 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MAP-CSI: Single-site Map-Assisted Localization Using Massive MIMO CSI
Oct 01, 2021
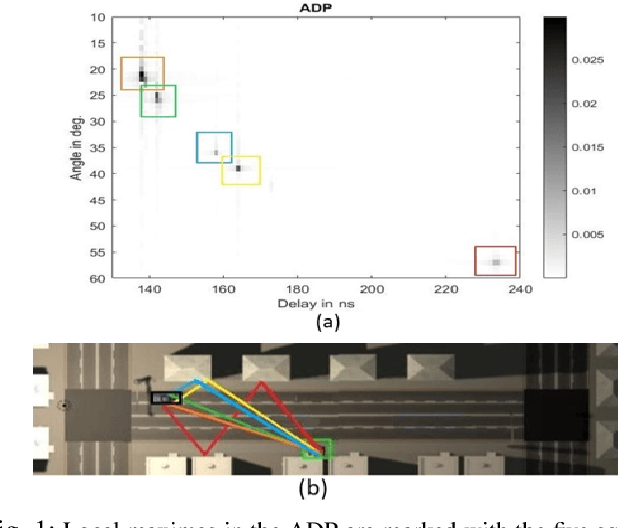
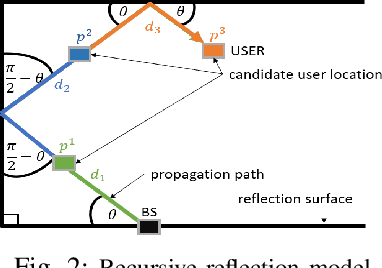

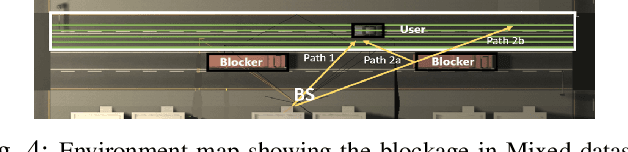
This paper presents a new map-assisted localization approach utilizing Chanel State Information (CSI) in Massive Multiple-Input Multiple-Output (MIMO) systems. Map-assisted localization is an environment-aware approach in which the communication system has information regarding the surrounding environment. By combining radio frequency ray tracing parameters of the multipath components (MPC) with the environment map, it is possible to accomplish localization. Unfortunately, in real-world scenarios, ray tracing parameters are typically not explicitly available. Thus, additional complexity is added at a base station to obtain this information. On the other hand, CSI is a common communication parameter, usually estimated for any communication channel. In this work, we leverage the already available CSI data to propose a novel map-assisted CSI localization approach, referred to as MAP-CSI. We show that Angle-of-Departure (AoD) and Time-of-Arrival (ToA) can be extracted from CSI and then be used in combination with the environment map to localize the user. We perform simulations on a public MIMO dataset and show that our method works for both line-of-sight (LOS) and non-line-of-sight (NLOS) scenarios. We compare our method to the state-of-the-art (SoA) method that uses the ray tracing data. Using MAP-CSI, we accomplish an average localization error of 1.8 m in LOS and 2.8 m in mixed (combination of LOS and NLOS samples) scenarios. On the other hand, SoA ray tracing has an average error of 1.0 m and 2.2 m, respectively, but requires explicit AoD and ToA information to perform the localization task.
