 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Subgroups of ICU Patients Using End-to-End Multivariate Time-Series Clustering Algorithm Based on Real-World Vital Signs Data
Jun 03, 2023
This study employed the MIMIC-IV database as data source to investigate the use of dynamic, high-frequency, multivariate time-series vital signs data, including temperature, heart rate, mean blood pressure, respiratory rate, and SpO2, monitored first 8 hours data in the ICU stay. Various clustering algorithms were compared, and an end-to-end multivariate time series clustering system called Time2Feat, combined with K-Means, was chosen as the most effective method to cluster patients in the ICU. In clustering analysis, data of 8,080 patients admitted between 2008 and 2016 was used for model development and 2,038 patients admitted between 2017 and 2019 for model validation. By analyzing the differences in clinical mortality prognosis among different categories, varying risks of ICU mortality and hospital mortality were found between different subgroups. Furthermore, the study visualized the trajectory of vital signs changes. The findings of this study provide valuable insights into the potential use of multivariate time-series clustering systems in patient management and monitoring in the ICU setting.
Contrastive Embedding Distribution Refinement and Entropy-Aware Attention for 3D Point Cloud Classification
Jan 27, 2022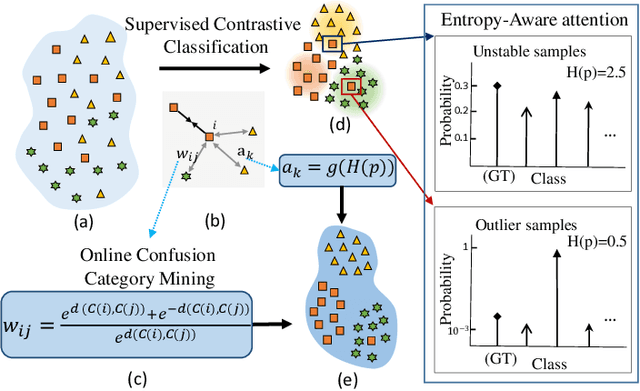
Learning a powerful representation from point clouds is a fundamental and challenging problem in the field of computer vision. Different from images where RGB pixels are stored in the regular grid, for point clouds, the underlying semantic and structural information of point clouds is the spatial layout of the points. Moreover, the properties of challenging in-context and background noise pose more challenges to point cloud analysis. One assumption is that the poor performance of the classification model can be attributed to the indistinguishable embedding feature that impedes the search for the optimal classifier. This work offers a new strategy for learning powerful representations via a contrastive learning approach that can be embedded into any point cloud classification network. First, we propose a supervised contrastive classification method to implement embedding feature distribution refinement by improving the intra-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class variations between some similar-looking categories, we propose a confusion-prone class mining strategy to alleviate the confusion effect. Finally, considering that outliers of the sample clusters in the embedding space may cause performance degradation, we design an entropy-aware attention module with information entropy theory to identify the outlier cases and the unstable samples by measuring the uncertainty of predicted probability. The results of extensive experiments demonstrate that our method outperforms the state-of-the-art approaches by achieving 82.9% accuracy on the real-world ScanObjectNN dataset and substantial performance gains up to 2.9% in DCGNN, 3.1% in PointNet++, and 2.4% in GBNet.
Fast PDN Impedance Prediction Using Deep Learning
Jun 20, 2021
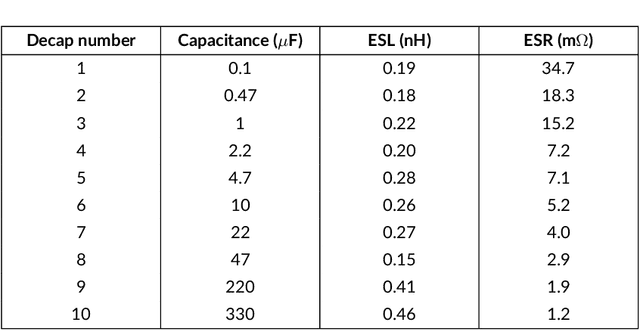
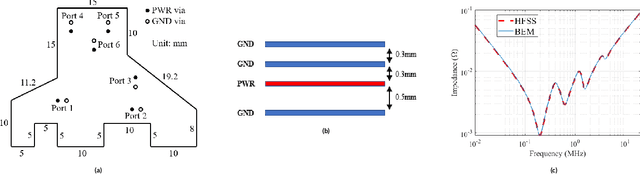

Modeling and simulating a power distribution network (PDN) for printed circuit boards (PCBs) with irregular board shapes and multi-layer stackup is computationally inefficient using full-wave simulations. This paper presents a new concept of using deep learning for PDN impedance prediction. A boundary element method (BEM) is applied to efficiently calculate the impedance for arbitrary board shape and stackup. Then over one million boards with different shapes, stackup, IC location, and decap placement are randomly generated to train a deep neural network (DNN). The trained DNN can predict the impedance accurately for new board configurations that have not been used for training. The consumed time using the trained DNN is only 0.1 seconds, which is over 100 times faster than the BEM method and 5000 times faster than full-wave simulations.