 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio
Jul 19, 2024



Recent advancements in music generation are raising multiple concerns about the implications of AI in creative music processes, current business models and impacts related to intellectual property management. A relevant challenge is the potential replication and plagiarism of the training set in AI-generated music, which could lead to misuse of data and intellectual property rights violations. To tackle this issue, we present the Music Replication Assessment (MiRA) tool: a model-independent open evaluation method based on diverse audio music similarity metrics to assess data replication of the training set. We evaluate the ability of five metrics to identify exact replication, by conducting a controlled replication experiment in different music genres based on synthetic samples. Our results show that the proposed methodology can estimate exact data replication with a proportion higher than 10%. By introducing the MiRA tool, we intend to encourage the open evaluation of music generative models by researchers, developers and users concerning data replication, highlighting the importance of ethical, social, legal and economic consequences of generative AI in the music domain.
Attribute Annotation and Bias Evaluation in Visual Datasets for Autonomous Driving
Dec 11, 2023This paper addresses the often overlooked issue of fairness in the autonomous driving domain, particularly in vision-based perception and prediction systems, which play a pivotal role in the overall functioning of Autonomous Vehicles (AVs). We focus our analysis on biases present in some of the most commonly used visual datasets for training person and vehicle detection systems. We introduce an annotation methodology and a specialised annotation tool, both designed to annotate protected attributes of agents in visual datasets. We validate our methodology through an inter-rater agreement analysis and provide the distribution of attributes across all datasets. These include annotations for the attributes age, sex, skin tone, group, and means of transport for more than 90K people, as well as vehicle type, colour, and car type for over 50K vehicles. Generally, diversity is very low for most attributes, with some groups, such as children, wheelchair users, or personal mobility vehicle users, being extremely underrepresented in the analysed datasets. The study contributes significantly to efforts to consider fairness in the evaluation of perception and prediction systems for AVs. This paper follows reproducibility principles. The annotation tool, scripts and the annotated attributes can be accessed publicly at https://github.com/ec-jrc/humaint_annotator.
Behind Recommender Systems: the Geography of the ACM RecSys Community
Sep 07, 2023The amount and dissemination rate of media content accessible online is nowadays overwhelming. Recommender Systems filter this information into manageable streams or feeds, adapted to our personal needs or preferences. It is of utter importance that algorithms employed to filter information do not distort or cut out important elements from our perspectives of the world. Under this principle, it is essential to involve diverse views and teams from the earliest stages of their design and development. This has been highlighted, for instance, in recent European Union regulations such as the Digital Services Act, via the requirement of risk monitoring, including the risk of discrimination, and the AI Act, through the requirement to involve people with diverse backgrounds in the development of AI systems. We look into the geographic diversity of the recommender systems research community, specifically by analyzing the affiliation countries of the authors who contributed to the ACM Conference on Recommender Systems (RecSys) during the last 15 years. This study has been carried out in the framework of the Diversity in AI - DivinAI project, whose main objective is the long-term monitoring of diversity in AI forums through a set of indexes.
Use case cards: a use case reporting framework inspired by the European AI Act
Jun 23, 2023



Despite recent efforts by the Artificial Intelligence (AI) community to move towards standardised procedures for documenting models, methods, systems or datasets, there is currently no methodology focused on use cases aligned with the risk-based approach of the European AI Act (AI Act). In this paper, we propose a new framework for the documentation of use cases, that we call "use case cards", based on the use case modelling included in the Unified Markup Language (UML) standard. Unlike other documentation methodologies, we focus on the intended purpose and operational use of an AI system. It consists of two main parts. Firstly, a UML-based template, tailored to allow implicitly assessing the risk level of the AI system and defining relevant requirements. Secondly, a supporting UML diagram designed to provide information about the system-user interactions and relationships. The proposed framework is the result of a co-design process involving a relevant team of EU policy experts and scientists. We have validated our proposal with 11 experts with different backgrounds and a reasonable knowledge of the AI Act as a prerequisite. We provide the 5 "use case cards" used in the co-design and validation process. "Use case cards" allows framing and contextualising use cases in an effective way, and we hope this methodology can be a useful tool for policy makers and providers for documenting use cases, assessing the risk level, adapting the different requirements and building a catalogue of existing usages of AI.
