 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposureEngine: Oriented Logo Detection and Sponsor Visibility Analytics in Sports Broadcasts
Oct 06, 2025Quantifying sponsor visibility in sports broadcasts is a critical marketing task traditionally hindered by manual, subjective, and unscalable analysis methods. While automated systems offer an alternative, their reliance on axis-aligned Horizontal Bounding Box (HBB) leads to inaccurate exposuremetrics when logos appear rotated or skewed due to dynamic camera angles and perspective distortions. This paper introduces ExposureEngine, an end-to-end system designed for accurate, rotation-aware sponsor visibility analytics in sports broadcasts, demonstrated in a soccer case study. Our approach predicts Oriented Bounding Box (OBB) to provide a geometrically precise fit to each logo regardless of the orientation on-screen. To train and evaluate our detector, we developed a new dataset comprising 1,103 frames from Swedish elite soccer, featuring 670 unique sponsor logos annotated with OBBs. Our model achieves a mean Average Precision (mAP@0.5) of 0.859, with a precision of 0.96 and recall of 0.87, demonstrating robust performance in localizing logos under diverse broadcast conditions. The system integrates these detections into an analytical pipeline that calculates precise visibility metrics, such as exposure duration and on-screen coverage. Furthermore, we incorporate a language-driven agentic layer, enabling users to generate reports, summaries, and media content through natural language queries. The complete system, including the dataset and the analytics dashboard, provides a comprehensive solution for auditable and interpretable sponsor measurement in sports media. An overview of the ExposureEngine is available online: https://youtu.be/tRw6OBISuW4 .
Comparative Analysis of Audio Feature Extraction for Real-Time Talking Portrait Synthesis
Nov 20, 2024



This paper examines the integration of real-time talking-head generation for interviewer training, focusing on overcoming challenges in Audio Feature Extraction (AFE), which often introduces latency and limits responsiveness in real-time applications. To address these issues, we propose and implement a fully integrated system that replaces conventional AFE models with Open AI's Whisper, leveraging its encoder to optimize processing and improve overall system efficiency. Our evaluation of two open-source real-time models across three different datasets shows that Whisper not only accelerates processing but also improves specific aspects of rendering quality, resulting in more realistic and responsive talking-head interactions. These advancements make the system a more effective tool for immersive, interactive training applications, expanding the potential of AI-driven avatars in interviewer training.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021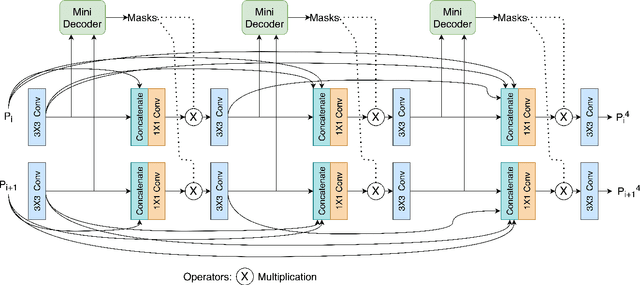
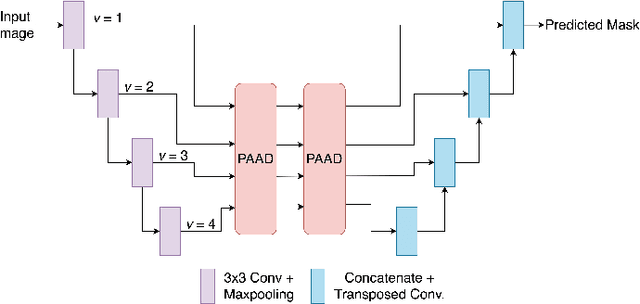
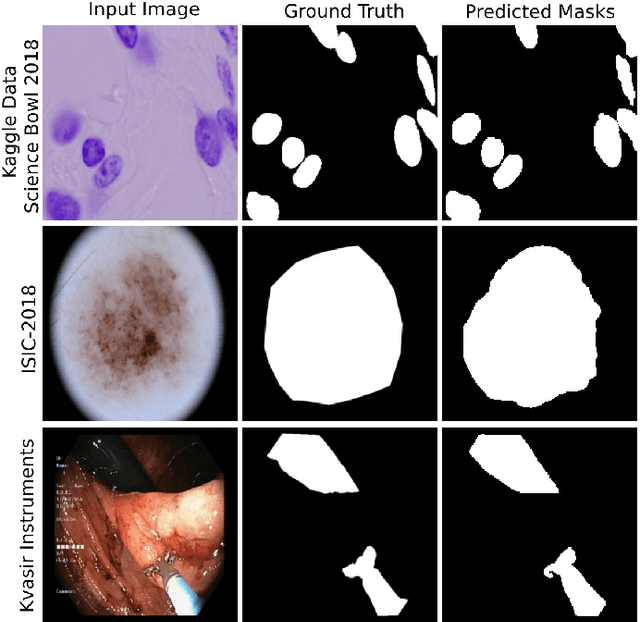
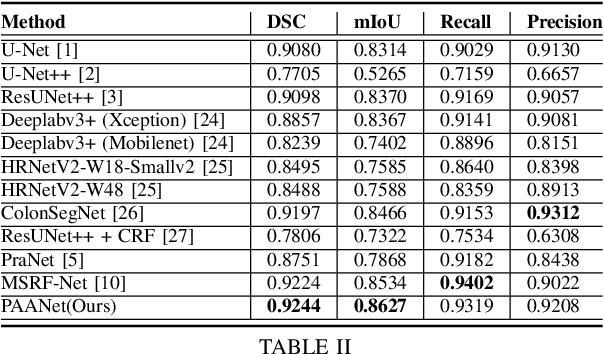
