 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HVTR: Hybrid Volumetric-Textural Rendering for Human Avatars
Dec 19, 2021

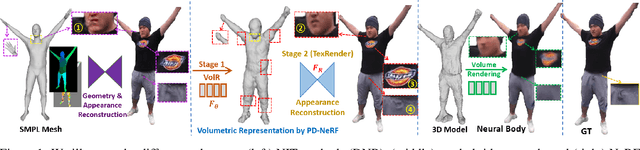
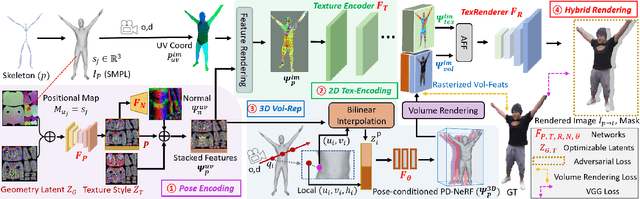
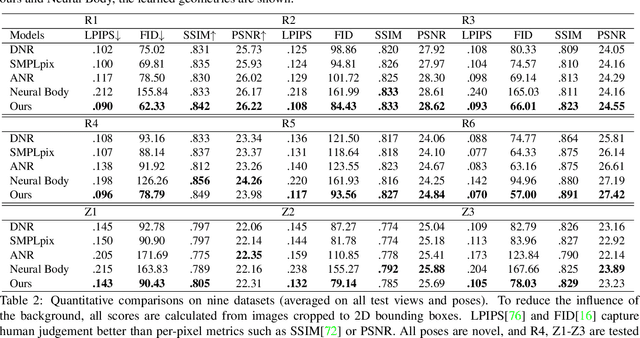
We propose a novel neural rendering pipeline, Hybrid Volumetric-Textural Rendering (HVTR), which synthesizes virtual human avatars from arbitrary poses efficiently and at high quality. First, we learn to encode articulated human motions on a dense UV manifold of the human body surface. To handle complicated motions (e.g., self-occlusions), we then leverage the encoded information on the UV manifold to construct a 3D volumetric representation based on a dynamic pose-conditioned neural radiance field. While this allows us to represent 3D geometry with changing topology, volumetric rendering is computationally heavy. Hence we employ only a rough volumetric representation using a pose-conditioned downsampled neural radiance field (PD-NeRF), which we can render efficiently at low resolutions. In addition, we learn 2D textural features that are fused with rendered volumetric features in image space. The key advantage of our approach is that we can then convert the fused features into a high resolution, high-quality avatar by a fast GAN-based textural renderer. We demonstrate that hybrid rendering enables HVTR to handle complicated motions, render high-quality avatars under user-controlled poses/shapes and even loose clothing, and most importantly, be fast at inference time. Our experimental results also demonstrate state-of-the-art quantitative results.
Knowledge-Aware Neural Networks for Medical Forum Question Classification
Sep 27, 2021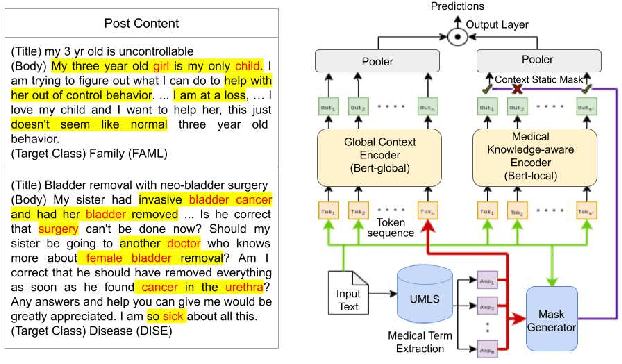
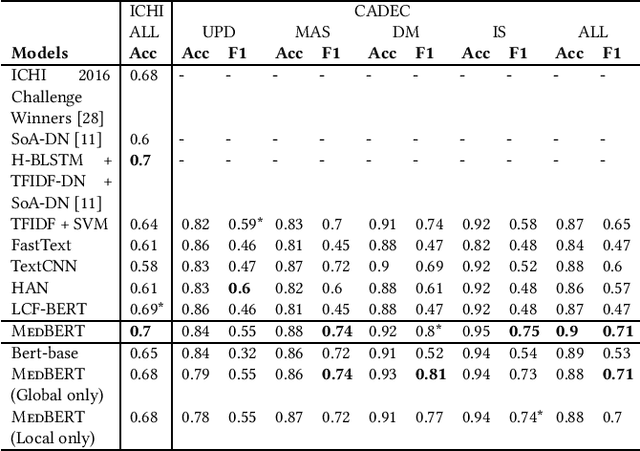
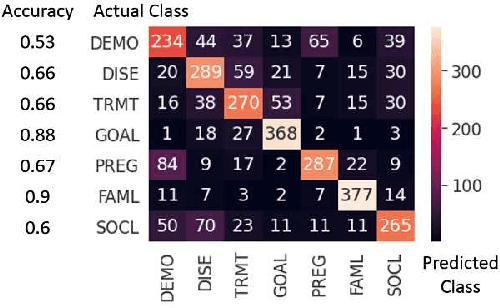
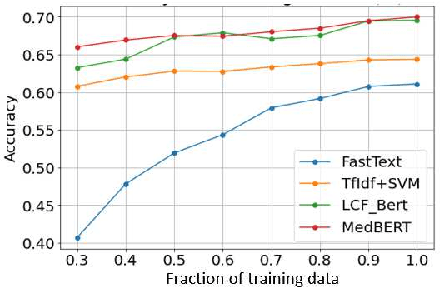
