 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text2Tree: Aligning Text Representation to the Label Tree Hierarchy for Imbalanced Medical Classification
Nov 28, 2023
Deep learning approaches exhibit promising performances on various text tasks. However, they are still struggling on medical text classification since samples are often extremely imbalanced and scarce. Different from existing mainstream approaches that focus on supplementary semantics with external medical information, this paper aims to rethink the data challenges in medical texts and present a novel framework-agnostic algorithm called Text2Tree that only utilizes internal label hierarchy in training deep learning models. We embed the ICD code tree structure of labels into cascade attention modules for learning hierarchy-aware label representations. Two new learning schemes, Similarity Surrogate Learning (SSL) and Dissimilarity Mixup Learning (DML), are devised to boost text classification by reusing and distinguishing samples of other labels following the label representation hierarchy, respectively. Experiments on authoritative public datasets and real-world medical records show that our approach stably achieves superior performances over classical and advanced imbalanced classification methods.
CiwaGAN: Articulatory information exchange
Sep 14, 2023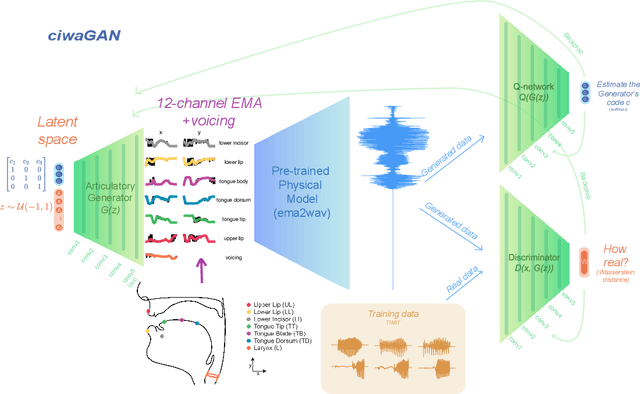

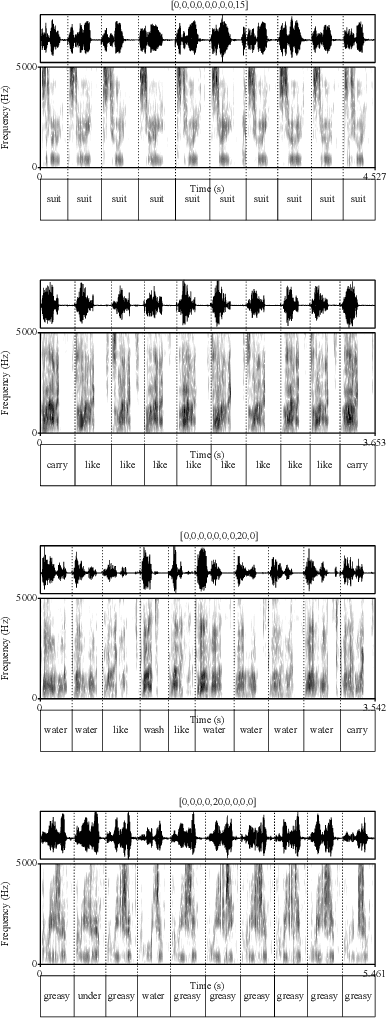

Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Deep Variational Multivariate Information Bottleneck -- A Framework for Variational Losses
Oct 05, 2023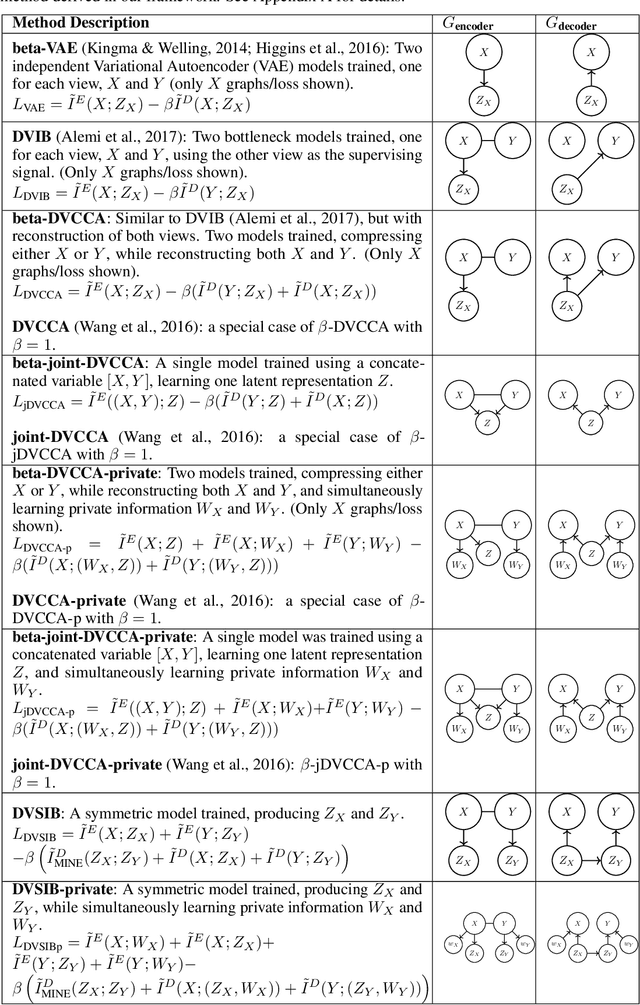
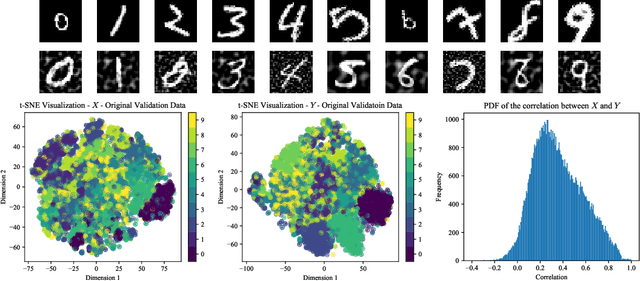
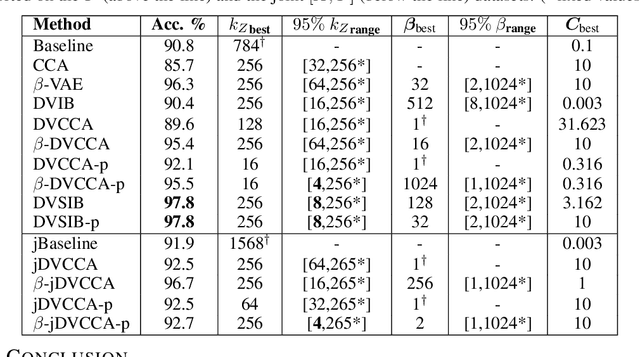
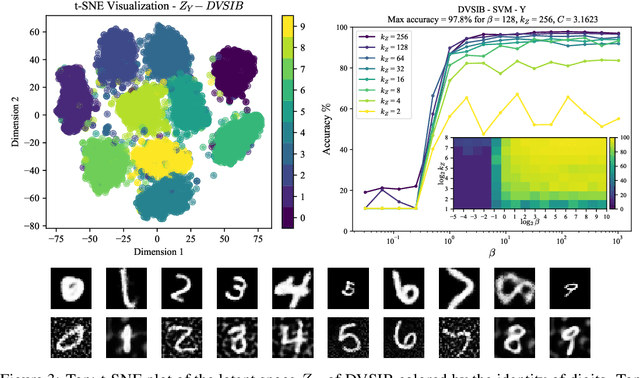
