 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatiotemporal Event Graphs for Dynamic Scene Understanding
Dec 11, 2023
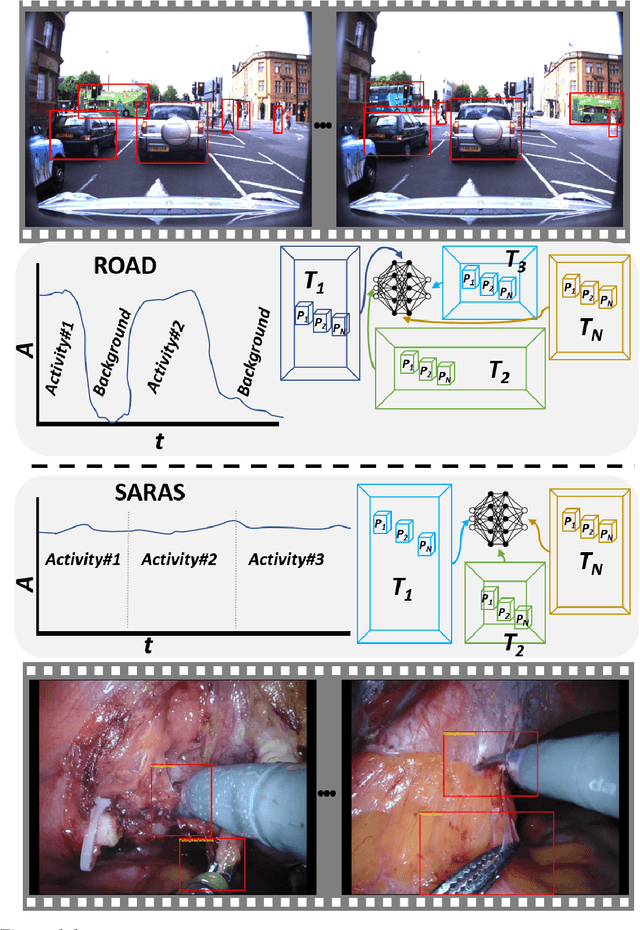
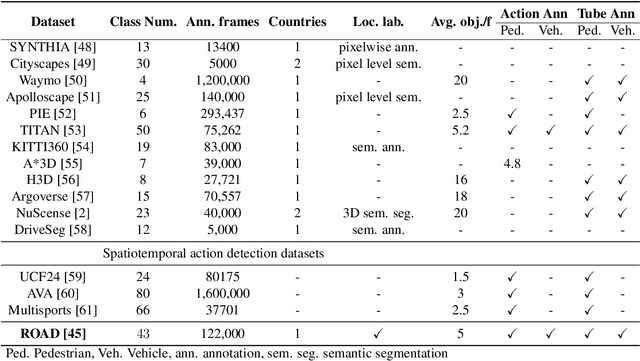
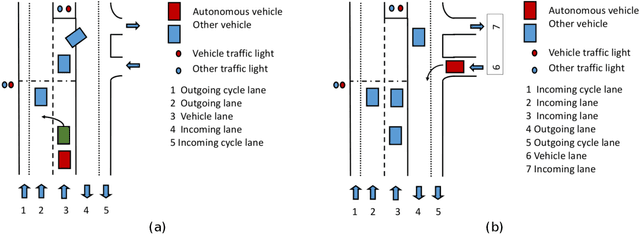
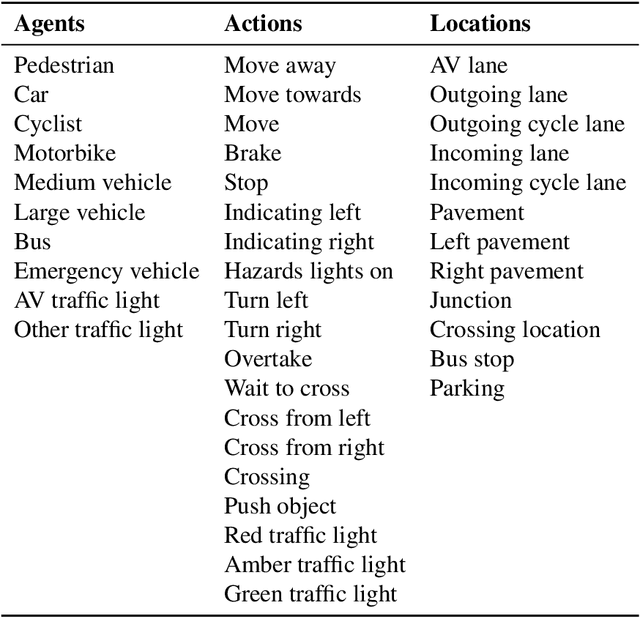
Dynamic scene understanding is the ability of a computer system to interpret and make sense of the visual information present in a video of a real-world scene. In this thesis, we present a series of frameworks for dynamic scene understanding starting from road event detection from an autonomous driving perspective to complex video activity detection, followed by continual learning approaches for the life-long learning of the models. Firstly, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. Due to the lack of datasets equipped with formally specified logical requirements, we also introduce the ROad event Awareness Dataset with logical Requirements (ROAD-R), the first publicly available dataset for autonomous driving with requirements expressed as logical constraints, as a tool for driving neurosymbolic research in the area. Next, we extend event detection to holistic scene understanding by proposing two complex activity detection methods. In the first method, we present a deformable, spatiotemporal scene graph approach, consisting of three main building blocks: action tube detection, a 3D deformable RoI pooling layer designed for learning the flexible, deformable geometry of the constituent action tubes, and a scene graph constructed by considering all parts as nodes and connecting them based on different semantics. In a second approach evolving from the first, we propose a hybrid graph neural network that combines attention applied to a graph encoding of the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Finally, the last part of the thesis is about presenting a new continual semi-supervised learning (CSSL) paradigm.
Benchmarking and Enhancing Disentanglement in Concept-Residual Models
Nov 30, 2023Concept bottleneck models (CBMs) are interpretable models that first predict a set of semantically meaningful features, i.e., concepts, from observations that are subsequently used to condition a downstream task. However, the model's performance strongly depends on the engineered features and can severely suffer from incomplete sets of concepts. Prior works have proposed a side channel -- a residual -- that allows for unconstrained information flow to the downstream task, thus improving model performance but simultaneously introducing information leakage, which is undesirable for interpretability. This work proposes three novel approaches to mitigate information leakage by disentangling concepts and residuals, investigating the critical balance between model performance and interpretability. Through extensive empirical analysis on the CUB, OAI, and CIFAR 100 datasets, we assess the performance of each disentanglement method and provide insights into when they work best. Further, we show how each method impacts the ability to intervene over the concepts and their subsequent impact on task performance.
