 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
Oct 08, 2024



Existing perception models achieve great success by learning from large amounts of labeled data, but they still struggle with open-world scenarios. To alleviate this issue, researchers introduce open-set perception tasks to detect or segment unseen objects in the training set. However, these models require predefined object categories as inputs during inference, which are not available in real-world scenarios. Recently, researchers pose a new and more practical problem, \textit{i.e.}, open-ended object detection, which discovers unseen objects without any object categories as inputs. In this paper, we present VL-SAM, a training-free framework that combines the generalized object recognition model (\textit{i.e.,} Vision-Language Model) with the generalized object localization model (\textit{i.e.,} Segment-Anything Model), to address the open-ended object detection and segmentation task. Without additional training, we connect these two generalized models with attention maps as the prompts. Specifically, we design an attention map generation module by employing head aggregation and a regularized attention flow to aggregate and propagate attention maps across all heads and layers in VLM, yielding high-quality attention maps. Then, we iteratively sample positive and negative points from the attention maps with a prompt generation module and send the sampled points to SAM to segment corresponding objects. Experimental results on the long-tail instance segmentation dataset (LVIS) show that our method surpasses the previous open-ended method on the object detection task and can provide additional instance segmentation masks. Besides, VL-SAM achieves favorable performance on the corner case object detection dataset (CODA), demonstrating the effectiveness of VL-SAM in real-world applications. Moreover, VL-SAM exhibits good model generalization that can incorporate various VLMs and SAMs.
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Aug 30, 2024



The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.
Vote&Mix: Plug-and-Play Token Reduction for Efficient Vision Transformer
Aug 30, 2024



Despite the remarkable success of Vision Transformers (ViTs) in various visual tasks, they are often hindered by substantial computational cost. In this work, we introduce Vote\&Mix (\textbf{VoMix}), a plug-and-play and parameter-free token reduction method, which can be readily applied to off-the-shelf ViT models \textit{without any training}. VoMix tackles the computational redundancy of ViTs by identifying tokens with high homogeneity through a layer-wise token similarity voting mechanism. Subsequently, the selected tokens are mixed into the retained set, thereby preserving visual information. Experiments demonstrate VoMix significantly improves the speed-accuracy tradeoff of ViTs on both images and videos. Without any training, VoMix achieves a 2$\times$ increase in throughput of existing ViT-H on ImageNet-1K and a 2.4$\times$ increase in throughput of existing ViT-L on Kinetics-400 video dataset, with a mere 0.3\% drop in top-1 accuracy.
Cycle Invariant Positional Encoding for Graph Representation Learning
Nov 30, 2023



