 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Iteration for Distance-Geometric Inverse Kinematics
Sep 08, 2021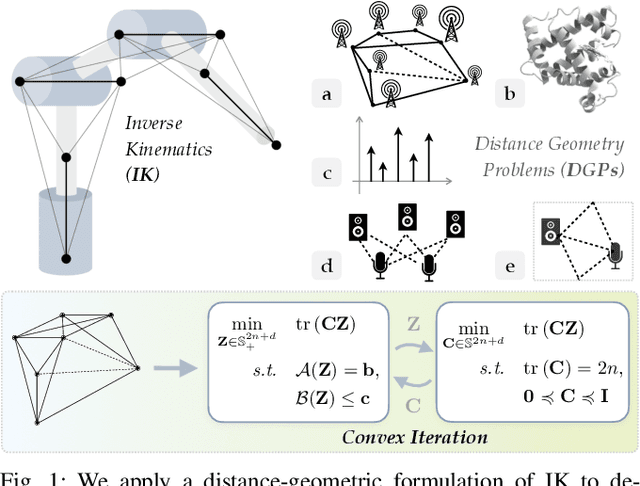
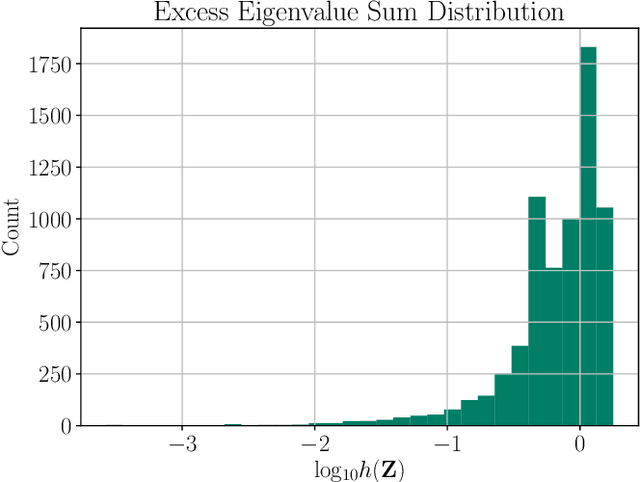
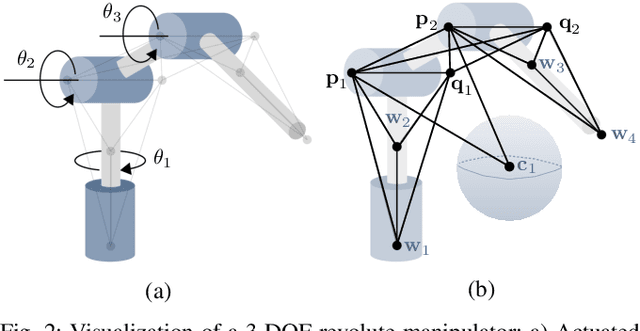
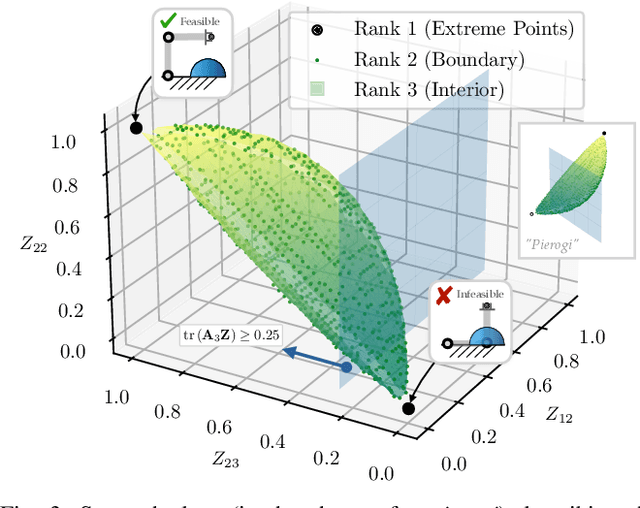
Inverse kinematics (IK) is the problem of finding robot joint configurations that satisfy constraints on the position or pose of one or more end-effectors. For robots with redundant degrees of freedom, there is often an infinite, nonconvex set of solutions. The IK problem is further complicated when collision avoidance constraints are imposed by obstacles in the workspace. In general, closed-form expressions yielding feasible configurations do not exist, motivating the use of numerical solution methods. However, these approaches rely on local optimization of nonconvex problems, often requiring an accurate initialization or numerous re-initializations to converge to a valid solution. In this work, we first formulate complicated inverse kinematics problems as convex feasibility problems whose low-rank feasible points provide exact IK solutions. We then present CIDGIK (Convex Iteration for Distance-Geometric Inverse Kinematics), an algorithm that solves these feasibility problems with a sequence of semidefinite programs whose objectives are designed to encourage low-rank minimizers. Our problem formulation elegantly unifies the configuration space and workspace constraints of a robot: intrinsic robot geometry and obstacle avoidance are both expressed as simple linear matrix equations and inequalities. Our experimental results for a variety of popular manipulator models demonstrate faster and more accurate convergence than a conventional nonlinear optimization-based approach, especially in environments with many obstacles.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021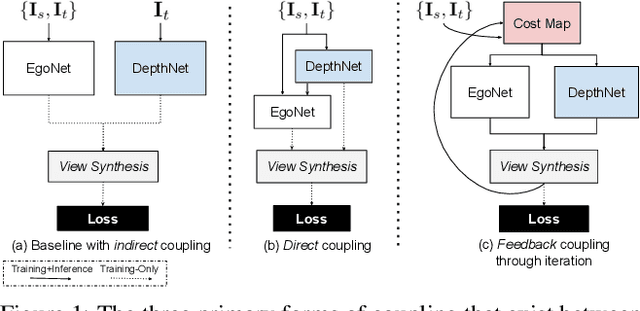
