentive progressive adversarial training (APAT) mechanism and a novel self-training policy. The APAT strategy progressively performs condition-specific alignment and attentive global feature matching. The new self-training scheme exploits the adversarial ambivalences of easy and hard adaptation regions and the correlations among target sub-domains effectively. We evaluate our method (DCAA) on various adaptation scenarios where the target images vary in weather conditions. The comparisons against baselines and the state-of-the-art approaches demonstrate the superiority of DCAA over the competitors.
3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics
Nov 18, 2020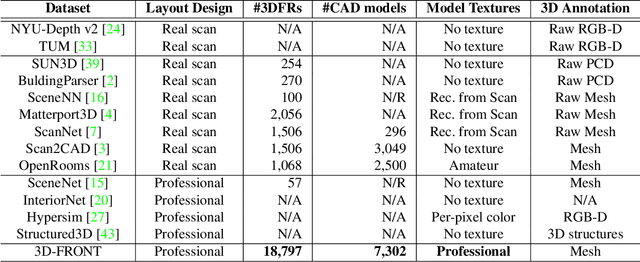
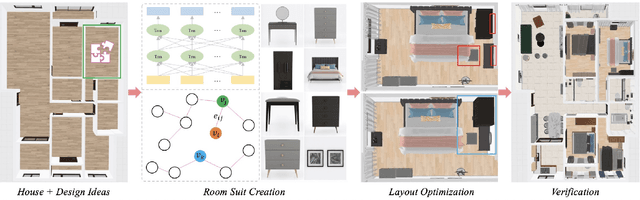
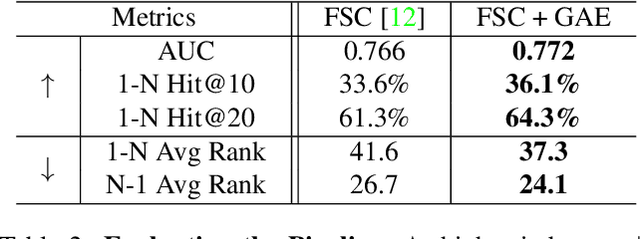
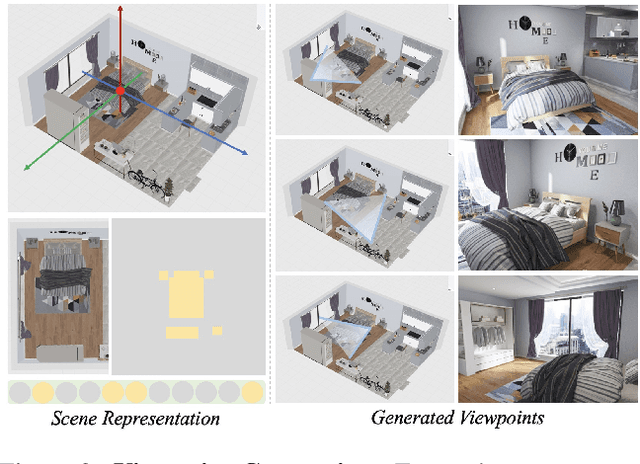
We introduce 3D-FRONT (3D Furnished Rooms with layOuts and semaNTics), a new, large-scale, and comprehensive repository of synthetic indoor scenes highlighted by professionally designed layouts and a large number of rooms populated by high-quality textured 3D models with style compatibility. From layout semantics down to texture details of individual objects, our dataset is freely available to the academic community and beyond. Currently, 3D-FRONT contains 18,797 rooms diversely furnished by 3D objects, far surpassing all publicly available scene datasets. In addition, the 7,302 furniture objects all come with high-quality textures. While the floorplans and layout designs are directly sourced from professional creations, the interior designs in terms of furniture styles, color, and textures have been carefully curated based on a recommender system we develop to attain consistent styles as expert designs. Furthermore, we release Trescope, a light-weight rendering tool, to support benchmark rendering of 2D images and annotations from 3D-FRONT. We demonstrate two applications, interior scene synthesis and texture synthesis, that are especially tailored to the strengths of our new dataset. The project page is at: https://tianchi.aliyun.com/specials/promotion/alibaba-3d-scene-dataset.