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
Exploring Deep Learning Methods for Real-Time Surgical Instrument Segmentation in Laparoscopy
Aug 03, 2021
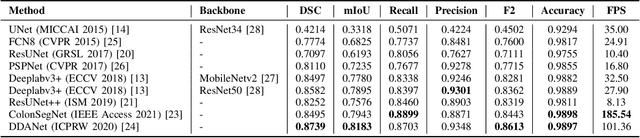
Minimally invasive surgery is a surgical intervention used to examine the organs inside the abdomen and has been widely used due to its effectiveness over open surgery. Due to the hardware improvements such as high definition cameras, this procedure has significantly improved and new software methods have demonstrated potential for computer-assisted procedures. However, there exists challenges and requirements to improve detection and tracking of the position of the instruments during these surgical procedures. To this end, we evaluate and compare some popular deep learning methods that can be explored for the automated segmentation of surgical instruments in laparoscopy, an important step towards tool tracking. Our experimental results exhibit that the Dual decoder attention network (DDANet) produces a superior result compared to other recent deep learning methods. DDANet yields a Dice coefficient of 0.8739 and mean intersection-over-union of 0.8183 for the Robust Medical Instrument Segmentation (ROBUST-MIS) Challenge 2019 dataset, at a real-time speed of 101.36 frames-per-second that is critical for such procedures.
A Comprehensive Study on Colorectal Polyp Segmentation with ResUNet++, Conditional Random Field and Test-Time Augmentation
Jul 26, 2021
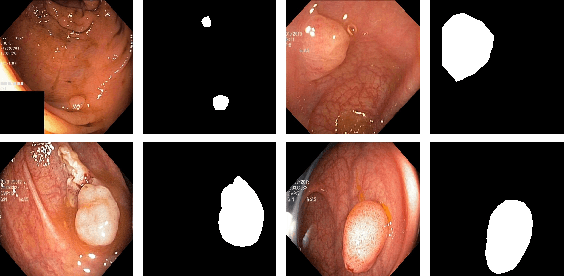
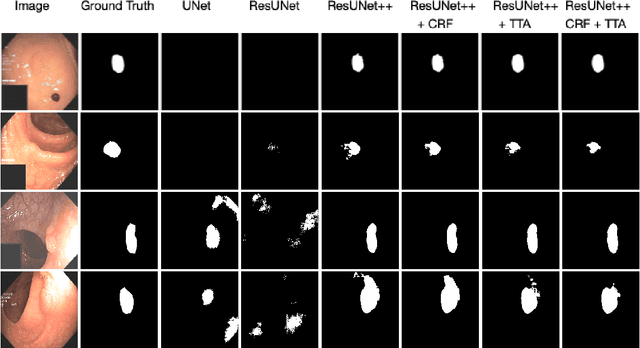
Colonoscopy is considered the gold standard for detection of colorectal cancer and its precursors. Existing examination methods are, however, hampered by high overall miss-rate, and many abnormalities are left undetected. Computer-Aided Diagnosis systems based on advanced machine learning algorithms are touted as a game-changer that can identify regions in the colon overlooked by the physicians during endoscopic examinations, and help detect and characterize lesions. In previous work, we have proposed the ResUNet++ architecture and demonstrated that it produces more efficient results compared with its counterparts U-Net and ResUNet. In this paper, we demonstrate that further improvements to the overall prediction performance of the ResUNet++ architecture can be achieved by using conditional random field and test-time augmentation. We have performed extensive evaluations and validated the improvements using six publicly available datasets: Kvasir-SEG, CVC-ClinicDB, CVC-ColonDB, ETIS-Larib Polyp DB, ASU-Mayo Clinic Colonoscopy Video Database, and CVC-VideoClinicDB. Moreover, we compare our proposed architecture and resulting model with other State-of-the-art methods. To explore the generalization capability of ResUNet++ on different publicly available polyp datasets, so that it could be used in a real-world setting, we performed an extensive cross-dataset evaluation. The experimental results show that applying CRF and TTA improves the performance on various polyp segmentation datasets both on the same dataset and cross-dataset.