Online medical forums have become a predominant platform for answering health-related information needs of consumers. However, with a significant rise in the number of queries and the limited availability of experts, it is necessary to automatically classify medical queries based on a consumer's intention, so that these questions may be directed to the right set of medical experts. Here, we develop a novel medical knowledge-aware BERT-based model (MedBERT) that explicitly gives more weightage to medical concept-bearing words, and utilize domain-specific side information obtained from a popular medical knowledge base. We also contribute a multi-label dataset for the Medical Forum Question Classification (MFQC) task. MedBERT achieves state-of-the-art performance on two benchmark datasets and performs very well in low resource settings.
Heuristic Search Planning with Deep Neural Networks using Imitation, Attention and Curriculum Learning
Dec 03, 2021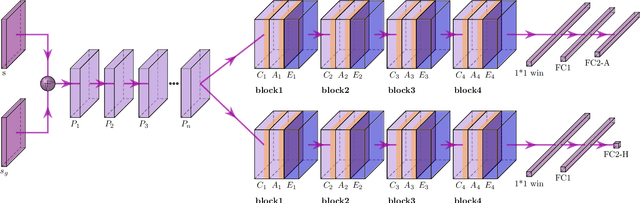
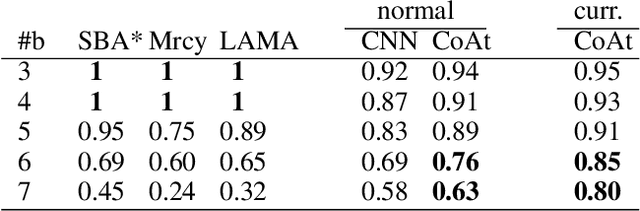
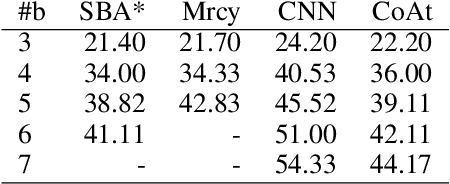
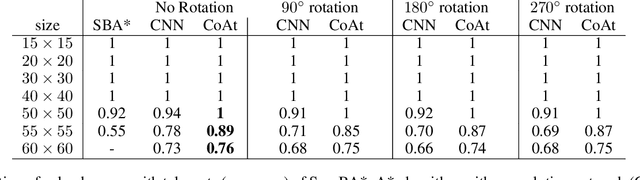
Learning a well-informed heuristic function for hard task planning domains is an elusive problem. Although there are known neural network architectures to represent such heuristic knowledge, it is not obvious what concrete information is learned and whether techniques aimed at understanding the structure help in improving the quality of the heuristics. This paper presents a network model to learn a heuristic capable of relating distant parts of the state space via optimal plan imitation using the attention mechanism, which drastically improves the learning of a good heuristic function. To counter the limitation of the method in the creation of problems of increasing difficulty, we demonstrate the use of curriculum learning, where newly solved problem instances are added to the training set, which, in turn, helps to solve problems of higher complexities and far exceeds the performances of all existing baselines including classical planning heuristics. We demonstrate its effectiveness for grid-type PDDL domains.