Learning active tactile perception through belief-space control
Nov 30, 2023Robots operating in an open world will encounter novel objects with unknown physical properties, such as mass, friction, or size. These robots will need to sense these properties through interaction prior to performing downstream tasks with the objects. We propose a method that autonomously learns tactile exploration policies by developing a generative world model that is leveraged to 1) estimate the object's physical parameters using a differentiable Bayesian filtering algorithm and 2) develop an exploration policy using an information-gathering model predictive controller. We evaluate our method on three simulated tasks where the goal is to estimate a desired object property (mass, height or toppling height) through physical interaction. We find that our method is able to discover policies that efficiently gather information about the desired property in an intuitive manner. Finally, we validate our method on a real robot system for the height estimation task, where our method is able to successfully learn and execute an information-gathering policy from scratch.
Flood Event Extraction from News Media to Support Satellite-Based Flood Insurance
Dec 05, 2023Floods cause large losses to property, life, and livelihoods across the world every year, hindering sustainable development. Safety nets to help absorb financial shocks in disasters, such as insurance, are often unavailable in regions of the world most vulnerable to floods, like Bangladesh. Index-based insurance has emerged as an affordable solution, which considers weather data or information from satellites to create a "flood index" that should correlate with the damage insured. However, existing flood event databases are often incomplete, and satellite sensors are not reliable under extreme weather conditions (e.g., because of clouds), which limits the spatial and temporal resolution of current approaches for index-based insurance. In this work, we explore a novel approach for supporting satellite-based flood index insurance by extracting high-resolution spatio-temporal information from news media. First, we publish a dataset consisting of 40,000 news articles covering flood events in Bangladesh by 10 prominent news sources, and inundated area estimates for each division in Bangladesh collected from a satellite radar sensor. Second, we show that keyword-based models are not adequate for this novel application, while context-based classifiers cover complex and implicit flood related patterns. Third, we show that time series extracted from news media have substantial correlation Spearman's rho$=0.70 with satellite estimates of inundated area. Our work demonstrates that news media is a promising source for improving the temporal resolution and expanding the spatial coverage of the available flood damage data.
