 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Navigation for Aerial Robots: Towards the Era of Large Language Models
Apr 09, 2026Aerial vision-and-language navigation (Aerial VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and autonomously navigate complex three-dimensional environments by grounding language in visual perception. This survey provides a critical and analytical review of the Aerial VLN field, with particular attention to the recent integration of large language models (LLMs) and vision-language models (VLMs). We first formally introduce the Aerial VLN problem and define two interaction paradigms: single-instruction and dialog-based, as foundational axes. We then organize the body of Aerial VLN methods into a taxonomy of five architectural categories: sequence-to-sequence and attention-based methods, end-to-end LLM/VLM methods, hierarchical methods, multi-agent methods, and dialog-based navigation methods. For each category, we systematically analyze design rationales, technical trade-offs, and reported performance. We critically assess the evaluation infrastructure for Aerial VLN, including datasets, simulation platforms, and metrics, and identify their gaps in scale, environmental diversity, real-world grounding, and metric coverage. We consolidate cross-method comparisons on shared benchmarks and analyze key architectural trade-offs, including discrete versus continuous actions, end-to-end versus hierarchical designs, and the simulation-to-reality gap. Finally, we synthesize seven concrete open problems: long-horizon instruction grounding, viewpoint robustness, scalable spatial representation, continuous 6-DoF action execution, onboard deployment, benchmark standardization, and multi-UAV swarm navigation, with specific research directions grounded in the evidence presented throughout the survey.
GateSID: Adaptive Gating for Semantic-Collaborative Alignment in Cold-Start Recommendation
Mar 24, 2026In cold-start scenarios, the scarcity of collaborative signals for new items exacerbates the Matthew effect, which undermines platform diversity and remains a persistent challenge in real-world recommender systems. Existing methods typically enhance collaborative signals with semantic information, but they often suffer from a collaborative-semantic tradeoff: collaborative signals are effective for popular items but unreliable for cold-start items, whereas over-reliance on semantic information may obscure meaningful collaborative differences. To address this issue, we propose GateSID, a framework that uses an adaptive gating network to dynamically balance semantic and collaborative signals according to item maturity. Specifically, we first discretize multimodal features into hierarchical Semantic IDs using Residual Quantized VAE. Building on this representation, we design two key components: (1) Gating-Fused Shared Attention, which fuses intra-modal attention distributions with item-level gating weights derived from embeddings and statistical features; and (2) Gate-Regulated Contrastive Alignment, which adaptively calibrates cross-modal alignment, enforcing stronger semantic-behavior consistency for cold-start items while relaxing the constraint for popular items to preserve reliable collaborative signals. Extensive offline experiments on large-scale industrial datasets demonstrate that GateSID consistently outperforms strong baselines. Online A/B tests further confirm its practical value, yielding +2.6% GMV, +1.1% CTR, and +1.6% orders with less than 5 ms additional latency.
SORT: A Systematically Optimized Ranking Transformer for Industrial-scale Recommenders
Mar 04, 2026While Transformers have achieved remarkable success in LLMs through superior scalability, their application in industrial-scale ranking models remains nascent, hindered by the challenges of high feature sparsity and low label density. In this paper, we propose SORT (Systematically Optimized Ranking Transformer), a scalable model designed to bridge the gap between Transformers and industrial-scale ranking models. We address the high feature sparsity and low label density challenges through a series of optimizations, including request-centric sample organization, local attention, query pruning and generative pre-training. Furthermore, we introduce a suite of refinements to the tokenization, multi-head attention (MHA), and feed-forward network (FFN) modules, which collectively stabilize the training process and enlarge the model capacity. To maximize hardware efficiency, we optimize our training system to elevate the model FLOPs utilization (MFU) to 22%. Extensive experiments demonstrate that SORT outperforms strong baselines and exhibits excellent scalability across data size, model size and sequence length, while remaining flexible at integrating diverse features. Finally, online A/B testing in large-scale e-commerce scenarios confirms that SORT achieves significant gains in key business metrics, including orders (+6.35%), buyers (+5.97%) and GMV (+5.47%), while simultaneously halving latency (-44.67%) and doubling throughput (+121.33%).