MSRF-Net: A Multi-Scale Residual Fusion Network for Biomedical Image Segmentation
May 16, 2021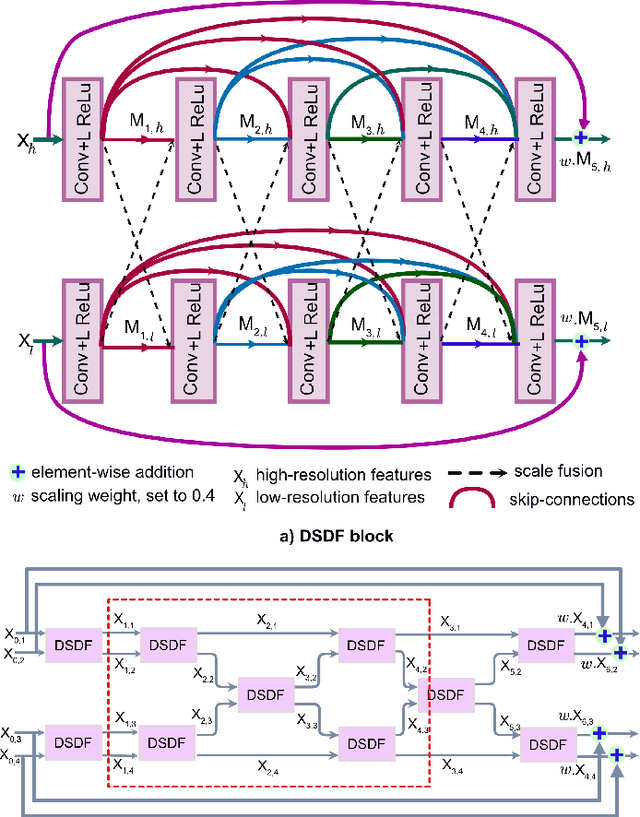
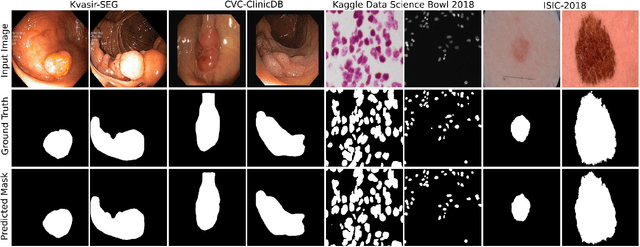
Methods based on convolutional neural networks have improved the performance of biomedical image segmentation. However, most of these methods cannot efficiently segment objects of variable sizes and train on small and biased datasets, which are common in biomedical use cases. While methods exist that incorporate multi-scale fusion approaches to address the challenges arising with variable sizes, they usually use complex models that are more suitable for general semantic segmentation computer vision problems. In this paper, we propose a novel architecture called MSRF-Net, which is specially designed for medical image segmentation tasks. The proposed MSRF-Net is able to exchange multi-scale features of varying receptive fields using a dual-scale dense fusion block (DSDF). Our DSDF block can exchange information rigorously across two different resolution scales, and our MSRF sub-network uses multiple DSDF blocks in sequence to perform multi-scale fusion. This allows the preservation of resolution, improved information flow, and propagation of both high- and low-level features to obtain accurate segmentation maps. The proposed MSRF-Net allows to capture object variabilities and provides improved results on different biomedical datasets. Extensive experiments on MSRF-Net demonstrate that the proposed method outperforms most of the cutting-edge medical image segmentation state-of-the-art methods. MSRF-Net advances the performance on four publicly available datasets, and also, MSRF-Net is more generalizable as compared to state-of-the-art methods.
