 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Similarity and Alignment Learning on Partial Video Copy Detection
Aug 04, 2021
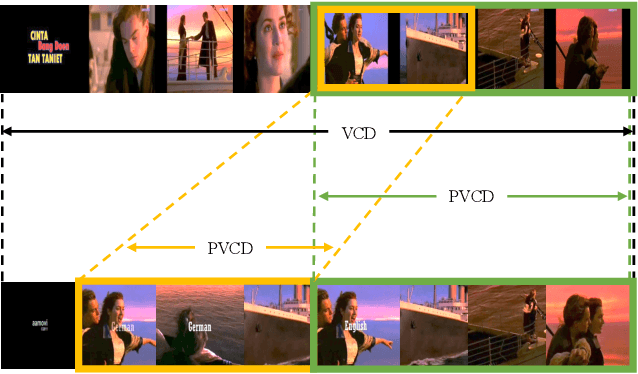
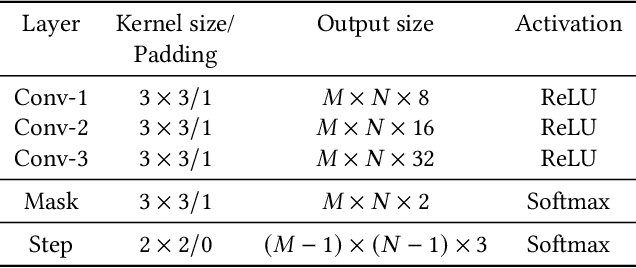
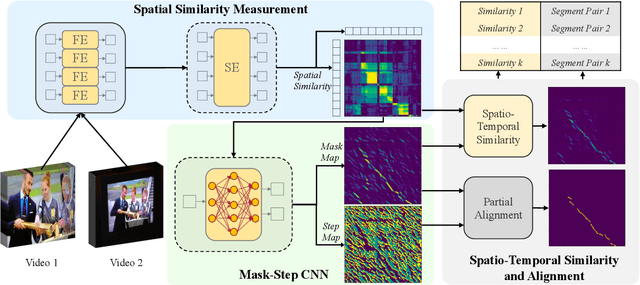
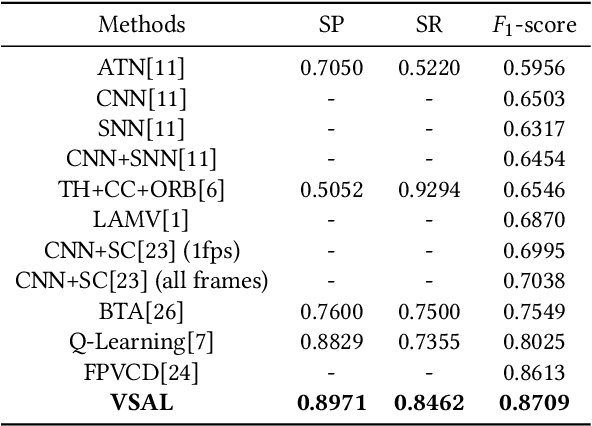
Existing video copy detection methods generally measure video similarity based on spatial similarities between key frames, neglecting the latent similarity in temporal dimension, so that the video similarity is biased towards spatial information. There are methods modeling unified video similarity in an end-to-end way, but losing detailed partial alignment information, which causes the incapability of copy segments localization. To address the above issues, we propose the Video Similarity and Alignment Learning (VSAL) approach, which jointly models spatial similarity, temporal similarity and partial alignment. To mitigate the spatial similarity bias, we model the temporal similarity as the mask map predicted from frame-level spatial similarity, where each element indicates the probability of frame pair lying right on the partial alignments. To further localize partial copies, the step map is learned from the spatial similarity where the elements indicate extending directions of the current partial alignments on the spatial-temporal similarity map. Obtained from the mask map, the start points extend out into partial optimal alignments following instructions of the step map. With the similarity and alignment learning strategy, VSAL achieves the state-of-the-art F1-score on VCDB core dataset. Furthermore, we construct a new benchmark of partial video copy detection and localization by adding new segment-level annotations for FIVR-200k dataset, where VSAL also achieves the best performance, verifying its effectiveness in more challenging situations. Our project is publicly available at https://pvcd-vsal.github.io/vsal/.