Query-LIFE: Query-aware Language Image Fusion Embedding for E-Commerce Relevance
Nov 26, 2023



Relevance module plays a fundamental role in e-commerce search as they are responsible for selecting relevant products from thousands of items based on user queries, thereby enhancing users experience and efficiency. The traditional approach models the relevance based product titles and queries, but the information in titles alone maybe insufficient to describe the products completely. A more general optimization approach is to further leverage product image information. In recent years, vision-language pre-training models have achieved impressive results in many scenarios, which leverage contrastive learning to map both textual and visual features into a joint embedding space. In e-commerce, a common practice is to fine-tune on the pre-trained model based on e-commerce data. However, the performance is sub-optimal because the vision-language pre-training models lack of alignment specifically designed for queries. In this paper, we propose a method called Query-LIFE (Query-aware Language Image Fusion Embedding) to address these challenges. Query-LIFE utilizes a query-based multimodal fusion to effectively incorporate the image and title based on the product types. Additionally, it employs query-aware modal alignment to enhance the accuracy of the comprehensive representation of products. Furthermore, we design GenFilt, which utilizes the generation capability of large models to filter out false negative samples and further improve the overall performance of the contrastive learning task in the model. Experiments have demonstrated that Query-LIFE outperforms existing baselines. We have conducted ablation studies and human evaluations to validate the effectiveness of each module within Query-LIFE. Moreover, Query-LIFE has been deployed on Miravia Search, resulting in improved both relevance and conversion efficiency.
Unwieldy Object Delivery with Nonholonomic Mobile Base: A Stable Pushing Approach
Sep 25, 2023



This paper addresses the problem of pushing manipulation with nonholonomic mobile robots. Pushing is a fundamental skill that enables robots to move unwieldy objects that cannot be grasped. We propose a stable pushing method that maintains stiff contact between the robot and the object to avoid consuming repositioning actions. We prove that a line contact, rather than a single point contact, is necessary for nonholonomic robots to achieve stable pushing. We also show that the stable pushing constraint and the nonholonomic constraint of the robot can be simplified as a concise linear motion constraint. Then the pushing planning problem can be formulated as a constrained optimization problem using nonlinear model predictive control (NMPC). According to the experiments, our NMPC-based planner outperforms a reactive pushing strategy in terms of efficiency, reducing the robot's traveled distance by 23.8\% and time by 77.4\%. Furthermore, our method requires four fewer hyperparameters and decision variables than the Linear Time-Varying (LTV) MPC approach, making it easier to implement. Real-world experiments are carried out to validate the proposed method with two differential-drive robots, Husky and Boxer, under different friction conditions.
LimeAttack: Local Explainable Method for Textual Hard-Label Adversarial Attack
Aug 01, 2023



Natural language processing models are vulnerable to adversarial examples. Previous textual adversarial attacks adopt gradients or confidence scores to calculate word importance ranking and generate adversarial examples. However, this information is unavailable in the real world. Therefore, we focus on a more realistic and challenging setting, named hard-label attack, in which the attacker can only query the model and obtain a discrete prediction label. Existing hard-label attack algorithms tend to initialize adversarial examples by random substitution and then utilize complex heuristic algorithms to optimize the adversarial perturbation. These methods require a lot of model queries and the attack success rate is restricted by adversary initialization. In this paper, we propose a novel hard-label attack algorithm named LimeAttack, which leverages a local explainable method to approximate word importance ranking, and then adopts beam search to find the optimal solution. Extensive experiments show that LimeAttack achieves the better attacking performance compared with existing hard-label attack under the same query budget. In addition, we evaluate the effectiveness of LimeAttack on large language models, and results indicate that adversarial examples remain a significant threat to large language models. The adversarial examples crafted by LimeAttack are highly transferable and effectively improve model robustness in adversarial training.
