 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021
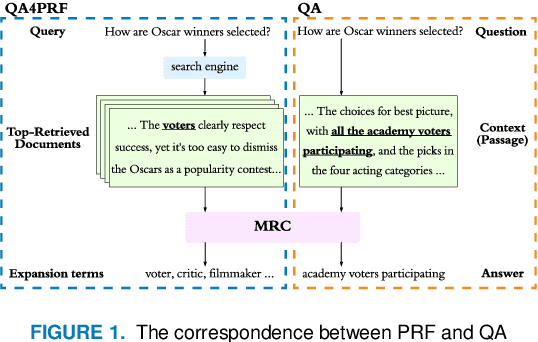

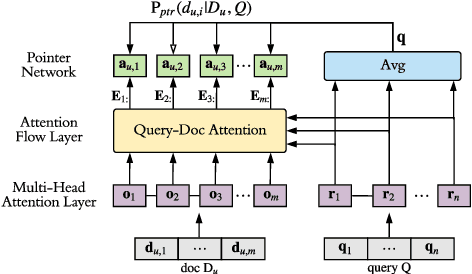

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022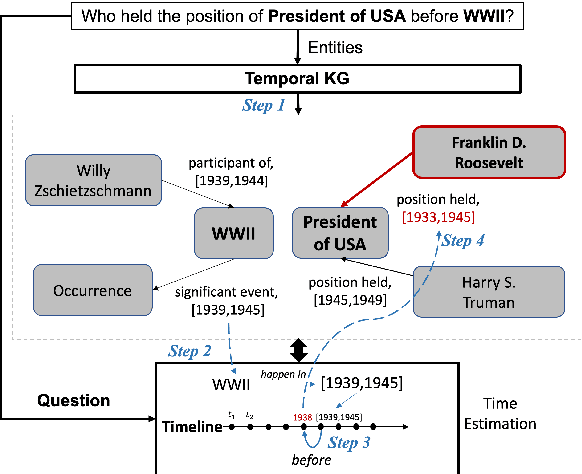
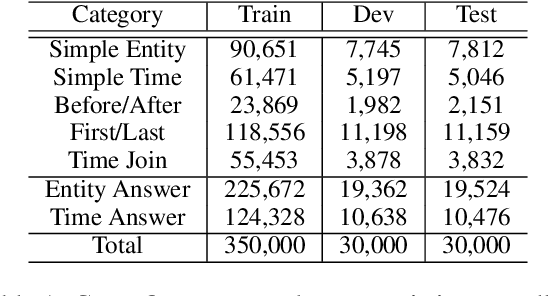
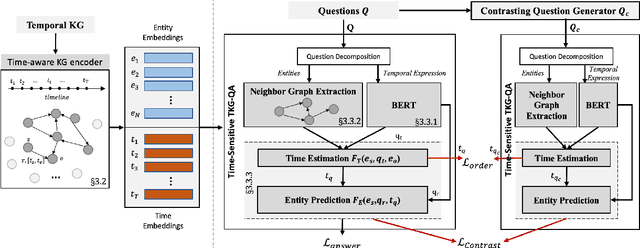
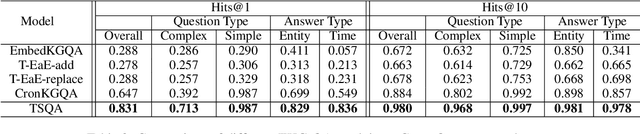
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
Missing Data Imputation and Acquisition with Deep Hierarchical Models and Hamiltonian Monte Carlo
Feb 09, 2022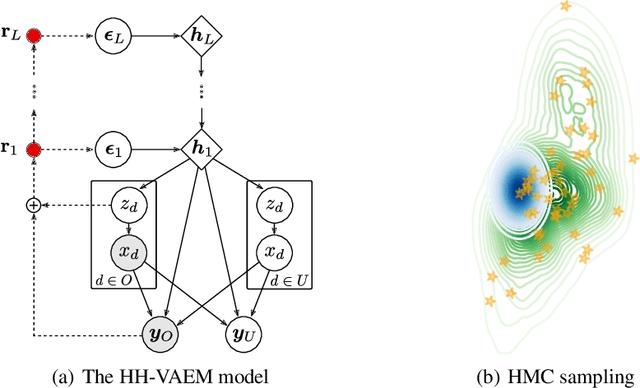


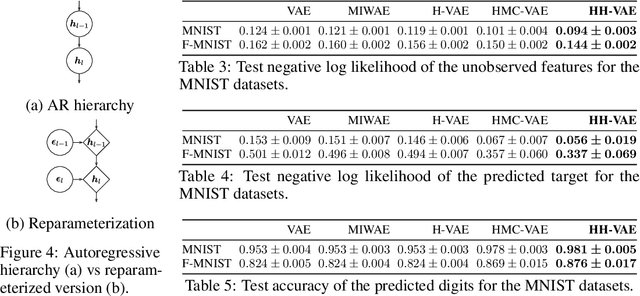
Variational Autoencoders (VAEs) have recently been highly successful at imputing and acquiring heterogeneous missing data and identifying outliers. However, within this specific application domain, existing VAE methods are restricted by using only one layer of latent variables and strictly Gaussian posterior approximations. To address these limitations, we present HH-VAEM, a Hierarchical VAE model for mixed-type incomplete data that uses Hamiltonian Monte Carlo with automatic hyper-parameter tuning for improved approximate inference. Our experiments show that HH-VAEM outperforms existing baselines in the tasks of missing data imputation, supervised learning and outlier identification with missing features. Finally, we also present a sampling-based approach for efficiently computing the information gain when missing features are to be acquired with HH-VAEM. Our experiments show that this sampling-based approach is superior to alternatives based on Gaussian approximations.