Variational dimensionality reduction methods are known for their high accuracy, generative abilities, and robustness. These methods have many theoretical justifications. Here we introduce a unifying principle rooted in information theory to rederive and generalize existing variational methods and design new ones. We base our framework on an interpretation of the multivariate information bottleneck, in which two Bayesian networks are traded off against one another. We interpret the first network as an encoder graph, which specifies what information to keep when compressing the data. We interpret the second network as a decoder graph, which specifies a generative model for the data. Using this framework, we rederive existing dimensionality reduction methods such as the deep variational information bottleneck (DVIB), beta variational auto-encoders (beta-VAE), and deep variational canonical correlation analysis (DVCCA). The framework naturally introduces a trade-off parameter between compression and reconstruction in the DVCCA family of algorithms, resulting in the new beta-DVCCA family. In addition, we derive a new variational dimensionality reduction method, deep variational symmetric informational bottleneck (DVSIB), which simultaneously compresses two variables to preserve information between their compressed representations. We implement all of these algorithms and evaluate their ability to produce shared low dimensional latent spaces on a modified noisy MNIST dataset. We show that algorithms that are better matched to the structure of the data (beta-DVCCA and DVSIB) produce better latent spaces as measured by classification accuracy and the dimensionality of the latent variables. We believe that this framework can be used to unify other multi-view representation learning algorithms. Additionally, it provides a straightforward framework for deriving problem-specific loss functions.