Fairness and Diversity in Information Access Systems
May 16, 2023Among the seven key requirements to achieve trustworthy AI proposed by the High-Level Expert Group on Artificial Intelligence (AI-HLEG) established by the European Commission (EC), the fifth requirement ("Diversity, non-discrimination and fairness") declares: "In order to achieve Trustworthy AI, we must enable inclusion and diversity throughout the entire AI system's life cycle. [...] This requirement is closely linked with the principle of fairness". In this paper, we try to shed light on how closely these two distinct concepts, diversity and fairness, may be treated by focusing on information access systems and ranking literature. These concepts should not be used interchangeably because they do represent two different values, but what we argue is that they also cannot be considered totally unrelated or divergent. Having diversity does not imply fairness, but fostering diversity can effectively lead to fair outcomes, an intuition behind several methods proposed to mitigate the disparate impact of information access systems, i.e. recommender systems and search engines.
Assessing the Impact of Music Recommendation Diversity on Listeners: A Longitudinal Study
Dec 01, 2022



We present the results of a 12-week longitudinal user study wherein the participants, 110 subjects from Southern Europe, received on a daily basis Electronic Music (EM) diversified recommendations. By analyzing their explicit and implicit feedback, we show that exposure to specific levels of music recommendation diversity may be responsible for long-term impacts on listeners' attitudes. In particular, we highlight the function of diversity in increasing the openness in listening to EM, a music genre not particularly known or liked by the participants previous to their participation in the study. Moreover, we demonstrate that recommendations may help listeners in removing positive and negative attachments towards EM, deconstructing pre-existing implicit associations but also stereotypes associated with this music. In addition, our results show the significant clout that recommendation diversity has in generating curiosity in listeners.
Liability regimes in the age of AI: a use-case driven analysis of the burden of proof
Nov 03, 2022



New emerging technologies powered by Artificial Intelligence (AI) have the potential to disruptively transform our societies for the better. In particular, data-driven learning approaches (i.e., Machine Learning (ML)) have been a true revolution in the advancement of multiple technologies in various application domains. But at the same time there is growing concerns about certain intrinsic characteristics of these methodologies that carry potential risks to both safety and fundamental rights. Although there are mechanisms in the adoption process to minimize these risks (e.g., safety regulations), these do not exclude the possibility of harm occurring, and if this happens, victims should be able to seek compensation. Liability regimes will therefore play a key role in ensuring basic protection for victims using or interacting with these systems. However, the same characteristics that make AI systems inherently risky, such as lack of causality, opacity, unpredictability or their self and continuous learning capabilities, lead to considerable difficulties when it comes to proving causation. This paper presents three case studies, as well as the methodology to reach them, that illustrate these difficulties. Specifically, we address the cases of cleaning robots, delivery drones and robots in education. The outcome of the proposed analysis suggests the need to revise liability regimes to alleviate the burden of proof on victims in cases involving AI technologies.
Diversity in the Music Listening Experience: Insights from Focus Group Interviews
Jan 25, 2022Music listening in today's digital spaces is highly characterized by the availability of huge music catalogues, accessible by people all over the world. In this scenario, recommender systems are designed to guide listeners in finding tracks and artists that best fit their requests, having therefore the power to influence the diversity of the music they listen to. Albeit several works have proposed new techniques for developing diversity-aware recommendations, little is known about how people perceive diversity while interacting with music recommendations. In this study, we interview several listeners about the role that diversity plays in their listening experience, trying to get a better understanding of how they interact with music recommendations. We recruit the listeners among the participants of a previous quantitative study, where they were confronted with the notion of diversity when asked to identify, from a series of electronic music lists, the most diverse ones according to their beliefs. As a follow-up, in this qualitative study we carry out semi-structured interviews to understand how listeners may assess the diversity of a music list and to investigate their experiences with music recommendation diversity. We report here our main findings on 1) what can influence the diversity assessment of tracks and artists' music lists, and 2) which factors can characterize listeners' interaction with music recommendation diversity.
Personalized musically induced emotions of not-so-popular Colombian music
Dec 09, 2021
This work presents an initial proof of concept of how Music Emotion Recognition (MER) systems could be intentionally biased with respect to annotations of musically induced emotions in a political context. In specific, we analyze traditional Colombian music containing politically charged lyrics of two types: (1) vallenatos and social songs from the "left-wing" guerrilla Fuerzas Armadas Revolucionarias de Colombia (FARC) and (2) corridos from the "right-wing" paramilitaries Autodefensas Unidas de Colombia (AUC). We train personalized machine learning models to predict induced emotions for three users with diverse political views - we aim at identifying the songs that may induce negative emotions for a particular user, such as anger and fear. To this extent, a user's emotion judgements could be interpreted as problematizing data - subjective emotional judgments could in turn be used to influence the user in a human-centered machine learning environment. In short, highly desired "emotion regulation" applications could potentially deviate to "emotion manipulation" - the recent discredit of emotion recognition technologies might transcend ethical issues of diversity and inclusion.