TwistSLAM: Constrained SLAM in Dynamic Environment
Feb 24, 2022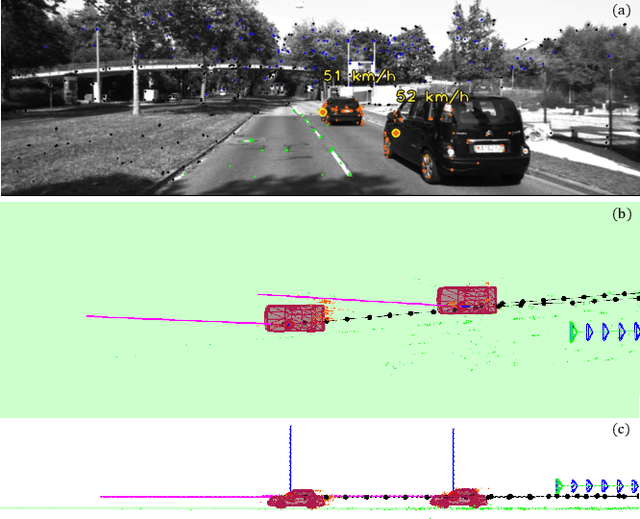
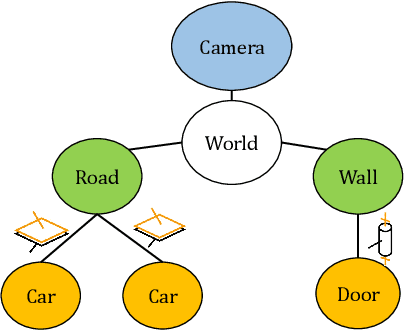
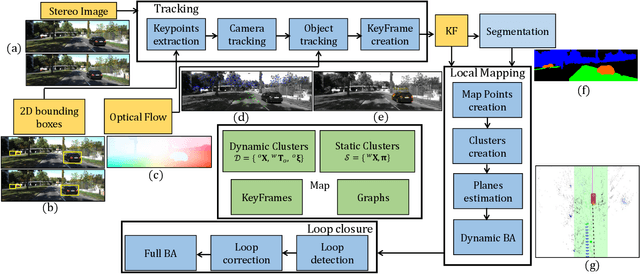
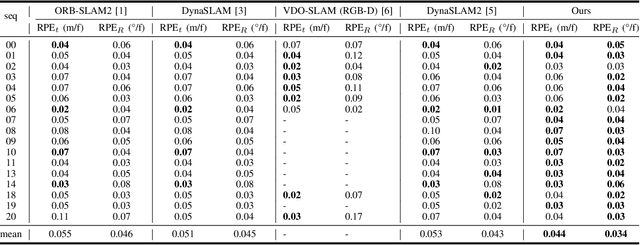
Moving objects are present in most scenes of our life. However they can be very problematic for classical SLAM algorithms that assume the scene to be rigid. This assumption limits the applicability of those algorithms as they are unable to accurately estimate the camera pose and world structure in many scenarios. Some SLAM systems have been proposed to detect and mask out dynamic objects, making the static scene assumption valid. However this information can allow the system to track objects within the scene, while tracking the camera, which can be crucial for some applications. In this paper we present TwistSLAM a semantic, dynamic, stereo SLAM system that can track dynamic objects in the scene. Our algorithm creates clusters of points according to their semantic class. It uses the static parts of the environment to robustly localize the camera and tracks the remaining objects. We propose a new formulation for the tracking and the bundle adjustment to take in account the characteristics of mechanical joints between clusters to constrain and improve their pose estimation. We evaluate our approach on several sequences from a public dataset and show that we improve camera and object tracking compared to state of the art.