End-to-End Learning of Multi-category 3D Pose and Shape Estimation
Dec 19, 2021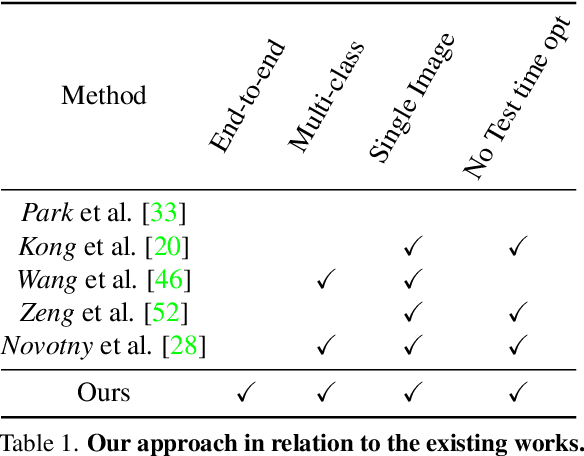

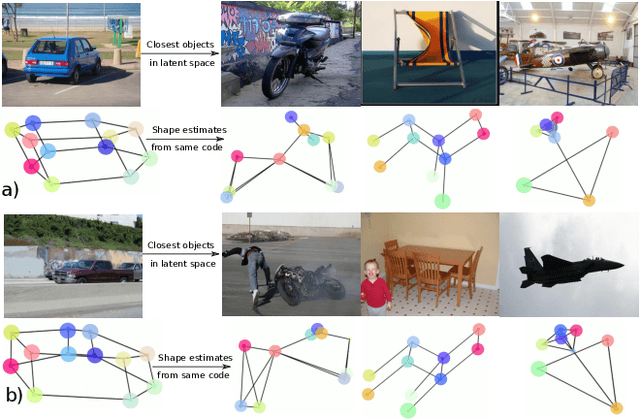
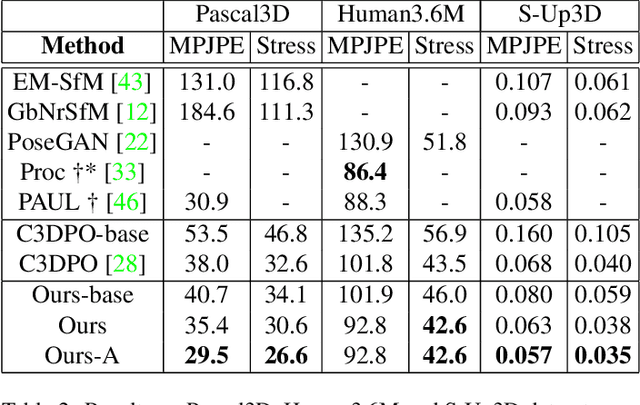
In this paper, we study the representation of the shape and pose of objects using their keypoints. Therefore, we propose an end-to-end method that simultaneously detects 2D keypoints from an image and lifts them to 3D. The proposed method learns both 2D detection and 3D lifting only from 2D keypoints annotations. In this regard, a novel method that explicitly disentangles the pose and 3D shape by means of augmentation-based cyclic self-supervision is proposed, for the first time. In addition of being end-to-end in image to 3D learning, our method also handles objects from multiple categories using a single neural network. We use a Transformer-based architecture to detect the keypoints, as well as to summarize the visual context of the image. This visual context information is then used while lifting the keypoints to 3D, so as to allow the context-based reasoning for better performance. While lifting, our method learns a small set of basis shapes and their sparse non-negative coefficients to represent the 3D shape in canonical frame. Our method can handle occlusions as well as wide variety of object classes. Our experiments on three benchmarks demonstrate that our method performs better than the state-of-the-art. Our source code will be made publicly available.
