 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartDexTOG: Generating Dexterous Task-Oriented Grasping via Language-driven Part Analysis
May 18, 2025Task-oriented grasping is a crucial yet challenging task in robotic manipulation. Despite the recent progress, few existing methods address task-oriented grasping with dexterous hands. Dexterous hands provide better precision and versatility, enabling robots to perform task-oriented grasping more effectively. In this paper, we argue that part analysis can enhance dexterous grasping by providing detailed information about the object's functionality. We propose PartDexTOG, a method that generates dexterous task-oriented grasps via language-driven part analysis. Taking a 3D object and a manipulation task represented by language as input, the method first generates the category-level and part-level grasp descriptions w.r.t the manipulation task by LLMs. Then, a category-part conditional diffusion model is developed to generate a dexterous grasp for each part, respectively, based on the generated descriptions. To select the most plausible combination of grasp and corresponding part from the generated ones, we propose a measure of geometric consistency between grasp and part. We show that our method greatly benefits from the open-world knowledge reasoning on object parts by LLMs, which naturally facilitates the learning of grasp generation on objects with different geometry and for different manipulation tasks. Our method ranks top on the OakInk-shape dataset over all previous methods, improving the Penetration Volume, the Grasp Displace, and the P-FID over the state-of-the-art by $3.58\%$, $2.87\%$, and $41.43\%$, respectively. Notably, it demonstrates good generality in handling novel categories and tasks.
PoolRank: Max/Min Pooling-based Ranking Loss for Listwise Learning & Ranking Balance
Aug 08, 2021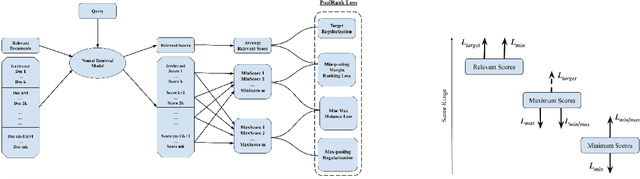
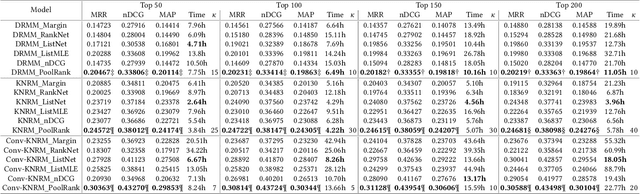
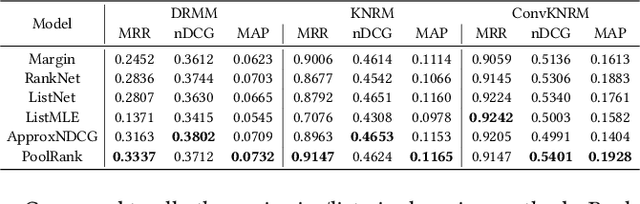
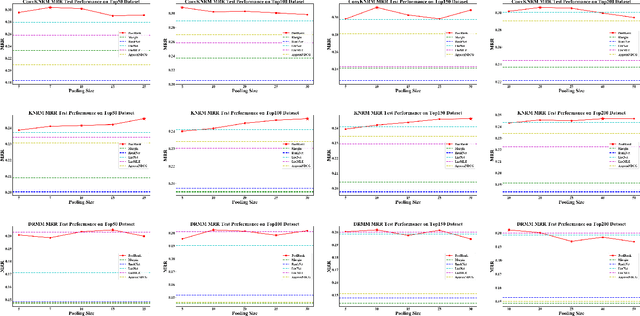
Numerous neural retrieval models have been proposed in recent years. These models learn to compute a ranking score between the given query and document. The majority of existing models are trained in pairwise fashion using human-judged labels directly without further calibration. The traditional pairwise schemes can be time-consuming and require pre-defined positive-negative document pairs for training, potentially leading to learning bias due to document distribution mismatch between training and test conditions. Some popular existing listwise schemes rely on the strong pre-defined probabilistic assumptions and stark difference between relevant and non-relevant documents for the given query, which may limit the model potential due to the low-quality or ambiguous relevance labels. To address these concerns, we turn to a physics-inspired ranking balance scheme and propose PoolRank, a pooling-based listwise learning framework. The proposed scheme has four major advantages: (1) PoolRank extracts training information from the best candidates at the local level based on model performance and relative ranking among abundant document candidates. (2) By combining four pooling-based loss components in a multi-task learning fashion, PoolRank calibrates the ranking balance for the partially relevant and the highly non-relevant documents automatically without costly human inspection. (3) PoolRank can be easily generalized to any neural retrieval model without requiring additional learnable parameters or model structure modifications. (4) Compared to pairwise learning and existing listwise learning schemes, PoolRank yields better ranking performance for all studied retrieval models while retaining efficient convergence rates.