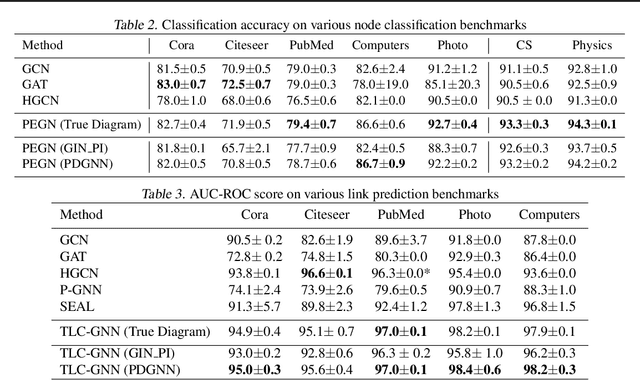
Cycles are fundamental elements in graph-structured data and have demonstrated their effectiveness in enhancing graph learning models. To encode such information into a graph learning framework, prior works often extract a summary quantity, ranging from the number of cycles to the more sophisticated persistence diagram summaries. However, more detailed information, such as which edges are encoded in a cycle, has not yet been used in graph neural networks. In this paper, we make one step towards addressing this gap, and propose a structure encoding module, called CycleNet, that encodes cycle information via edge structure encoding in a permutation invariant manner. To efficiently encode the space of all cycles, we start with a cycle basis (i.e., a minimal set of cycles generating the cycle space) which we compute via the kernel of the 1-dimensional Hodge Laplacian of the input graph. To guarantee the encoding is invariant w.r.t. the choice of cycle basis, we encode the cycle information via the orthogonal projector of the cycle basis, which is inspired by BasisNet proposed by Lim et al. We also develop a more efficient variant which however requires that the input graph has a unique shortest cycle basis. To demonstrate the effectiveness of the proposed module, we provide some theoretical understandings of its expressive power. Moreover, we show via a range of experiments that networks enhanced by our CycleNet module perform better in various benchmarks compared to several existing SOTA models.
Recognition-Guided Diffusion Model for Scene Text Image Super-Resolution
Nov 22, 2023Scene Text Image Super-Resolution (STISR) aims to enhance the resolution and legibility of text within low-resolution (LR) images, consequently elevating recognition accuracy in Scene Text Recognition (STR). Previous methods predominantly employ discriminative Convolutional Neural Networks (CNNs) augmented with diverse forms of text guidance to address this issue. Nevertheless, they remain deficient when confronted with severely blurred images, due to their insufficient generation capability when little structural or semantic information can be extracted from original images. Therefore, we introduce RGDiffSR, a Recognition-Guided Diffusion model for scene text image Super-Resolution, which exhibits great generative diversity and fidelity even in challenging scenarios. Moreover, we propose a Recognition-Guided Denoising Network, to guide the diffusion model generating LR-consistent results through succinct semantic guidance. Experiments on the TextZoom dataset demonstrate the superiority of RGDiffSR over prior state-of-the-art methods in both text recognition accuracy and image fidelity.
Efficiently Counting Substructures by Subgraph GNNs without Running GNN on Subgraphs
Mar 19, 2023



Using graph neural networks (GNNs) to approximate specific functions such as counting graph substructures is a recent trend in graph learning. Among these works, a popular way is to use subgraph GNNs, which decompose the input graph into a collection of subgraphs and enhance the representation of the graph by applying GNN to individual subgraphs. Although subgraph GNNs are able to count complicated substructures, they suffer from high computational and memory costs. In this paper, we address a non-trivial question: can we count substructures efficiently with GNNs? To answer the question, we first theoretically show that the distance to the rooted nodes within subgraphs is key to boosting the counting power of subgraph GNNs. We then encode such information into structural embeddings, and precompute the embeddings to avoid extracting information over all subgraphs via GNNs repeatedly. Experiments on various benchmarks show that the proposed model can preserve the counting power of subgraph GNNs while running orders of magnitude faster.
FlowNAS: Neural Architecture Search for Optical Flow Estimation
Jul 04, 2022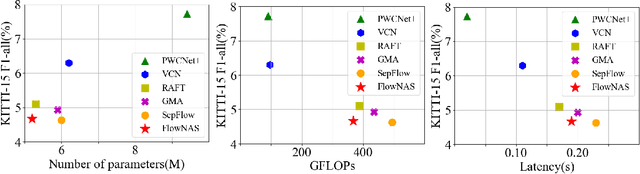
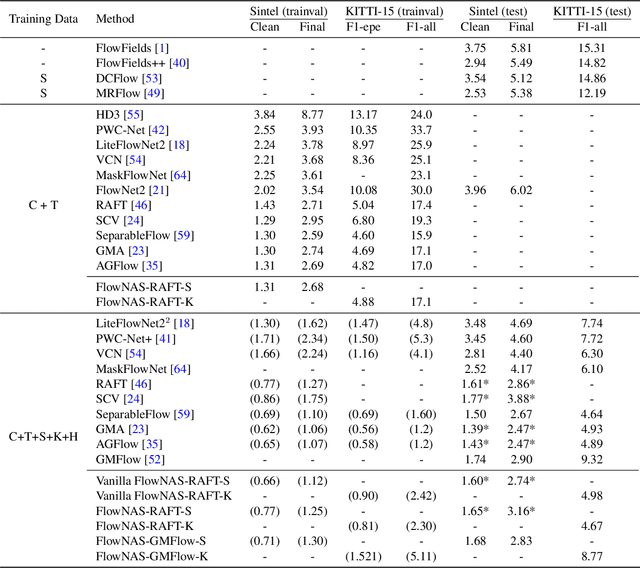
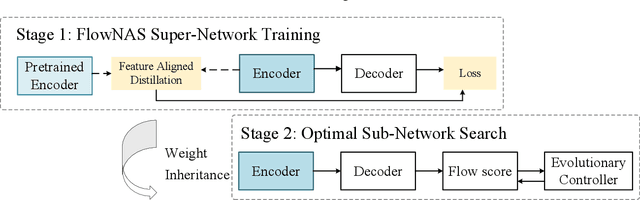
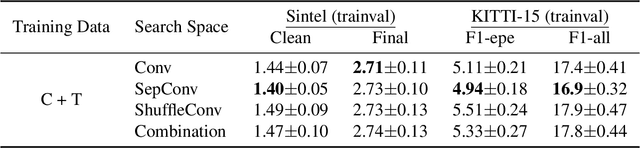
Existing optical flow estimators usually employ the network architectures typically designed for image classification as the encoder to extract per-pixel features. However, due to the natural difference between the tasks, the architectures designed for image classification may be sub-optimal for flow estimation. To address this issue, we propose a neural architecture search method named FlowNAS to automatically find the better encoder architecture for flow estimation task. We first design a suitable search space including various convolutional operators and construct a weight-sharing super-network for efficiently evaluating the candidate architectures. Then, for better training the super-network, we propose Feature Alignment Distillation, which utilizes a well-trained flow estimator to guide the training of super-network. Finally, a resource-constrained evolutionary algorithm is exploited to find an optimal architecture (i.e., sub-network). Experimental results show that the discovered architecture with the weights inherited from the super-network achieves 4.67\% F1-all error on KITTI, an 8.4\% reduction of RAFT baseline, surpassing state-of-the-art handcrafted models GMA and AGFlow, while reducing the model complexity and latency. The source code and trained models will be released in https://github.com/VDIGPKU/FlowNAS.
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022

