 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks on Locally Private Graph Neural Networks
Mar 21, 2026Graph neural network (GNN) is a powerful tool for analyzing graph-structured data. However, their vulnerability to adversarial attacks raises serious concerns, especially when dealing with sensitive information. Local Differential Privacy (LDP) offers a privacy-preserving framework for training GNNs, but its impact on adversarial robustness remains underexplored. This paper investigates adversarial attacks on LDP-protected GNNs. We explore how the privacy guarantees of LDP can be leveraged or hindered by adversarial perturbations. The effectiveness of existing attack methods on LDP-protected GNNs are analyzed and potential challenges in crafting adversarial examples under LDP constraints are discussed. Additionally, we suggest directions for defending LDP-protected GNNs against adversarial attacks. This work investigates the interplay between privacy and security in graph learning, highlighting the need for robust and privacy-preserving GNN architectures.
Generation of Human Comprehensible Access Control Policies from Audit Logs
Mar 15, 2026Over the years, access control systems have become increasingly more complex, often causing a disconnect between what is envisaged by the stakeholders in decision-making positions and the actual permissions granted as evidenced from access logs. For instance, Attribute-based Access Control (ABAC), which is a flexible yet complex model typically configured by system security officers, can be made understandable to others only when presented at a high level in natural language. Although several algorithms have been proposed in the literature for automatic extraction of ABAC rules from access logs, there is no attempt yet to bridge the semantic gap between the machine-enforceable formal logic and human-centric policy intent. Our work addresses this problem by developing a framework that generates human understandable natural language access control policies from logs. We investigate to what extent the power of Large Language Models (LLMs) can be harnessed to achieve both accuracy and scalability in the process. Named LANTERN (LLM-based ABAC Natural Translation and Explanation for Rule Navigation), we have instantiated the framework as a publicly accessible web based application for reproducibility of our results.
Strategic Incentivization for Locally Differentially Private Federated Learning
Aug 10, 2025In Federated Learning (FL), multiple clients jointly train a machine learning model by sharing gradient information, instead of raw data, with a server over multiple rounds. To address the possibility of information leakage in spite of sharing only the gradients, Local Differential Privacy (LDP) is often used. In LDP, clients add a selective amount of noise to the gradients before sending the same to the server. Although such noise addition protects the privacy of clients, it leads to a degradation in global model accuracy. In this paper, we model this privacy-accuracy trade-off as a game, where the sever incentivizes the clients to add a lower degree of noise for achieving higher accuracy, while the clients attempt to preserve their privacy at the cost of a potential loss in accuracy. A token based incentivization mechanism is introduced in which the quantum of tokens credited to a client in an FL round is a function of the degree of perturbation of its gradients. The client can later access a newly updated global model only after acquiring enough tokens, which are to be deducted from its balance. We identify the players, their actions and payoff, and perform a strategic analysis of the game. Extensive experiments were carried out to study the impact of different parameters.
SolRPDS: A Dataset for Analyzing Rug Pulls in Solana Decentralized Finance
Apr 06, 2025Rug pulls in Solana have caused significant damage to users interacting with Decentralized Finance (DeFi). A rug pull occurs when developers exploit users' trust and drain liquidity from token pools on Decentralized Exchanges (DEXs), leaving users with worthless tokens. Although rug pulls in Ethereum and Binance Smart Chain (BSC) have gained attention recently, analysis of rug pulls in Solana remains largely under-explored. In this paper, we introduce SolRPDS (Solana Rug Pull Dataset), the first public rug pull dataset derived from Solana's transactions. We examine approximately four years of DeFi data (2021-2024) that covers suspected and confirmed tokens exhibiting rug pull patterns. The dataset, derived from 3.69 billion transactions, consists of 62,895 suspicious liquidity pools. The data is annotated for inactivity states, which is a key indicator, and includes several detailed liquidity activities such as additions, removals, and last interaction as well as other attributes such as inactivity periods and withdrawn token amounts, to help identify suspicious behavior. Our preliminary analysis reveals clear distinctions between legitimate and fraudulent liquidity pools and we found that 22,195 tokens in the dataset exhibit rug pull patterns during the examined period. SolRPDS can support a wide range of future research on rug pulls including the development of data-driven and heuristic-based solutions for real-time rug pull detection and mitigation.
Generation of Optimized Solidity Code for Machine Learning Models using LLMs
Mar 08, 2025