ExpertRank: A Multi-level Coarse-grained Expert-based Listwise Ranking Loss
Jul 29, 2021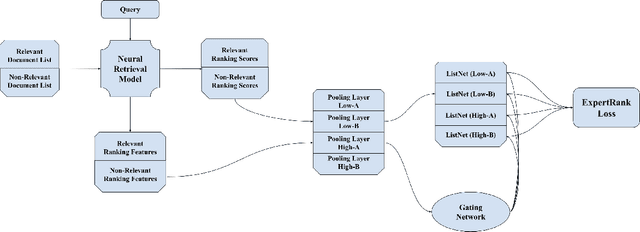
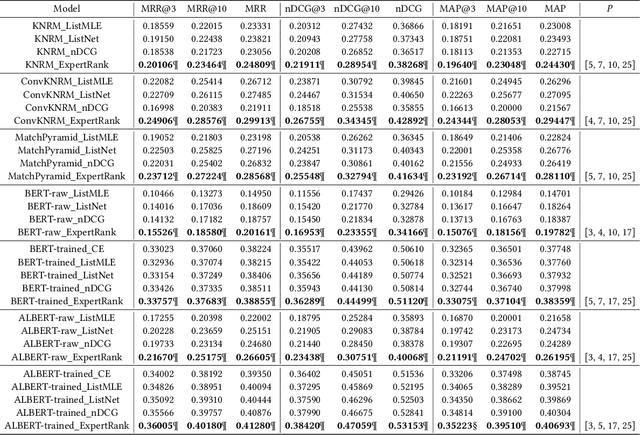
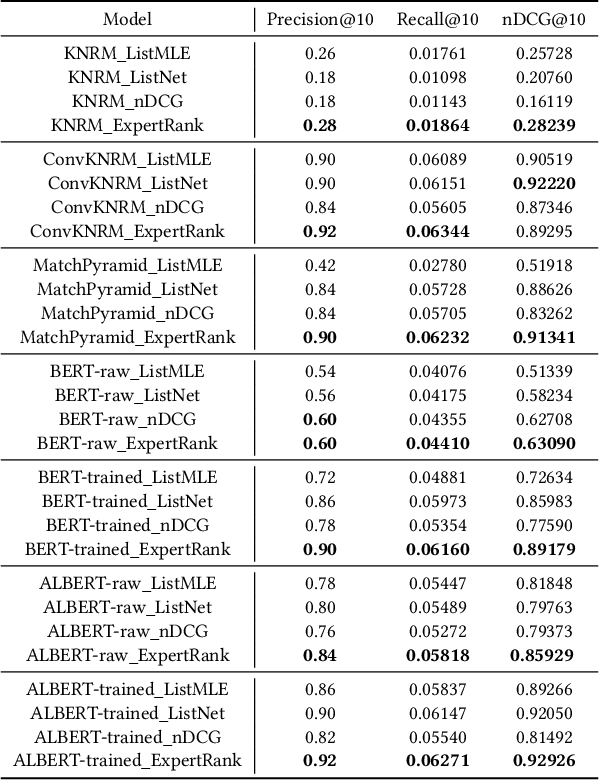
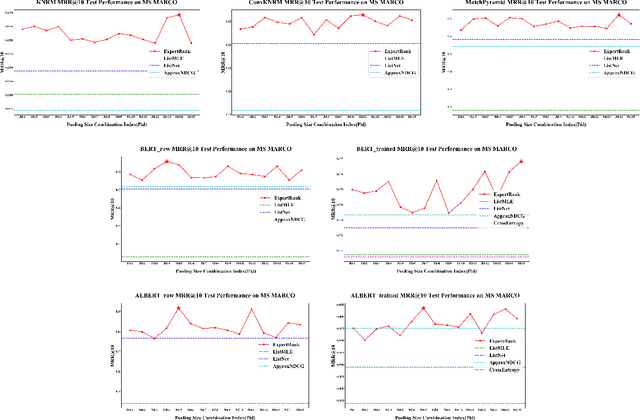
The goal of information retrieval is to recommend a list of document candidates that are most relevant to a given query. Listwise learning trains neural retrieval models by comparing various candidates simultaneously on a large scale, offering much more competitive performance than pairwise and pointwise schemes. Existing listwise ranking losses treat the candidate document list as a whole unit without further inspection. Some candidates with moderate semantic prominence may be ignored by the noisy similarity signals or overshadowed by a few especially pronounced candidates. As a result, existing ranking losses fail to exploit the full potential of neural retrieval models. To address these concerns, we apply the classic pooling technique to conduct multi-level coarse graining and propose ExpertRank, a novel expert-based listwise ranking loss. The proposed scheme has three major advantages: (1) ExpertRank introduces the profound physics concept of coarse graining to information retrieval by selecting prominent candidates at various local levels based on model prediction and inter-document comparison. (2) ExpertRank applies the mixture of experts (MoE) technique to combine different experts effectively by extending the traditional ListNet. (3) Compared to other existing listwise