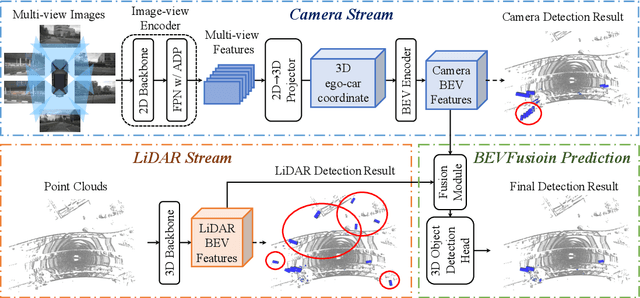
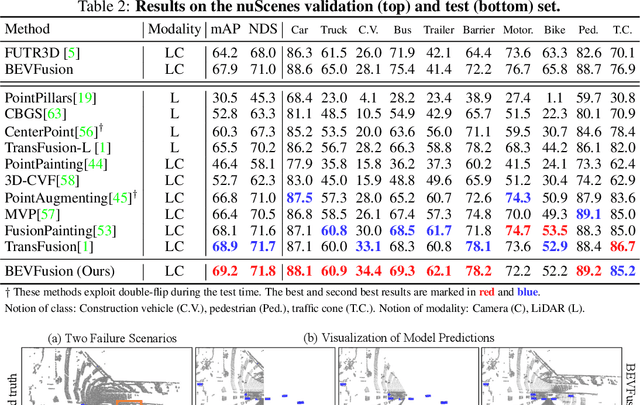
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
Neural Approximation of Extended Persistent Homology on Graphs
Jan 28, 2022