Stochastic One-Sided Full-Information Bandit
Jun 20, 2019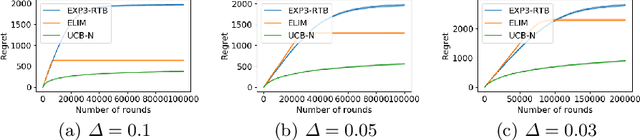
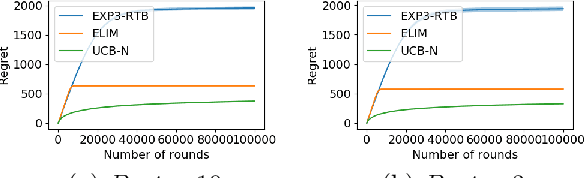
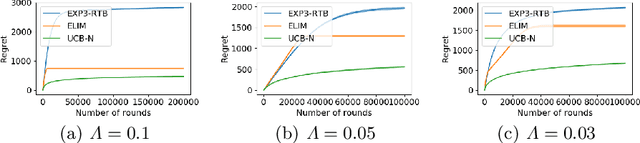
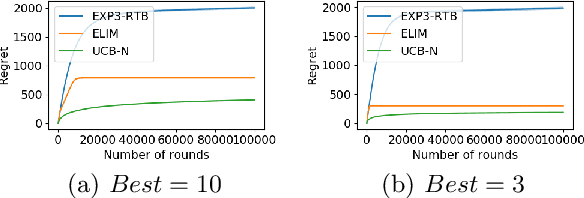
In this paper, we study the stochastic version of the one-sided full information bandit problem, where we have $K$ arms $[K] = \{1, 2, \ldots, K\}$, and playing arm $i$ would gain reward from an unknown distribution for arm $i$ while obtaining reward feedback for all arms $j \ge i$. One-sided full information bandit can model the online repeated second-price auctions, where the auctioneer could select the reserved price in each round and the bidders only reveal their bids when their bids are higher than the reserved price. In this paper, we present an elimination-based algorithm to solve the problem. Our elimination based algorithm achieves distribution independent regret upper bound $O(\sqrt{T\cdot\log (TK)})$, and distribution dependent bound $O((\log T + \log K)f(\Delta))$, where $T$ is the time horizon, $\Delta$ is a vector of gaps between the mean reward of arms and the mean reward of the best arm, and $f(\Delta)$ is a formula depending on the gap vector that we will specify in detail. Our algorithm has the best theoretical regret upper bound so far. We also validate our algorithm empirically against other possible alternatives.
Transfer Learning Based Multi-Objective Evolutionary Algorithm for Community Detection of Dynamic Complex Networks
Sep 30, 2021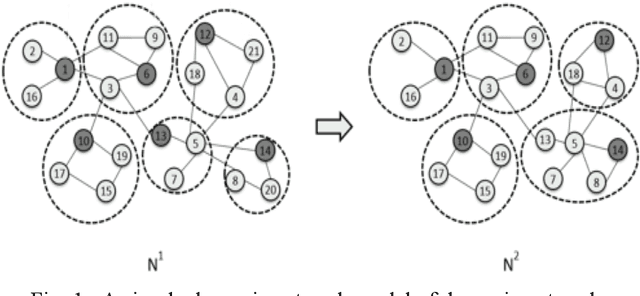

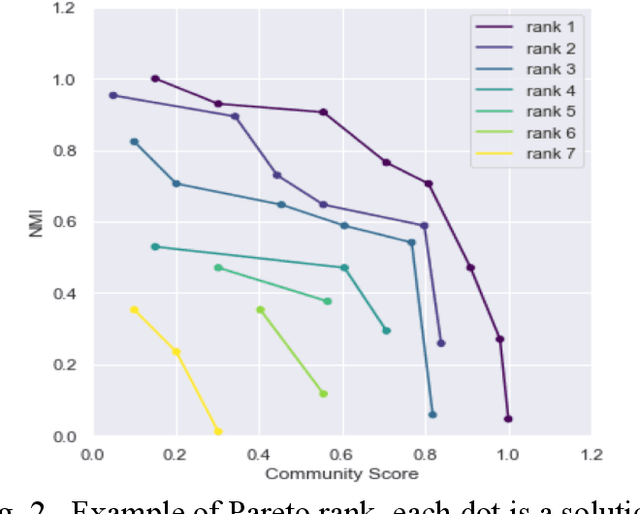

Dynamic community detection is the hotspot and basic problem of complex network and artificial intelligence research in recent years. It is necessary to maximize the accuracy of clustering as the network structure changes, but also to minimize the two consecutive clustering differences between the two results. There is a trade-off relationship between these two objectives. In this paper, we propose a Feature Transfer Based Multi-Objective Optimization Genetic Algorithm (TMOGA) based on transfer learning and traditional multi-objective evolutionary algorithm framework. The main idea is to extract stable features from past community structures, retain valuable feature information, and integrate this feature information into current optimization processes to improve the evolutionary algorithms. Additionally, a new theoretical framework is proposed in this paper to analyze community detection problem based on information theory. Then, we exploit this framework to prove the rationality of TMOGA. Finally, the experimental results show that our algorithm can achieve better clustering effects compared with the state-of-the-art dynamic network community detection algorithms in diverse test problems.