A Relation-Oriented Clustering Method for Open Relation Extraction
Sep 15, 2021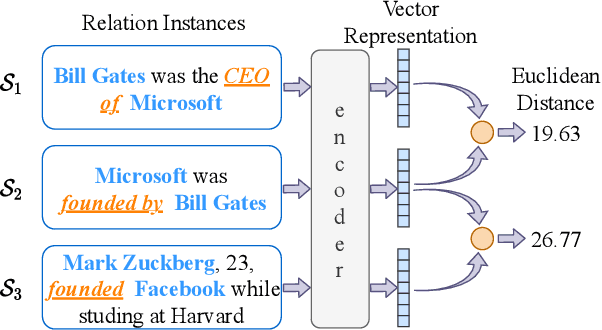
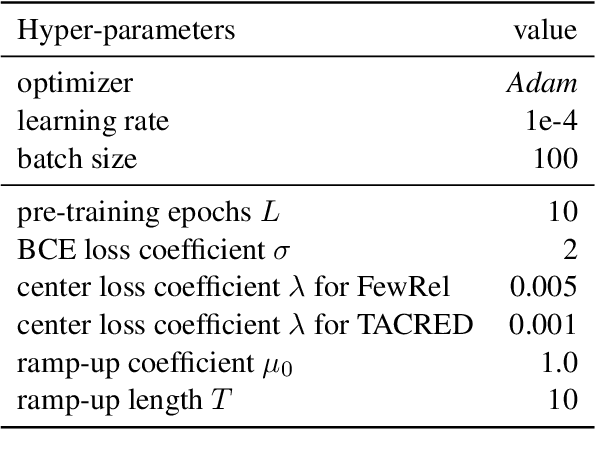
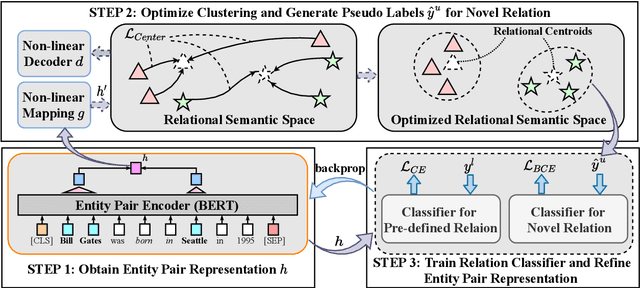
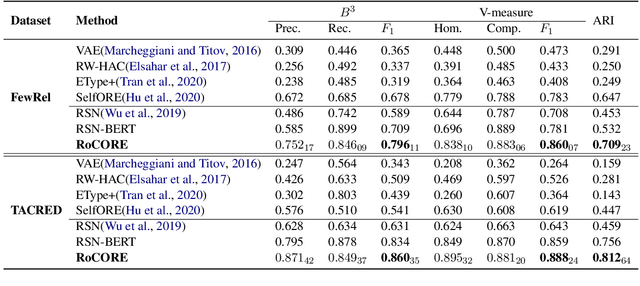
The clustering-based unsupervised relation discovery method has gradually become one of the important methods of open relation extraction (OpenRE). However, high-dimensional vectors can encode complex linguistic information which leads to the problem that the derived clusters cannot explicitly align with the relational semantic classes. In this work, we propose a relation-oriented clustering model and use it to identify the novel relations in the unlabeled data. Specifically, to enable the model to learn to cluster relational data, our method leverages the readily available labeled data of pre-defined relations to learn a relation-oriented representation. We minimize distance between the instance with same relation by gathering the instances towards their corresponding relation centroids to form a cluster structure, so that the learned representation is cluster-friendly. To reduce the clustering bias on predefined classes, we optimize the model by minimizing a joint objective on both labeled and unlabeled data. Experimental results show that our method reduces the error rate by 29.2% and 15.7%, on two datasets respectively, compared with current SOTA methods.
