 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Efficient Multi-Agent Cooperative Visual Exploration
Oct 12, 2021
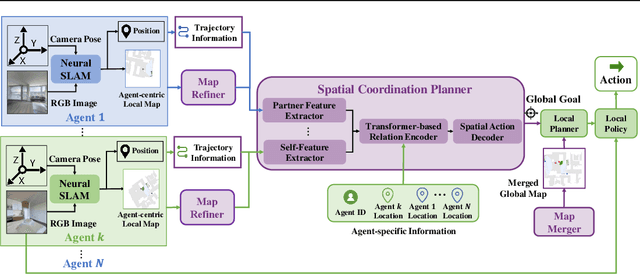
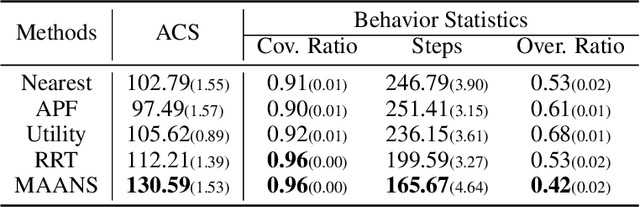
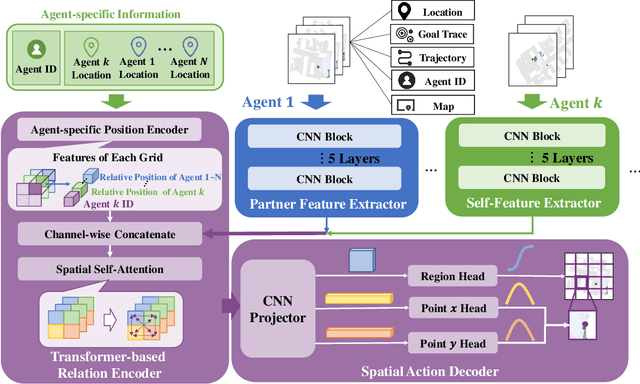
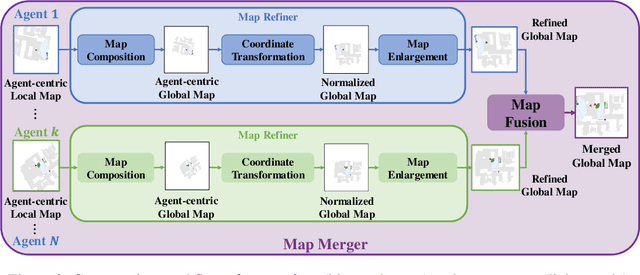
We consider the task of visual indoor exploration with multiple agents, where the agents need to cooperatively explore the entire indoor region using as few steps as possible. Classical planning-based methods often suffer from particularly expensive computation at each inference step and a limited expressiveness of cooperation strategy. By contrast, reinforcement learning (RL) has become a trending paradigm for tackling this challenge due to its modeling capability of arbitrarily complex strategies and minimal inference overhead. We extend the state-of-the-art single-agent RL solution, Active Neural SLAM (ANS), to the multi-agent setting by introducing a novel RL-based global-goal planner, Spatial Coordination Planner (SCP), which leverages spatial information from each individual agent in an end-to-end manner and effectively guides the agents to navigate towards different spatial goals with high exploration efficiency. SCP consists of a transformer-based relation encoder to capture intra-agent interactions and a spatial action decoder to produce accurate goals. In addition, we also implement a few multi-agent enhancements to process local information from each agent for an aligned spatial representation and more precise planning. Our final solution, Multi-Agent Active Neural SLAM (MAANS), combines all these techniques and substantially outperforms 4 different planning-based methods and various RL baselines in the photo-realistic physical testbed, Habitat.
DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features
Aug 11, 2021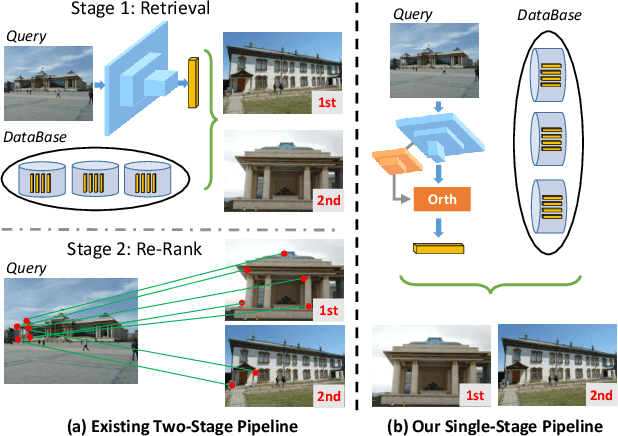
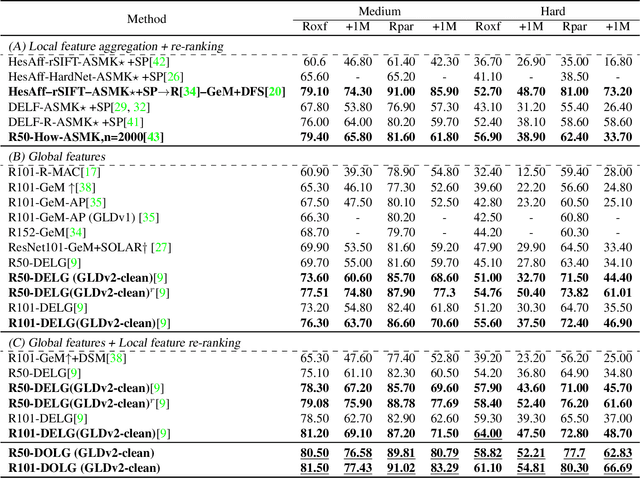
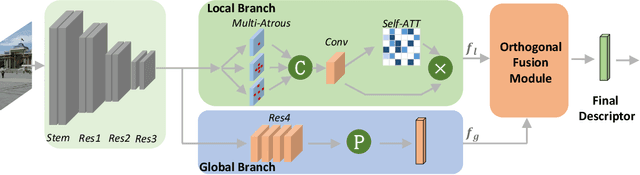
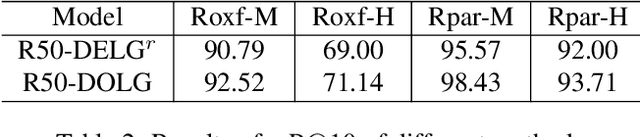
Image Retrieval is a fundamental task of obtaining images similar to the query one from a database. A common image retrieval practice is to firstly retrieve candidate images via similarity search using global image features and then re-rank the candidates by leveraging their local features. Previous learning-based studies mainly focus on either global or local image representation learning to tackle the retrieval task. In this paper, we abandon the two-stage paradigm and seek to design an effective single-stage solution by integrating local and global information inside images into compact image representations. Specifically, we propose a Deep Orthogonal Local and Global (DOLG) information fusion framework for end-to-end image retrieval. It attentively extracts representative local information with multi-atrous convolutions and self-attention at first. Components orthogonal to the global image representation are then extracted from the local information. At last, the orthogonal components are concatenated with the global representation as a complementary, and then aggregation is performed to generate the final representation. The whole framework is end-to-end differentiable and can be trained with image-level labels. Extensive experimental results validate the effectiveness of our solution and show that our model achieves state-of-the-art image retrieval performances on Revisited Oxford and Paris datasets.