Prediction Sensitivity: Continual Audit of Counterfactual Fairness in Deployed Classifiers
Feb 09, 2022


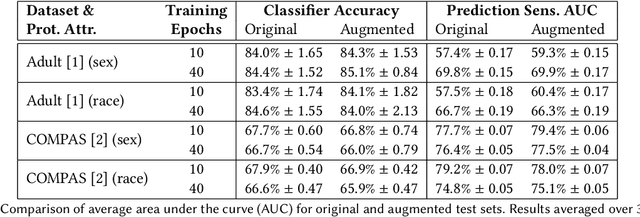
As AI-based systems increasingly impact many areas of our lives, auditing these systems for fairness is an increasingly high-stakes problem. Traditional group fairness metrics can miss discrimination against individuals and are difficult to apply after deployment. Counterfactual fairness describes an individualized notion of fairness but is even more challenging to evaluate after deployment. We present prediction sensitivity, an approach for continual audit of counterfactual fairness in deployed classifiers. Prediction sensitivity helps answer the question: would this prediction have been different, if this individual had belonged to a different demographic group -- for every prediction made by the deployed model. Prediction sensitivity can leverage correlations between protected status and other features and does not require protected status information at prediction time. Our empirical results demonstrate that prediction sensitivity is effective for detecting violations of counterfactual fairness.
Contrastive Embedding Distribution Refinement and Entropy-Aware Attention for 3D Point Cloud Classification
Jan 27, 2022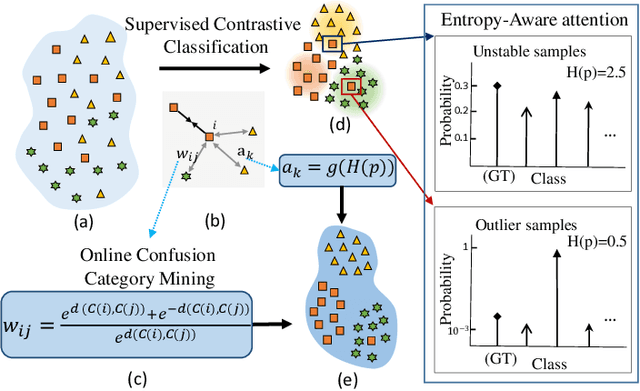
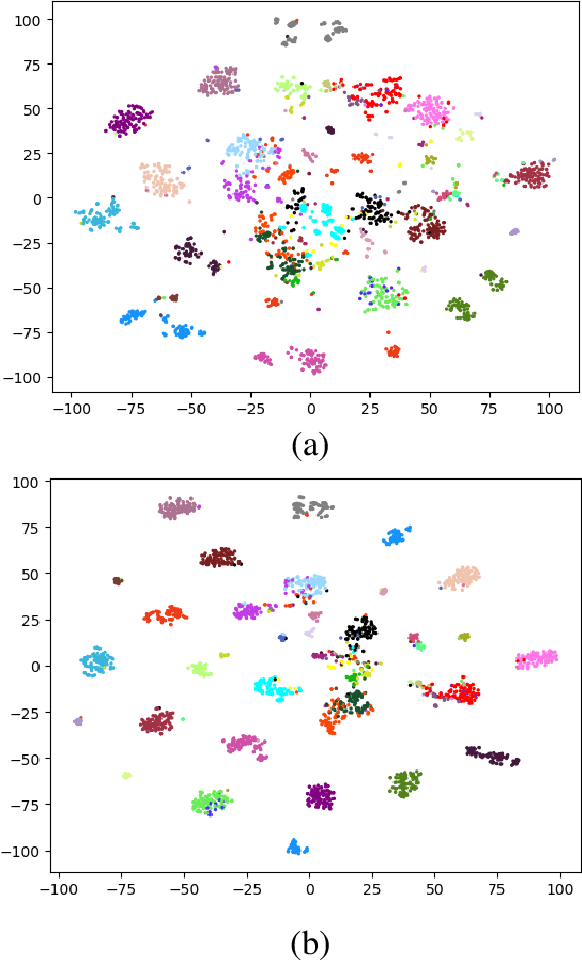
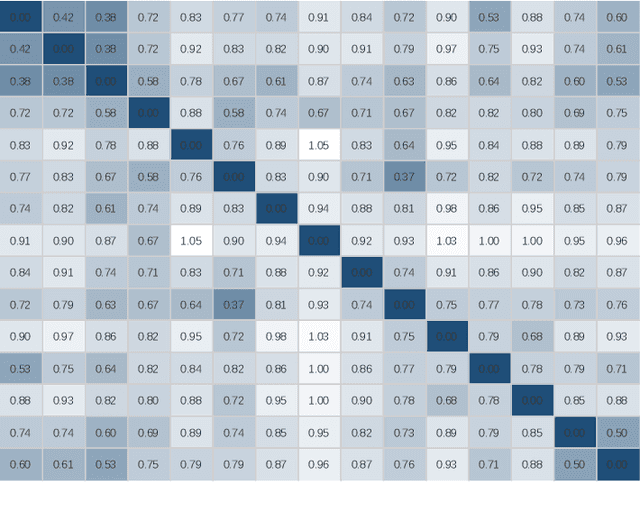
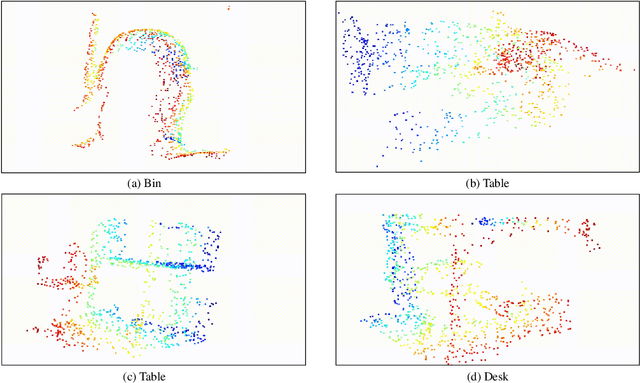
Learning a powerful representation from point clouds is a fundamental and challenging problem in the field of computer vision. Different from images where RGB pixels are stored in the regular grid, for point clouds, the underlying semantic and structural information of point clouds is the spatial layout of the points. Moreover, the properties of challenging in-context and background noise pose more challenges to point cloud analysis. One assumption is that the poor performance of the classification model can be attributed to the indistinguishable embedding feature that impedes the search for the optimal classifier. This work offers a new strategy for learning powerful representations via a contrastive learning approach that can be embedded into any point cloud classification network. First, we propose a supervised contrastive classification method to implement embedding feature distribution refinement by improving the intra-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class variations between some similar-looking categories, we propose a confusion-prone class mining strategy to alleviate the confusion effect. Finally, considering that outliers of the sample clusters in the embedding space may cause performance degradation, we design an entropy-aware attention module with information entropy theory to identify the outlier cases and the unstable samples by measuring the uncertainty of predicted probability. The results of extensive experiments demonstrate that our method outperforms the state-of-the-art approaches by achieving 82.9% accuracy on the real-world ScanObjectNN dataset and substantial performance gains up to 2.9% in DCGNN, 3.1% in PointNet++, and 2.4% in GBNet.