Multivariate Dependence Beyond Shannon Information
Sep 08, 2016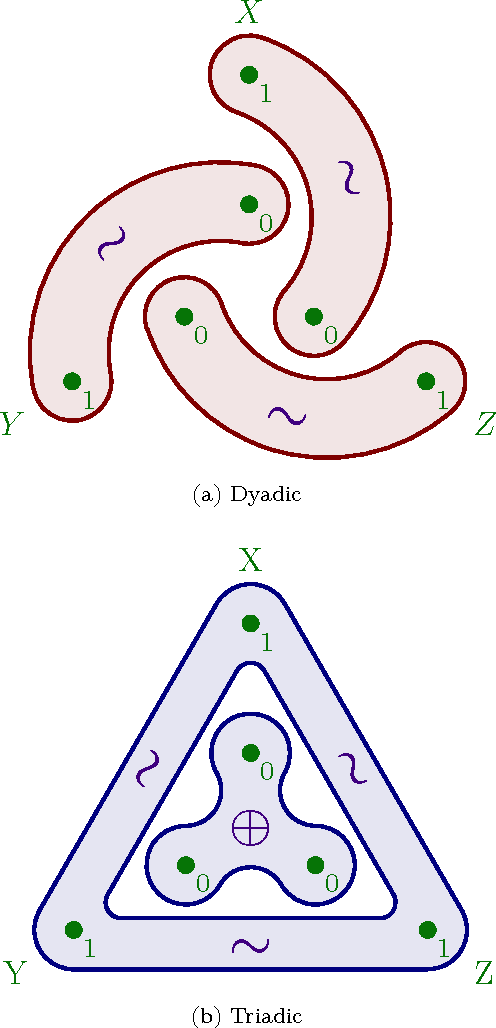
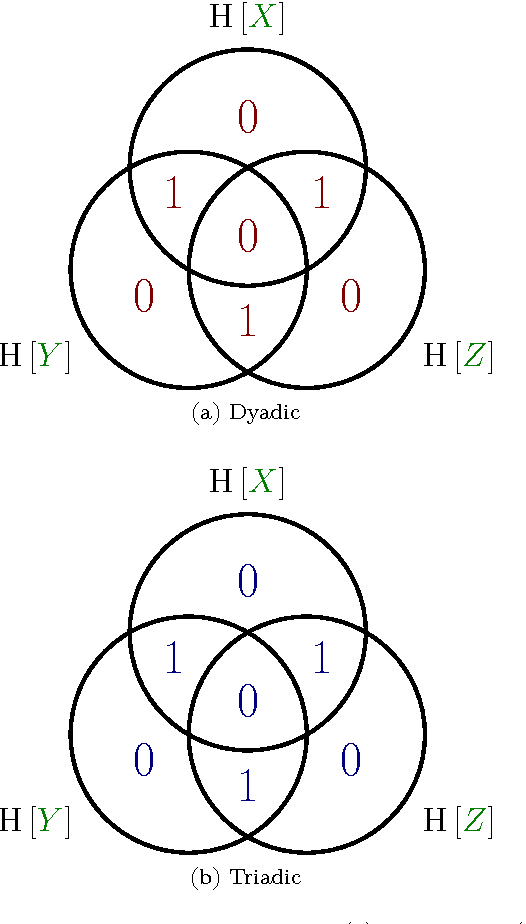
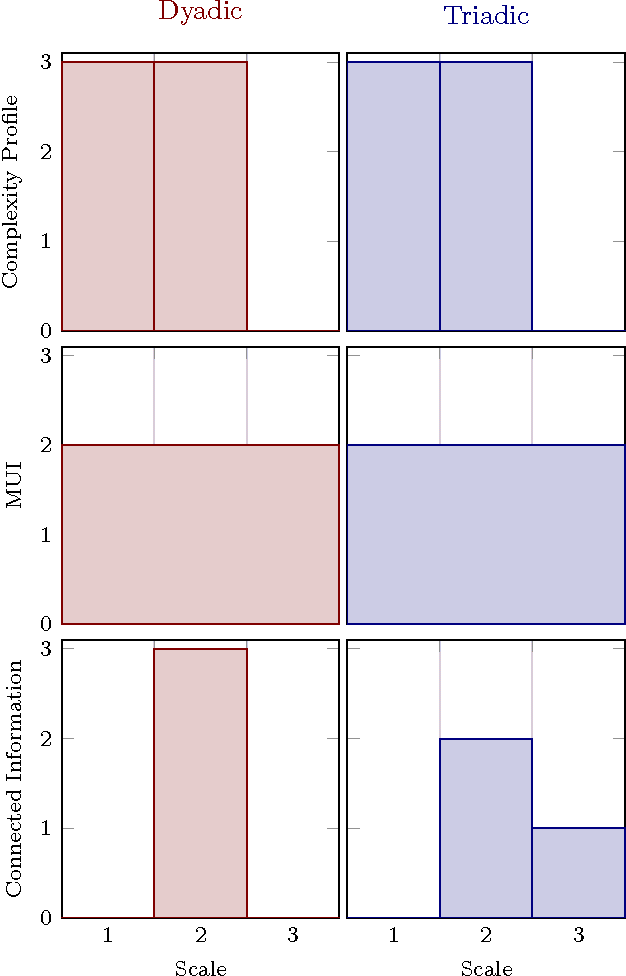
Accurately determining dependency structure is critical to discovering a system's causal organization. We recently showed that the transfer entropy fails in a key aspect of this---measuring information flow---due to its conflation of dyadic and polyadic relationships. We extend this observation to demonstrate that this is true of all such Shannon information measures when used to analyze multivariate dependencies. This has broad implications, particularly when employing information to express the organization and mechanisms embedded in complex systems, including the burgeoning efforts to combine complex network theory with information theory. Here, we do not suggest that any aspect of information theory is wrong. Rather, the vast majority of its informational measures are simply inadequate for determining the meaningful dependency structure within joint probability distributions. Therefore, such information measures are inadequate for discovering intrinsic causal relations. We close by demonstrating that such distributions exist across an arbitrary set of variables.