Reconstructing Training Data with Informed Adversaries
Jan 13, 2022
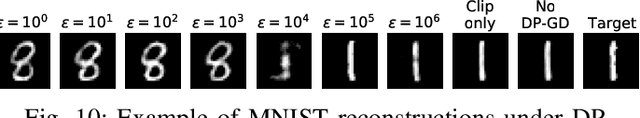
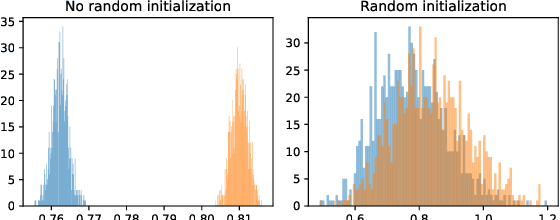
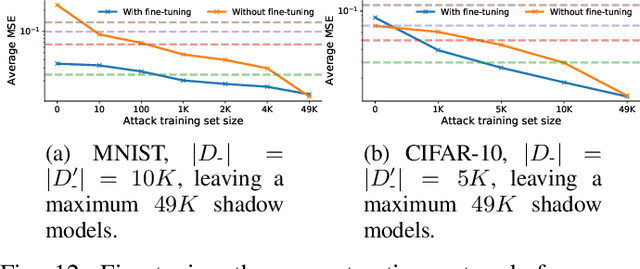
Given access to a machine learning model, can an adversary reconstruct the model's training data? This work studies this question from the lens of a powerful informed adversary who knows all the training data points except one. By instantiating concrete attacks, we show it is feasible to reconstruct the remaining data point in this stringent threat model. For convex models (e.g. logistic regression), reconstruction attacks are simple and can be derived in closed-form. For more general models (e.g. neural networks), we propose an attack strategy based on training a reconstructor network that receives as input the weights of the model under attack and produces as output the target data point. We demonstrate the effectiveness of our attack on image classifiers trained on MNIST and CIFAR-10, and systematically investigate which factors of standard machine learning pipelines affect