learning approaches, ExpertRank produces much more reliable and competitive performance for various neural retrieval models with different complexities, from traditional models, such as KNRM, ConvKNRM, MatchPyramid, to sophisticated BERT/ALBERT-based retrieval models.
The Cross-Lingual Arabic Information REtrieval (CLAIRE) System
Jul 29, 2021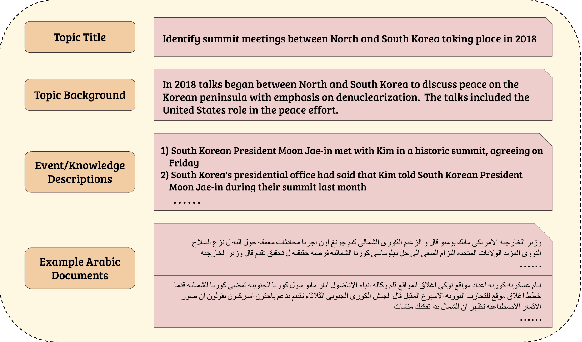
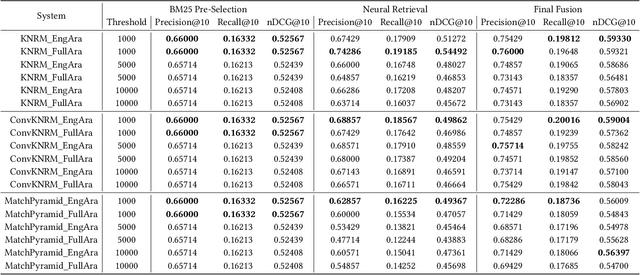
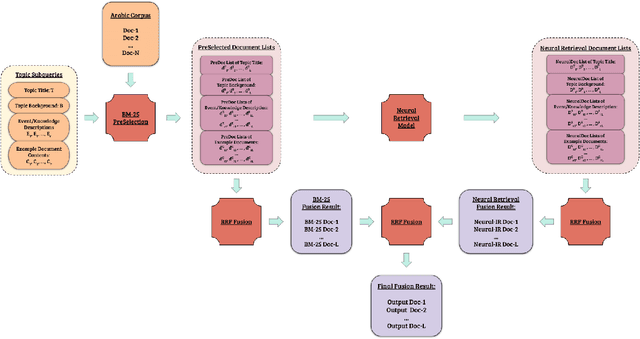
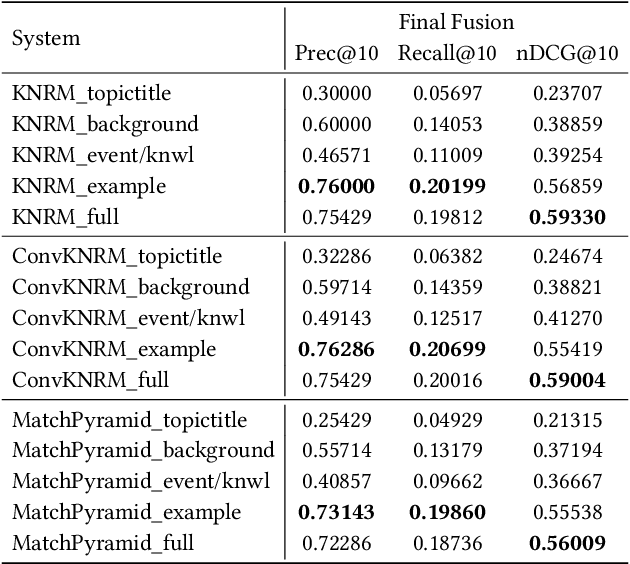
Despite advances in neural machine translation, cross-lingual retrieval tasks in which queries and documents live in different natural language spaces remain challenging. Although neural translation models may provide an intuitive approach to tackle the cross-lingual problem, their resource-consuming training and advanced model structures may complicate the overall retrieval pipeline and reduce users engagement. In this paper, we build our end-to-end Cross-Lingual Arabic Information REtrieval (CLAIRE) system based on the cross-lingual word embedding where searchers are assumed to have a passable passive understanding of Arabic and various supporting information in English is provided to aid retrieval experience. The proposed system has three major advantages: (1) The usage of English-Arabic word embedding simplifies the overall pipeline and avoids the potential mistakes caused by machine translation. (2) Our CLAIRE system can incorporate arbitrary word embedding-based neural retrieval models without structural modification. (3) Early empirical results on an Arabic news collection show promising performance.