PermuteFormer: Efficient Relative Position Encoding for Long Sequences
Sep 08, 2021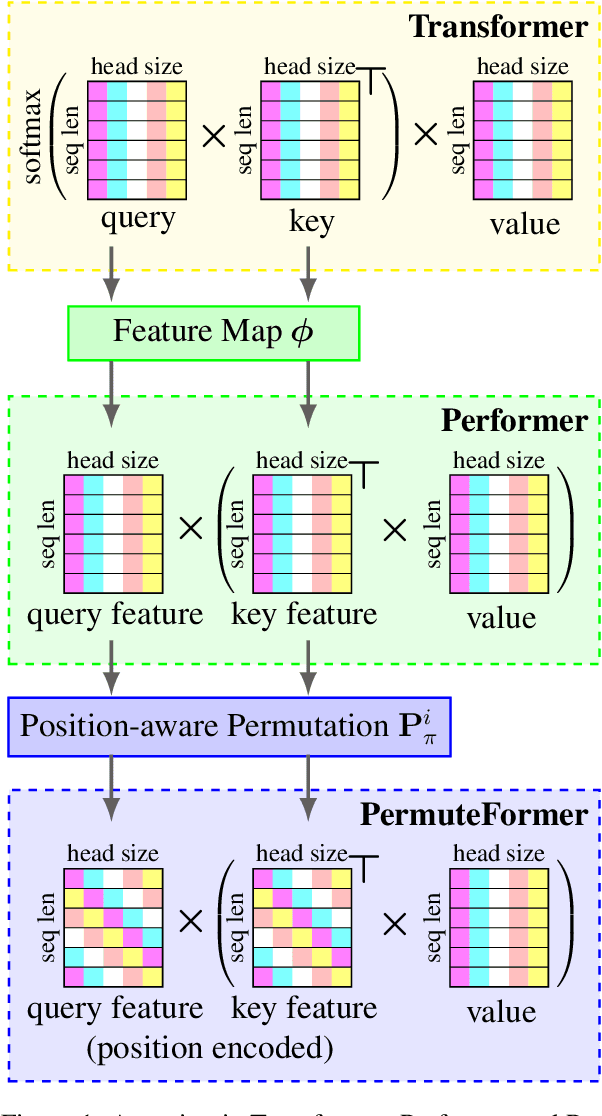
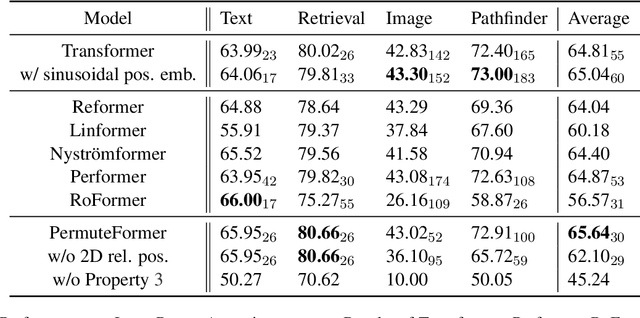
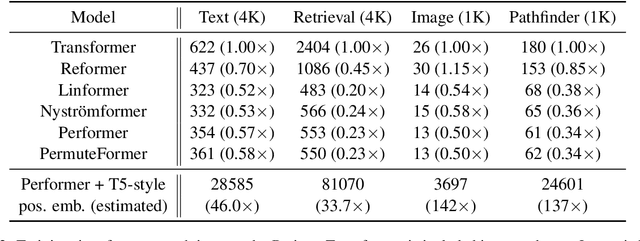
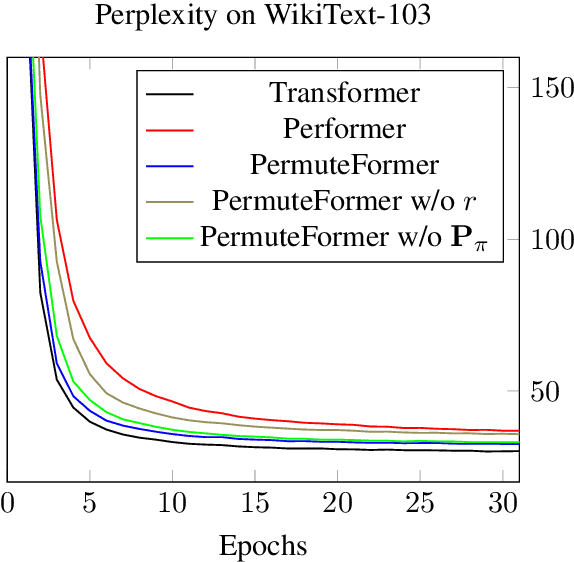
A recent variation of Transformer, Performer, scales Transformer to longer sequences with a linear attention mechanism. However, it is not compatible with relative position encoding, which has advantages over absolute position encoding. In this paper, we discuss possible ways to add relative position encoding to Performer. Based on the analysis, we propose PermuteFormer, a Performer-based model with relative position encoding that scales linearly on long sequences. PermuteFormer applies position-dependent transformation on queries and keys to encode positional information into the attention module. This transformation is carefully crafted so that the final output of self-attention is not affected by absolute positions of tokens. PermuteFormer introduces negligible computational overhead by design that it runs as fast as Performer. We evaluate PermuteFormer on Long-Range Arena, a dataset for long sequences, as well as WikiText-103, a language modeling dataset. The experiments show that PermuteFormer uniformly improves the performance of Performer with almost no computational overhead and outperforms vanilla Transformer on most of the tasks.