NanoNet: Real-Time Polyp Segmentation in Video Capsule Endoscopy and Colonoscopy
Apr 22, 2021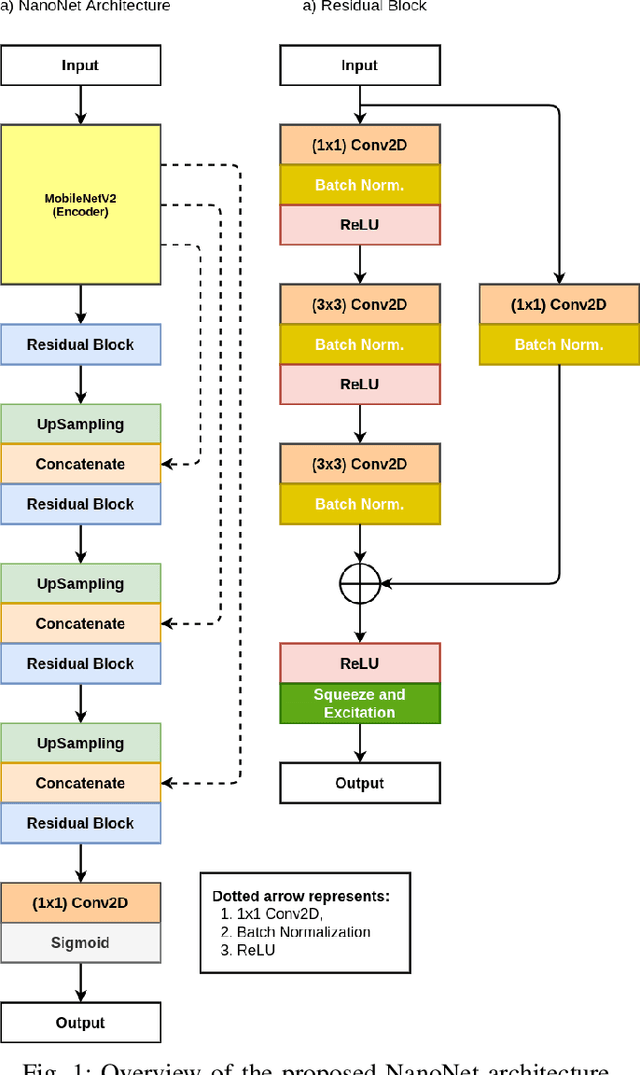
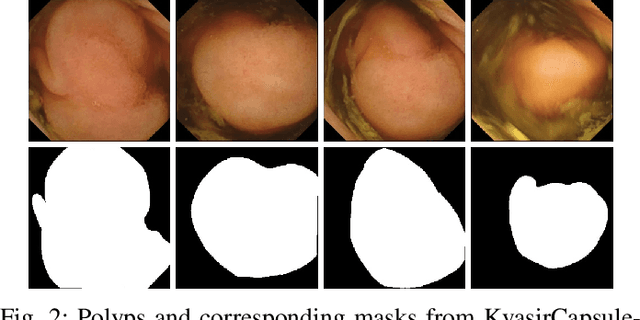
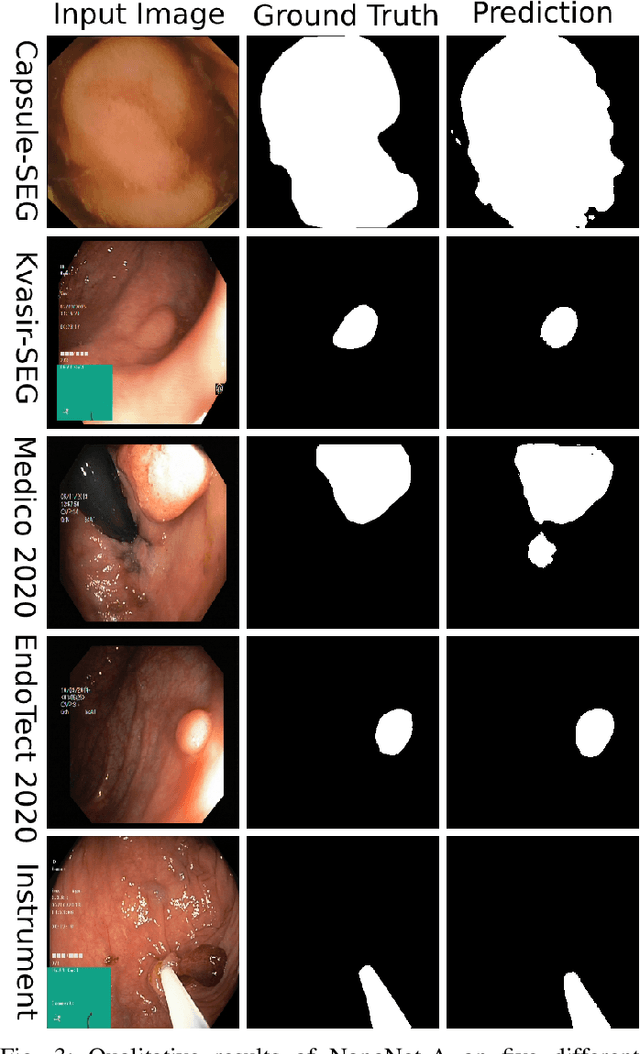

Deep learning in gastrointestinal endoscopy can assist to improve clinical performance and be helpful to assess lesions more accurately. To this extent, semantic segmentation methods that can perform automated real-time delineation of a region-of-interest, e.g., boundary identification of cancer or precancerous lesions, can benefit both diagnosis and interventions. However, accurate and real-time segmentation of endoscopic images is extremely challenging due to its high operator dependence and high-definition image quality. To utilize automated methods in clinical settings, it is crucial to design lightweight models with low latency such that they can be integrated with low-end endoscope hardware devices. In this work, we propose NanoNet, a novel architecture for the segmentation of video capsule endoscopy and colonoscopy images. Our proposed architecture allows real-time