Query-LIFE: Query-aware Language Image Fusion Embedding for E-Commerce Relevance
Nov 26, 2023Relevance module plays a fundamental role in e-commerce search as they are responsible for selecting relevant products from thousands of items based on user queries, thereby enhancing users experience and efficiency. The traditional approach models the relevance based product titles and queries, but the information in titles alone maybe insufficient to describe the products completely. A more general optimization approach is to further leverage product image information. In recent years, vision-language pre-training models have achieved impressive results in many scenarios, which leverage contrastive learning to map both textual and visual features into a joint embedding space. In e-commerce, a common practice is to fine-tune on the pre-trained model based on e-commerce data. However, the performance is sub-optimal because the vision-language pre-training models lack of alignment specifically designed for queries. In this paper, we propose a method called Query-LIFE (Query-aware Language Image Fusion Embedding) to address these challenges. Query-LIFE utilizes a query-based multimodal fusion to effectively incorporate the image and title based on the product types. Additionally, it employs query-aware modal alignment to enhance the accuracy of the comprehensive representation of products. Furthermore, we design GenFilt, which utilizes the generation capability of large models to filter out false negative samples and further improve the overall performance of the contrastive learning task in the model. Experiments have demonstrated that Query-LIFE outperforms existing baselines. We have conducted ablation studies and human evaluations to validate the effectiveness of each module within Query-LIFE. Moreover, Query-LIFE has been deployed on Miravia Search, resulting in improved both relevance and conversion efficiency.
Language Model Inversion
Nov 22, 2023Language models produce a distribution over the next token; can we use this information to recover the prompt tokens? We consider the problem of language model inversion and show that next-token probabilities contain a surprising amount of information about the preceding text. Often we can recover the text in cases where it is hidden from the user, motivating a method for recovering unknown prompts given only the model's current distribution output. We consider a variety of model access scenarios, and show how even without predictions for every token in the vocabulary we can recover the probability vector through search. On Llama-2 7b, our inversion method reconstructs prompts with a BLEU of $59$ and token-level F1 of $78$ and recovers $27\%$ of prompts exactly. Code for reproducing all experiments is available at http://github.com/jxmorris12/vec2text.
