 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGUIDE: Benchmarking Clinical Decision-Making in Large Language Models
May 16, 2025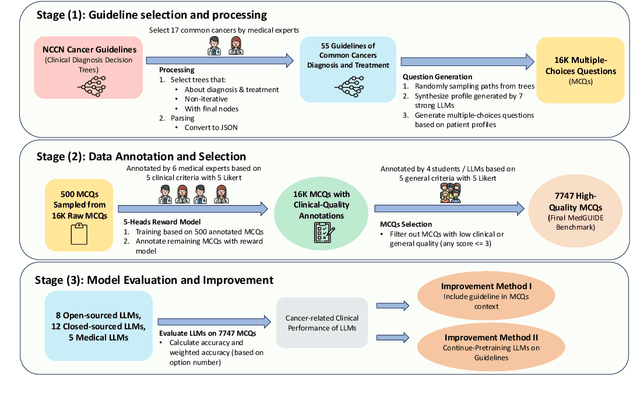
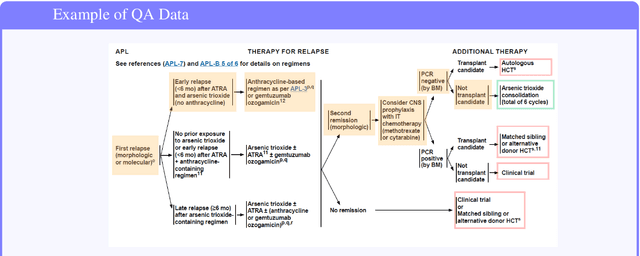
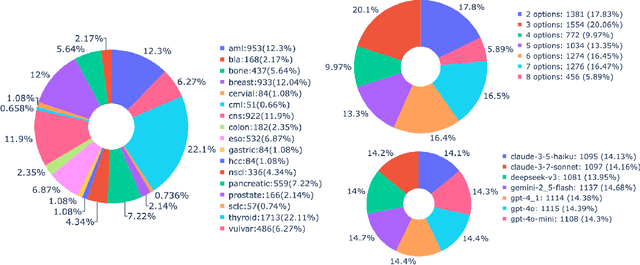
Clinical guidelines, typically structured as decision trees, are central to evidence-based medical practice and critical for ensuring safe and accurate diagnostic decision-making. However, it remains unclear whether Large Language Models (LLMs) can reliably follow such structured protocols. In this work, we introduce MedGUIDE, a new benchmark for evaluating LLMs on their ability to make guideline-consistent clinical decisions. MedGUIDE is constructed from 55 curated NCCN decision trees across 17 cancer types and uses clinical scenarios generated by LLMs to create a large pool of multiple-choice diagnostic questions. We apply a two-stage quality selection process, combining expert-labeled reward models and LLM-as-a-judge ensembles across ten clinical and linguistic criteria, to select 7,747 high-quality samples. We evaluate 25 LLMs spanning general-purpose, open-source, and medically specialized models, and find that even domain-specific LLMs often underperform on tasks requiring structured guideline adherence. We also test whether performance can be improved via in-context guideline inclusion or continued pretraining. Our findings underscore the importance of MedGUIDE in assessing whether LLMs can operate safely within the procedural frameworks expected in real-world clinical settings.
Multi-head Reward Aggregation Guided by Entropy
Mar 26, 2025



Aligning large language models (LLMs) with safety guidelines typically involves reinforcement learning from human feedback (RLHF), relying on human-generated preference annotations. However, assigning consistent overall quality ratings is challenging, prompting recent research to shift towards detailed evaluations based on multiple specific safety criteria. This paper uncovers a consistent observation: safety rules characterized by high rating entropy are generally less reliable in identifying responses preferred by humans. Leveraging this finding, we introduce ENCORE, a straightforward entropy-guided approach that composes multi-head rewards by downweighting rules exhibiting high rating entropy. Theoretically, we demonstrate that rules with elevated entropy naturally receive minimal weighting in the Bradley-Terry optimization framework, justifying our entropy-based penalization. Through extensive experiments on RewardBench safety tasks, our method significantly surpasses several competitive baselines, including random weighting, uniform weighting, single-head Bradley-Terry models, and LLM-based judging methods. Our proposed approach is training-free, broadly applicable to various datasets, and maintains interpretability, offering a practical and effective solution for multi-attribute reward modeling.
Data-adaptive Safety Rules for Training Reward Models
Jan 26, 2025



Reinforcement Learning from Human Feedback (RLHF) is commonly employed to tailor models to human preferences, especially to improve the safety of outputs from large language models (LLMs). Traditionally, this method depends on selecting preferred responses from pairs. However, due to the variability in human opinions and the challenges in directly comparing two responses, there is an increasing trend towards fine-grained annotation approaches that evaluate responses using multiple targeted metrics or rules. The challenge lies in efficiently choosing and applying these rules to handle the diverse range of preference data. In this paper, we propose a dynamic method that adaptively selects the most important rules for each response pair. We introduce a mathematical framework that utilizes the maximum discrepancy across paired responses and demonstrate theoretically that this approach maximizes the mutual information between the rule-based annotations and the underlying true preferences. We then train an 8B reward model using this adaptively labeled preference dataset and assess its efficacy using RewardBench. As of January 25, 2025, our model achieved the highest safety performance on the leaderboard, surpassing various larger models.
The use of large language models to enhance cancer clinical trial educational materials
Dec 02, 2024Cancer clinical trials often face challenges in recruitment and engagement due to a lack of participant-facing informational and educational resources. This study investigated the potential of Large Language Models (LLMs), specifically GPT4, in generating patient-friendly educational content from clinical trial informed consent forms. Using data from ClinicalTrials.gov, we employed zero-shot learning for creating trial summaries and one-shot learning for developing multiple-choice questions, evaluating their effectiveness through patient surveys and crowdsourced annotation. Results showed that GPT4-generated summaries were both readable and comprehensive, and may improve patients' understanding and interest in clinical trials. The multiple-choice questions demonstrated high accuracy and agreement with crowdsourced annotators. For both resource types, hallucinations were identified that require ongoing human oversight. The findings demonstrate the potential of LLMs "out-of-the-box" to support the generation of clinical trial education materials with minimal trial-specific engineering, but implementation with a human-in-the-loop is still needed to avoid misinformation risks.
Rule-based Data Selection for Large Language Models
Oct 07, 2024