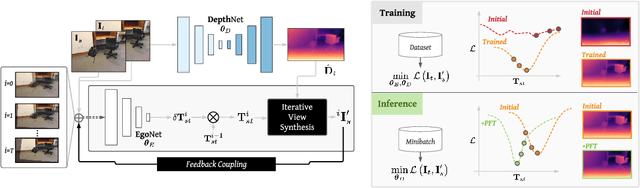
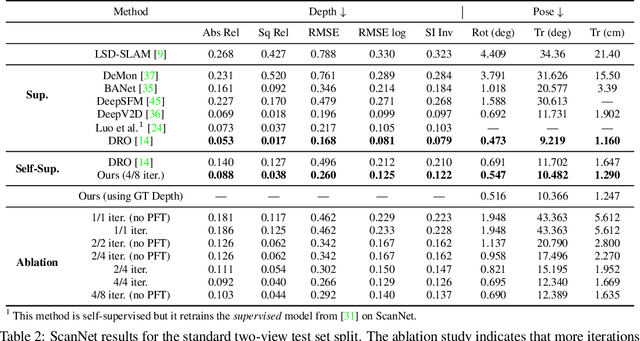

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
A Smooth Representation of Belief over SO for Deep Rotation Learning with Uncertainty
Jun 17, 2020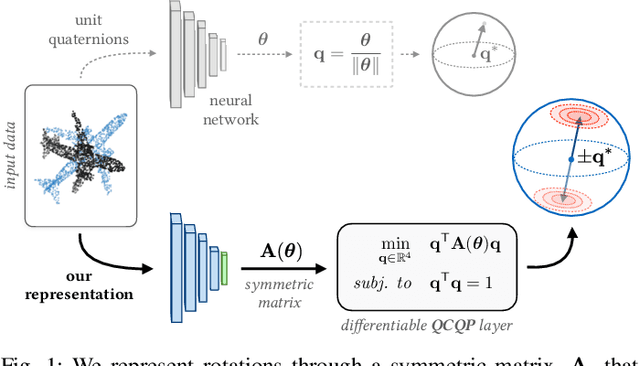

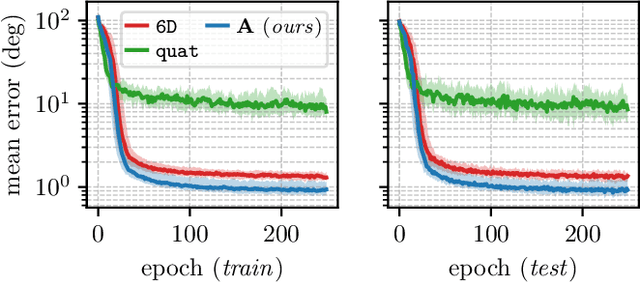
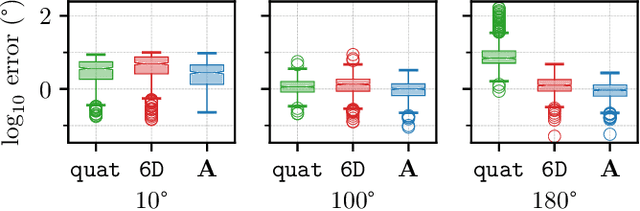
Accurate rotation estimation is at the heart of robot perception tasks such as visual odometry and object pose estimation. Deep neural networks have provided a new way to perform these tasks, and the choice of rotation representation is an important part of network design. In this work, we present a novel symmetric matrix representation of the 3D rotation group, SO(3), with two important properties that make it particularly suitable for learned models: (1) it satisfies a smoothness property that improves convergence and generalization when regressing large rotation targets, and (2) it encodes a symmetric Bingham belief over the space of unit quaternions, permitting the training of uncertainty-aware models. We empirically validate the benefits of our formulation by training deep neural rotation regressors on two data modalities. First, we use synthetic point-cloud data to show that our representation leads to superior predictive accuracy over existing representations for arbitrary rotation targets. Second, we use image data collected onboard ground and aerial vehicles to demonstrate that our representation is amenable to an effective out-of-distribution (OOD) rejection technique that significantly improves the robustness of rotation estimates to unseen environmental effects and corrupted input images, without requiring the use of an explicit likelihood loss, stochastic sampling, or an auxiliary classifier. This capability is key for safety-critical applications where detecting novel inputs can prevent catastrophic failure of learned models.