A Gating Model for Bias Calibration in Generalized Zero-shot Learning
Mar 08, 2022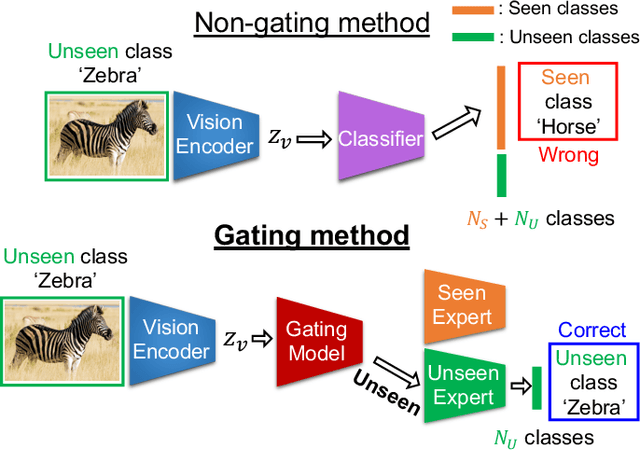
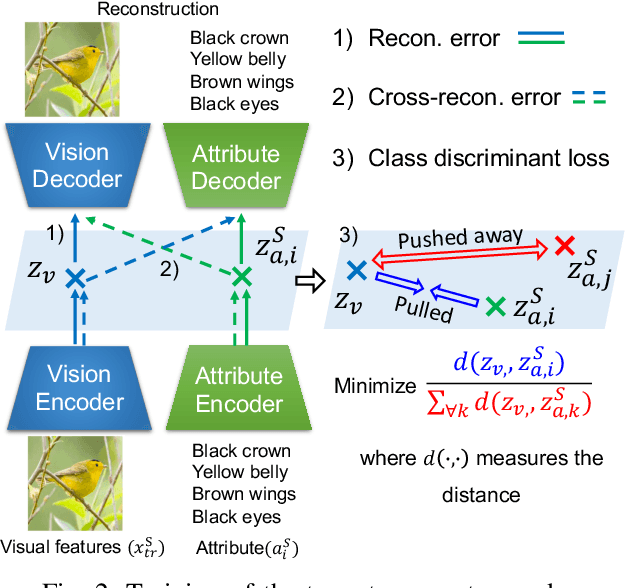
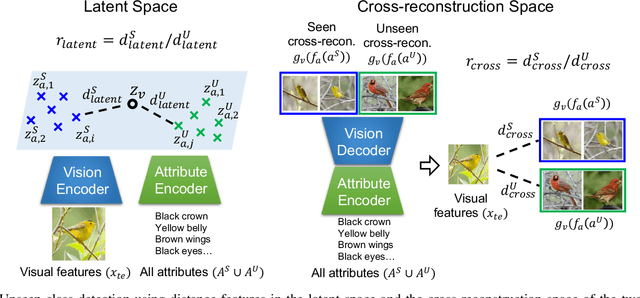

Generalized zero-shot learning (GZSL) aims at training a model that can generalize to unseen class data by only using auxiliary information. One of the main challenges in GZSL is a biased model prediction toward seen classes caused by overfitting on only available seen class data during training. To overcome this issue, we propose a two-stream autoencoder-based gating model for GZSL. Our gating model predicts whether the query data is from seen classes or unseen classes, and utilizes separate seen and unseen experts to predict the class independently from each other. This framework avoids comparing the biased prediction scores for seen classes with the prediction scores for unseen classes. In particular, we measure the distance between visual and attribute representations in the latent space and the cross-reconstruction space of the autoencoder. These distances are utilized as complementary features to characterize unseen classes at different levels of data abstraction. Also, the two-stream autoencoder works as a unified framework for the gating model and the unseen expert, which makes the proposed method computationally efficient. We validate our proposed method in four benchmark image recognition datasets. In comparison with other state-of-the-art methods, we achieve the best harmonic mean accuracy in SUN and AWA2, and the second best in CUB and AWA1. Furthermore, our base model requires at least 20% less number of model parameters than state-of-the-art methods relying on generative models.