Agree to Disagree: Subjective Fairness in Privacy-Restricted Decentralised Conflict Resolution
Jun 30, 2021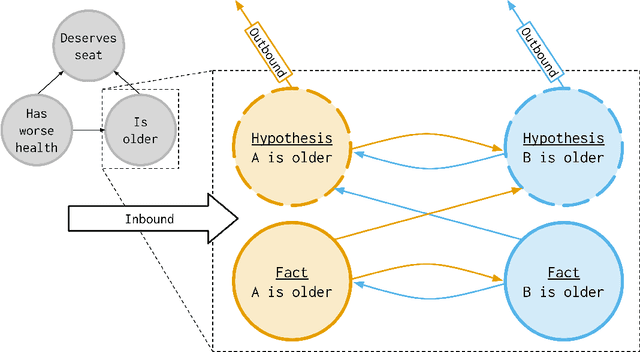
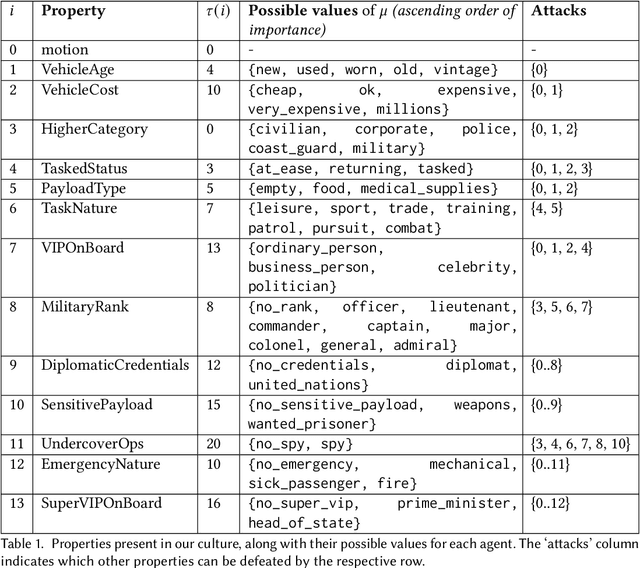
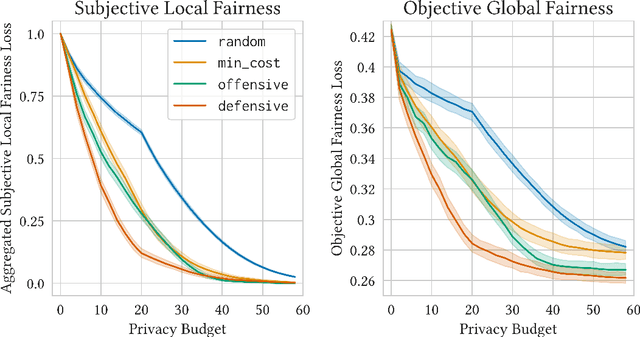
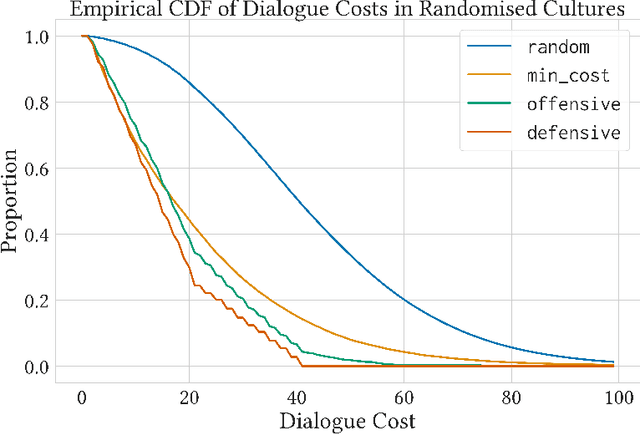
Fairness is commonly seen as a property of the global outcome of a system and assumes centralisation and complete knowledge. However, in real decentralised applications, agents only have partial observation capabilities. Under limited information, agents rely on communication to divulge some of their private (and unobservable) information to others. When an agent deliberates to resolve conflicts, limited knowledge may cause its perspective of a correct outcome to differ from the actual outcome of the conflict resolution. This is subjective unfairness. To enable decentralised, fairness-aware conflict resolution under privacy constraints, we have two contributions: (1) a novel interaction approach and (2) a formalism of the relationship between privacy and fairness. Our proposed interaction approach is an architecture for privacy-aware explainable conflict resolution where agents engage in a dialogue of hypotheses and facts. To measure the privacy-fairness relationship, we define subjective and objective fairness on both the local and global scope and formalise the impact of partial observability due to privacy in these different notions of fairness. We first study our proposed architecture and the privacy-fairness relationship in the abstract, testing different argumentation strategies on a large number of randomised cultures. We empirically demonstrate the trade-off between privacy, objective fairness, and subjective fairness and show that better strategies can mitigate the effects of privacy in distributed systems. In addition to this analysis across a broad set of randomised abstract cultures, we analyse a case study for a specific scenario: we instantiate our architecture in a multi-agent simulation of prioritised rule-aware collision avoidance with limited information disclosure.
Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions
Sep 27, 2021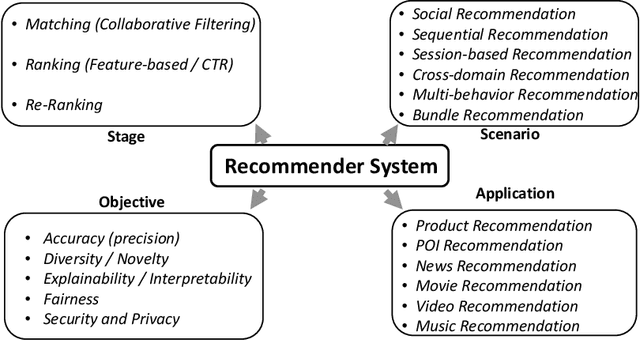

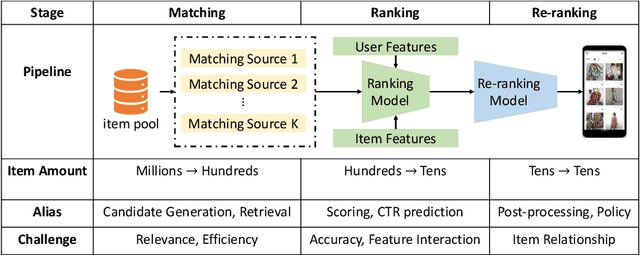
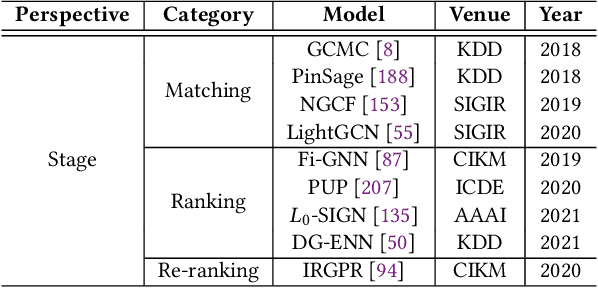
Recommender system is one of the most important information services on today's Internet. Recently, graph neural networks have become the new state-of-the-art approach of recommender systems. In this survey, we conduct a comprehensive review of the literature in graph neural network-based recommender systems. We first introduce the background and the history of the development of both recommender systems and graph neural networks. For recommender systems, in general, there are four aspects for categorizing existing works: stage, scenario, objective, and application. For graph neural networks, the existing methods consist of two categories, spectral models and spatial ones. We then discuss the motivation of applying graph neural networks into recommender systems, mainly consisting of the high-order connectivity, the structural property of data, and the enhanced supervision signal. We then systematically analyze the challenges in graph construction, embedding propagation/aggregation, model optimization, and computation efficiency. Afterward and primarily, we provide a comprehensive overview of a multitude of existing works of graph neural network-based recommender systems, following the taxonomy above. Finally, we raise discussions on the open problems and promising future directions of this area. We summarize the representative papers along with their codes repositories in https://github.com/tsinghua-fib-lab/GNN-Recommender-Systems.
MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
Aug 14, 2021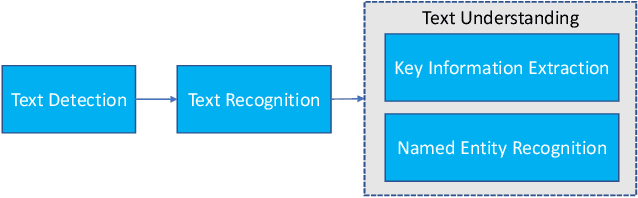



We present MMOCR-an open-source toolbox which provides a comprehensive pipeline for text detection and recognition, as well as their downstream tasks such as named entity recognition and key information extraction. MMOCR implements 14 state-of-the-art algorithms, which is significantly more than all the existing open-source OCR projects we are aware of to date. To facilitate future research and industrial applications of text recognition-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of text detection, recognition and understanding. MMOCR is publicly released at https://github.com/open-mmlab/mmocr.
Distributionally Robust Multi-Output Regression Ranking
Sep 27, 2021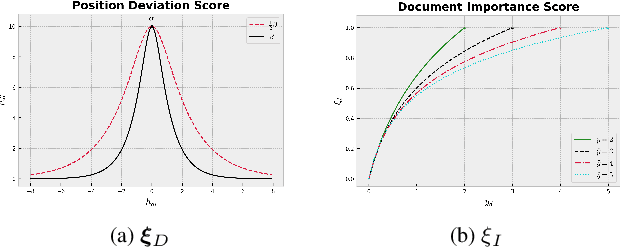
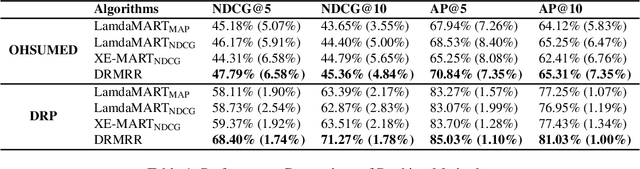

Despite their empirical success, most existing listwiselearning-to-rank (LTR) models are not built to be robust to errors in labeling or annotation, distributional data shift, or adversarial data perturbations. To fill this gap, we introduce a new listwise LTR model called Distributionally Robust Multi-output Regression Ranking (DRMRR). Different from existing methods, the scoring function of DRMRR was designed as a multivariate mapping from a feature vector to a vector of deviation scores, which captures local context information and cross-document interactions. DRMRR uses a Distributionally Robust Optimization (DRO) framework to minimize a multi-output loss function under the most adverse distributions in the neighborhood of the empirical data distribution defined by a Wasserstein ball. We show that this is equivalent to a regularized regression problem with a matrix norm regularizer. Our experiments were conducted on two real-world applications, medical document retrieval, and drug response prediction, showing that DRMRR notably outperforms state-of-the-art LTR models. We also conducted a comprehensive analysis to assess the resilience of DRMRR against various types of noise: Gaussian noise, adversarial perturbations, and label poisoning. We show that DRMRR is not only able to achieve significantly better performance than other baselines, but it can maintain a relatively stable performance as more noise is added to the data.
