 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Multimodal In-Context Learning
Mar 05, 2026Vision-language models are increasingly applied to sensitive domains such as medical imaging and personal photographs, yet existing differentially private methods for in-context learning are limited to few-shot, text-only settings because privacy cost scales with the number of tokens processed. We present Differentially Private Multimodal Task Vectors (DP-MTV), the first framework enabling many-shot multimodal in-context learning with formal $(\varepsilon, δ)$-differential privacy by aggregating hundreds of demonstrations into compact task vectors in activation space. DP-MTV partitions private data into disjoint chunks, applies per-layer clipping to bound sensitivity, and adds calibrated noise to the aggregate, requiring only a single noise addition that enables unlimited inference queries. We evaluate on eight benchmarks across three VLM architectures, supporting deployment with or without auxiliary data. At $\varepsilon=1.0$, DP-MTV achieves 50% on VizWiz compared to 55% non-private and 35% zero-shot, preserving most of the gain from in-context learning under meaningful privacy constraints.
AgentSCOPE: Evaluating Contextual Privacy Across Agentic Workflows
Mar 05, 2026Agentic systems are increasingly acting on users' behalf, accessing calendars, email, and personal files to complete everyday tasks. Privacy evaluation for these systems has focused on the input and output boundaries, but each task involves several intermediate information flows, from agent queries to tool responses, that are not currently evaluated. We argue that every boundary in an agentic pipeline is a site of potential privacy violation and must be assessed independently. To support this, we introduce the Privacy Flow Graph, a Contextual Integrity-grounded framework that decomposes agentic execution into a sequence of information flows, each annotated with the five CI parameters, and traces violations to their point of origin. We present AgentSCOPE, a benchmark of 62 multi-tool scenarios across eight regulatory domains with ground truth at every pipeline stage. Our evaluation across seven state-of-the-art LLMs show that privacy violations in the pipeline occur in over 80% of scenarios, even when final outputs appear clean (24%), with most violations arising at the tool-response stage where APIs return sensitive data indiscriminately. These results indicate that output-level evaluation alone substantially underestimates the privacy risk of agentic systems.
Backpropagation Clipping for Deep Learning with Differential Privacy
Feb 17, 2022



We present backpropagation clipping, a novel variant of differentially private stochastic gradient descent (DP-SGD) for privacy-preserving deep learning. Our approach clips each trainable layer's inputs (during the forward pass) and its upstream gradients (during the backward pass) to ensure bounded global sensitivity for the layer's gradient; this combination replaces the gradient clipping step in existing DP-SGD variants. Our approach is simple to implement in existing deep learning frameworks. The results of our empirical evaluation demonstrate that backpropagation clipping provides higher accuracy at lower values for the privacy parameter $\epsilon$ compared to previous work. We achieve 98.7% accuracy for MNIST with $\epsilon = 0.07$ and 74% accuracy for CIFAR-10 with $\epsilon = 3.64$.
Prediction Sensitivity: Continual Audit of Counterfactual Fairness in Deployed Classifiers
Feb 09, 2022


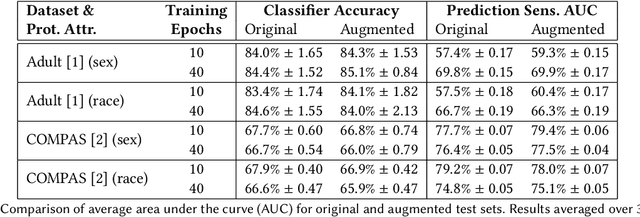
As AI-based systems increasingly impact many areas of our lives, auditing these systems for fairness is an increasingly high-stakes problem. Traditional group fairness metrics can miss discrimination against individuals and are difficult to apply after deployment. Counterfactual fairness describes an individualized notion of fairness but is even more challenging to evaluate after deployment. We present prediction sensitivity, an approach for continual audit of counterfactual fairness in deployed classifiers. Prediction sensitivity helps answer the question: would this prediction have been different, if this individual had belonged to a different demographic group -- for every prediction made by the deployed model. Prediction sensitivity can leverage correlations between protected status and other features and does not require protected status information at prediction time. Our empirical results demonstrate that prediction sensitivity is effective for detecting violations of counterfactual fairness.
Towards Auditability for Fairness in Deep Learning
Nov 30, 2020
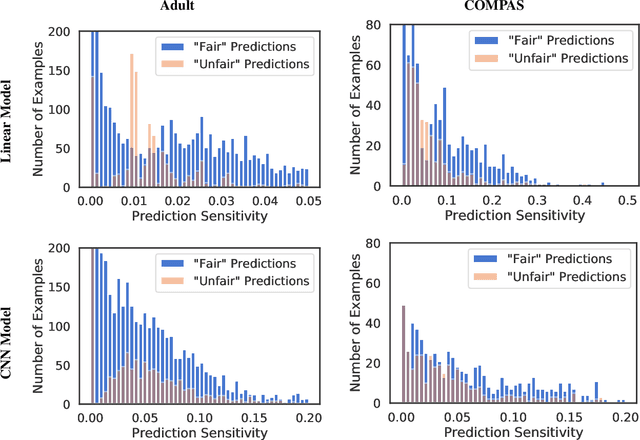
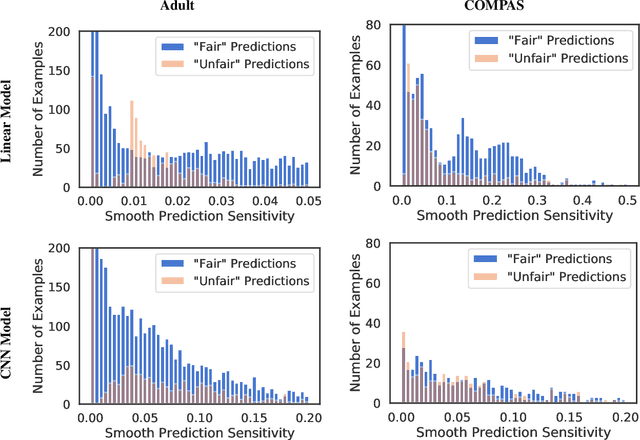
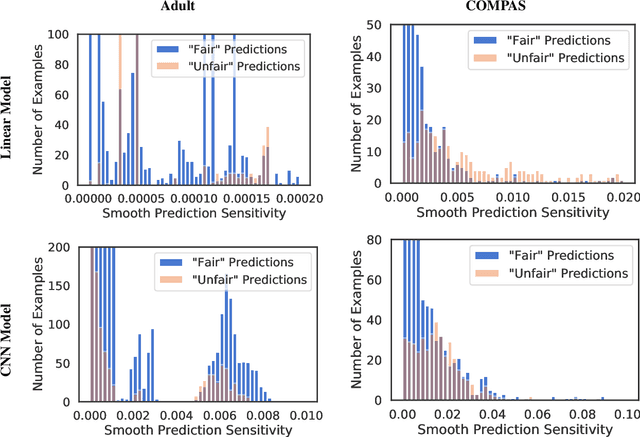
Group fairness metrics can detect when a deep learning model behaves differently for advantaged and disadvantaged groups, but even models that score well on these metrics can make blatantly unfair predictions. We present smooth prediction sensitivity, an efficiently computed measure of individual fairness for deep learning models that is inspired by ideas from interpretability in deep learning. smooth prediction sensitivity allows individual predictions to be audited for fairness. We present preliminary experimental results suggesting that smooth prediction sensitivity can help distinguish between fair and unfair predictions, and that it may be helpful in detecting blatantly unfair predictions from "group-fair" models.