Structure-Preserving Deraining with Residue Channel Prior Guidance
Aug 20, 2021
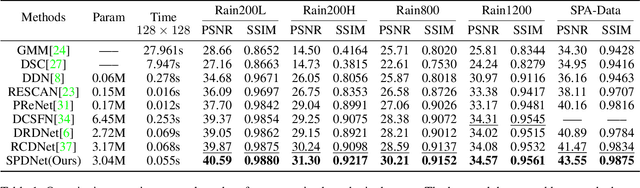


Single image deraining is important for many high-level computer vision tasks since the rain streaks can severely degrade the visibility of images, thereby affecting the recognition and analysis of the image. Recently, many CNN-based methods have been proposed for rain removal. Although these methods can remove part of the rain streaks, it is difficult for them to adapt to real-world scenarios and restore high-quality rain-free images with clear and accurate structures. To solve this problem, we propose a Structure-Preserving Deraining Network (SPDNet) with RCP guidance. SPDNet directly generates high-quality rain-free images with clear and accurate structures under the guidance of RCP but does not rely on any rain-generating assumptions. Specifically, we found that the RCP of images contains more accurate structural information than rainy images. Therefore, we introduced it to our deraining network to protect structure information of the rain-free image. Meanwhile, a Wavelet-based Multi-Level Module (WMLM) is proposed as the backbone for learning the background information of rainy images and an Interactive Fusion Module (IFM) is designed to make full use of RCP information. In addition, an iterative guidance strategy is proposed to gradually improve the accuracy of RCP, refining the result in a progressive path. Extensive experimental results on both synthetic and real-world datasets demonstrate that the proposed model achieves new state-of-the-art results. Code: https://github.com/Joyies/SPDNet
Recurrent Video Deblurring with Blur-Invariant Motion Estimation and Pixel Volumes
Aug 23, 2021
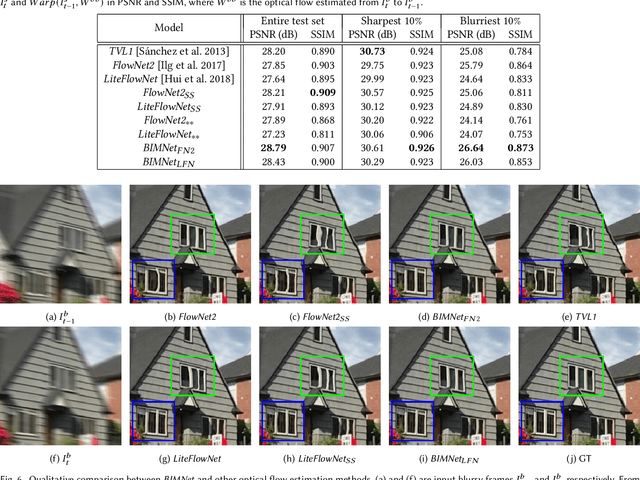
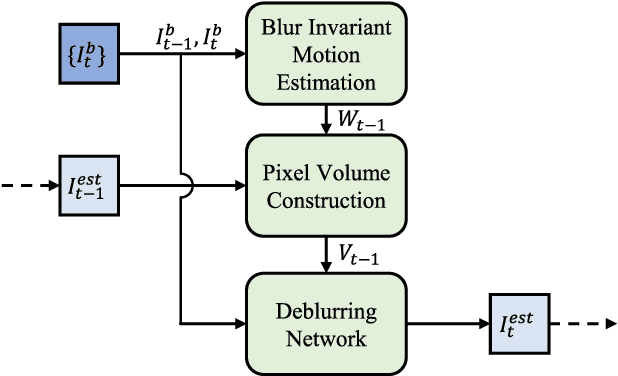
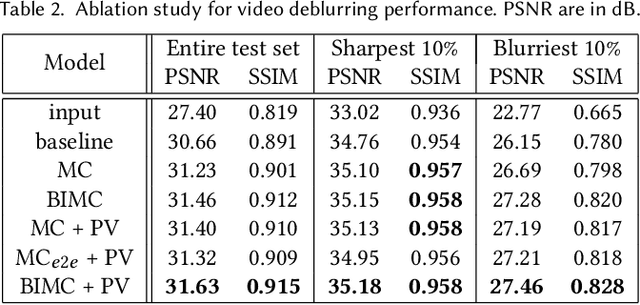
For the success of video deblurring, it is essential to utilize information from neighboring frames. Most state-of-the-art video deblurring methods adopt motion compensation between video frames to aggregate information from multiple frames that can help deblur a target frame. However, the motion compensation methods adopted by previous deblurring methods are not blur-invariant, and consequently, their accuracy is limited for blurry frames with different blur amounts. To alleviate this problem, we propose two novel approaches to deblur videos by effectively aggregating information from multiple video frames. First, we present blur-invariant motion estimation learning to improve motion estimation accuracy between blurry frames. Second, for motion compensation, instead of aligning frames by warping with estimated motions, we use a pixel volume that contains candidate sharp pixels to resolve motion estimation errors. We combine these two processes to propose an effective recurrent video deblurring network that fully exploits deblurred previous frames. Experiments show that our method achieves the state-of-the-art performance both quantitatively and qualitatively compared to recent methods that use deep learning.
