 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021
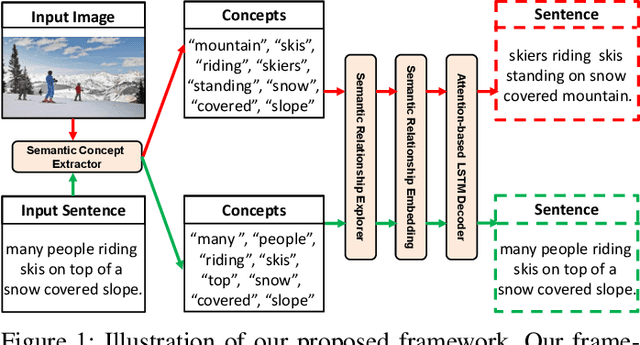
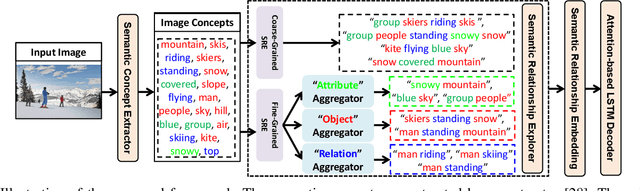
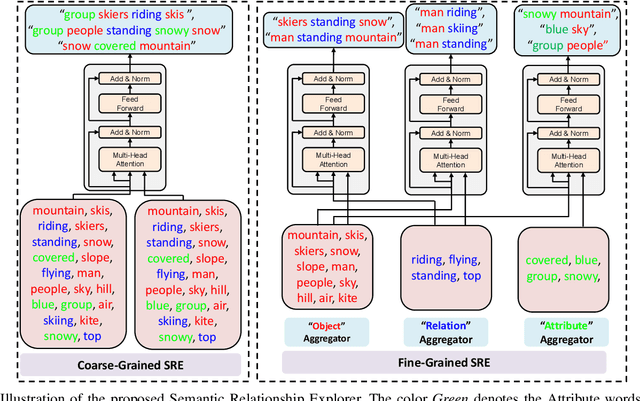

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.
Under the Hood: Using Diagnostic Classifiers to Investigate and Improve how Language Models Track Agreement Information
Sep 07, 2018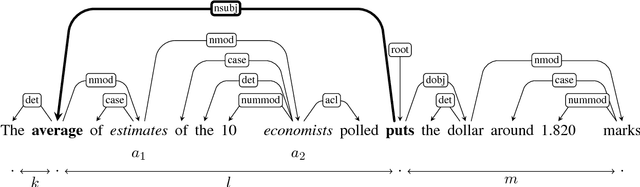


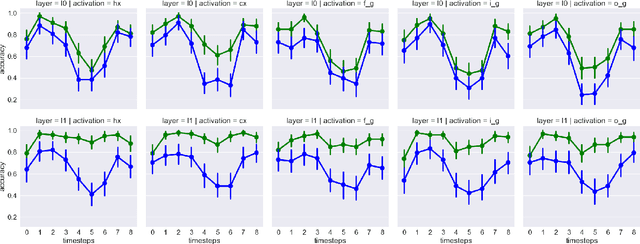
How do neural language models keep track of number agreement between subject and verb? We show that `diagnostic classifiers', trained to predict number from the internal states of a language model, provide a detailed understanding of how, when, and where this information is represented. Moreover, they give us insight into when and where number information is corrupted in cases where the language model ends up making agreement errors. To demonstrate the causal role played by the representations we find, we then use agreement information to influence the course of the LSTM during the processing of difficult sentences. Results from such an intervention reveal a large increase in the language model's accuracy. Together, these results show that diagnostic classifiers give us an unrivalled detailed look into the representation of linguistic information in neural models, and demonstrate that this knowledge can be used to improve their performance.
Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation
Jul 04, 2021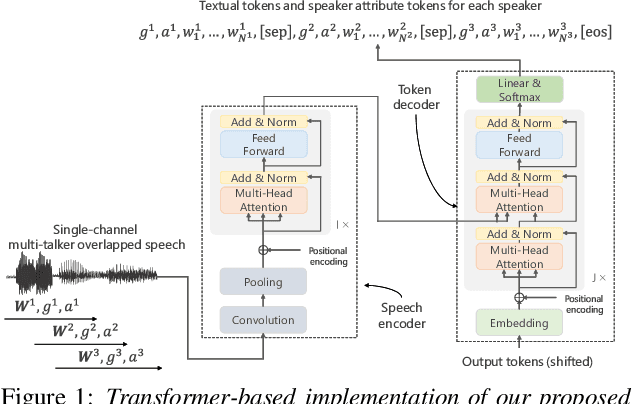
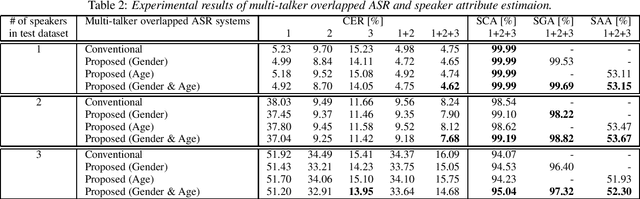
In this paper, we present a novel modeling method for single-channel multi-talker overlapped automatic speech recognition (ASR) systems. Fully neural network based end-to-end models have dramatically improved the performance of multi-taker overlapped ASR tasks. One promising approach for end-to-end modeling is autoregressive modeling with serialized output training in which transcriptions of multiple speakers are recursively generated one after another. This enables us to naturally capture relationships between speakers. However, the conventional modeling method cannot explicitly take into account the speaker attributes of individual utterances such as gender and age information. In fact, the performance deteriorates when each speaker is the same gender or is close in age. To address this problem, we propose unified autoregressive modeling for joint end-to-end multi-talker overlapped ASR and speaker attribute estimation. Our key idea is to handle gender and age estimation tasks within the unified autoregressive modeling. In the proposed method, transformer-based autoregressive model recursively generates not only textual tokens but also attribute tokens of each speaker. This enables us to effectively utilize speaker attributes for improving multi-talker overlapped ASR. Experiments on Japanese multi-talker overlapped ASR tasks demonstrate the effectiveness of the proposed method.
SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images
Jul 04, 2021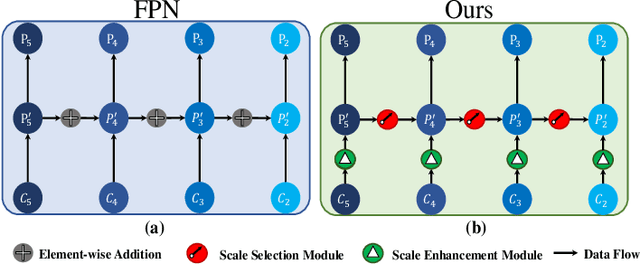
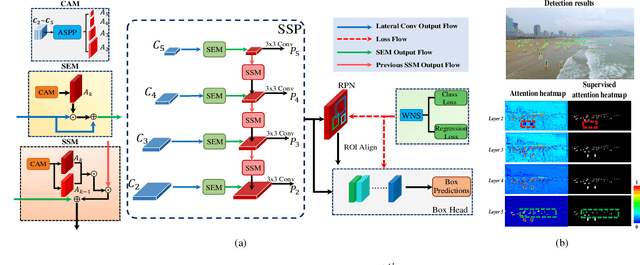