Self-Supervised Deep Pose Corrections for Robust Visual Odometry
Feb 27, 2020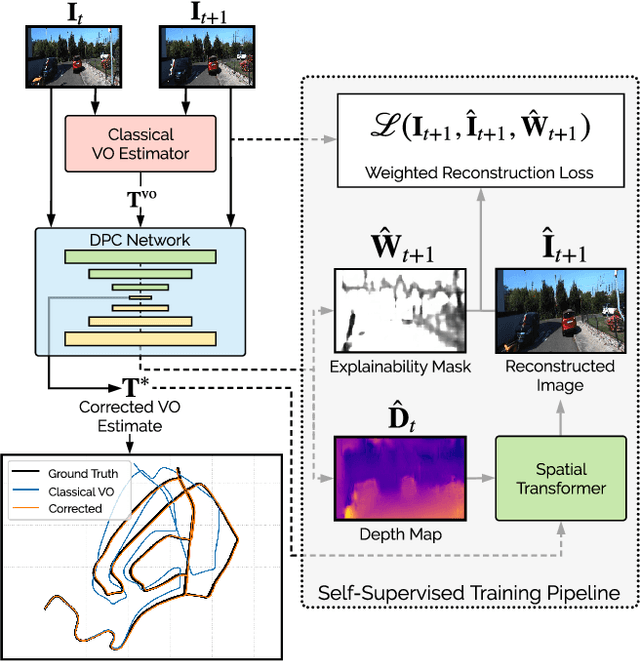
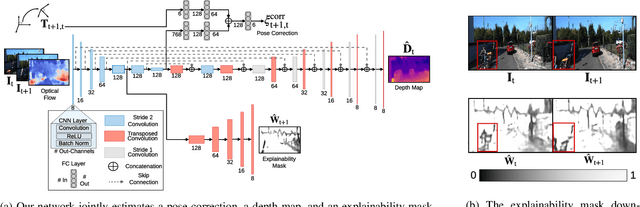
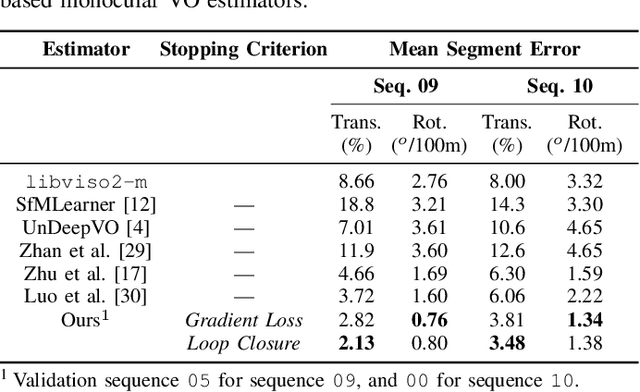
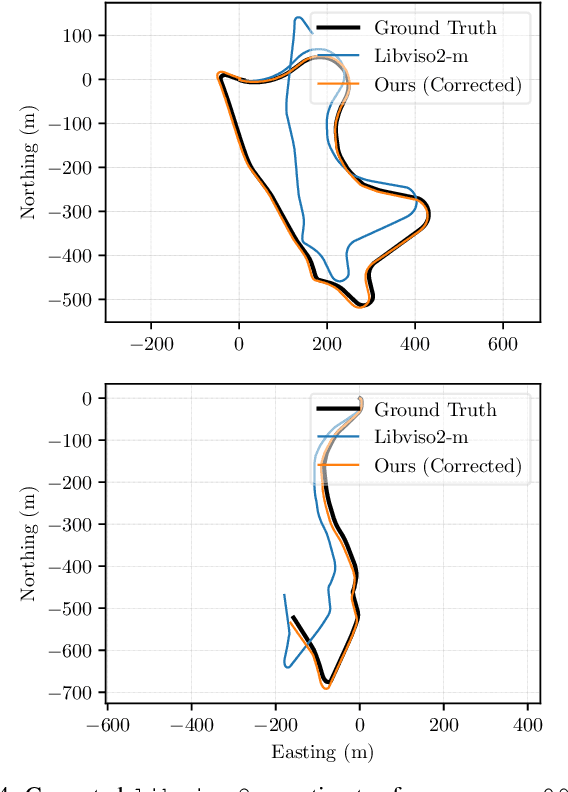
We present a self-supervised deep pose correction (DPC) network that applies pose corrections to a visual odometry estimator to improve its accuracy. Instead of regressing inter-frame pose changes directly, we build on prior work that uses data-driven learning to regress pose corrections that account for systematic errors due to violations of modelling assumptions. Our self-supervised formulation removes any requirement for six-degrees-of-freedom ground truth and, in contrast to expectations, often improves overall navigation accuracy compared to a supervised approach. Through extensive experiments, we show that our self-supervised DPC network can significantly enhance the performance of classical monocular and stereo odometry estimators and substantially out-performs state-of-the-art learning-only approaches.