EIHW-MTG: Second DiCOVA Challenge System Report
Oct 18, 2021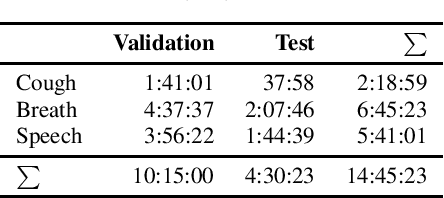
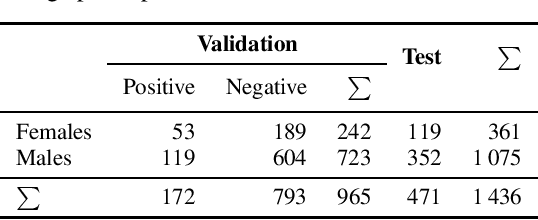
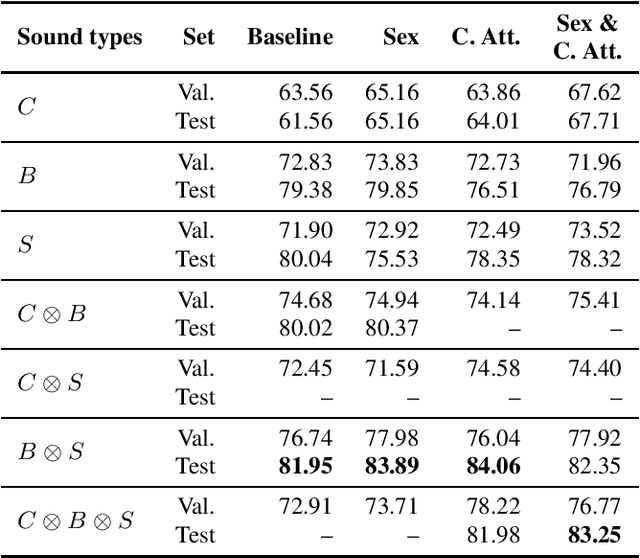
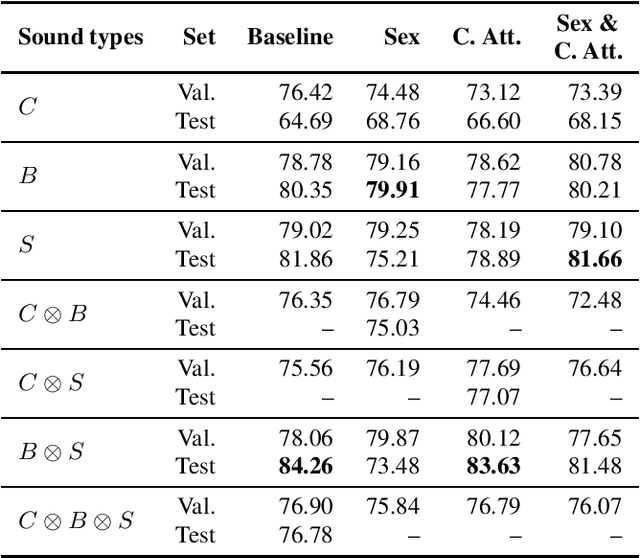
This work presents an outer product-based approach to fuse the embedded representations generated from the spectrograms of cough, breath, and speech samples for the automatic detection of COVID-19. To extract deep learnt representations from the spectrograms, we compare the performance of a CNN trained from scratch and a ResNet18 architecture fine-tuned for the task at hand. Furthermore, we investigate whether the patients' sex and the use of contextual attention mechanisms is beneficial. Our experiments use the dataset released as part of the Second Diagnosing COVID-19 using Acoustics (DiCOVA) Challenge. The results suggest the suitability of fusing breath and speech information to detect COVID-19. An Area Under the Curve (AUC) of 84.06% is obtained on the test partition when using a CNN trained from scratch with contextual attention mechanisms. When using the ResNet18 architecture for feature extraction, the baseline model scores the highest performance with an AUC of 84.26%.