Translation Transformers Rediscover Inherent Data Domains
Sep 16, 2021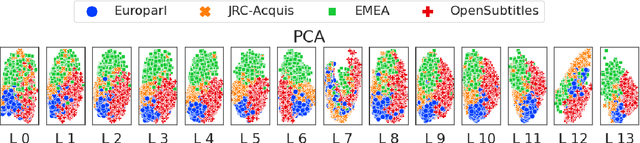
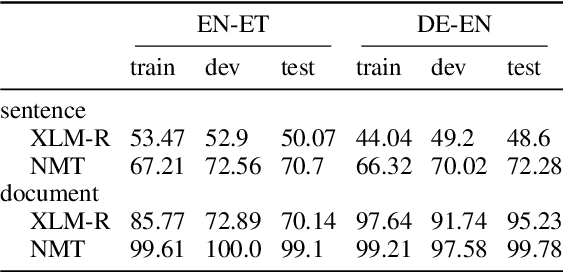
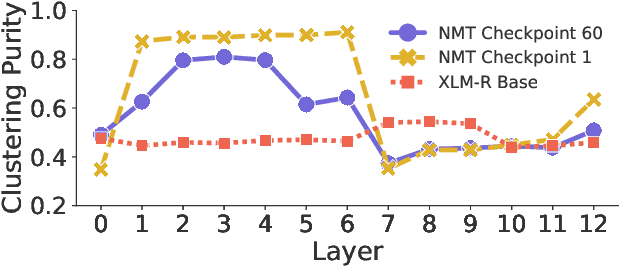
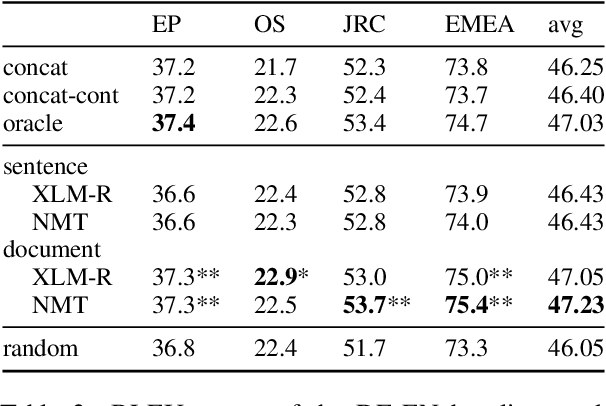
Many works proposed methods to improve the performance of Neural Machine Translation (NMT) models in a domain/multi-domain adaptation scenario. However, an understanding of how NMT baselines represent text domain information internally is still lacking. Here we analyze the sentence representations learned by NMT Transformers and show that these explicitly include the information on text domains, even after only seeing the input sentences without domains labels. Furthermore, we show that this internal information is enough to cluster sentences by their underlying domains without supervision. We show that NMT models produce clusters better aligned to the actual domains compared to pre-trained language models (LMs). Notably, when computed on document-level, NMT cluster-to-domain correspondence nears 100%. We use these findings together with an approach to NMT domain adaptation using automatically extracted domains. Whereas previous work relied on external LMs for text clustering, we propose re-using the NMT model as a source of unsupervised clusters. We perform an extensive experimental study comparing two approaches across two data scenarios, three language pairs, and both sentence-level and document-level clustering, showing equal or significantly superior performance compared to LMs.
