 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge
Jun 11, 2025Indirect Prompt Injection attacks exploit the inherent limitation of Large Language Models (LLMs) to distinguish between instructions and data in their inputs. Despite numerous defense proposals, the systematic evaluation against adaptive adversaries remains limited, even when successful attacks can have wide security and privacy implications, and many real-world LLM-based applications remain vulnerable. We present the results of LLMail-Inject, a public challenge simulating a realistic scenario in which participants adaptively attempted to inject malicious instructions into emails in order to trigger unauthorized tool calls in an LLM-based email assistant. The challenge spanned multiple defense strategies, LLM architectures, and retrieval configurations, resulting in a dataset of 208,095 unique attack submissions from 839 participants. We release the challenge code, the full dataset of submissions, and our analysis demonstrating how this data can provide new insights into the instruction-data separation problem. We hope this will serve as a foundation for future research towards practical structural solutions to prompt injection.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Are you still on track!? Catching LLM Task Drift with Activations
Jun 02, 2024



Large Language Models (LLMs) are routinely used in retrieval-augmented applications to orchestrate tasks and process inputs from users and other sources. These inputs, even in a single LLM interaction, can come from a variety of sources, of varying trustworthiness and provenance. This opens the door to prompt injection attacks, where the LLM receives and acts upon instructions from supposedly data-only sources, thus deviating from the user's original instructions. We define this as task drift, and we propose to catch it by scanning and analyzing the LLM's activations. We compare the LLM's activations before and after processing the external input in order to detect whether this input caused instruction drift. We develop two probing methods and find that simply using a linear classifier can detect drift with near perfect ROC AUC on an out-of-distribution test set. We show that this approach generalizes surprisingly well to unseen task domains, such as prompt injections, jailbreaks, and malicious instructions, without being trained on any of these attacks. Our setup does not require any modification of the LLM (e.g., fine-tuning) or any text generation, thus maximizing deployability and cost efficiency and avoiding reliance on unreliable model output. To foster future research on activation-based task inspection, decoding, and interpretability, we will release our large-scale TaskTracker toolkit, comprising a dataset of over 500K instances, representations from 4 SoTA language models, and inspection tools.
Closed-Form Bounds for DP-SGD against Record-level Inference
Feb 22, 2024



Machine learning models trained with differentially-private (DP) algorithms such as DP-SGD enjoy resilience against a wide range of privacy attacks. Although it is possible to derive bounds for some attacks based solely on an $(\varepsilon,\delta)$-DP guarantee, meaningful bounds require a small enough privacy budget (i.e., injecting a large amount of noise), which results in a large loss in utility. This paper presents a new approach to evaluate the privacy of machine learning models against specific record-level threats, such as membership and attribute inference, without the indirection through DP. We focus on the popular DP-SGD algorithm, and derive simple closed-form bounds. Our proofs model DP-SGD as an information theoretic channel whose inputs are the secrets that an attacker wants to infer (e.g., membership of a data record) and whose outputs are the intermediate model parameters produced by iterative optimization. We obtain bounds for membership inference that match state-of-the-art techniques, whilst being orders of magnitude faster to compute. Additionally, we present a novel data-dependent bound against attribute inference. Our results provide a direct, interpretable, and practical way to evaluate the privacy of trained models against specific inference threats without sacrificing utility.
SoK: Let The Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Dec 21, 2022


Deploying machine learning models in production may allow adversaries to infer sensitive information about training data. There is a vast literature analyzing different types of inference risks, ranging from membership inference to reconstruction attacks. Inspired by the success of games (i.e., probabilistic experiments) to study security properties in cryptography, some authors describe privacy inference risks in machine learning using a similar game-based style. However, adversary capabilities and goals are often stated in subtly different ways from one presentation to the other, which makes it hard to relate and compose results. In this paper, we present a game-based framework to systematize the body of knowledge on privacy inference risks in machine learning.
Synthetic Data -- what, why and how?
May 06, 2022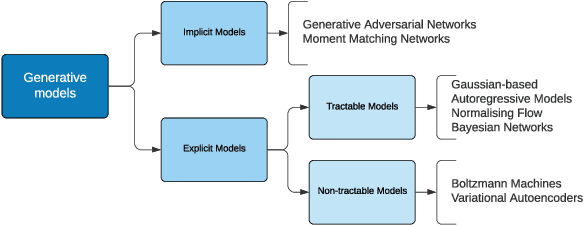
This explainer document aims to provide an overview of the current state of the rapidly expanding work on synthetic data technologies, with a particular focus on privacy. The article is intended for a non-technical audience, though some formal definitions have been given to provide clarity to specialists. This article is intended to enable the reader to quickly become familiar with the notion of synthetic data, as well as understand some of the subtle intricacies that come with it. We do believe that synthetic data is a very useful tool, and our hope is that this report highlights that, while drawing attention to nuances that can easily be overlooked in its deployment.
Approximating Full Conformal Prediction at Scale via Influence Functions
Feb 02, 2022