Robust Data-Driven Zero-Velocity Detection for Foot-Mounted Inertial Navigation
Oct 25, 2019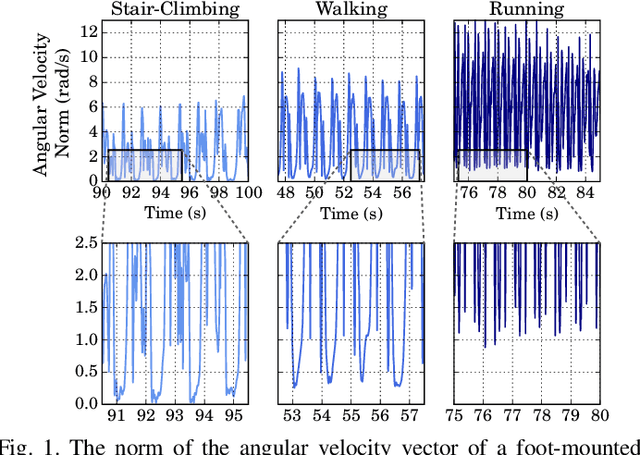
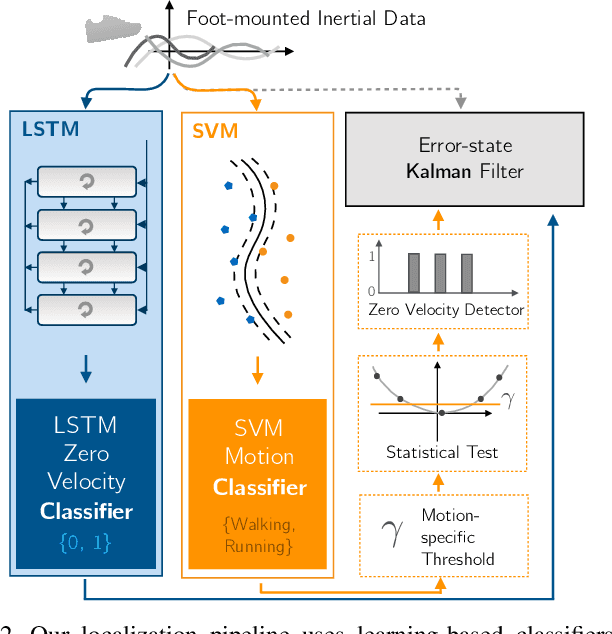
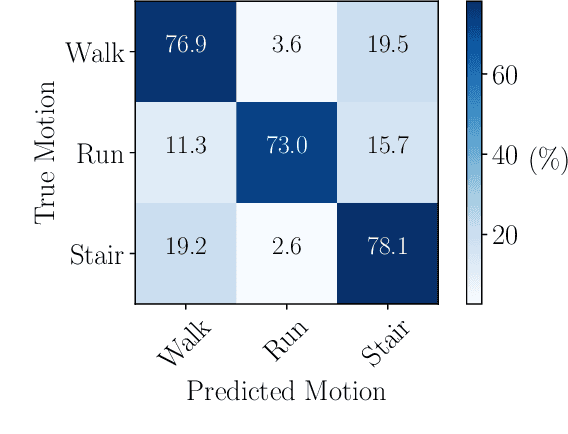
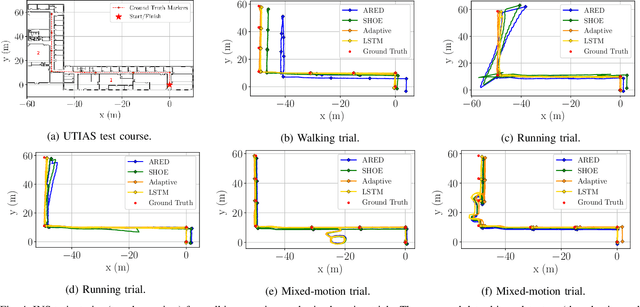
We present two novel techniques for detecting zero-velocity events to improve foot-mounted inertial navigation. Our first technique augments a classical zero-velocity detector by incorporating a motion classifier that adaptively updates the detector's threshold parameter. Our second technique uses a long short-term memory (LSTM) recurrent neural network to classify zero-velocity events from raw inertial data, in contrast to the majority of zero-velocity detection methods that rely on basic statistical hypothesis testing. We demonstrate that both of our proposed detectors achieve higher accuracies than existing detectors for trajectories including walking, running, and stair-climbing motions. Additionally, we present a straightforward data augmentation method that is able to extend the LSTM-based model to different inertial sensors without the need to collect new training data.