Direct Multi-view Multi-person 3D Pose Estimation
Nov 07, 2021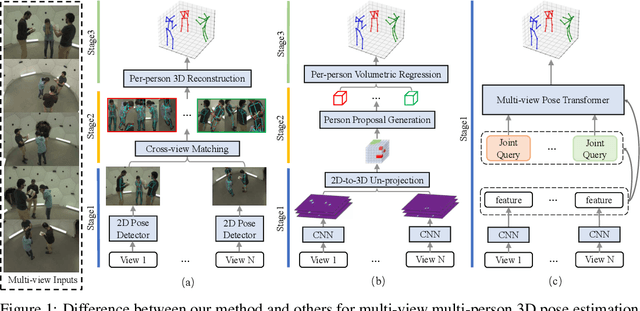

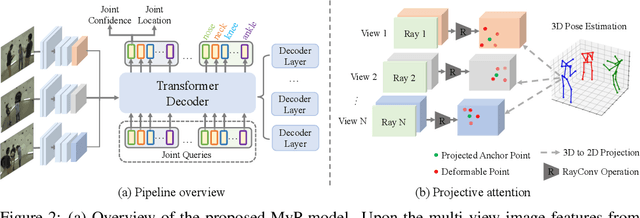
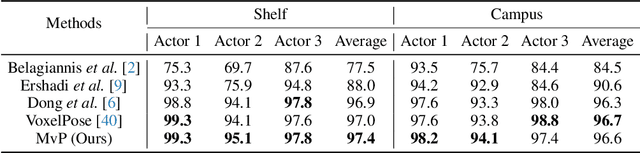
We present Multi-view Pose transformer (MvP) for estimating multi-person 3D poses from multi-view images. Instead of estimating 3D joint locations from costly volumetric representation or reconstructing the per-person 3D pose from multiple detected 2D poses as in previous methods, MvP directly regresses the multi-person 3D poses in a clean and efficient way, without relying on intermediate tasks. Specifically, MvP represents skeleton joints as learnable query embeddings and let them progressively attend to and reason over the multi-view information from the input images to directly regress the actual 3D joint locations. To improve the accuracy of such a simple pipeline, MvP presents a hierarchical scheme to concisely represent query embeddings of multi-person skeleton joints and introduces an input-dependent query adaptation approach. Further, MvP designs a novel geometrically guided attention mechanism, called projective attention, to more precisely fuse the cross-view information for each joint. MvP also introduces a RayConv operation to integrate the view-dependent camera geometry into the feature representations for augmenting the projective attention. We show experimentally that our MvP model outperforms the state-of-the-art methods on several benchmarks while being much more efficient. Notably, it achieves 92.3% AP25 on the challenging Panoptic dataset, improving upon the previous best approach [36] by 9.8%. MvP is general and also extendable to recovering human mesh represented by the SMPL model, thus useful for modeling multi-person body shapes. Code and models are available at https://github.com/sail-sg/mvp.
EIHW-MTG DiCOVA 2021 Challenge System Report
Oct 13, 2021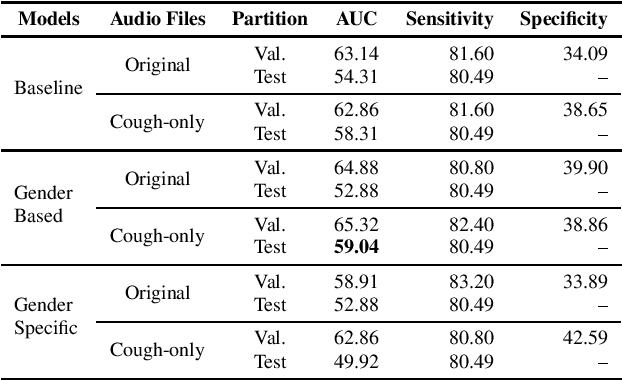
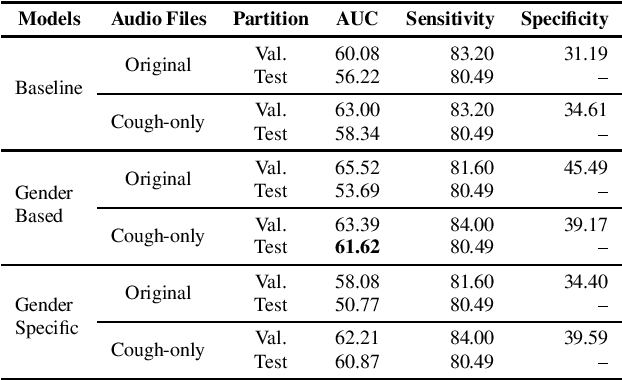
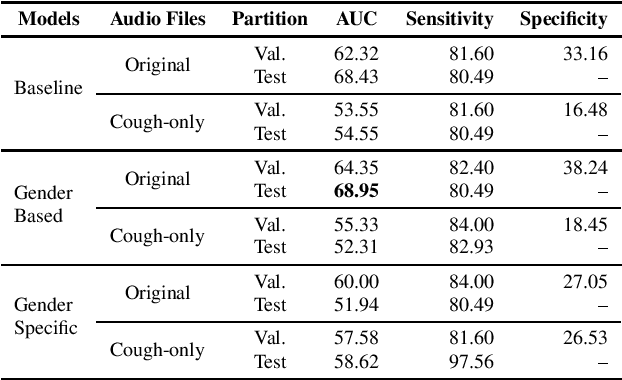
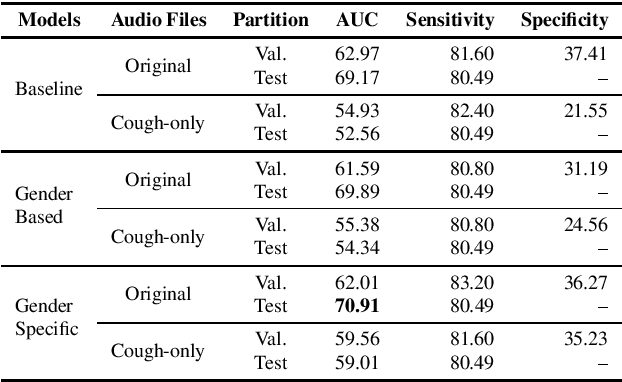