BeamAttack: Generating High-quality Textual Adversarial Examples through Beam Search and Mixed Semantic Spaces
Mar 09, 2023



Natural language processing models based on neural networks are vulnerable to adversarial examples. These adversarial examples are imperceptible to human readers but can mislead models to make the wrong predictions. In a black-box setting, attacker can fool the model without knowing model's parameters and architecture. Previous works on word-level attacks widely use single semantic space and greedy search as a search strategy. However, these methods fail to balance the attack success rate, quality of adversarial examples and time consumption. In this paper, we propose BeamAttack, a textual attack algorithm that makes use of mixed semantic spaces and improved beam search to craft high-quality adversarial examples. Extensive experiments demonstrate that BeamAttack can improve attack success rate while saving numerous queries and time, e.g., improving at most 7\% attack success rate than greedy search when attacking the examples from MR dataset. Compared with heuristic search, BeamAttack can save at most 85\% model queries and achieve a competitive attack success rate. The adversarial examples crafted by BeamAttack are highly transferable and can effectively improve model's robustness during adversarial training. Code is available at https://github.com/zhuhai-ustc/beamattack/tree/master
Multi-robot Task Assignment for Aerial Tracking with Viewpoint Constraints
May 31, 2022
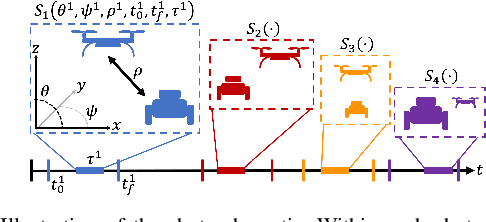
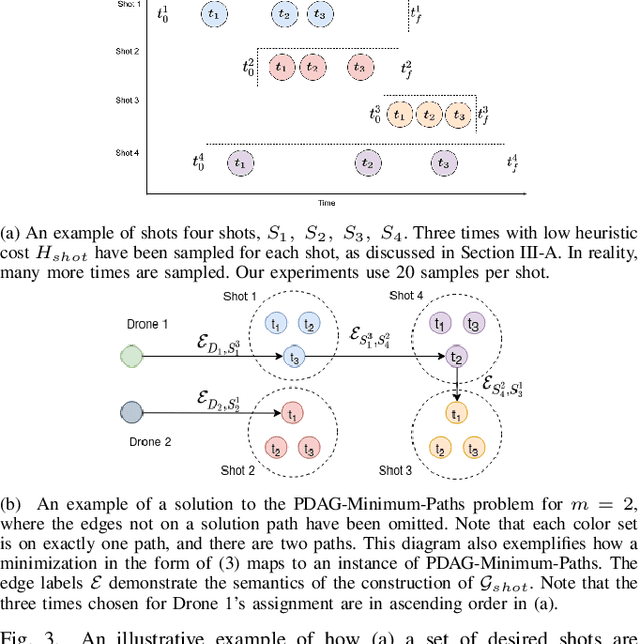
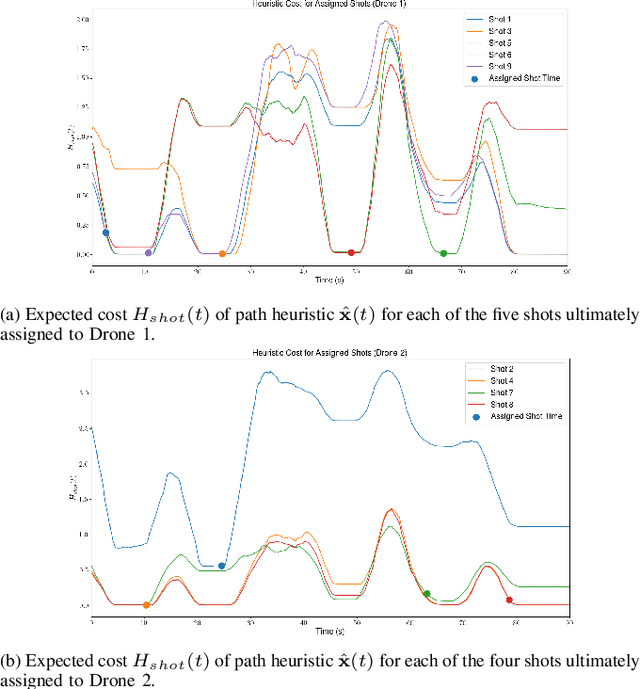
We address the problem of assigning a team of drones to autonomously capture a set desired shots of a dynamic target in the presence of obstacles. We present a two-stage planning pipeline that generates offline an assignment of drone to shots and locally optimizes online the viewpoint. Given desired shot parameters, the high-level planner uses a visibility heuristic to predict good times for capturing each shot and uses an Integer Linear Program to compute drone assignments. An online Model Predictive Control algorithm uses the assignments as reference to capture the shots. The algorithm is validated in hardware with a pair of drones and a remote controlled car.