Sparse Bounded Degree Sum of Squares Optimization for Certifiably Globally Optimal Rotation Averaging
Apr 02, 2019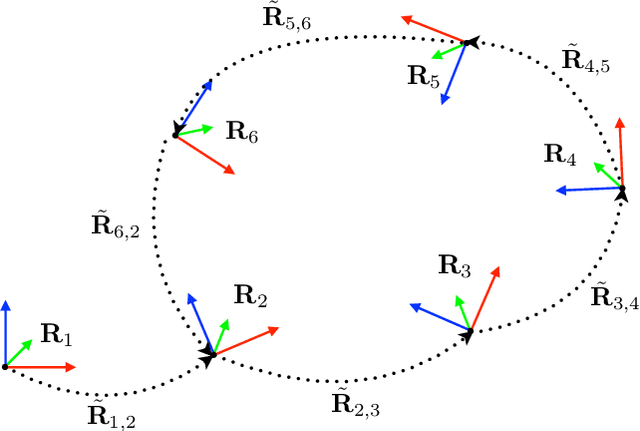
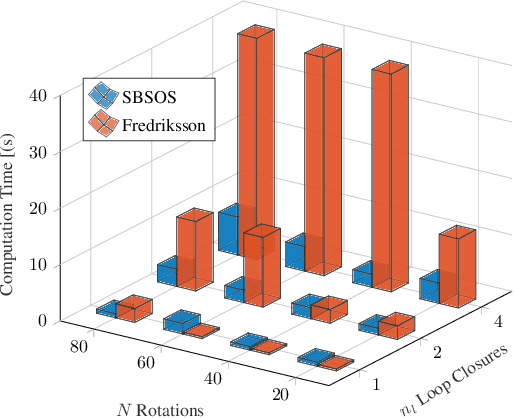
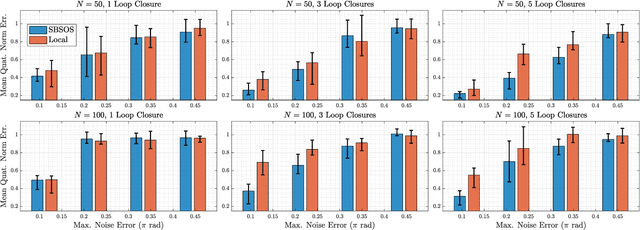
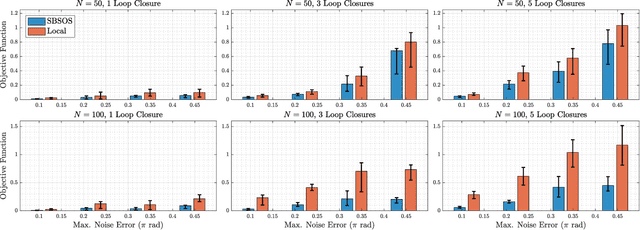
Estimating unknown rotations from noisy measurements is an important step in SfM and other 3D vision tasks. Typically, local optimization methods susceptible to returning suboptimal local minima are used to solve the rotation averaging problem. A new wave of approaches that leverage convex relaxations have provided the first formal guarantees of global optimality for state estimation techniques involving SO(3). However, most of these guarantees are only applicable when the measurement error introduced by noise is within a certain bound that depends on the problem instance's structure. In this paper, we cast rotation averaging as a polynomial optimization problem over unit quaternions to produce the first rotation averaging method that is formally guaranteed to provide a certifiably globally optimal solution for \textit{any} problem instance. This is achieved by formulating and solving a sparse convex sum of squares (SOS) relaxation of the problem. We provide an open source implementation of our algorithm and experiments, demonstrating the benefits of our globally optimal approach.