3D-ANAS v2: Grafting Transformer Module on Automatically Designed ConvNet for Hyperspectral Image Classification
Oct 21, 2021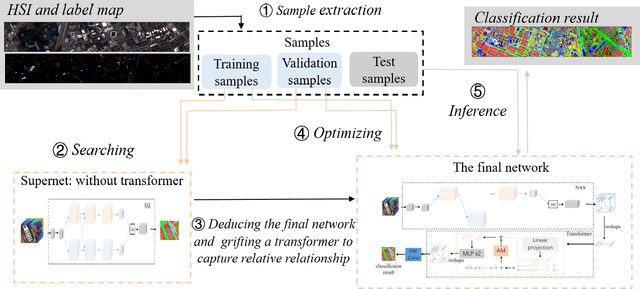
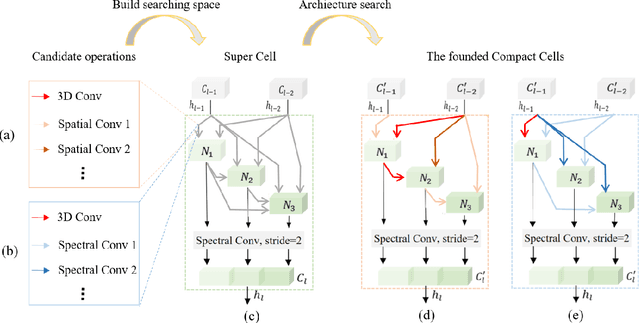
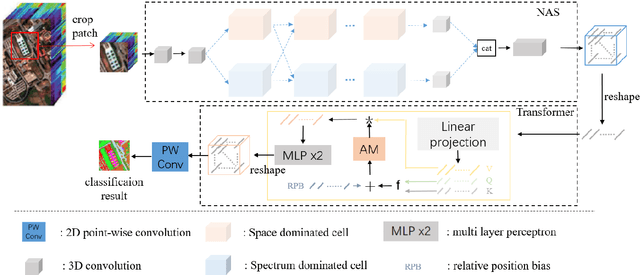
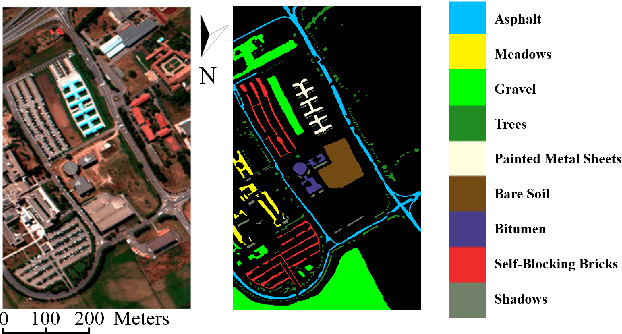
Hyperspectral image (HSI) classification has been a hot topic for decides, as Hyperspectral image has rich spatial and spectral information, providing strong basis for distinguishing different land-cover objects. Benefiting from the development of deep learning technologies, deep learning based HSI classification methods have achieved promising performance. Recently, several neural architecture search (NAS) algorithms are proposed for HSI classification, which further improve the accuracy of HSI classification to a new level. In this paper, we revisit the search space designed in previous HSI classification NAS methods and propose a novel hybrid search space, where 3D convolution, 2D spatial convolution and 2D spectral convolution are employed. Compared search space proposed in previous works, the serach space proposed in this paper is more aligned with characteristic of HSI data that is HSIs have a relatively low spatial resolution and an extremely