performance and has higher segmentation accuracy compared to other more complex ones. We use video capsule endoscopy and standard colonoscopy datasets with polyps, and a dataset consisting of endoscopy biopsies and surgical instruments, to evaluate the effectiveness of our approach. Our experiments demonstrate the increased performance of our architecture in terms of a trade-off between model complexity, speed, model parameters, and metric performances. Moreover, the resulting model size is relatively tiny, with only nearly 36,000 parameters compared to traditional deep learning approaches having millions of parameters.
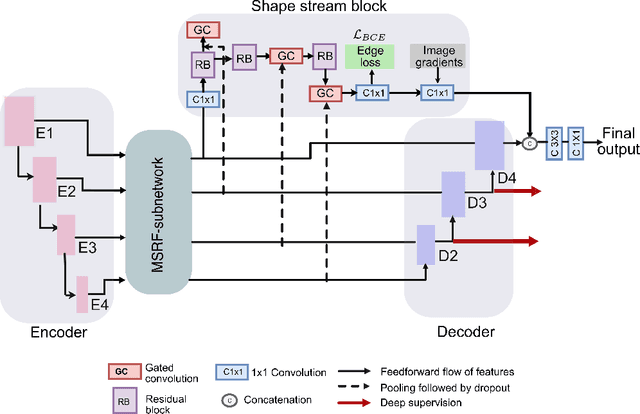
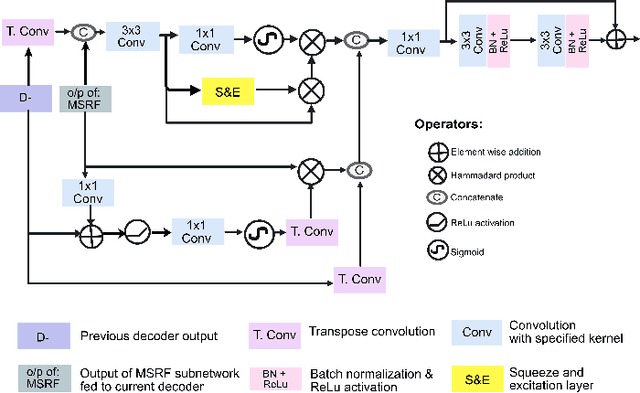
FANet: A Feedback Attention Network for Improved Biomedical Image Segmentation
Mar 31, 2021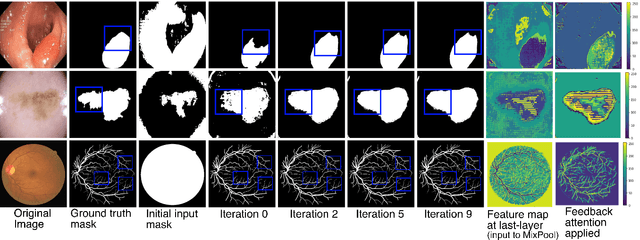
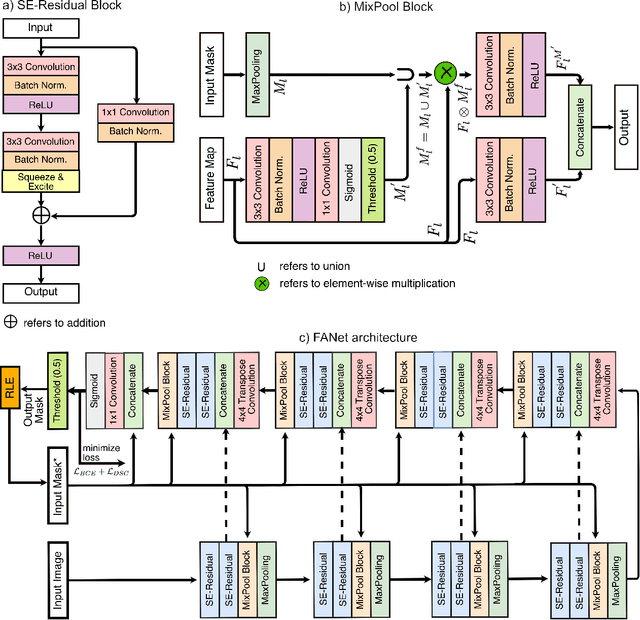
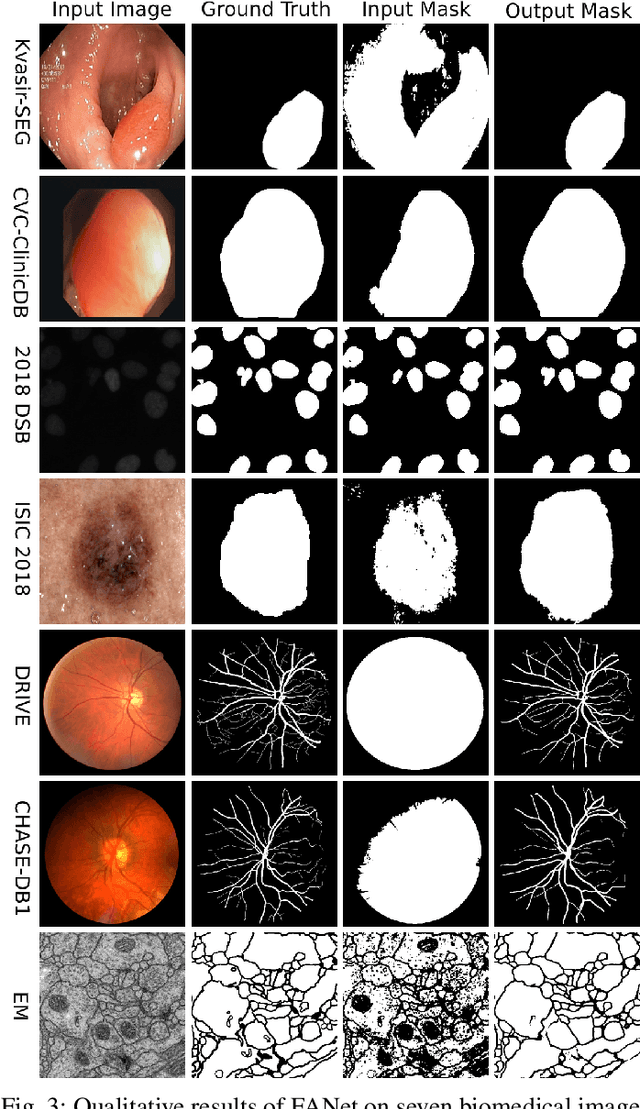
With the increase in available large clinical and experimental datasets, there has been substantial amount of work being done on addressing the challenges in the area of biomedical image analysis. Image segmentation, which is crucial for any quantitative analysis, has especially attracted attention. Recent hardware advancement has led to the success of deep learning approaches. However, although deep learning models are being trained on large datasets, existing methods do not use the information from different learning epochs effectively. In this work, we leverage the information of each training epoch to prune the prediction maps of the subsequent epochs. We propose a novel architecture called feedback attention network (FANet) that unifies the previous epoch mask with the feature map of the current training epoch. The previous epoch mask is then used to provide a hard attention to the learnt feature maps at different convolutional layers. The network also allows to rectify the predictions in an iterative fashion during the test time. We show that our proposed feedback attention model provides a substantial improvement on most segmentation metrics tested on seven publicly available biomedical imaging datasets demonstrating the effectiveness of the proposed FANet.