DiffuseBot: Breeding Soft Robots With Physics-Augmented Generative Diffusion Models
Nov 28, 2023Nature evolves creatures with a high complexity of morphological and behavioral intelligence, meanwhile computational methods lag in approaching that diversity and efficacy. Co-optimization of artificial creatures' morphology and control in silico shows promise for applications in physical soft robotics and virtual character creation; such approaches, however, require developing new learning algorithms that can reason about function atop pure structure. In this paper, we present DiffuseBot, a physics-augmented diffusion model that generates soft robot morphologies capable of excelling in a wide spectrum of tasks. DiffuseBot bridges the gap between virtually generated content and physical utility by (i) augmenting the diffusion process with a physical dynamical simulation which provides a certificate of performance, and (ii) introducing a co-design procedure that jointly optimizes physical design and control by leveraging information about physical sensitivities from differentiable simulation. We showcase a range of simulated and fabricated robots along with their capabilities. Check our website at https://diffusebot.github.io/
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models
Nov 28, 2023In this work, we present a novel method to tackle the token generation challenge in Vision Language Models (VLMs) for video and image understanding, called LLaMA-VID. Current VLMs, while proficient in tasks like image captioning and visual question answering, face computational burdens when processing long videos due to the excessive visual tokens. LLaMA-VID addresses this issue by representing each frame with two distinct tokens, namely context token and content token. The context token encodes the overall image context based on user input, whereas the content token encapsulates visual cues in each frame. This dual-token strategy significantly reduces the overload of long videos while preserving critical information. Generally, LLaMA-VID empowers existing frameworks to support hour-long videos and pushes their upper limit with an extra context token. It is proved to surpass previous methods on most of video- or image-based benchmarks. Code is available https://github.com/dvlab-research/LLaMA-VID}{https://github.com/dvlab-research/LLaMA-VID
Temporal Importance Factor for Loss Functions for CTR Prediction
Nov 28, 2023Click-through rate (CTR) prediction is an important task for the companies to recommend products which better match user preferences. User behavior in digital advertising is dynamic and changes over time. It is crucial for the companies to capture the most recent trends to provide more accurate recommendations for users. In CTR prediction, most models use binary cross-entropy loss function. However, it does not focus on the data distribution shifts occurring over time. To address this problem, we propose a factor for the loss functions by utilizing the sequential nature of user-item interactions. This approach aims to focus on the most recent samples by penalizing them more through the loss function without forgetting the long-term information. Our solution is model-agnostic, and the temporal importance factor can be used with different loss functions. Offline experiments in both public and company datasets show that the temporal importance factor for loss functions outperforms the baseline loss functions considered.