Combining Counting Processes and Classification Improves a Stopping Rule for Technology Assisted Review
Dec 05, 2023Technology Assisted Review (TAR) stopping rules aim to reduce the cost of manually assessing documents for relevance by minimising the number of documents that need to be examined to ensure a desired level of recall. This paper extends an effective stopping rule using information derived from a text classifier that can be trained without the need for any additional annotation. Experiments on multiple data sets (CLEF e-Health, TREC Total Recall, TREC Legal and RCV1) showed that the proposed approach consistently improves performance and outperforms several alternative methods.
Integrated Drill Boom Hole-Seeking Control via Reinforcement Learning
Dec 04, 2023Intelligent drill boom hole-seeking is a promising technology for enhancing drilling efficiency, mitigating potential safety hazards, and relieving human operators. Most existing intelligent drill boom control methods rely on a hierarchical control framework based on inverse kinematics. However, these methods are generally time-consuming due to the computational complexity of inverse kinematics and the inefficiency of the sequential execution of multiple joints. To tackle these challenges, this study proposes an integrated drill boom control method based on Reinforcement Learning (RL). We develop an integrated drill boom control framework that utilizes a parameterized policy to directly generate control inputs for all joints at each time step, taking advantage of joint posture and target hole information. By formulating the hole-seeking task as a Markov decision process, contemporary mainstream RL algorithms can be directly employed to learn a hole-seeking policy, thus eliminating the need for inverse kinematics solutions and promoting cooperative multi-joint control. To enhance the drilling accuracy throughout the entire drilling process, we devise a state representation that combines Denavit-Hartenberg joint information and preview hole-seeking discrepancy data. Simulation results show that the proposed method significantly outperforms traditional methods in terms of hole-seeking accuracy and time efficiency.
BioCLIP: A Vision Foundation Model for the Tree of Life
Dec 04, 2023

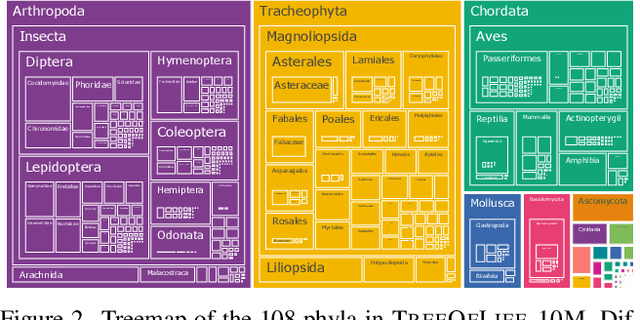

Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
Phonetic-aware speaker embedding for far-field speaker verification
Nov 27, 2023When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
Cycle Invariant Positional Encoding for Graph Representation Learning
Nov 30, 2023Cycles are fundamental elements in graph-structured data and have demonstrated their effectiveness in enhancing graph learning models. To encode such information into a graph learning framework, prior works often extract a summary quantity, ranging from the number of cycles to the more sophisticated persistence diagram summaries. However, more detailed information, such as which edges are encoded in a cycle, has not yet been used in graph neural networks. In this paper, we make one step towards addressing this gap, and propose a structure encoding module, called CycleNet, that encodes cycle information via edge structure encoding in a permutation invariant manner. To efficiently encode the space of all cycles, we start with a cycle basis (i.e., a minimal set of cycles generating the cycle space) which we compute via the kernel of the 1-dimensional Hodge Laplacian of the input graph. To guarantee the encoding is invariant w.r.t. the choice of cycle basis, we encode the cycle information via the orthogonal projector of the cycle basis, which is inspired by BasisNet proposed by Lim et al. We also develop a more efficient variant which however requires that the input graph has a unique shortest cycle basis. To demonstrate the effectiveness of the proposed module, we provide some theoretical understandings of its expressive power. Moreover, we show via a range of experiments that networks enhanced by our CycleNet module perform better in various benchmarks compared to several existing SOTA models.