LightLayers: Parameter Efficient Dense and Convolutional Layers for Image Classification
Jan 06, 2021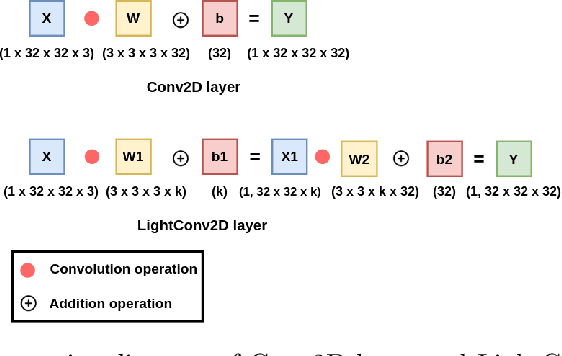
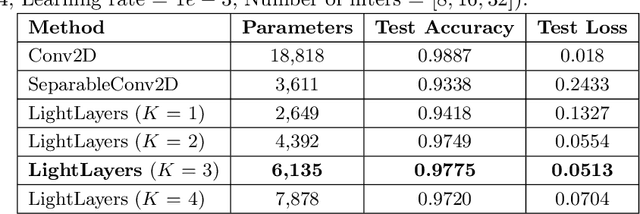
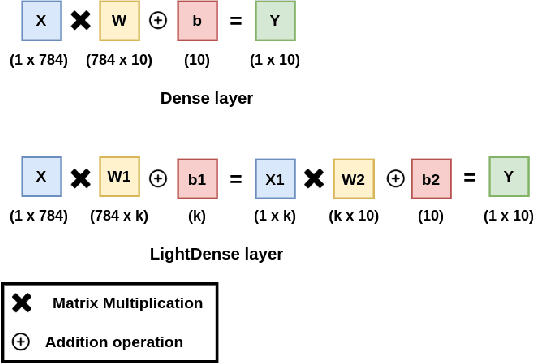
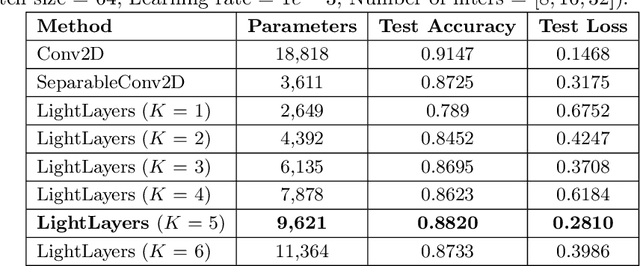
Deep Neural Networks (DNNs) have become the de-facto standard in computer vision, as well as in many other pattern recognition tasks. A key drawback of DNNs is that the training phase can be very computationally expensive. Organizations or individuals that cannot afford purchasing state-of-the-art hardware or tapping into cloud-hosted infrastructures may face a long waiting time before the training completes or might not be able to train a model at all. Investigating novel ways to reduce the training time could be a potential solution to alleviate this drawback, and thus enabling more rapid development of new algorithms and models. In this paper, we propose LightLayers, a method for reducing the number of trainable parameters in deep neural networks (DNN). The proposed LightLayers consists of LightDense andLightConv2D layer that are as efficient as regular Conv2D and Dense layers, but uses less parameters. We resort to Matrix Factorization to reduce the complexity of the DNN models resulting into lightweight DNNmodels that require less computational power, without much loss in the accuracy. We have tested LightLayers on MNIST, Fashion MNIST, CI-FAR 10, and CIFAR 100 datasets. Promising results are obtained for MNIST, Fashion MNIST, CIFAR-10 datasets whereas CIFAR 100 shows acceptable performance by using fewer parameters.