With the increasing demand for search and rescue, it is highly demanded to detect objects of interest in large-scale images captured by Unmanned Aerial Vehicles (UAVs), which is quite challenging due to extremely small scales of objects. Most existing methods employed Feature Pyramid Network (FPN) to enrich shallow layers' features by combing deep layers' contextual features. However, under the limitation of the inconsistency in gradient computation across different layers, the shallow layers in FPN are not fully exploited to detect tiny objects. In this paper, we propose a Scale Selection Pyramid network (SSPNet) for tiny person detection, which consists of three components: Context Attention Module (CAM), Scale Enhancement Module (SEM), and Scale Selection Module (SSM). CAM takes account of context information to produce hierarchical attention heatmaps. SEM highlights features of specific scales at different layers, leading the detector to focus on objects of specific scales instead of vast backgrounds. SSM exploits adjacent layers' relationships to fulfill suitable feature sharing between deep layers and shallow layers, thereby avoiding the inconsistency in gradient computation across different layers. Besides, we propose a Weighted Negative Sampling (WNS) strategy to guide the detector to select more representative samples. Experiments on the TinyPerson benchmark show that our method outperforms other state-of-the-art (SOTA) detectors.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Jul 16, 2021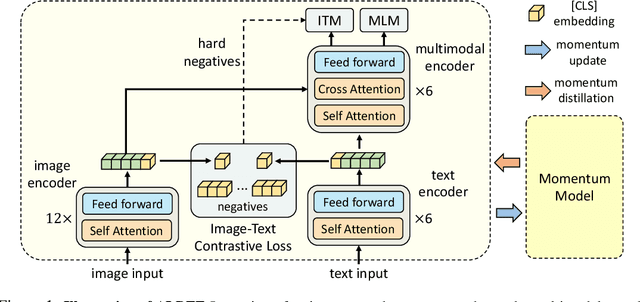
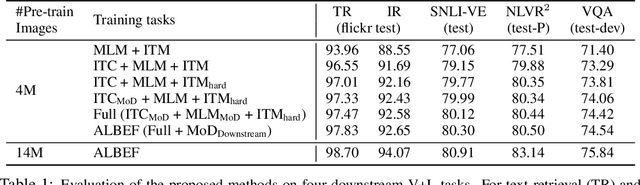

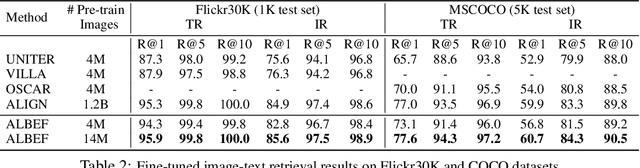
Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and word tokens. Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. In order to improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair. ALBEF achieves state-of-the-art performance on multiple downstream vision-language tasks. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets. On VQA and NLVR$^2$, ALBEF achieves absolute improvements of 2.37% and 3.84% compared to the state-of-the-art, while enjoying faster inference speed. Code and pre-trained models are available at https://github.com/salesforce/ALBEF/.
Defending Democracy: Using Deep Learning to Identify and Prevent Misinformation
Jun 03, 2021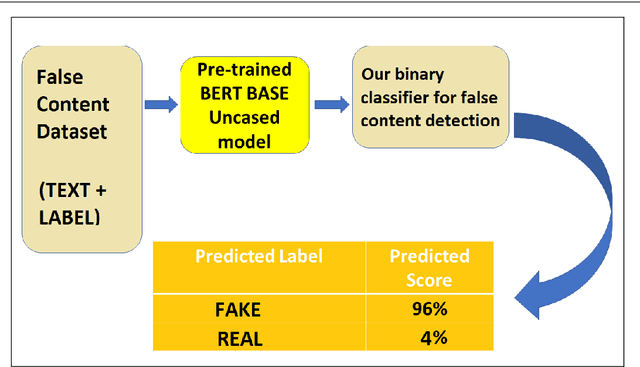
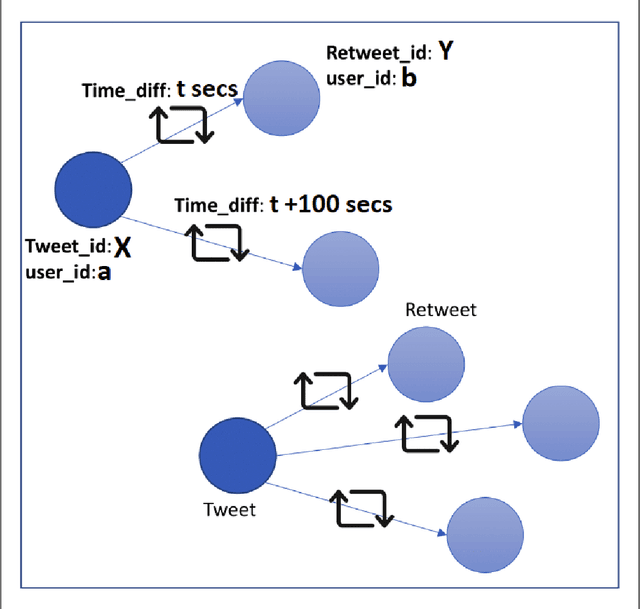
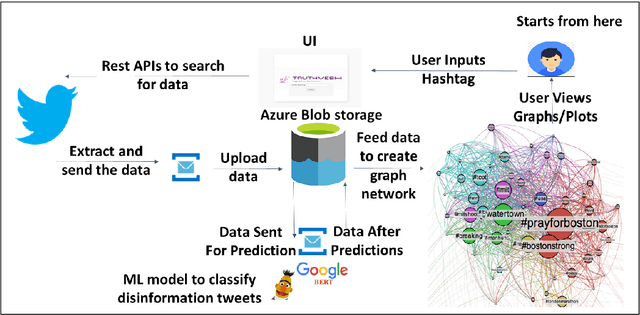
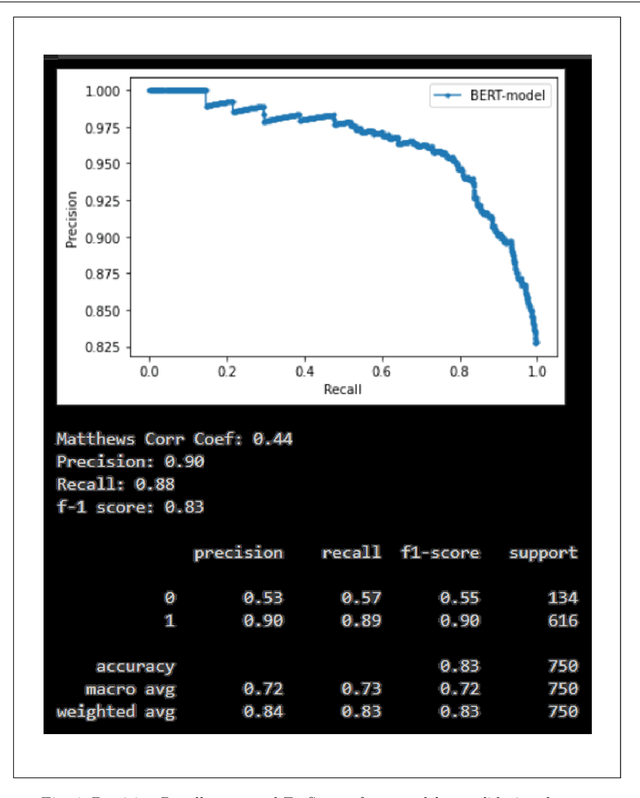
The rise in online misinformation in recent years threatens democracies by distorting authentic public discourse and causing confusion, fear, and even, in extreme cases, violence. There is a need to understand the spread of false content through online networks for developing interventions that disrupt misinformation before it achieves virality. Using a Deep Bidirectional Transformer for Language Understanding (BERT) and propagation graphs, this study classifies and visualizes the spread of misinformation on a social media network using publicly available Twitter data. The results confirm prior research around user clusters and the virality of false content while improving the precision of deep learning models for misinformation detection. The study further demonstrates the suitability of BERT for providing a scalable model for false information detection, which can contribute to the development of more timely and accurate interventions to slow the spread of misinformation in online environments.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observation
