 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Recommendation with Denoising Auxiliary Task
Sep 25, 2024The historical interaction sequences of users plays a crucial role in training recommender systems that can accurately predict user preferences. However, due to the arbitrariness of user behavior, the presence of noise in these sequences poses a challenge to predicting their next actions in recommender systems. To address this issue, our motivation is based on the observation that training noisy sequences and clean sequences (sequences without noise) with equal weights can impact the performance of the model. We propose a novel self-supervised Auxiliary Task Joint Training (ATJT) method aimed at more accurately reweighting noisy sequences in recommender systems. Specifically, we strategically select subsets from users' original sequences and perform random replacements to generate artificially replaced noisy sequences. Subsequently, we perform joint training on these artificially replaced noisy sequences and the original sequences. Through effective reweighting, we incorporate the training results of the noise recognition model into the recommender model. We evaluate our method on three datasets using a consistent base model. Experimental results demonstrate the effectiveness of introducing self-supervised auxiliary task to enhance the base model's performance.
VM-Rec: A Variational Mapping Approach for Cold-start User Recommendation
Nov 02, 2023The cold-start problem is a common challenge for most recommender systems. With extremely limited interactions of cold-start users, conventional recommender models often struggle to generate embeddings with sufficient expressivity. Moreover, the absence of auxiliary content information of users exacerbates the presence of challenges, rendering most cold-start methods difficult to apply. To address this issue, our motivation is based on the observation that if a model can generate expressive embeddings for existing users with relatively more interactions, who were also initially cold-start users, then we can establish a mapping from few initial interactions to expressive embeddings, simulating the process of generating embeddings for cold-start users. Based on this motivation, we propose a Variational Mapping approach for cold-start user Recommendation (VM-Rec). Firstly, we generate a personalized mapping function for cold-start users based on their initial interactions, and parameters of the function are generated from a variational distribution. For the sake of interpretability and computational efficiency, we model the personalized mapping function as a sparse linear model, where each parameter indicates the association to a specific existing user. Consequently, we use this mapping function to map the embeddings of existing users to an embedding of the cold-start user in the same space. The resulting embedding has similar expressivity to that of existing users and can be directly integrated into a pre-trained recommender model to predict click through rates or ranking scores. We evaluate our method based on three widely used recommender models as pre-trained base recommender models, outperforming four popular cold-start methods on two datasets under the same base model.
Anomaly Sequences Detection from Logs Based on Compression
Sep 08, 2011
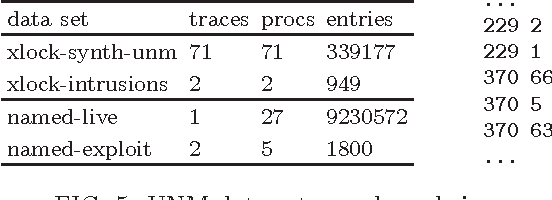


Mining information from logs is an old and still active research topic. In recent years, with the rapid emerging of cloud computing, log mining becomes increasingly important to industry. This paper focus on one major mission of log mining: anomaly detection, and proposes a novel method for mining abnormal sequences from large logs. Different from previous anomaly detection systems which based on statistics, probabilities and Markov assumption, our approach measures the strangeness of a sequence using compression. It first trains a grammar about normal behaviors using grammar-based compression, then measures the information quantities and densities of questionable sequences according to incrementation of grammar length. We have applied our approach on mining some real bugs from fine grained execution logs. We have also tested its ability on intrusion detection using some publicity available system call traces. The experiments show that our method successfully selects the strange sequences which related to bugs or attacking.