reconstruction success. Finally, we theoretically investigate what amount of differential privacy suffices to mitigate reconstruction attacks by informed adversaries. Our work provides an effective reconstruction attack that model developers can use to assess memorization of individual points in general settings beyond those considered in previous works (e.g. generative language models or access to training gradients); it shows that standard models have the capacity to store enough information to enable high-fidelity reconstruction of training data points; and it demonstrates that differential privacy can successfully mitigate such attacks in a parameter regime where utility degradation is minimal.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
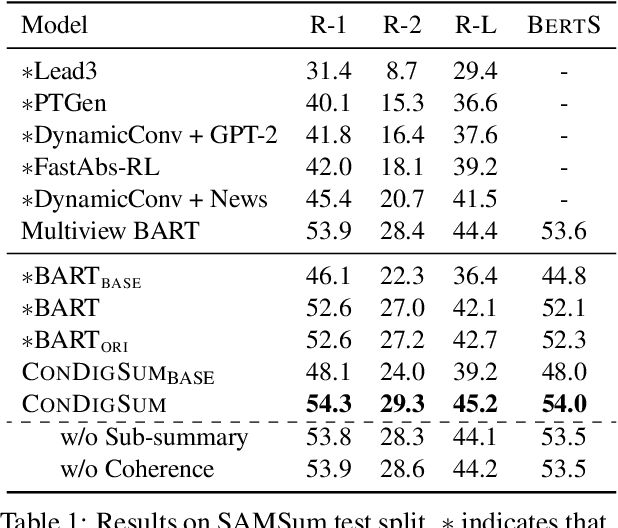
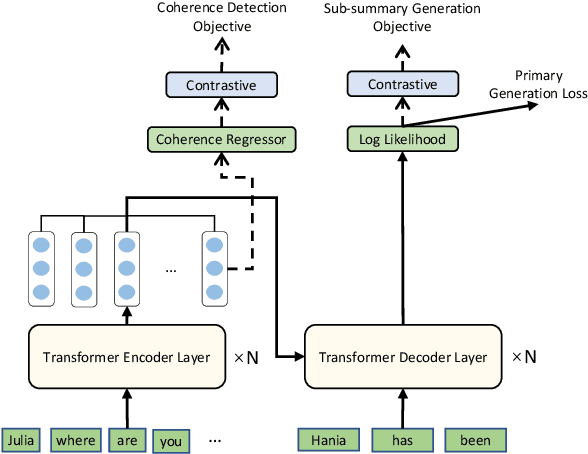
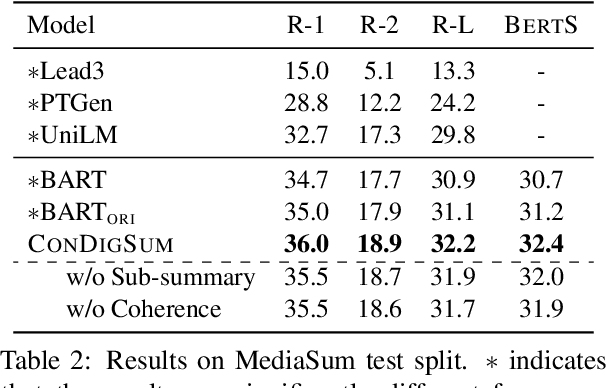
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.
Zero-Shot Semantic Segmentation via Spatial and Multi-Scale Aware Visual Class Embedding
Dec 20, 2021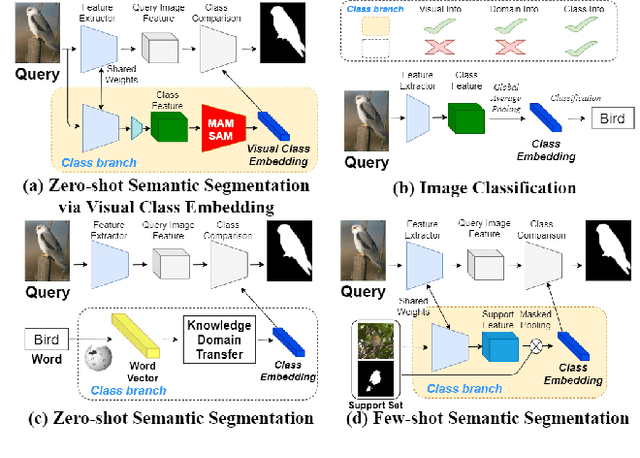