high spectral resolution. In addition, to further improve the classification accuracy, we attempt to graft the emerging transformer module on the automatically designed ConvNet to adding global information to local region focused features learned by ConvNet. We carry out comparison experiments on three public HSI datasets which have different spectral characteristics to evaluate the proposed method. Experimental results show that the proposed method achieves much better performance than comparison approaches, and both adopting the proposed hybrid search space and grafting transformer module improves classification accuracy. Especially on the most recently captured dataset Houston University, overall accuracy is improved by up to nearly 6 percentage points. Code will be available at: https://github.com/xmm/3D-ANAS-V2.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

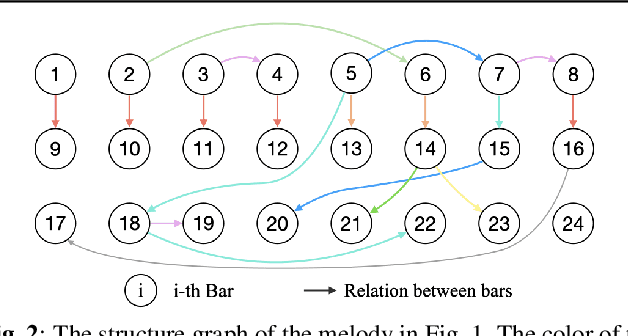
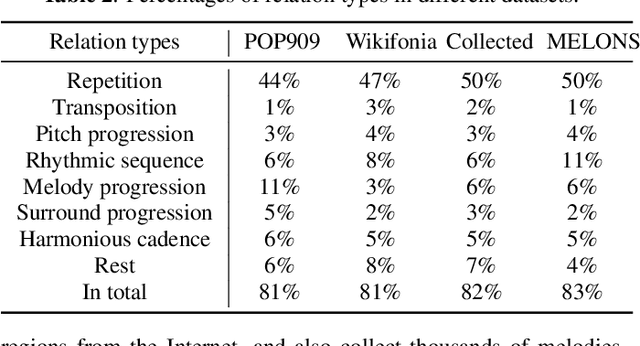
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 23, 2021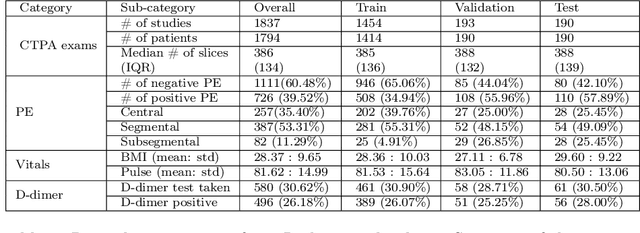
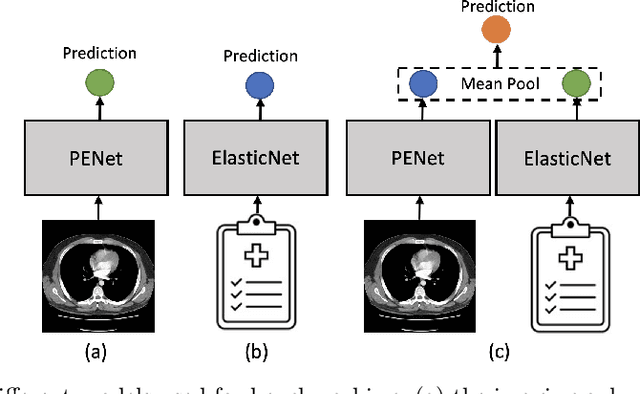
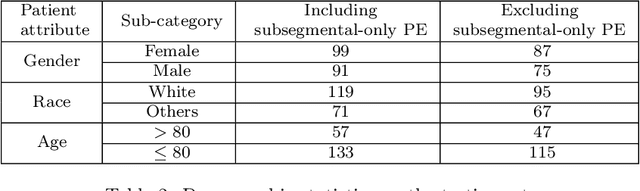
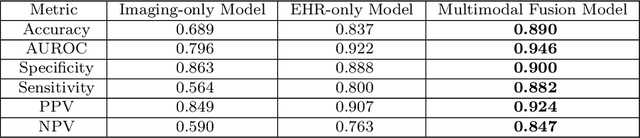
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.