This paper aims to automatically detect COVID-19 patients by analysing the acoustic information embedded in coughs. COVID-19 affects the respiratory system, and, consequently, respiratory-related signals have the potential to contain salient information for the task at hand. We focus on analysing the spectrogram representations of coughing samples with the aim to investigate whether COVID-19 alters the frequency content of these signals. Furthermore, this work also assesses the impact of gender in the automatic detection of COVID-19. To extract deep learnt representations of the spectrograms, we compare the performance of a cough-specific, and a Resnet18 pre-trained Convolutional Neural Network (CNN). Additionally, our approach explores the use of contextual attention, so the model can learn to highlight the most relevant deep learnt features extracted by the CNN. We conduct our experiments on the dataset released for the Cough Sound Track of the DiCOVA 2021 Challenge. The best performance on the test set is obtained using the Resnet18 pre-trained CNN with contextual attention, which scored an Area Under the Curve (AUC) of 70.91 at 80% sensitivity.
Reducing Catastrophic Forgetting in Self Organizing Maps with Internally-Induced Generative Replay
Dec 09, 2021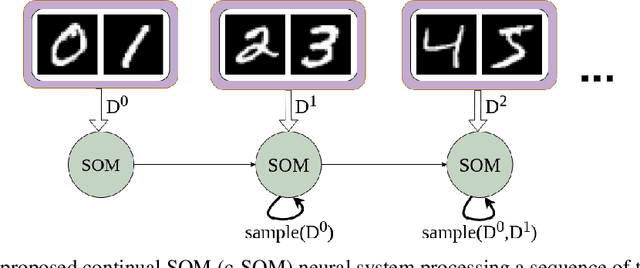


A lifelong learning agent is able to continually learn from potentially infinite streams of pattern sensory data. One major historic difficulty in building agents that adapt in this way is that neural systems struggle to retain previously-acquired knowledge when learning from new samples. This problem is known as catastrophic forgetting (interference) and remains an unsolved problem in the domain of machine learning to this day. While forgetting in the context of feedforward networks has been examined extensively over the decades, far less has been done in the context of alternative architectures such as the venerable self-organizing map (SOM), an unsupervised neural model that is often used in tasks such as clustering and dimensionality reduction. Although the competition among its internal neurons might carry the potential to improve memory retention, we observe that a fixed-sized SOM trained on task incremental data, i.e., it receives data points related to specific classes at certain temporal increments, experiences significant forgetting. In this study, we propose the continual SOM (c-SOM), a model that is capable of reducing its own forgetting when processing information.