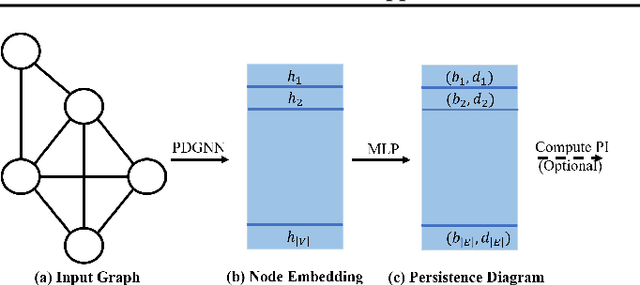
Persistent homology is a widely used theory in topological data analysis. In the context of graph learning, topological features based on persistent homology have been used to capture potentially high-order structural information so as to augment existing graph neural network methods. However, computing extended persistent homology summaries remains slow for large and dense graphs, especially since in learning applications one has to carry out this computation potentially many times. Inspired by recent success in neural algorithmic reasoning, we propose a novel learning method to compute extended persistence diagrams on graphs. The proposed neural network aims to simulate a specific algorithm and learns to compute extended persistence diagrams for new graphs efficiently. Experiments on approximating extended persistence diagrams and several downstream graph representation learning tasks demonstrate the effectiveness of our method. Our method is also efficient; on large and dense graphs, we accelerate the computation by nearly 100 times.
A Topological View of Rule Learning in Knowledge Graphs
Oct 06, 2021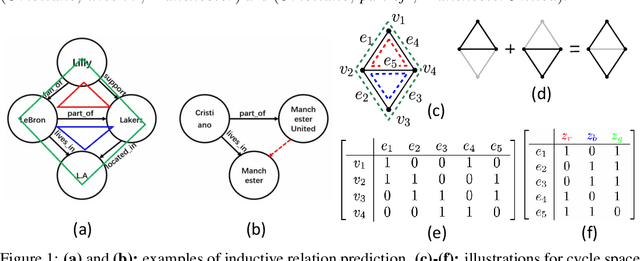
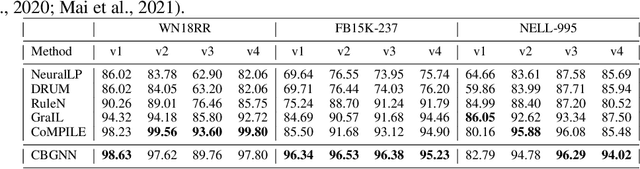
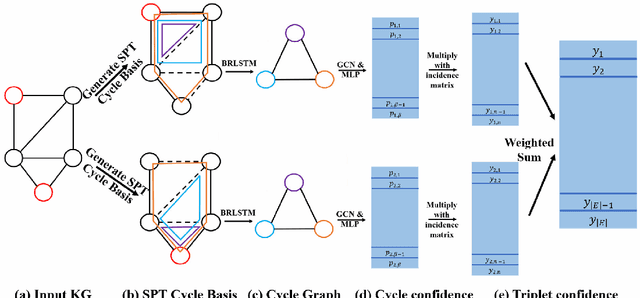
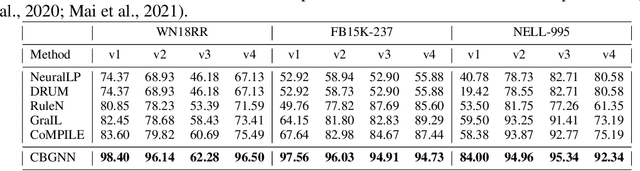
Inductive relation prediction is an important learning task for knowledge graph completion. One can use the existence of rules, namely a sequence of relations, to predict the relation between two entities. Previous works view rules as paths and primarily focus on the searching of paths between entities. The space of paths is huge, and one has to sacrifice either efficiency or accuracy. In this paper, we consider rules in knowledge graphs as cycles and show that the space of cycles has a unique structure based on the theory of algebraic topology. By exploring the linear structure of the cycle space, we can improve the searching efficiency of rules. We propose to collect cycle bases that span the space of cycles. We build a novel GNN framework on the collected cycles to learn the representations of cycles, and to predict the existence/non-existence of a relation. Our method achieves state-of-the-art performance on benchmarks.