While a plethora of machine learning (ML) models are currently available, along with their implementation on disparate platforms, there is hardly any verifiable ML code which can be executed on public blockchains. We propose a novel approach named LMST that enables conversion of the inferencing path of an ML model as well as its weights trained off-chain into Solidity code using Large Language Models (LLMs). Extensive prompt engineering is done to achieve gas cost optimization beyond mere correctness of the produced code, while taking into consideration the capabilities and limitations of the Ethereum Virtual Machine. We have also developed a proof of concept decentralized application using the code so generated for verifying the accuracy claims of the underlying ML model. An extensive set of experiments demonstrate the feasibility of deploying ML models on blockchains through automated code translation using LLMs.
LMN: A Tool for Generating Machine Enforceable Policies from Natural Language Access Control Rules using LLMs
Feb 18, 2025



Organizations often lay down rules or guidelines called Natural Language Access Control Policies (NLACPs) for specifying who gets access to which information and when. However, these cannot be directly used in a target access control model like Attribute-based Access Control (ABAC). Manually translating the NLACP rules into Machine Enforceable Security Policies (MESPs) is both time consuming and resource intensive, rendering it infeasible especially for large organizations. Automated machine translation workflows, on the other hand, require information security officers to be adept at using such processes. To effectively address this problem, we have developed a free web-based publicly accessible tool called LMN (LLMs for generating MESPs from NLACPs) that takes an NLACP as input and converts it into a corresponding MESP. Internally, LMN uses the GPT 3.5 API calls and an appropriately chosen prompt. Extensive experiments with different prompts and performance metrics firmly establish the usefulness of LMN.
Heterogeneous Graph Generation: A Hierarchical Approach using Node Feature Pooling
Oct 15, 2024



Heterogeneous graphs are present in various domains, such as social networks, recommendation systems, and biological networks. Unlike homogeneous graphs, heterogeneous graphs consist of multiple types of nodes and edges, each representing different entities and relationships. Generating realistic heterogeneous graphs that capture the complex interactions among diverse entities is a difficult task due to several reasons. The generator has to model both the node type distribution along with the feature distribution for each node type. In this paper, we look into solving challenges in heterogeneous graph generation, by employing a two phase hierarchical structure, wherein the first phase creates a skeleton graph with node types using a prior diffusion based model and in the second phase, we use an encoder and a sampler structure as generator to assign node type specific features to the nodes. A discriminator is used to guide training of the generator and feature vectors are sampled from a node feature pool. We conduct extensive experiments with subsets of IMDB and DBLP datasets to show the effectiveness of our method and also the need for various architecture components.
Unlocking Efficiency: Adaptive Masking for Gene Transformer Models
Aug 13, 2024



Gene transformer models such as Nucleotide Transformer, DNABert, and LOGO are trained to learn optimal gene sequence representations by using the Masked Language Modeling (MLM) training objective over the complete Human Reference Genome. However, the typical tokenization methods employ a basic sliding window of tokens, such as k-mers, that fail to utilize gene-centric semantics. This could result in the (trivial) masking of easily predictable sequences, leading to inefficient MLM training. Time-variant training strategies are known to improve pretraining efficiency in both language and vision tasks. In this work, we focus on using curriculum masking where we systematically increase the difficulty of masked token prediction task by using a Pointwise Mutual Information-based difficulty criterion, as gene sequences lack well-defined semantic units similar to words or sentences of NLP domain. Our proposed Curriculum Masking-based Gene Masking Strategy (CM-GEMS) demonstrates superior representation learning capabilities compared to baseline masking approaches when evaluated on downstream gene sequence classification tasks. We perform extensive evaluation in both few-shot (five datasets) and full dataset settings (Genomic Understanding Evaluation benchmark consisting of 27 tasks). Our findings reveal that CM-GEMS outperforms state-of-the-art models (DNABert-2, Nucleotide transformer, DNABert) trained at 120K steps, achieving similar results in just 10K and 1K steps. We also demonstrate that Curriculum-Learned LOGO (a 2-layer DNABert-like model) can achieve nearly 90% of the state-of-the-art model performance of 120K steps. We will make the models and codes publicly available at https://github.com/roysoumya/curriculum-GeneMask.
BOXREC: Recommending a Box of Preferred Outfits in Online Shopping
Feb 26, 2024