Improving Pedestrian Prediction Models with Self-Supervised Continual Learning
Feb 15, 2022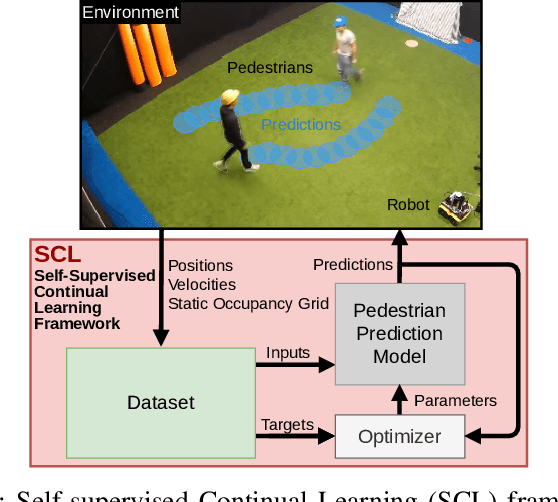
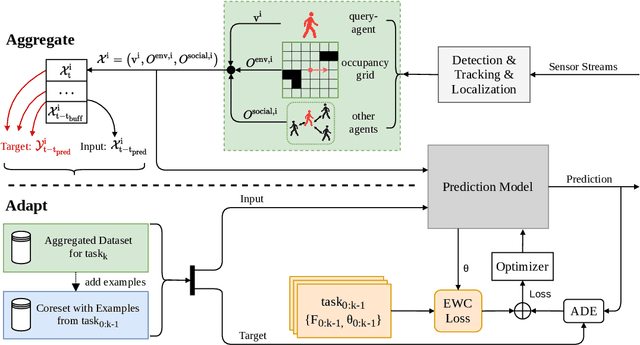
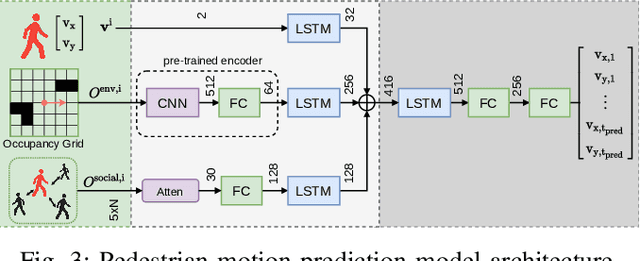
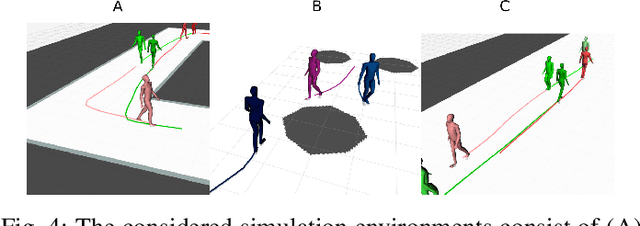
Autonomous mobile robots require accurate human motion predictions to safely and efficiently navigate among pedestrians, whose behavior may adapt to environmental changes. This paper introduces a self-supervised continual learning framework to improve data-driven pedestrian prediction models online across various scenarios continuously. In particular, we exploit online streams of pedestrian data, commonly available from the robot's detection and tracking pipeline, to refine the prediction model and its performance in unseen scenarios. To avoid the forgetting of previously learned concepts, a problem known as catastrophic forgetting, our framework includes a regularization loss to penalize changes of model parameters that are important for previous scenarios and retrains on a set of previous examples to retain past knowledge. Experimental results on real and simulation data show that our approach can improve prediction performance in unseen scenarios while retaining knowledge from seen scenarios when compared to naively training the prediction model online.