Augmenting x-ray single particle imaging reconstruction with self-supervised machine learning
Nov 28, 2023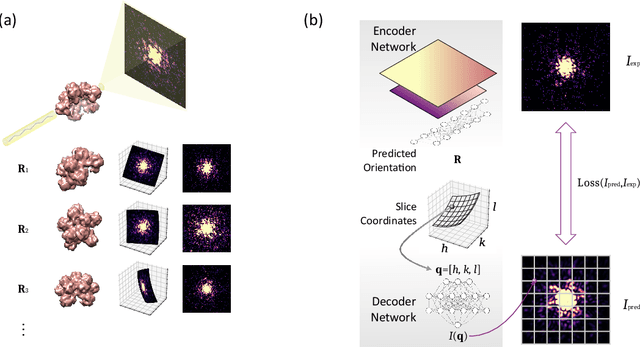
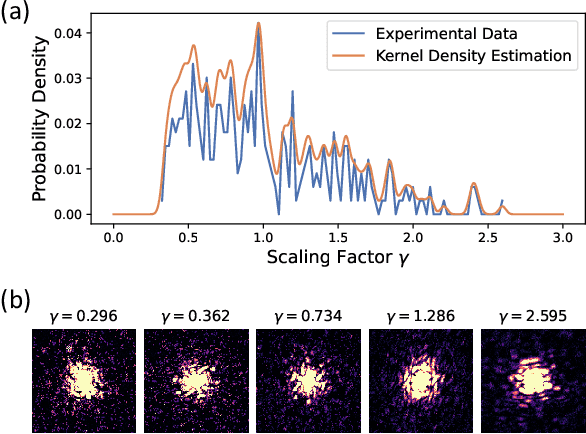
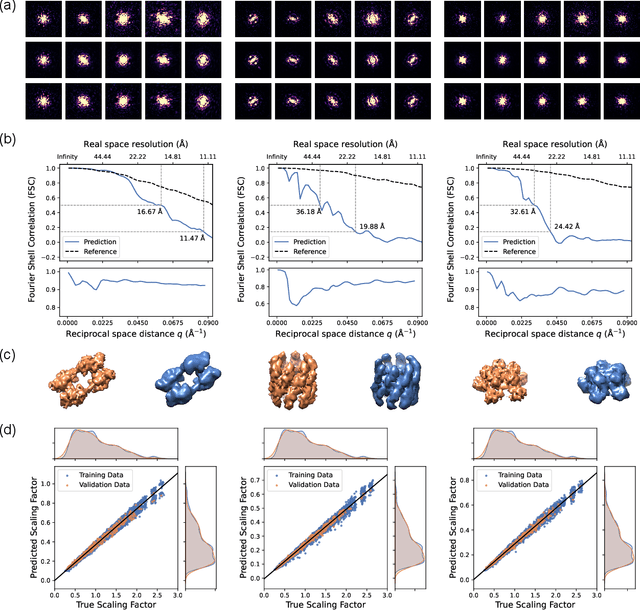
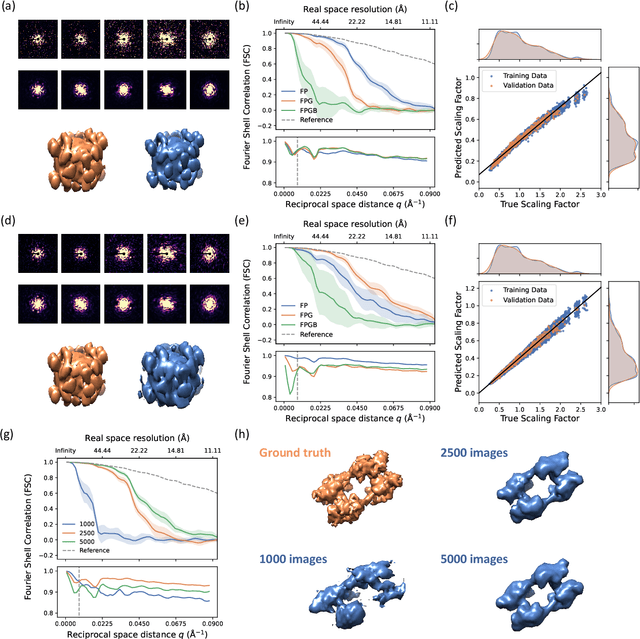
The development of X-ray Free Electron Lasers (XFELs) has opened numerous opportunities to probe atomic structure and ultrafast dynamics of various materials. Single Particle Imaging (SPI) with XFELs enables the investigation of biological particles in their natural physiological states with unparalleled temporal resolution, while circumventing the need for cryogenic conditions or crystallization. However, reconstructing real-space structures from reciprocal-space x-ray diffraction data is highly challenging due to the absence of phase and orientation information, which is further complicated by weak scattering signals and considerable fluctuations in the number of photons per pulse. In this work, we present an end-to-end, self-supervised machine learning approach to recover particle orientations and estimate reciprocal space intensities from diffraction images only. Our method demonstrates great robustness under demanding experimental conditions with significantly enhanced reconstruction capabilities compared with conventional algorithms, and signifies a paradigm shift in SPI as currently practiced at XFELs.
TopoSemiSeg: Enforcing Topological Consistency for Semi-Supervised Segmentation of Histopathology Images
Nov 28, 2023In computational pathology, segmenting densely distributed objects like glands and nuclei is crucial for downstream analysis. To alleviate the burden of obtaining pixel-wise annotations, semi-supervised learning methods learn from large amounts of unlabeled data. Nevertheless, existing semi-supervised methods overlook the topological information hidden in the unlabeled images and are thus prone to topological errors, e.g., missing or incorrectly merged/separated glands or nuclei. To address this issue, we propose TopoSemiSeg, the first semi-supervised method that learns the topological representation from unlabeled data. In particular, we propose a topology-aware teacher-student approach in which the teacher and student networks learn shared topological representations. To achieve this, we introduce topological consistency loss, which contains signal consistency and noise removal losses to ensure the learned representation is robust and focuses on true topological signals. Extensive experiments on public pathology image datasets show the superiority of our method, especially on topology-wise evaluation metrics. Code is available at https://github.com/Melon-Xu/TopoSemiSeg.