Are "Undocumented Workers" the Same as "Illegal Aliens"? Disentangling Denotation and Connotation in Vector Spaces
Oct 25, 2020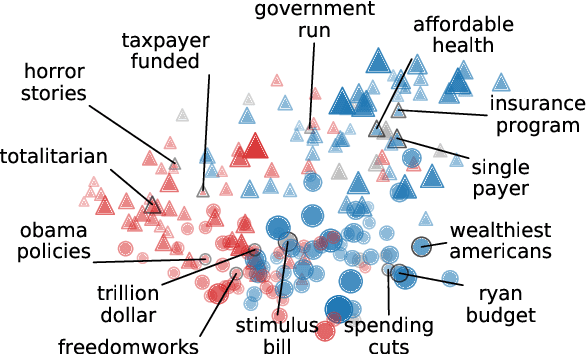

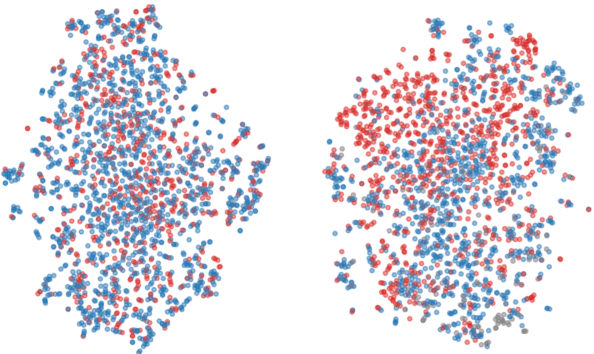
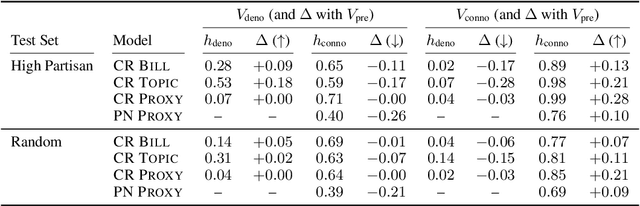
In politics, neologisms are frequently invented for partisan objectives. For example, "undocumented workers" and "illegal aliens" refer to the same group of people (i.e., they have the same denotation), but they carry clearly different connotations. Examples like these have traditionally posed a challenge to reference-based semantic theories and led to increasing acceptance of alternative theories (e.g., Two-Factor Semantics) among philosophers and cognitive scientists. In NLP, however, popular pretrained models encode both denotation and connotation as one entangled representation. In this study, we propose an adversarial neural network that decomposes a pretrained representation as independent denotation and connotation representations. For intrinsic interpretability, we show that words with the same denotation but different connotations (e.g., "immigrants" vs. "aliens", "estate tax" vs. "death tax") move closer to each other in denotation space while moving further apart in connotation space. For extrinsic application, we train an information retrieval system with our disentangled representations and show that the denotation vectors improve the viewpoint diversity of document rankings.