Jan 06, 2021
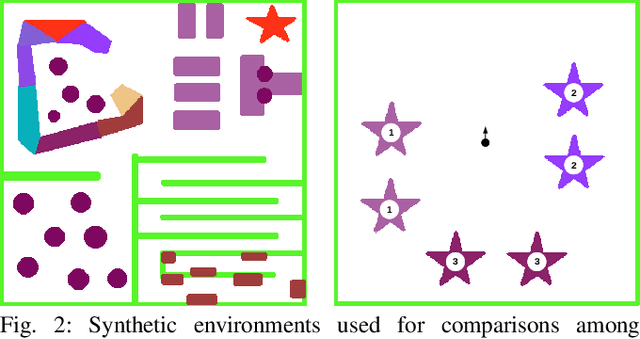
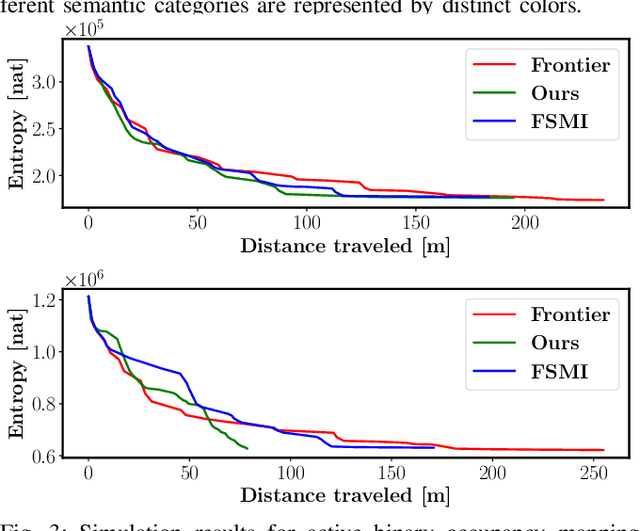
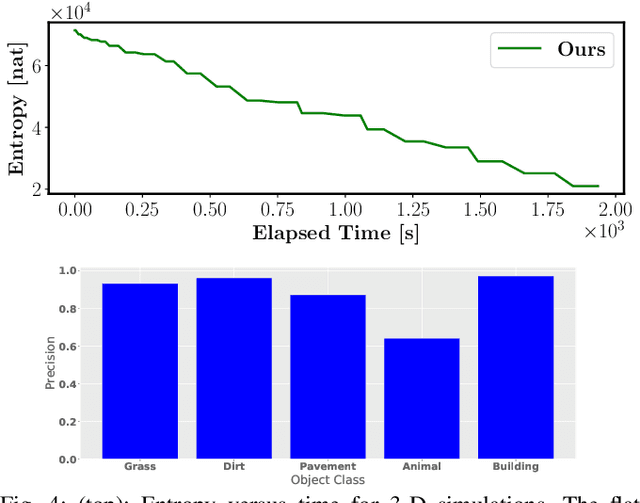
Many robot applications call for autonomous exploration and mapping of unknown and unstructured environments. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. This work develops a Bayesian multi-class mapping algorithm utilizing range-category measurements. We derive a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. We compare our method against frontier-based and FSMI exploration and apply it in a 3-D photo-realistic simulation environment.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021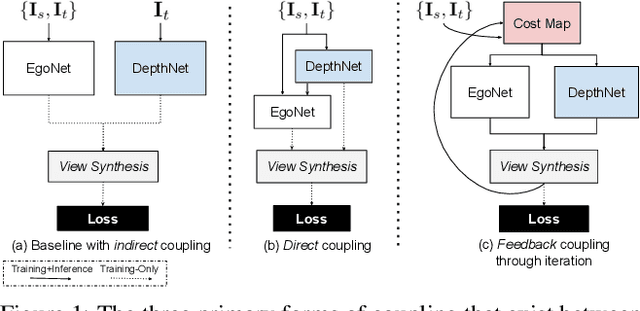
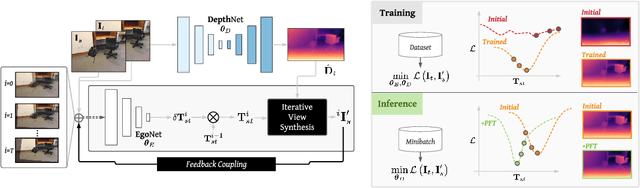
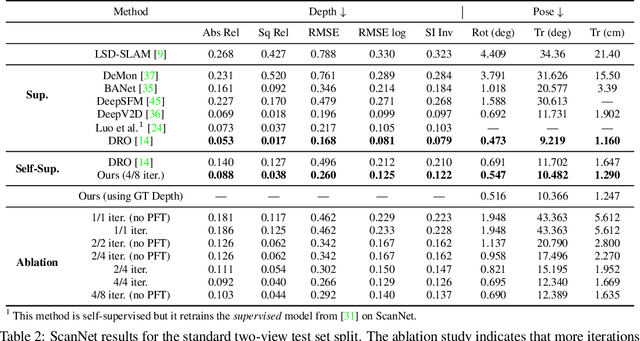

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
Expressivity of Emergent Language is a Trade-off between Contextual Complexity and Unpredictability
Jun 07, 2021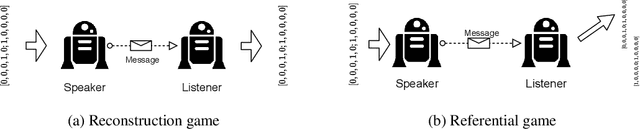

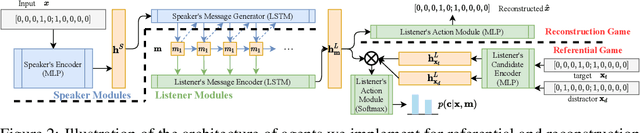
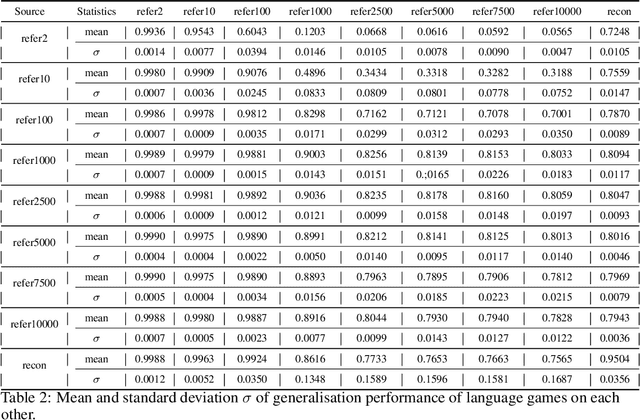
Researchers are now using deep learning models to explore the emergence of language in various language games, where simulated agents interact and develop an emergent language to solve a task. Although it is quite intuitive that different types of language games posing different communicative challenges might require emergent languages which encode different levels of information, there is no existing work exploring the expressivity of the emergent languages. In this work, we propose a definition of partial order between expressivity based on the generalisation performance across different language games. We also validate the hypothesis that expressivity of emergent languages is a trade-off