 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic One-Sided Full-Information Bandit
Paper and Code
Jun 20, 2019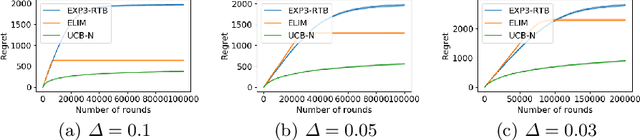
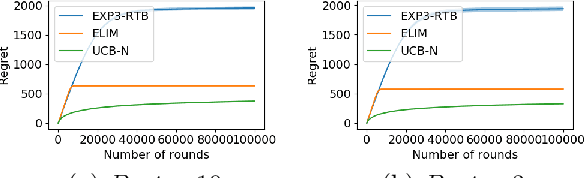
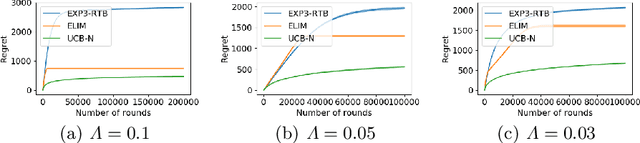
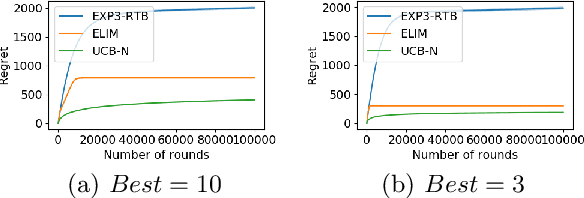
In this paper, we study the stochastic version of the one-sided full information bandit problem, where we have $K$ arms $[K] = \{1, 2, \ldots, K\}$, and playing arm $i$ would gain reward from an unknown distribution for arm $i$ while obtaining reward feedback for all arms $j \ge i$. One-sided full information bandit can model the online repeated second-price auctions, where the auctioneer could select the reserved price in each round and the bidders only reveal their bids when their bids are higher than the reserved price. In this paper, we present an elimination-based algorithm to solve the problem. Our elimination based algorithm achieves distribution independent regret upper bound $O(\sqrt{T\cdot\log (TK)})$, and distribution dependent bound $O((\log T + \log K)f(\Delta))$, where $T$ is the time horizon, $\Delta$ is a vector of gaps between the mean reward of arms and the mean reward of the best arm, and $f(\Delta)$ is a formula depending on the gap vector that we will specify in detail. Our algorithm has the best theoretical regret upper bound so far. We also validate our algorithm empirically against other possible alternatives.