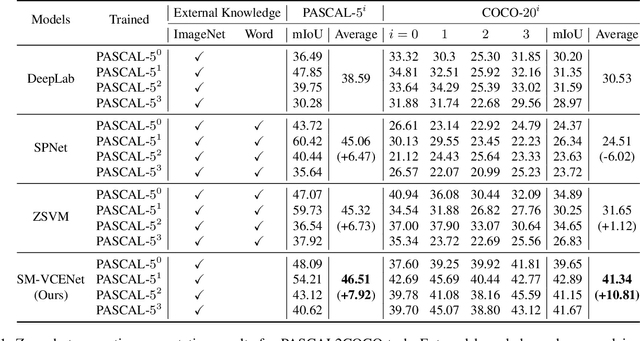
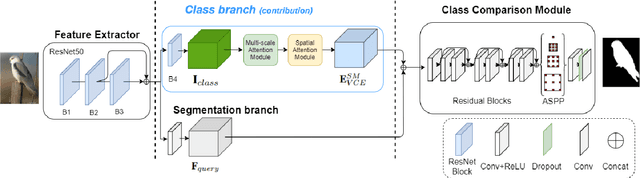
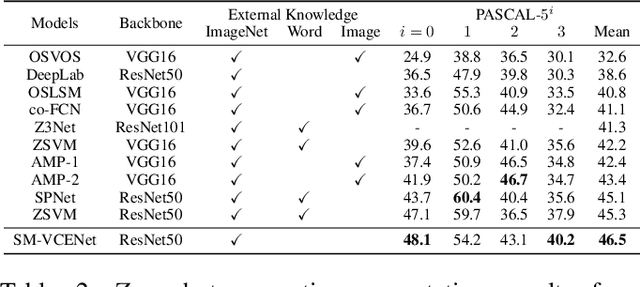
Fully supervised semantic segmentation technologies bring a paradigm shift in scene understanding. However, the burden of expensive labeling cost remains as a challenge. To solve the cost problem, recent studies proposed language model based zero-shot semantic segmentation (L-ZSSS) approaches. In this paper, we address L-ZSSS has a limitation in generalization which is a virtue of zero-shot learning. Tackling the limitation, we propose a language-model-free zero-shot semantic segmentation framework, Spatial and Multi-scale aware Visual Class Embedding Network (SM-VCENet). Furthermore, leveraging vision-oriented class embedding SM-VCENet enriches visual information of the class embedding by multi-scale attention and spatial attention. We also propose a novel benchmark (PASCAL2COCO) for zero-shot semantic segmentation, which provides generalization evaluation by domain adaptation and contains visually challenging samples. In experiments, our