Conformal prediction (CP) is a wrapper around traditional machine learning models, giving coverage guarantees under the sole assumption of exchangeability; in classification problems, for a chosen significance level $\varepsilon$, CP guarantees that the number of errors is at most $\varepsilon$, irrespective of whether the underlying model is misspecified. However, the prohibitive computational costs of full CP led researchers to design scalable alternatives, which alas do not attain the same guarantees or statistical power of full CP. In this paper, we use influence functions to efficiently approximate full CP. We prove that our method is a consistent approximation of full CP, and empirically show that the approximation error becomes smaller as the training set increases; e.g., for $10^{3}$ training points the two methods output p-values that are $<10^{-3}$ apart: a negligible error for any practical application. Our methods enable scaling full CP to large real-world datasets. We compare our full CP approximation ACP to mainstream CP alternatives, and observe that our method is computationally competitive whilst enjoying the statistical predictive power of full CP.
Reconstructing Training Data with Informed Adversaries
Jan 13, 2022
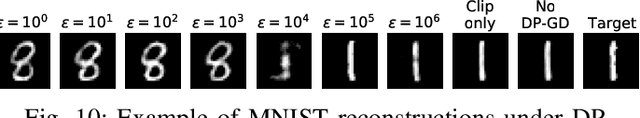
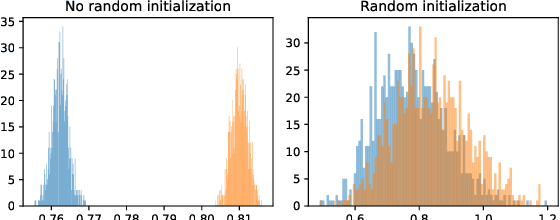
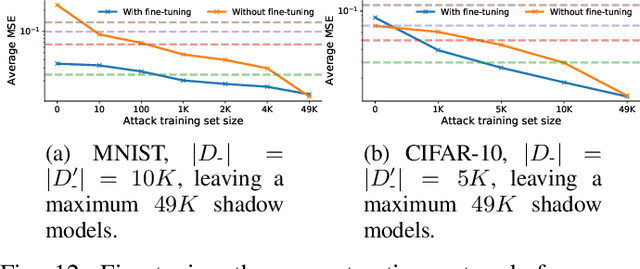
Given access to a machine learning model, can an adversary reconstruct the model's training data? This work studies this question from the lens of a powerful informed adversary who knows all the training data points except one. By instantiating concrete attacks, we show it is feasible to reconstruct the remaining data point in this stringent threat model. For convex models (e.g. logistic regression), reconstruction attacks are simple and can be derived in closed-form. For more general models (e.g. neural networks), we propose an attack strategy based on training a reconstructor network that receives as input the weights of the model under attack and produces as output the target data point. We demonstrate the effectiveness of our attack on image classifiers trained on MNIST and CIFAR-10, and systematically investigate which factors of standard machine learning pipelines affect reconstruction success. Finally, we theoretically investigate what amount of differential privacy suffices to mitigate reconstruction attacks by informed adversaries. Our work provides an effective reconstruction attack that model developers can use to assess memorization of individual points in general settings beyond those considered in previous works (e.g. generative language models or access to training gradients); it shows that standard models have the capacity to store enough information to enable high-fidelity reconstruction of training data points; and it demonstrates that differential privacy can successfully mitigate such attacks in a parameter regime where utility degradation is minimal.
Exact Optimization of Conformal Predictors via Incremental and Decremental Learning
Feb 05, 2021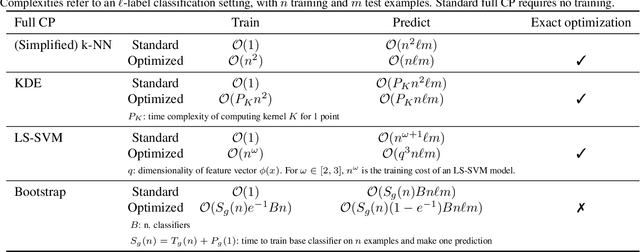
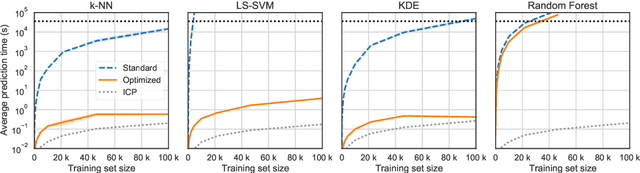
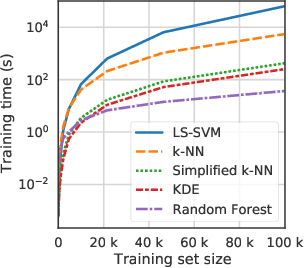
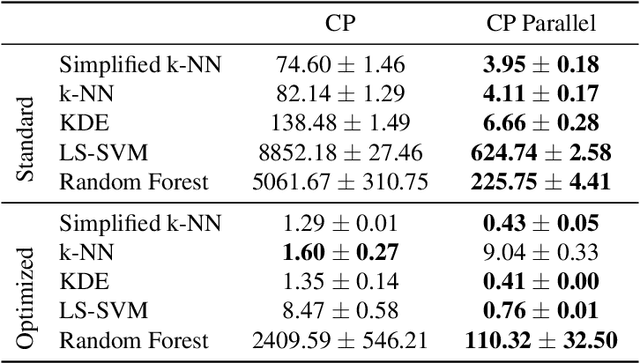
Conformal Predictors (CP) are wrappers around ML methods, providing error guarantees under weak assumptions on the data distribution. They are suitable for a wide range of problems, from classification and regression to anomaly detection. Unfortunately, their high computational complexity limits their applicability to large datasets. In this work, we show that it is possible to speed up a CP classifier considerably, by studying it in conjunction with the underlying ML method, and by exploiting incremental&decremental learning. For methods such as k-NN, KDE, and kernel LS-SVM, our approach reduces the running time by one order of magnitude, whilst producing exact solutions. With similar ideas, we also achieve a linear speed up for the harder case of bootstrapping. Finally, we extend these techniques to improve upon an optimization of k-NN CP for regression. We evaluate our findings empirically, and discuss when methods are suitable for CP optimization.