 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
ReLCP: Scalable Complementarity-Based Collision Resolution for Smooth Rigid Bodies
Jun 17, 2025We present a complementarity-based collision resolution algorithm for smooth, non-spherical, rigid bodies. Unlike discrete surface representation approaches, which approximate surfaces using discrete elements (e.g., tessellations or sub-spheres) with constraints between nearby faces, edges, nodes, or sub-objects, our algorithm solves a recursively generated linear complementarity problem (ReLCP) to adaptively identify potential collision locations during the collision resolution procedure. Despite adaptively and in contrast to Newton-esque schemes, we prove conditions under which the resulting solution exists and the center of mass translational and rotational dynamics are unique. Our ReLCP also converges to classical LCP-based collision resolution for sufficiently small timesteps. Because increasing the surface resolution in discrete representation methods necessitates subdividing geometry into finer elements -- leading to a super-linear increase in the number of collision constraints -- these approaches scale poorly with increased surface resolution. In contrast, our adaptive ReLCP framework begins with a single constraint per pair of nearby bodies and introduces new constraints only when unconstrained motion would lead to overlap, circumventing the oversampling required by discrete methods. By requiring one to two orders of magnitude fewer collision constraints to achieve the same surface resolution, we observe 10-100x speedup in densely packed applications. We validate our ReLCP method against multisphere and single-constraint methods, comparing convergence in a two-ellipsoid collision test, scalability and performance in a compacting ellipsoid suspension and growing bacterial colony, and stability in a taut chainmail network, highlighting our ability to achieve high-fidelity surface representations without suffering from poor scalability or artificial surface roughness.
A Novel RFID Authentication Protocol Based on A Block-Order-Modulus Variable Matrix Encryption Algorithm
Dec 17, 2023



In this paper, authentication for mobile radio frequency identification (RFID) systems with low-cost tags is studied. Firstly, a diagonal block key matrix (DBKM) encryption algorithm is proposed, which effectively expands the feasible domain of the key space. Subsequently, in order to enhance the security, a self updating encryption order (SUEO) algorithm is conceived. To further weaken the correlation between plaintext and ciphertext, a self updating modulus (SUM) algorithm is constructed. Based on the above three algorithms, a new joint DBKM-SUEO-SUM matrix encryption algorithm is established, which intends to enhance security without the need of additional storage for extra key matrices. Making full use of the advantages of the proposed joint algorithm, a two-way RFID authentication protocol named DBKM-SUEO-SUM-RFID is proposed for mobile RFID systems. In addition, the Burrows-Abadi-Needham (BAN) logic and security analysis indicate that the newly proposed DBKM-SUEO-SUM-RFID protocol can effectively resist various typical attacks, such as replay attacks and de-synchronization. Finally, numerical results demonstrate that the DBKM-SUEO-SUM algorithm can save at least 90.46\% of tag storage compared to traditional algorithms, and thus, is friendly to be employed with low-cost RFID tags.
Towards Automated Error Analysis: Learning to Characterize Errors
Jan 14, 2022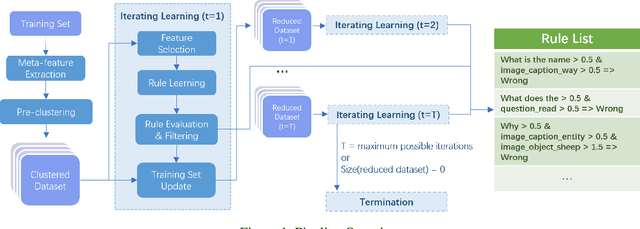