Decentralized Probabilistic Multi-Robot Collision Avoidance Using Buffered Uncertainty-Aware Voronoi Cells
Jan 11, 2022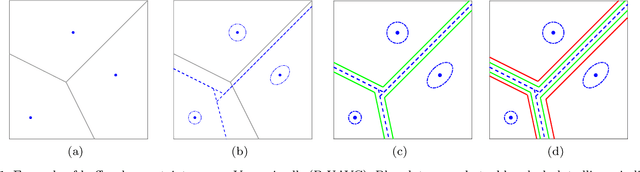
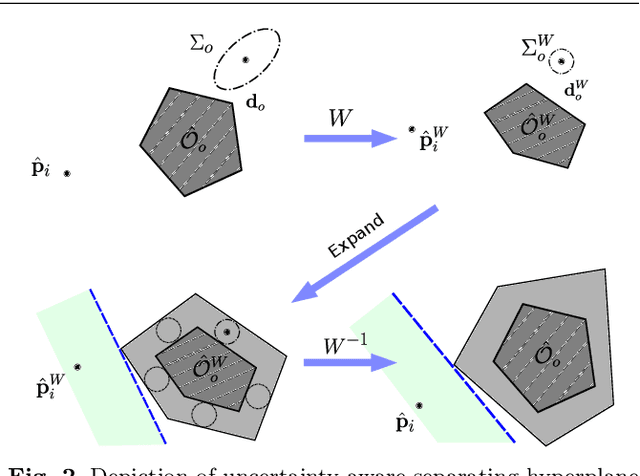
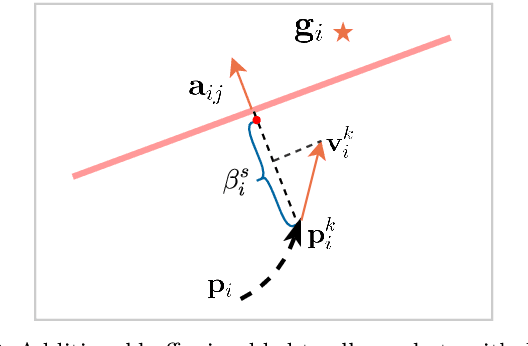
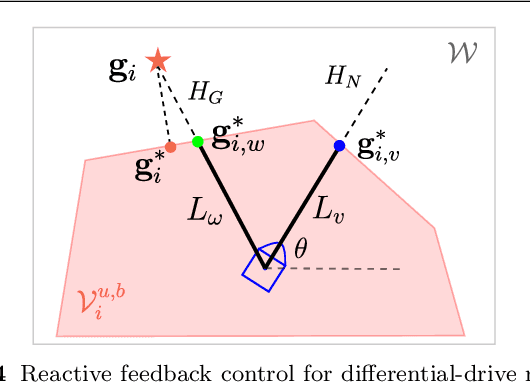
In this paper, we present a decentralized and communication-free collision avoidance approach for multi-robot systems that accounts for both robot localization and sensing uncertainties. The approach relies on the computation of an uncertainty-aware safe region for each robot to navigate among other robots and static obstacles in the environment, under the assumption of Gaussian-distributed uncertainty. In particular, at each time step, we construct a chance-constrained buffered uncertainty-aware Voronoi cell (B-UAVC) for each robot given a specified collision probability threshold. Probabilistic collision avoidance is achieved by constraining the motion of each robot to be within its corresponding B-UAVC, i.e. the collision probability between the robots and obstacles remains below the specified threshold. The proposed approach is decentralized, communication-free, scalable with the number of robots and robust to robots' localization and sensing uncertainties. We applied the approach to single-integrator, double-integrator, differential-drive robots, and robots with general nonlinear dynamics. Extensive simulations and experiments with a team of ground vehicles, quadrotors, and heterogeneous robot teams are performed to analyze and validate the proposed approach.