Securing Reconfigurable Intelligent Surface-Aided Cell-Free Networks
Feb 15, 2022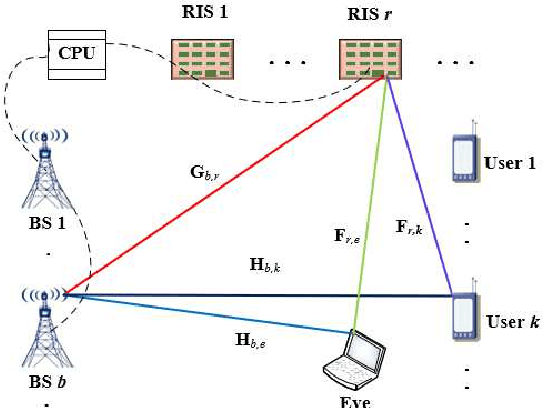
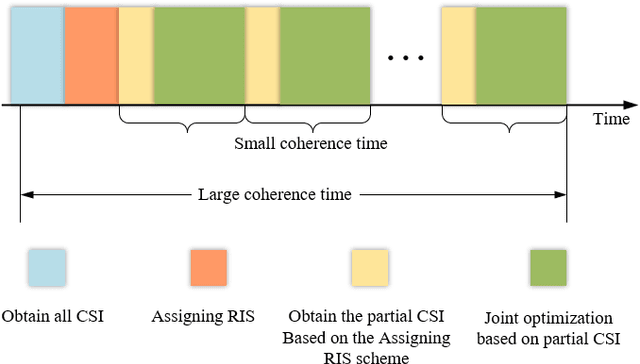
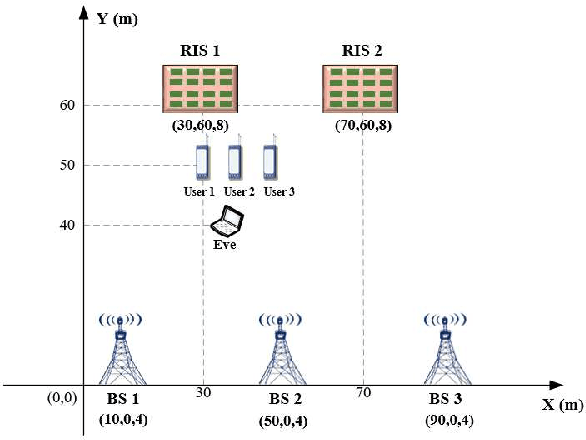
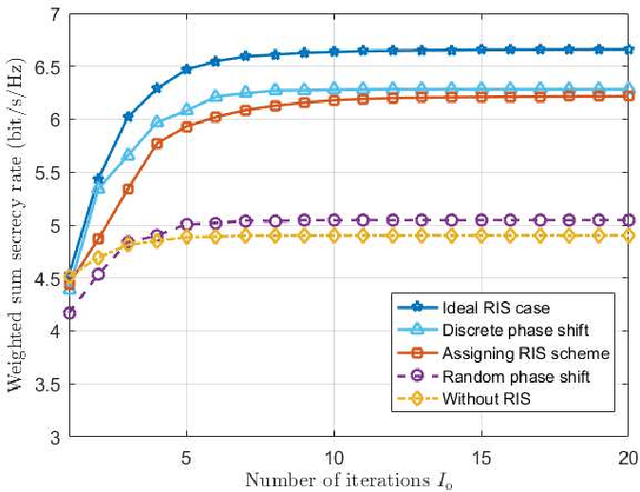
In this paper, we investigate the physical layer security in the reconfigurable intelligent surface (RIS)-aided cell-free networks. A maximum weighted sum secrecy rate problem is formulated by jointly optimizing the active beamforming (BF) at the base stations and passive BF at the RISs. To handle this non-trivial problem, we adopt the alternating optimization to decouple the original problem into two sub-ones, which are solved using the semidefinite relaxation and continuous convex approximation theory. To decrease the complexity for obtaining overall channel state information (CSI), we extend the proposed framework to the case that only requires part of the RIS' CSI. This is achieved via deliberately discarding the RIS that has a small contribution to the user's secrecy rate. Based on this, we formulate a mixed integer non-linear programming problem, and the linear conic relaxation is used to obtained the solutions. Finally, the simulation results show that the proposed schemes can obtain a higher secrecy rate than the existing ones.