Hard-sample Guided Hybrid Contrast Learning for Unsupervised Person Re-Identification
Sep 25, 2021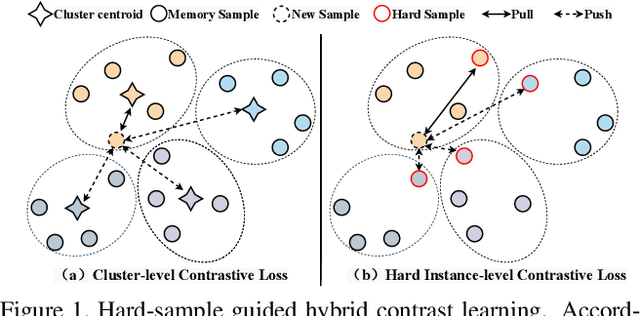
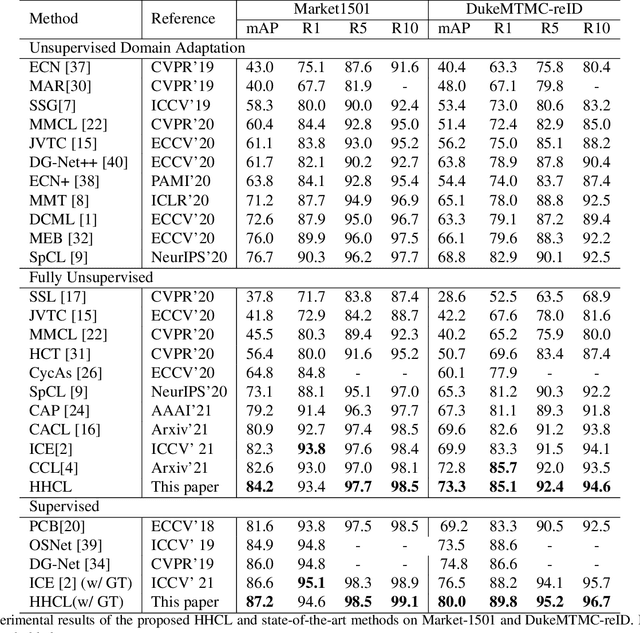
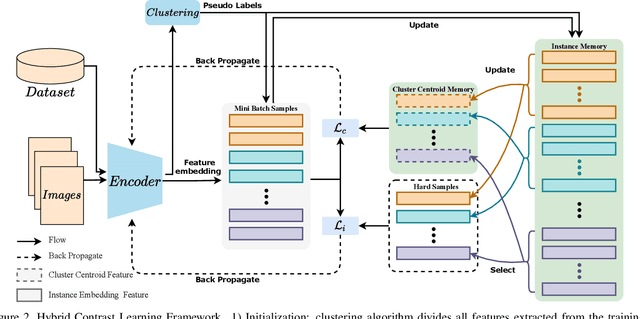
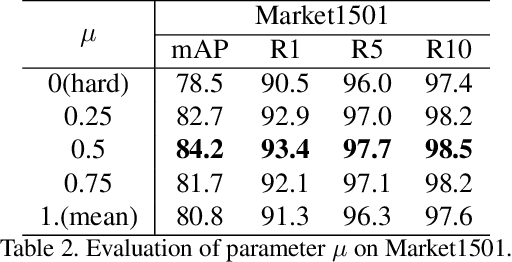
Unsupervised person re-identification (Re-ID) is a promising and very challenging research problem in computer vision. Learning robust and discriminative features with unlabeled data is of central importance to Re-ID. Recently, more attention has been paid to unsupervised Re-ID algorithms based on clustered pseudo-label. However, the previous approaches did not fully exploit information of hard samples, simply using cluster centroid or all instances for contrastive learning. In this paper, we propose a Hard-sample Guided Hybrid Contrast Learning (HHCL) approach combining cluster-level loss with instance-level loss for unsupervised person Re-ID. Our approach applies cluster centroid contrastive loss to ensure that the network is updated in a more stable way. Meanwhile, introduction of a hard instance contrastive loss further mines the discriminative information. Extensive experiments on two popular large-scale Re-ID benchmarks demonstrate that our HHCL outperforms previous state-of-the-art methods and significantly improves the performance of unsupervised person Re-ID. The code of our work is available soon at https://github.com/bupt-ai-cz/HHCL-ReID.
Transformaly -- Two (Feature Spaces) Are Better Than One
Dec 08, 2021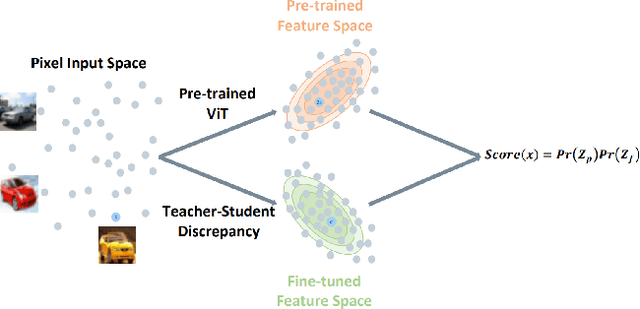