Probabilistic Regression of Rotations using Quaternion Averaging and a Deep Multi-Headed Network
Apr 01, 2019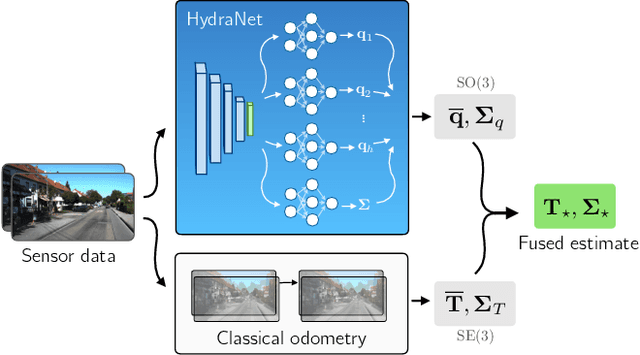
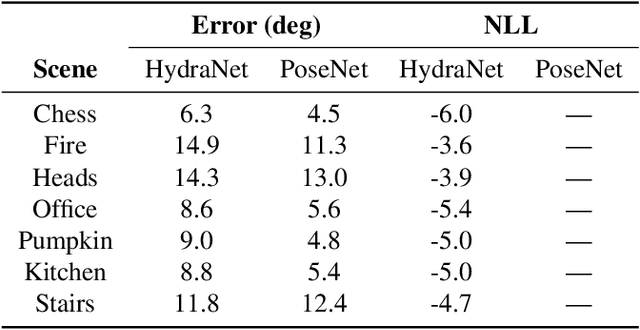
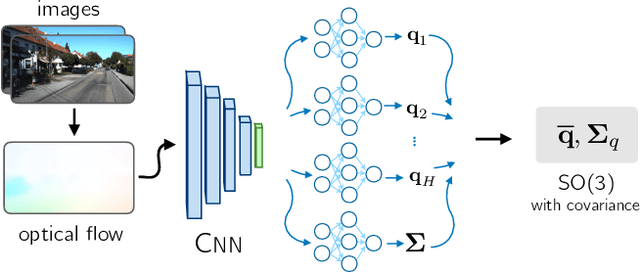
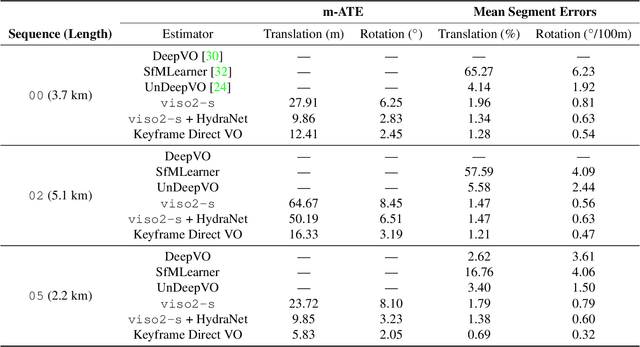
Accurate estimates of rotation are crucial to vision-based motion estimation in augmented reality and robotics. In this work, we present a method to extract probabilistic estimates of rotation from deep regression models. First, we build on prior work and argue that a multi-headed network structure we name HydraNet provides better calibrated uncertainty estimates than methods that rely on stochastic forward passes. Second, we extend HydraNet to targets that belong to the rotation group, SO(3), by regressing unit quaternions and using the tools of rotation averaging and uncertainty injection onto the manifold to produce three-dimensional covariances. Finally, we present results and analysis on a synthetic dataset, learn consistent orientation estimates on the 7-Scenes dataset, and show how we can use our learned covariances to fuse deep estimates of relative orientation with classical stereo visual odometry to improve localization on the KITTI dataset.
Certifiably Globally Optimal Extrinsic Calibration from Per-Sensor Egomotion
Jan 27, 2019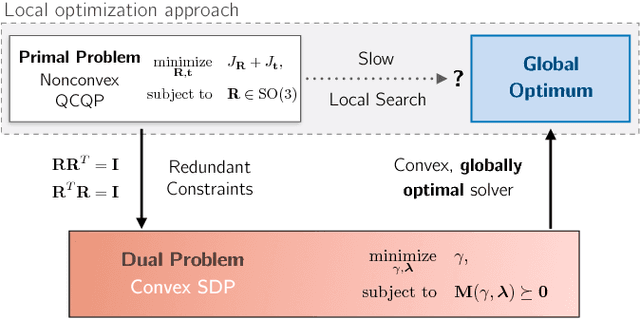
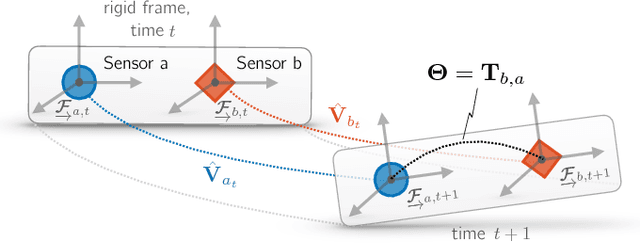
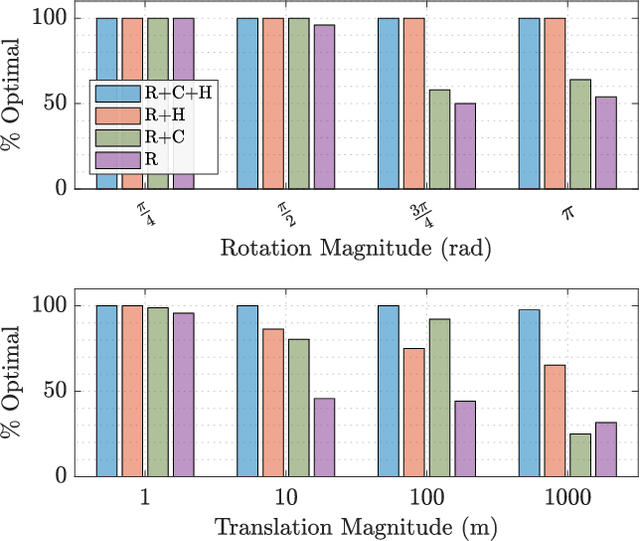
We present a certifiably globally optimal algorithm for determining the extrinsic calibration between two sensors that are capable of producing independent egomotion estimates. This problem has been previously solved using a variety of techniques, including local optimization approaches that have no formal global optimality guarantees. We use a quadratic objective function to formulate calibration as a quadratically constrained quadratic program (QCQP). By leveraging recent advances in the optimization of QCQPs, we are able to use existing semidefinite