ExpertRank: A Multi-level Coarse-grained Expert-based Listwise Ranking Loss
Jul 29, 2021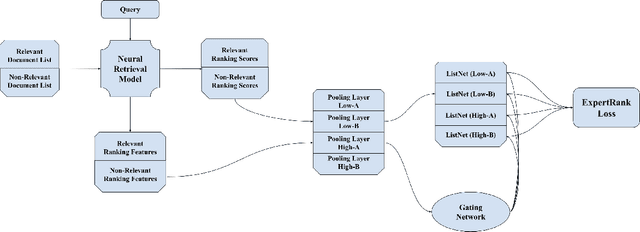
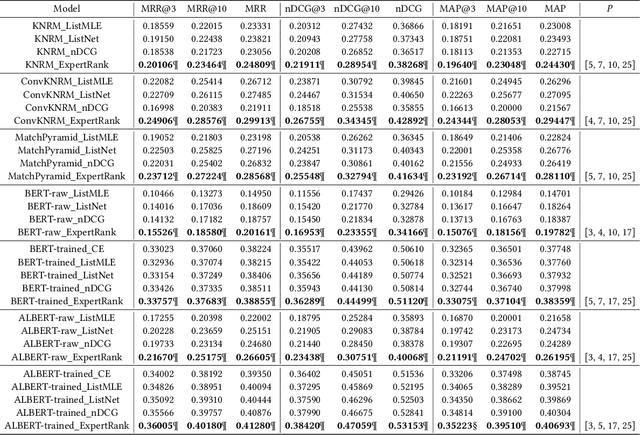
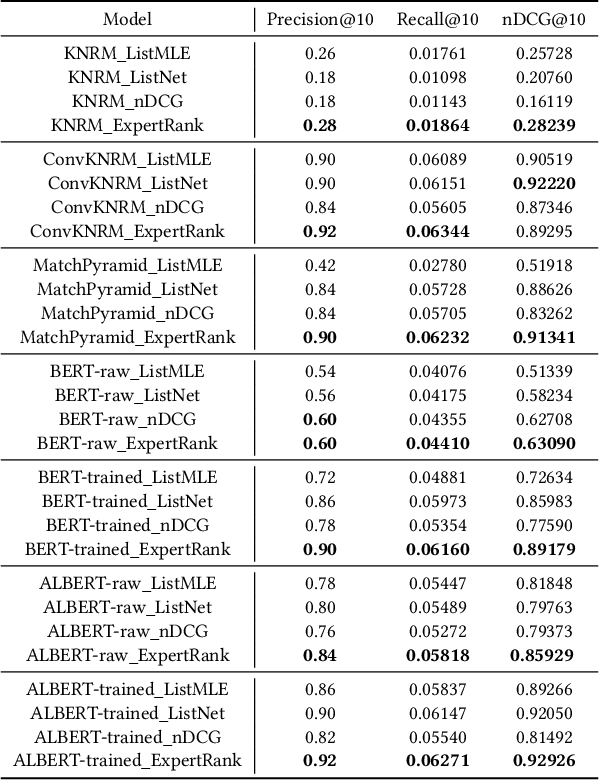
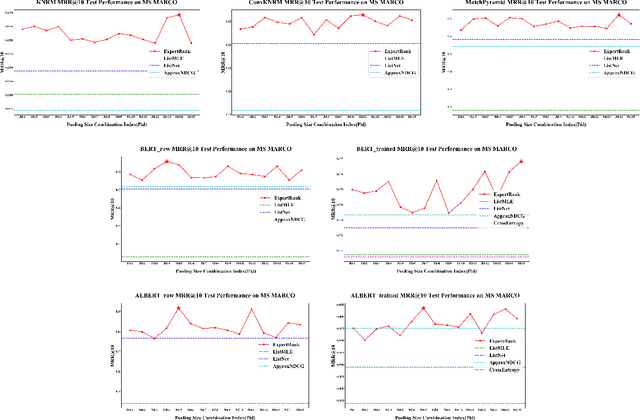
The goal of information retrieval is to recommend a list of document candidates that are most relevant to a given query. Listwise learning trains neural retrieval models by comparing various candidates simultaneously on a large scale, offering much more competitive performance than pairwise and pointwise schemes. Existing listwise ranking losses treat the candidate document list as a whole unit without further inspection. Some candidates with moderate semantic prominence may be ignored by the noisy similarity signals or overshadowed by a few especially pronounced candidates. As a result, existing ranking losses fail to exploit the full potential of neural retrieval models. To address these concerns, we apply the classic pooling technique to conduct multi-level coarse graining and propose ExpertRank, a novel expert-based listwise ranking loss. The proposed scheme has three major advantages: (1) ExpertRank introduces the profound physics concept of coarse graining to information retrieval by selecting prominent candidates at various local levels based on model prediction and inter-document comparison. (2) ExpertRank applies the mixture of experts (MoE) technique to combine different experts effectively by extending the traditional ListNet. (3) Compared to other existing listwise learning approaches, ExpertRank produces much more reliable and competitive performance for various neural retrieval models with different complexities, from traditional models, such as KNRM, ConvKNRM, MatchPyramid, to sophisticated BERT/ALBERT-based retrieval models.