Breast Cancer Molecular Subtypes Prediction on Pathological Images with Discriminative Patch Selecting and Multi-Instance Learning
Mar 15, 2022
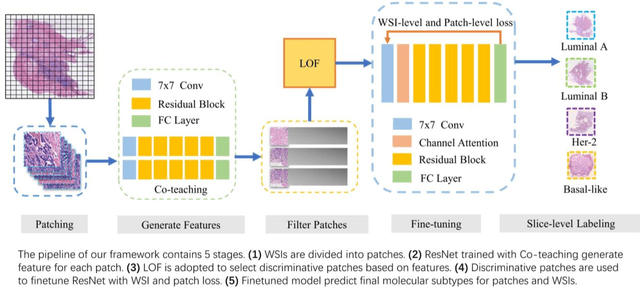
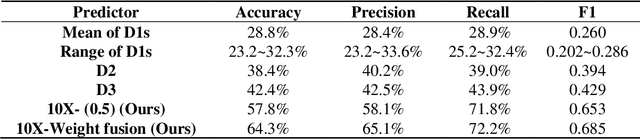
Molecular subtypes of breast cancer are important references to personalized clinical treatment. For cost and labor savings, only one of the patient's paraffin blocks is usually selected for subsequent immunohistochemistry (IHC) to obtain molecular subtypes. Inevitable sampling error is risky due to tumor heterogeneity and could result in a delay in treatment. Molecular subtype prediction from conventional H&E pathological whole slide images (WSI) using AI method is useful and critical to assist pathologists pre-screen proper paraffin block for IHC. It's a challenging task since only WSI level labels of molecular subtypes can be obtained from IHC. Gigapixel WSIs are divided into a huge number of patches to be computationally feasible for deep learning. While with coarse slide-level labels, patch-based methods may suffer from abundant noise patches, such as folds, overstained regions, or non-tumor tissues. A weakly supervised learning framework based on discriminative patch selecting and multi-instance learning was proposed for breast cancer molecular subtype prediction from H&E WSIs. Firstly, co-teaching strategy was adopted to learn molecular subtype representations and filter out noise patches. Then, a balanced sampling strategy was used to handle the imbalance in subtypes in the dataset. In addition, a noise patch filtering algorithm that used local outlier factor based on cluster centers was proposed to further select discriminative patches. Finally, a loss function integrating patch with slide constraint information was used to finetune MIL framework on obtained discriminative patches and further improve the performance of molecular subtyping. The experimental results confirmed the effectiveness of the proposed method and our models outperformed even senior pathologists, with potential to assist pathologists to pre-screen paraffin blocks for IHC in clinic.
MISF: Multi-level Interactive Siamese Filtering for High-Fidelity Image Inpainting
Mar 12, 2022

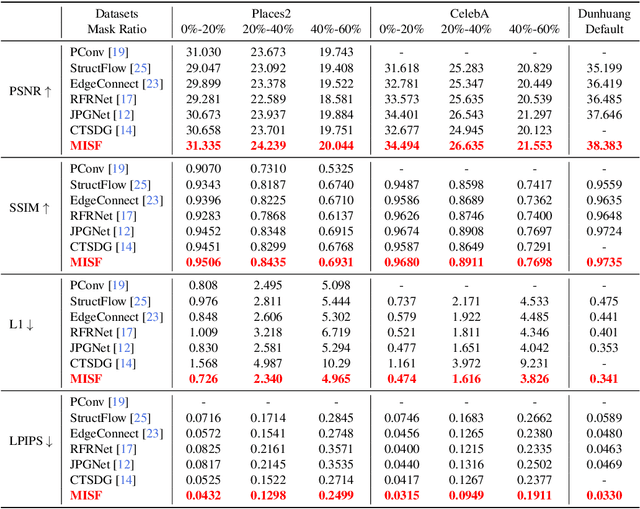
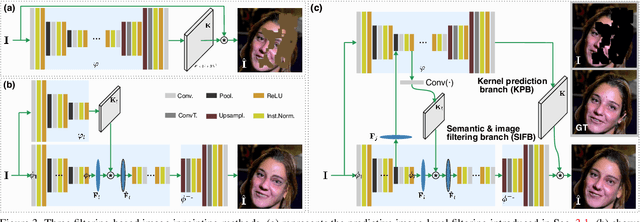
Although achieving significant progress, existing deep generative inpainting methods are far from real-world applications due to the low generalization across different scenes. As a result, the generated images usually contain artifacts or the filled pixels differ greatly from the ground truth. Image-level predictive filtering is a widely used image restoration technique, predicting suitable kernels adaptively according to different input scenes. Inspired by this inherent advantage, we explore the possibility of addressing image inpainting as a filtering task. To this end, we first study the advantages and challenges of image-level predictive filtering for image inpainting: the method can preserve local structures and avoid artifacts but fails to fill large missing areas. Then, we propose semantic filtering by conducting filtering on the deep feature level, which fills the missing semantic information but fails to recover the details. To address the issues while adopting the respective advantages, we propose a novel filtering technique, i.e., Multilevel Interactive Siamese Filtering (MISF), which contains two branches: kernel prediction branch (KPB) and semantic & image filtering branch (SIFB). These two branches are interactively linked: SIFB provides multi-level features for KPB while KPB predicts dynamic kernels for SIFB. As a result, the final method takes the advantage of effective semantic & image-level filling for high-fidelity inpainting. We validate our method on three challenging datasets, i.e., Dunhuang, Places2, and CelebA. Our method outperforms state-of-the-art baselines on four metrics, i.e., L1, PSNR, SSIM, and LPIPS. Please try the released code and model at https://github.com/tsingqguo/misf.