program (SDP) solvers to obtain a certifiably global optimum via the Lagrangian dual problem. Our problem formulation can be globally optimized by existing general-purpose solvers in less than a second, regardless of the number of measurements available and the noise level. This enables a variety of robotic platforms to rapidly and robustly compute and certify a globally optimal set of calibration parameters without a prior estimate or operator intervention. We compare the performance of our approach with a local solver on extensive simulations and multiple real datasets. Finally, we present necessary observability conditions that connect our approach to recent theoretical results and analytically support the empirical performance of our system.
DPC-Net: Deep Pose Correction for Visual Localization
Sep 10, 2018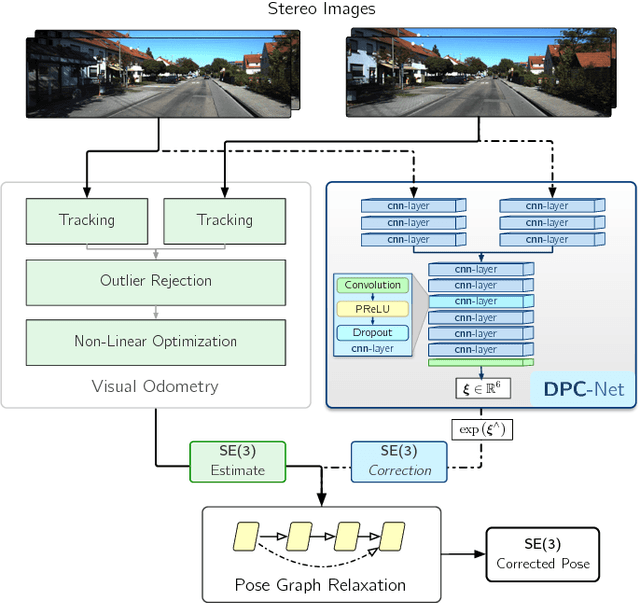
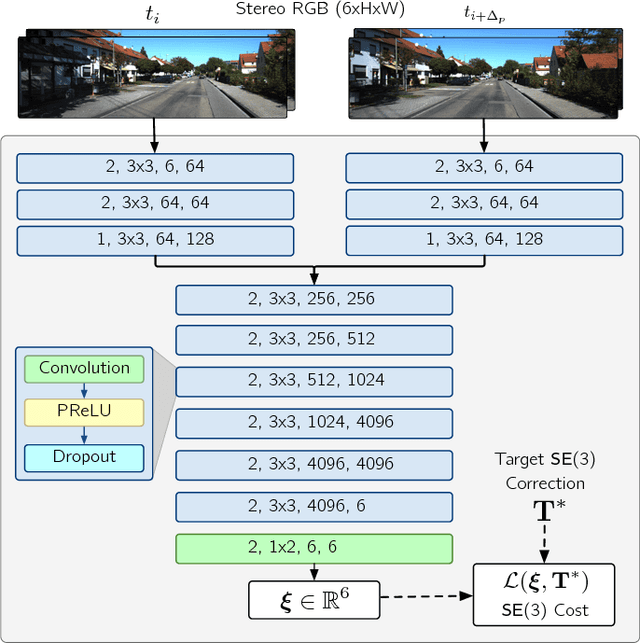

We present a novel method to fuse the power of deep networks with the computational efficiency of geometric and probabilistic localization algorithms. In contrast to other methods that completely replace a classical visual estimator with a deep network, we propose an approach that uses a convolutional neural network to learn difficult-to-model corrections to the estimator from ground-truth training data. To this end, we derive a novel loss function for learning SE(3) corrections based on a matrix Lie groups approach, with a natural formulation for balancing translation and rotation errors. We use this loss to train a Deep Pose Correction network (DPC-Net) that predicts corrections for a particular estimator, sensor and environment. Using the KITTI odometry dataset, we demonstrate significant improvements to the accuracy of a computationally-efficient sparse stereo visual odometry pipeline, that render it as accurate as a modern computationally-intensive dense estimator. Further, we show how DPC-Net can be used to mitigate the effect of poorly calibrated lens distortion parameters.