Speech2Video: Cross-Modal Distillation for Speech to Video Generation
Jul 10, 2021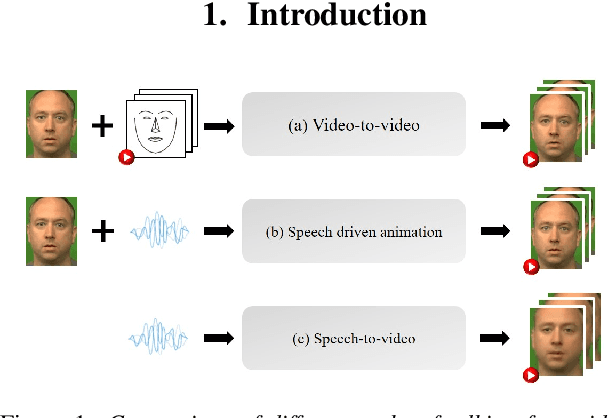
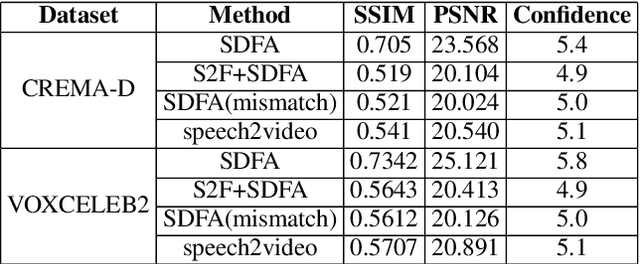
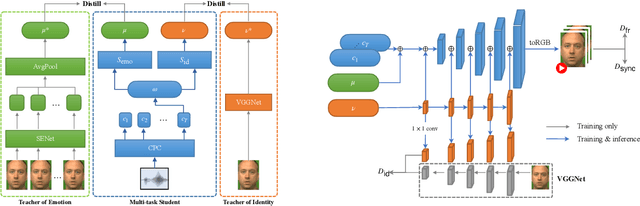
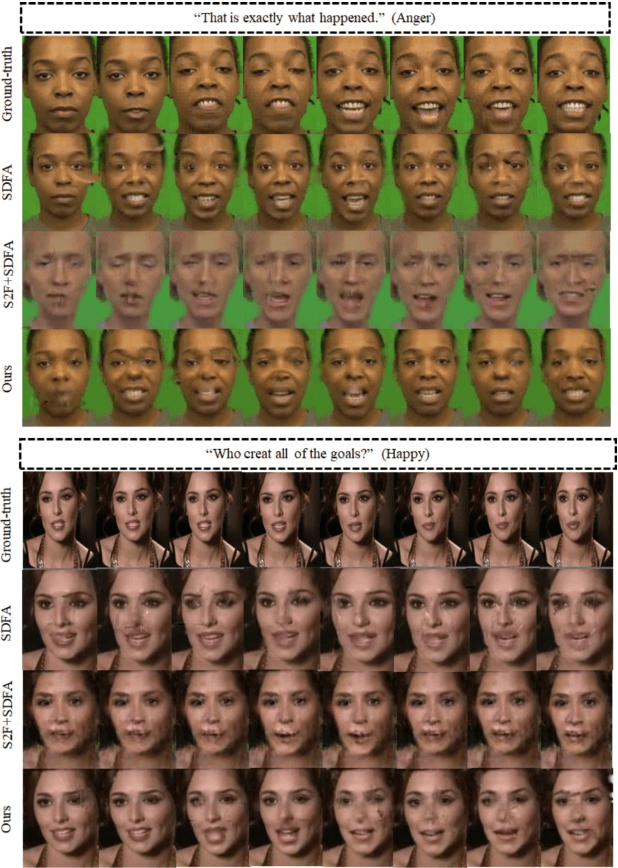
This paper investigates a novel task of talking face video generation solely from speeches. The speech-to-video generation technique can spark interesting applications in entertainment, customer service, and human-computer-interaction industries. Indeed, the timbre, accent and speed in speeches could contain rich information relevant to speakers' appearance. The challenge mainly lies in disentangling the distinct visual attributes from audio signals. In this article, we propose a light-weight, cross-modal distillation method to extract disentangled emotional and identity information from unlabelled video inputs. The extracted features are then integrated by a generative adversarial network into talking face video clips. With carefully crafted discriminators, the proposed framework achieves realistic generation results. Experiments with observed individuals demonstrated that the proposed framework captures the emotional expressions solely from speeches, and produces spontaneous facial motion in the video output. Compared to the baseline method where speeches are combined with a static image of the speaker, the results of the proposed framework is almost indistinguishable. User studies also show that the proposed method outperforms the existing algorithms in terms of emotion expression in the generated videos.