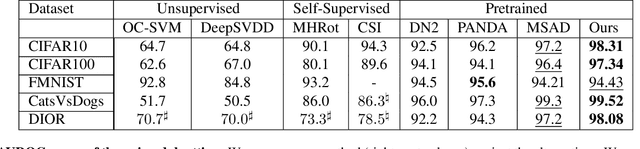
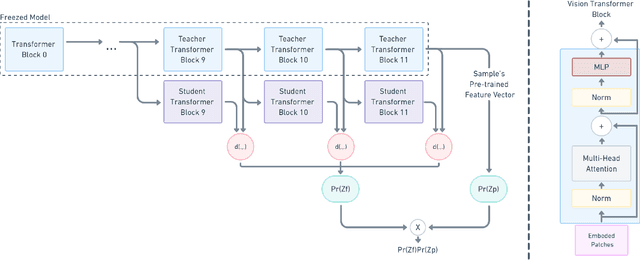
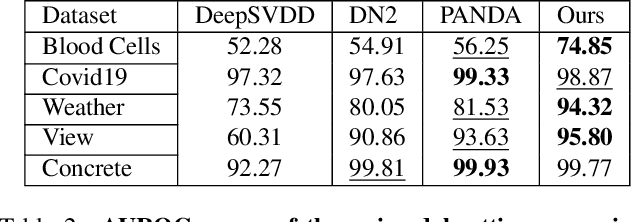
Anomaly detection is a well-established research area that seeks to identify samples outside of a predetermined distribution. An anomaly detection pipeline is comprised of two main stages: (1) feature extraction and (2) normality score assignment. Recent papers used pre-trained networks for feature extraction achieving state-of-the-art results. However, the use of pre-trained networks does not fully-utilize the normal samples that are available at train time. This paper suggests taking advantage of this information by using teacher-student training. In our setting, a pretrained teacher network is used to train a student network on the normal training samples. Since the student network is trained only on normal samples, it is expected to deviate from the teacher network in abnormal cases. This difference can serve as a complementary representation to the pre-trained feature vector. Our method -- Transformaly -- exploits a pre-trained Vision Transformer (ViT) to extract both feature vectors: the pre-trained (agnostic) features and the teacher-student (fine-tuned) features. We report state-of-the-art AUROC results in both the common unimodal setting, where one class is considered normal and the rest are considered abnormal, and the multimodal setting, where all classes but one are considered normal, and just one class is considered abnormal. The code is available at https://github.com/MatanCohen1/Transformaly.