SM-VCENet outperforms zero-shot semantic segmentation state-of-the-art by a relative margin in PASCAL-5i benchmark and shows generalization-robustness in PASCAL2COCO benchmark.
Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022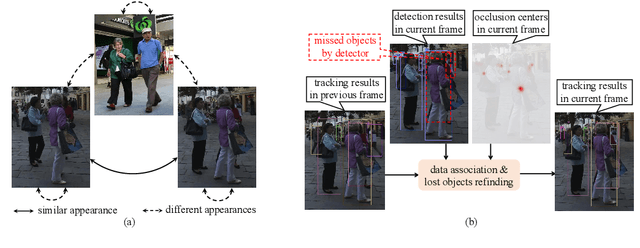

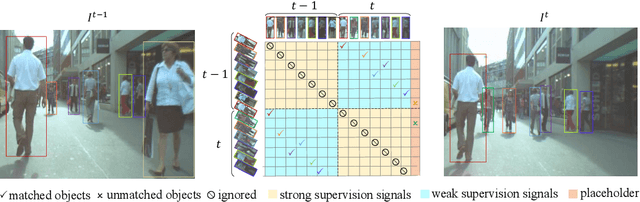

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.
MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding
Oct 16, 2021

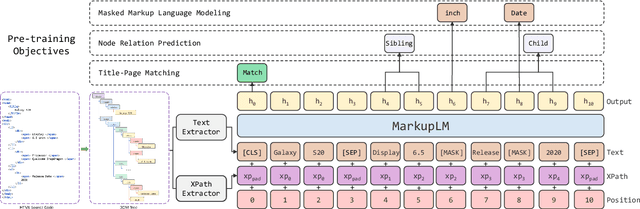
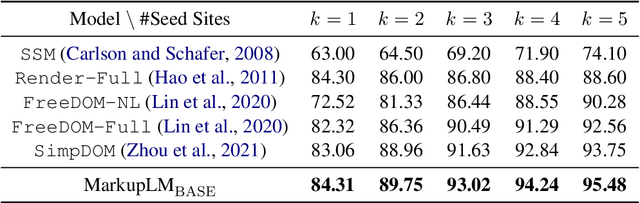
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks. The pre-trained model and code will be publicly available at https://aka.ms/markuplm.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021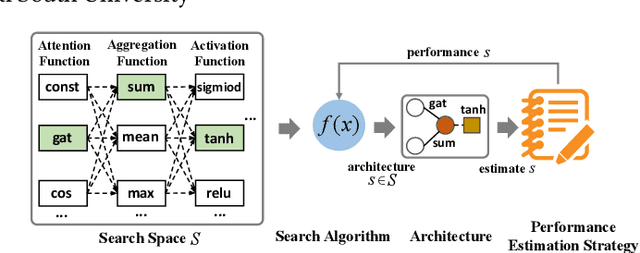

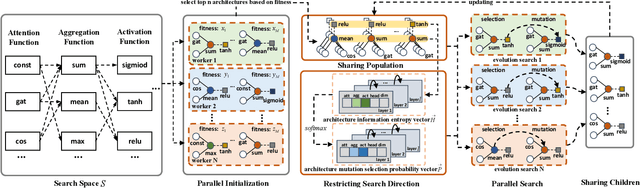
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021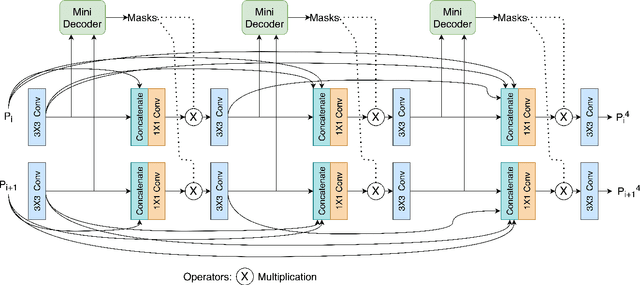
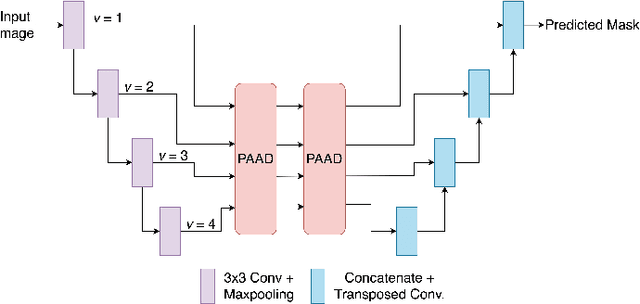
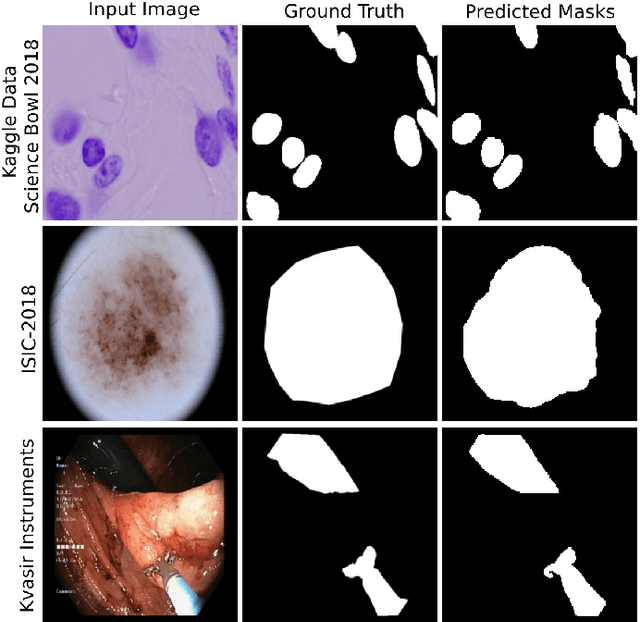
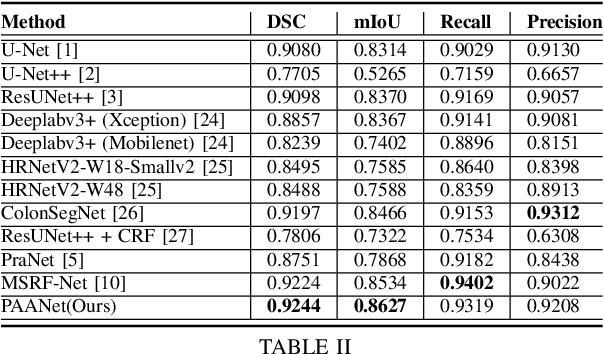
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.