between the complexity and unpredictability of the context those languages are used in. Our second novel contribution is introducing contrastive loss into the implementation of referential games. We show that using our contrastive loss alleviates the collapse of message types seen using standard referential loss functions.
Heterogeneous Multi-task Learning with Expert Diversity
Jun 20, 2021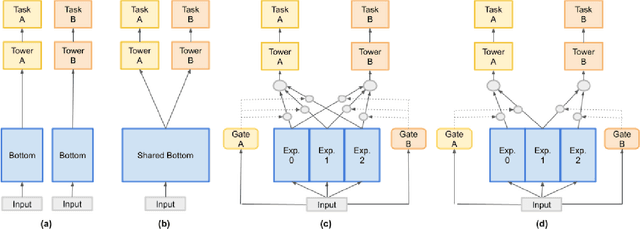
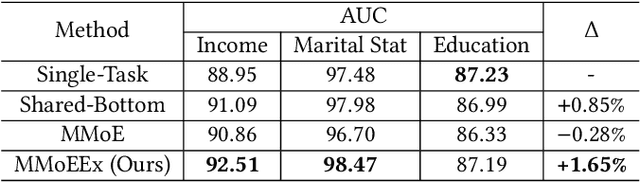
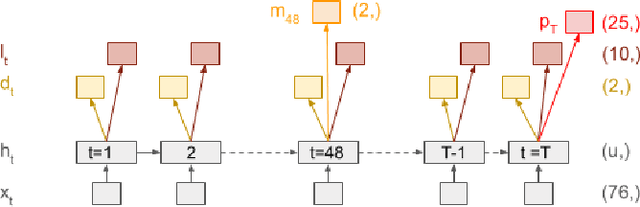
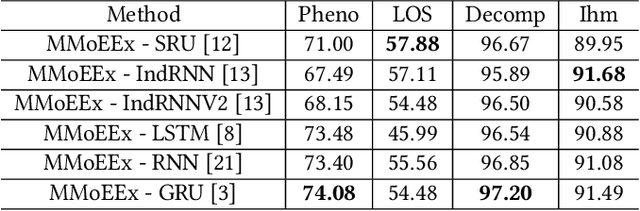
Predicting multiple heterogeneous biological and medical targets is a challenge for traditional deep learning models. In contrast to single-task learning, in which a separate model is trained for each target, multi-task learning (MTL) optimizes a single model to predict multiple related targets simultaneously. To address this challenge, we propose the Multi-gate Mixture-of-Experts with Exclusivity (MMoEEx). Our work aims to tackle the heterogeneous MTL setting, in which the same model optimizes multiple tasks with different characteristics. Such a scenario can overwhelm current MTL approaches due to the challenges in balancing shared and task-specific representations and the need to optimize tasks with competing optimization paths. Our method makes two key contributions: first, we introduce an approach to induce more diversity among experts, thus creating representations more suitable for highly imbalanced and heterogenous MTL learning; second, we adopt a two-step optimization [6, 11] approach to balancing the tasks at the gradient level. We validate our method on three MTL benchmark datasets, including Medical Information Mart for Intensive Care (MIMIC-III) and PubChem BioAssay (PCBA).