Over the past few years, automation of outfit composition has gained much attention from the research community. Most of the existing outfit recommendation systems focus on pairwise item compatibility prediction (using visual and text features) to score an outfit combination having several items, followed by recommendation of top-n outfits or a capsule wardrobe having a collection of outfits based on user's fashion taste. However, none of these consider user's preference of price-range for individual clothing types or an overall shopping budget for a set of items. In this paper, we propose a box recommendation framework - BOXREC - which at first, collects user preferences across different item types (namely, top-wear, bottom-wear and foot-wear) including price-range of each type and a maximum shopping budget for a particular shopping session. It then generates a set of preferred outfits by retrieving all types of preferred items from the database (according to user specified preferences including price-ranges), creates all possible combinations of three preferred items (belonging to distinct item types) and verifies each combination using an outfit scoring framework - BOXREC-OSF. Finally, it provides a box full of fashion items, such that different combinations of the items maximize the number of outfits suitable for an occasion while satisfying maximum shopping budget. Empirical results show superior performance of BOXREC-OSF over the baseline methods.
Knowledge-Aware Neural Networks for Medical Forum Question Classification
Sep 27, 2021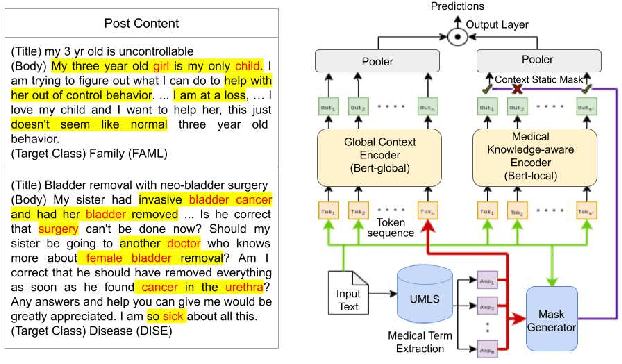
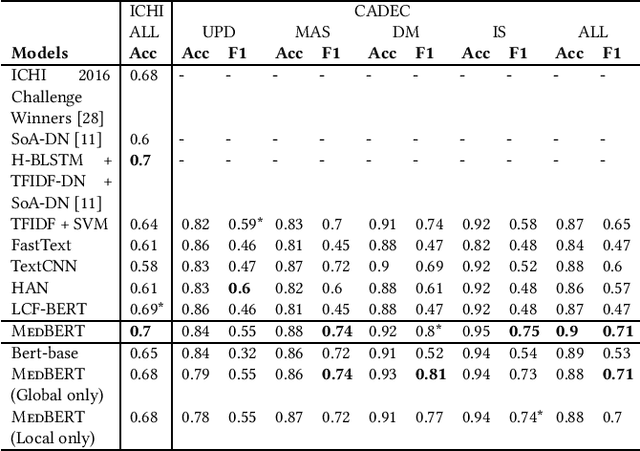
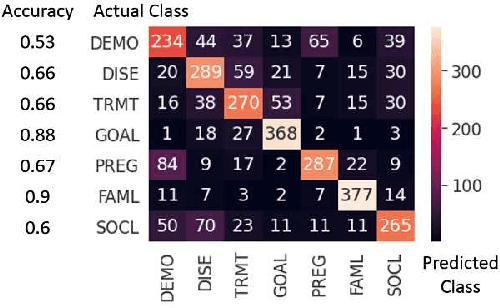
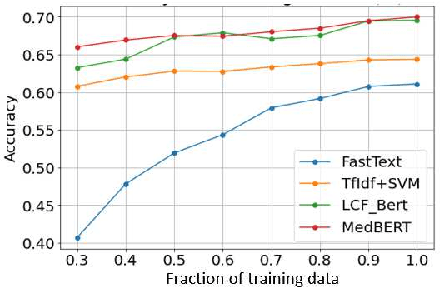
Online medical forums have become a predominant platform for answering health-related information needs of consumers. However, with a significant rise in the number of queries and the limited availability of experts, it is necessary to automatically classify medical queries based on a consumer's intention, so that these questions may be directed to the right set of medical experts. Here, we develop a novel medical knowledge-aware BERT-based model (MedBERT) that explicitly gives more weightage to medical concept-bearing words, and utilize domain-specific side information obtained from a popular medical knowledge base. We also contribute a multi-label dataset for the Medical Forum Question Classification (MFQC) task. MedBERT achieves state-of-the-art performance on two benchmark datasets and performs very well in low resource settings.