Improving Foot-Mounted Inertial Navigation Through Real-Time Motion Classification
Jul 13, 2018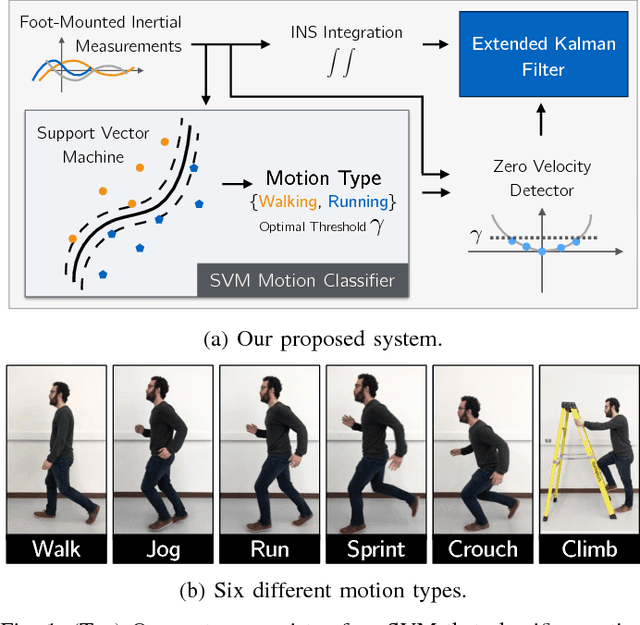
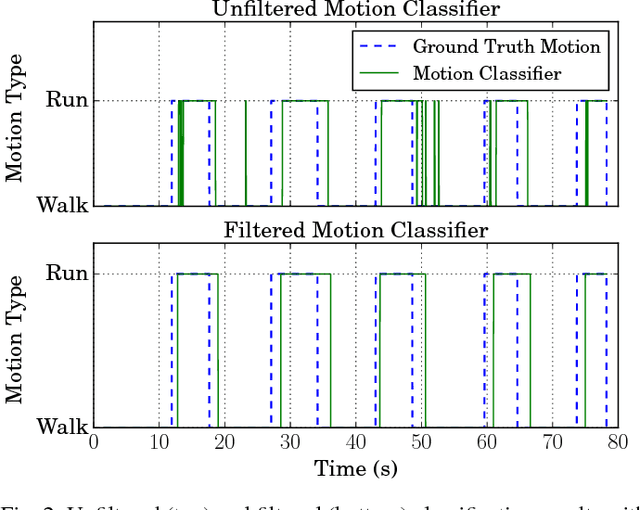

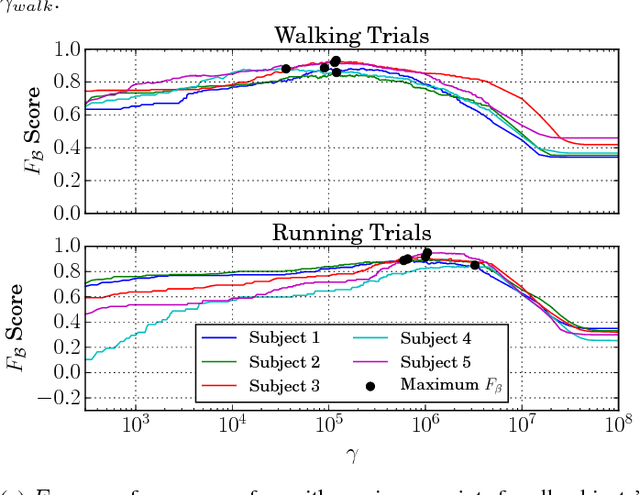
We present a method to improve the accuracy of a foot-mounted, zero-velocity-aided inertial navigation system (INS) by varying estimator parameters based on a real-time classification of motion type. We train a support vector machine (SVM) classifier using inertial data recorded by a single foot-mounted sensor to differentiate between six motion types (walking, jogging, running, sprinting, crouch-walking, and ladder-climbing) and report mean test classification accuracy of over 90% on a dataset with five different subjects. From these motion types, we select two of the most common (walking and running), and describe a method to compute optimal zero-velocity detection parameters tailored to both a specific user and motion type by maximizing the detector F-score. By combining the motion classifier with a set of optimal detection parameters, we show how we can reduce INS position error during mixed walking and running motion. We evaluate our adaptive system on a total of 5.9 km of indoor pedestrian navigation performed by five different subjects moving along a 130 m path with surveyed ground truth markers.