Understanding the Effect of Stochasticity in Policy Optimization
Oct 29, 2021

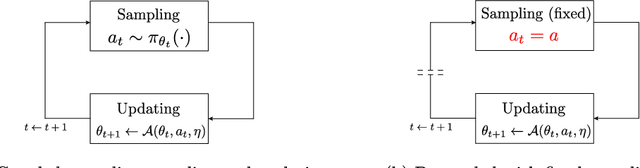
We study the effect of stochasticity in on-policy policy optimization, and make the following four contributions. First, we show that the preferability of optimization methods depends critically on whether stochastic versus exact gradients are used. In particular, unlike the true gradient setting, geometric information cannot be easily exploited in the stochastic case for accelerating policy optimization without detrimental consequences or impractical assumptions. Second, to explain these findings we introduce the concept of committal rate for stochastic policy optimization, and show that this can serve as a criterion for determining almost sure convergence to global optimality. Third, we show that in the absence of external oracle information, which allows an algorithm to determine the difference between optimal and sub-optimal actions given only on-policy samples, there is an inherent trade-off between exploiting geometry to accelerate convergence versus achieving optimality almost surely. That is, an uninformed algorithm either converges to a globally optimal policy with probability $1$ but at a rate no better than $O(1/t)$, or it achieves faster than $O(1/t)$ convergence but then must fail to converge to the globally optimal policy with some positive probability. Finally, we use the committal rate theory to explain why practical policy optimization methods are sensitive to random initialization, then develop an ensemble method that can be guaranteed to achieve near-optimal solutions with high probability.
Raising context awareness in motion forecasting
Sep 16, 2021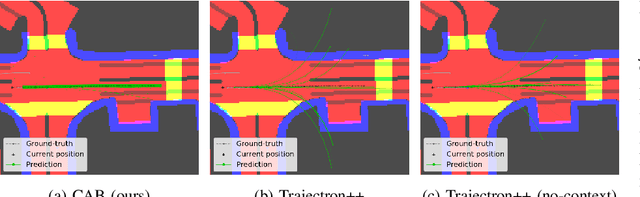
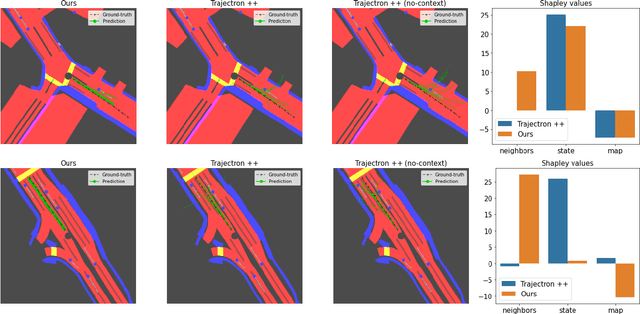
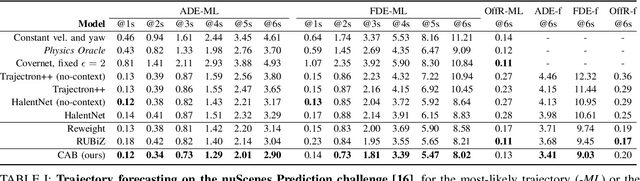
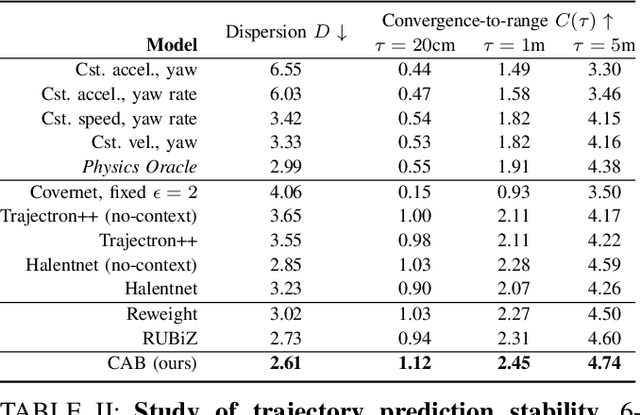
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.