The quality of training data significantly impacts the performance of large language models (LLMs). There are increasing studies using LLMs to rate and select data based on several human-crafted metrics (rules). However, these conventional rule-based approaches often depend too heavily on human heuristics, lack effective metrics for assessing rules, and exhibit limited adaptability to new tasks. In our study, we introduce an innovative rule-based framework that utilizes the orthogonality of score vectors associated with rules as a novel metric for rule evaluations. Our approach includes an automated pipeline that first uses LLMs to generate a diverse set of rules, encompassing various rating dimensions to evaluate data quality. Then it rates a batch of data based on these rules and uses the determinantal point process (DPP) from random matrix theory to select the most orthogonal score vectors, thereby identifying a set of independent rules. These rules are subsequently used to evaluate all data, selecting samples with the highest average scores for downstream tasks such as LLM training. We verify the effectiveness of our method through two experimental setups: 1) comparisons with ground truth ratings and 2) benchmarking LLMs trained with the chosen data. Our comprehensive experiments cover a range of scenarios, including general pre-training and domain-specific fine-tuning in areas such as IMDB, Medical, Math, and Code. The outcomes demonstrate that our DPP-based rule rating method consistently outperforms other approaches, including rule-free rating, uniform sampling, importance resampling, and QuRating, in terms of both rating precision and model performance.
Wait, but Tylenol is Acetaminophen... Investigating and Improving Language Models' Ability to Resist Requests for Misinformation
Sep 30, 2024



Background: Large language models (LLMs) are trained to follow directions, but this introduces a vulnerability to blindly comply with user requests even if they generate wrong information. In medicine, this could accelerate the generation of misinformation that impacts human well-being. Objectives/Methods: We analyzed compliance to requests to generate misleading content about medications in settings where models know the request is illogical. We investigated whether in-context directions and instruction-tuning of LLMs to prioritize logical reasoning over compliance reduced misinformation risk. Results: While all frontier LLMs complied with misinformation requests, both prompt-based and parameter-based approaches can improve the detection of logic flaws in requests and prevent the dissemination of medical misinformation. Conclusion: Shifting LLMs to prioritize logic over compliance could reduce risks of exploitation for medical misinformation.
Language Models are Surprisingly Fragile to Drug Names in Biomedical Benchmarks
Jun 17, 2024Medical knowledge is context-dependent and requires consistent reasoning across various natural language expressions of semantically equivalent phrases. This is particularly crucial for drug names, where patients often use brand names like Advil or Tylenol instead of their generic equivalents. To study this, we create a new robustness dataset, RABBITS, to evaluate performance differences on medical benchmarks after swapping brand and generic drug names using physician expert annotations. We assess both open-source and API-based LLMs on MedQA and MedMCQA, revealing a consistent performance drop ranging from 1-10\%. Furthermore, we identify a potential source of this fragility as the contamination of test data in widely used pre-training datasets. All code is accessible at https://github.com/BittermanLab/RABBITS, and a HuggingFace leaderboard is available at https://huggingface.co/spaces/AIM-Harvard/rabbits-leaderboard.
A Comprehensive Survey of Accelerated Generation Techniques in Large Language Models
May 15, 2024Despite the crucial importance of accelerating text generation in large language models (LLMs) for efficiently producing content, the sequential nature of this process often leads to high inference latency, posing challenges for real-time applications. Various techniques have been proposed and developed to address these challenges and improve efficiency. This paper presents a comprehensive survey of accelerated generation techniques in autoregressive language models, aiming to understand the state-of-the-art methods and their applications. We categorize these techniques into several key areas: speculative decoding, early exiting mechanisms, and non-autoregressive methods. We discuss each category's underlying principles, advantages, limitations, and recent advancements. Through this survey, we aim to offer insights into the current landscape of techniques in LLMs and provide guidance for future research directions in this critical area of natural language processing.
Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias
May 09, 2024



Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data. In this study, we introduce Cross-Care, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups. We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs. We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups. Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs. Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages. For further exploration and analysis, we make all data and a data visualization tool available at: www.crosscare.net.
Augmenting x-ray single particle imaging reconstruction with self-supervised machine learning
Nov 28, 2023



The development of X-ray Free Electron Lasers (XFELs) has opened numerous opportunities to probe atomic structure and ultrafast dynamics of various materials. Single Particle Imaging (SPI) with XFELs enables the investigation of biological particles in their natural physiological states with unparalleled temporal resolution, while circumventing the need for cryogenic conditions or crystallization. However, reconstructing real-space structures from reciprocal-space x-ray diffraction data is highly challenging due to the absence of phase and orientation information, which is further complicated by weak scattering signals and considerable fluctuations in the number of photons per pulse. In this work, we present an end-to-end, self-supervised machine learning approach to recover particle orientations and estimate reciprocal space intensities from diffraction images only. Our method demonstrates great robustness under demanding experimental conditions with significantly enhanced reconstruction capabilities compared with conventional algorithms, and signifies a paradigm shift in SPI as currently practiced at XFELs.