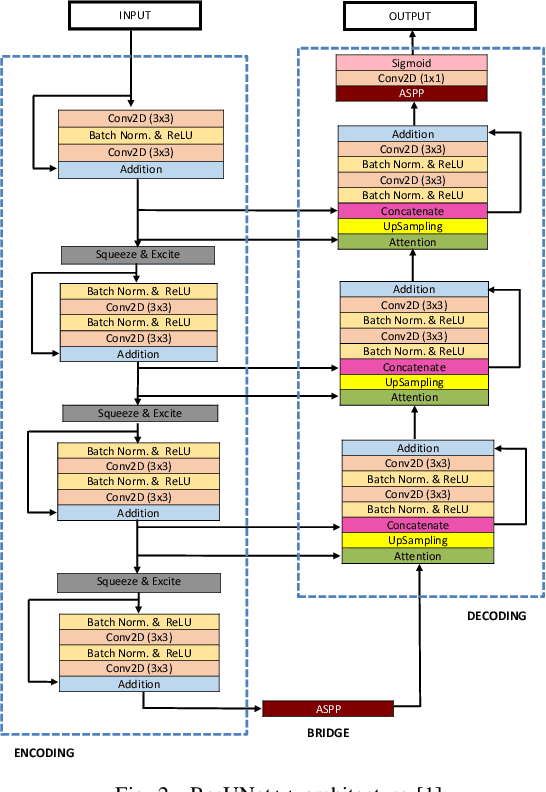
DDANet: Dual Decoder Attention Network for Automatic Polyp Segmentation
Dec 30, 2020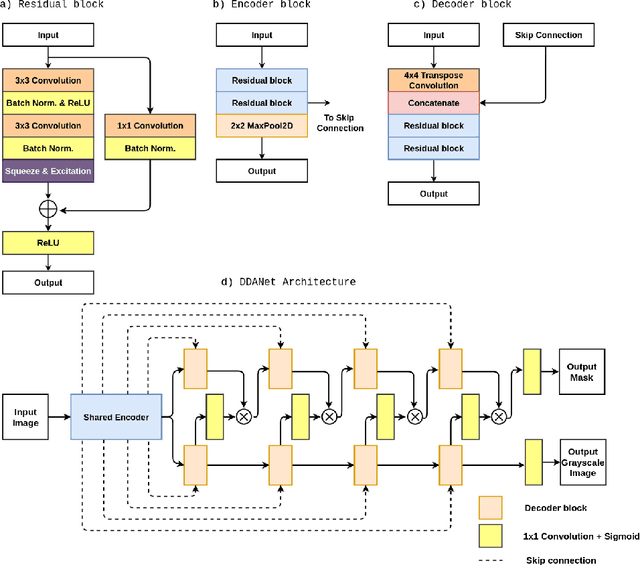
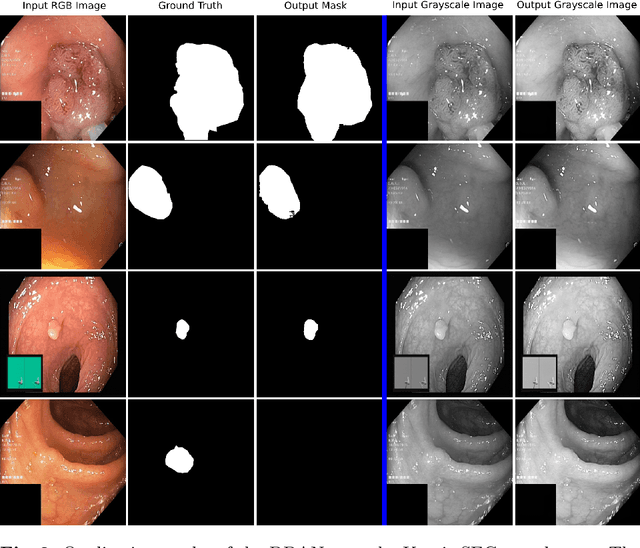
Colonoscopy is the gold standard for examination and detection of colorectal polyps. Localization and delineation of polyps can play a vital role in treatment (e.g., surgical planning) and prognostic decision making. Polyp segmentation can provide detailed boundary information for clinical analysis. Convolutional neural networks have improved the performance in colonoscopy. However, polyps usually possess various challenges, such as intra-and inter-class variation and noise. While manual labeling for polyp assessment requires time from experts and is prone to human error (e.g., missed lesions), an automated, accurate, and fast segmentation can improve the quality of delineated lesion boundaries and reduce missed rate. The Endotect challenge provides an opportunity to benchmark computer vision methods by training on the publicly available Hyperkvasir and testing on a separate unseen dataset. In this paper, we propose a novel architecture called ``DDANet'' based on a dual decoder attention network. Our experiments demonstrate that the model trained on the Kvasir-SEG dataset and tested on an unseen dataset achieves a dice coefficient of 0.7874, mIoU of 0.7010, recall of 0.7987, and a precision of 0.8577, demonstrating the generalization ability of our model.