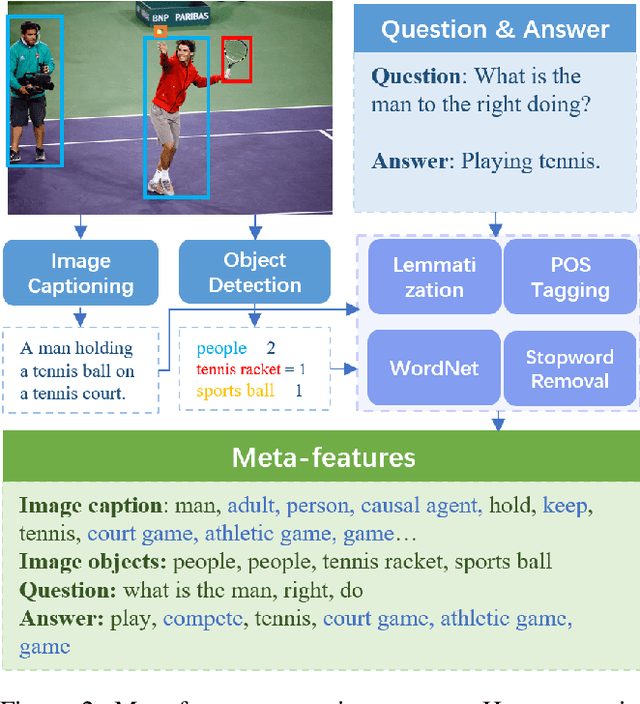

Characterizing the patterns of errors that a system makes helps researchers focus future development on increasing its accuracy and robustness. We propose a novel form of "meta learning" that automatically learns interpretable rules that characterize the types of errors that a system makes, and demonstrate these rules' ability to help understand and improve two NLP systems. Our approach works by collecting error cases on validation data, extracting meta-features describing these samples, and finally learning rules that characterize errors using these features. We apply our approach to VilBERT, for Visual Question Answering, and RoBERTa, for Common Sense Question Answering. Our system learns interpretable rules that provide insights into systemic errors these systems make on the given tasks. Using these insights, we are also able to "close the loop" and modestly improve performance of these systems.
MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
Aug 14, 2021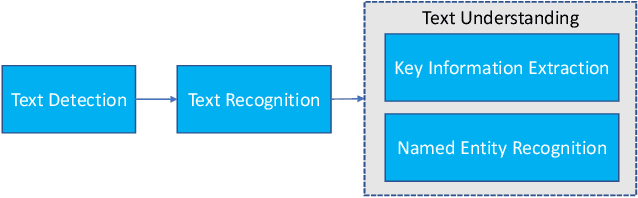



We present MMOCR-an open-source toolbox which provides a comprehensive pipeline for text detection and recognition, as well as their downstream tasks such as named entity recognition and key information extraction. MMOCR implements 14 state-of-the-art algorithms, which is significantly more than all the existing open-source OCR projects we are aware of to date. To facilitate future research and industrial applications of text recognition-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of text detection, recognition and understanding. MMOCR is publicly released at https://github.com/open-mmlab/mmocr.
Systematic Generalization on gSCAN with Language Conditioned Embedding
Oct 04, 2020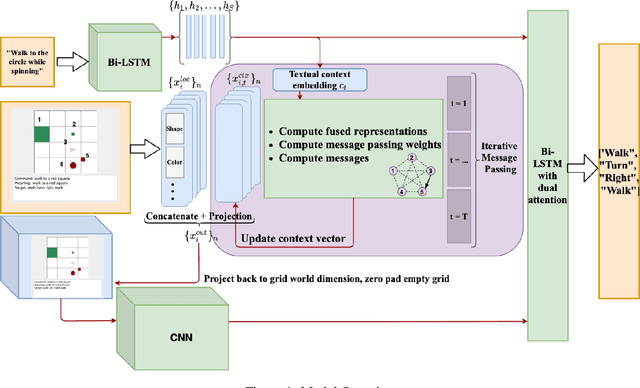
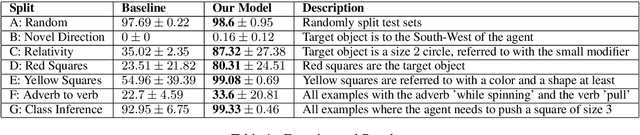

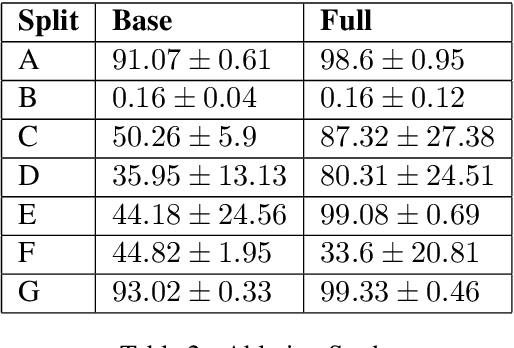
Systematic Generalization refers to a learning algorithm's ability to extrapolate learned behavior to unseen situations that are distinct but semantically similar to its training data. As shown in recent work, state-of-the-art deep learning models fail dramatically even on tasks for which they are designed when the test set is systematically different from the training data. We hypothesize that explicitly modeling the relations between objects in their contexts while learning their representations will help achieve systematic generalization. Therefore, we propose a novel method that learns objects' contextualized embeddings with dynamic message passing conditioned on the input natural language and end-to-end trainable with other downstream deep learning modules. To our knowledge, this model is the first one that significantly outperforms the provided baseline and reaches state-of-the-art performance on grounded-SCAN (gSCAN), a grounded natural language navigation dataset designed to require systematic generalization in its test splits.
Large-Scale Answerer in Questioner's Mind for Visual Dialog Question Generation
Feb 22, 2019

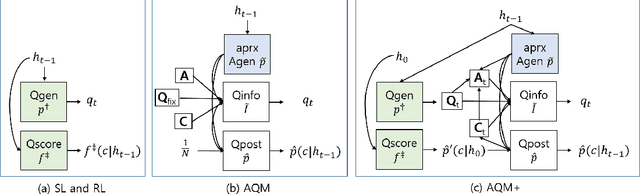

Answerer in Questioner's Mind (AQM) is an information-theoretic framework that has been recently proposed for task-oriented dialog systems. AQM benefits from asking a question that would maximize the information gain when it is asked. However, due to its intrinsic nature of explicitly calculating the information gain, AQM has a limitation when the solution space is very large. To address this, we propose AQM+ that can deal with a large-scale problem and ask a question that is more coherent to the current context of the dialog. We evaluate our method on GuessWhich, a challenging task-oriented visual dialog problem, where the number of candidate classes is near 10K. Our experimental results and ablation studies show that AQM+ outperforms the state-of-the-art models by a remarkable margin with a reasonable approximation. In particular, the proposed AQM+ reduces more than 60% of error as the dialog proceeds, while the comparative algorithms diminish the error by less than 6%. Based on our results, we argue that AQM+ is a general task-oriented dialog algorithm that can be applied for non-yes-or-no responses.