Federated Learning with Correlated Data: Taming the Tail for Age-Optimal Industrial IoT
Aug 17, 2021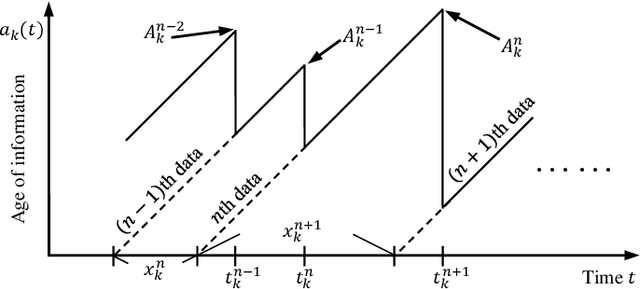

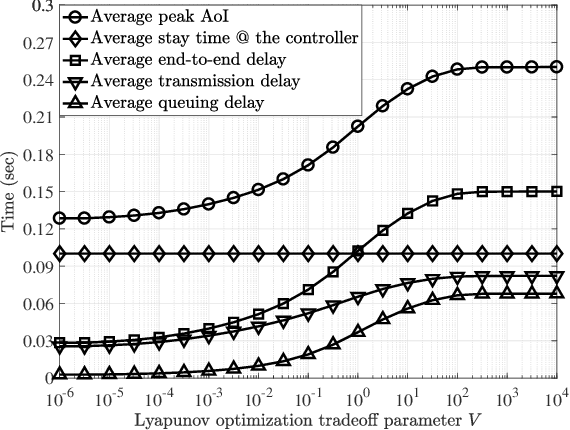
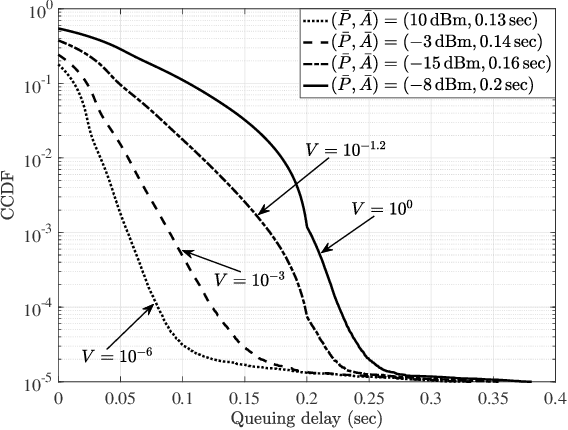
While information delivery in industrial Internet of things demands reliability and latency guarantees, the freshness of the controller's available information, measured by the age of information (AoI), is paramount for high-performing industrial automation. The problem in this work is cast as a sensor's transmit power minimization subject to the peak-AoI requirement and a probabilistic constraint on queuing latency. We further characterize the tail behavior of the latency by a generalized Pareto distribution (GPD) for solving the power allocation problem through Lyapunov optimization. As each sensor utilizes its own data to locally train the GPD model, we incorporate federated learning and propose a local-model selection approach which accounts for correlation among the sensor's training data. Numerical results show the tradeoff between the transmit power, peak AoI, and delay's tail distribution. Furthermore, we verify the superiority of the proposed correlation-aware approach for selecting the local models in federated learning over an existing baseline.